
智能圈选依赖必要的数据进行特征开发和模型建模,您需要按照数据格式和建模数量级要求准备建模依赖的数据,并进行数据校验,帮助您快速接入插件。本文为您介绍训练任务输入数据格式说明、建模量级要求及离线自测方法。
策略训练任务输入数据格式说明
如果您要在后续使用智能发送来触达人群,则需要按照个性化触达时间配置说明来配置行为维表(behavior)和运营记录维表(operation)的数据。
目录要求
训练任务输入数据依赖用户基础信息(user)、物品基础信息(item)、用户行为(behavior)、运营记录(operation)四类数据进行建模,您可以在存储空间Bucket(以pai-usergrowth-客户拼写缩写命名)下设置两层文件夹,具体目录结构如下所示。
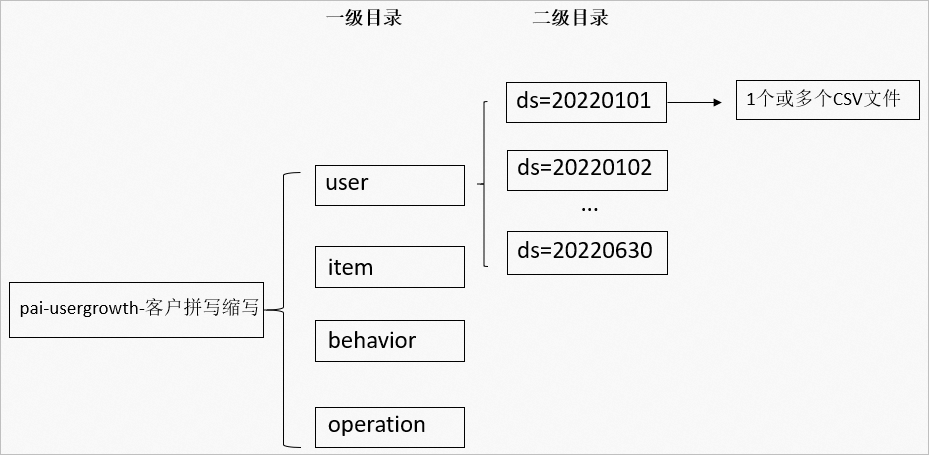 其中:
其中:一级目录为各个维表,目录名称固定为user、item、behavior和operation,且不能修改。
二级目录对应各维表的ds分区字段,时间目录,命名为ds=yyyymmdd,例如ds=20220301。
各ds文件夹下可上传单个或多个CSV文件,CSV文件内容分别为用户在YYYYDDMM这一天的用户基础信息、物品基础信息、行为信息和运营信息。您可以上传单个或多个CSV文件,文件内容格式要求如下:
UTF-8编码。
首行为字段名,格式以及字段顺序严格按照各个维表要求。
由于ds已经作为二级目录名存在,CSV文件中不能包含ds字段。
统一使用\N表示NULL值。
XXX.csv文件内容要求
需要每天按时间目录更新数据,各个维表字段要求如下:
说明数值型属性应满足属性值比大小是有意义的。提供一个数值型属性的反例,例如我们对省份按1、2、3...连续编号,则用户地域信息可转化为数值型,此时省份x大于省份y并没有意义,违反约定,因此省份需要按字符型数据处理。
用户基础维表(user)
用来记录静态用户属性,比如性别、年龄、注册日期等。各字段定义如下表所示。
字段名称
字段类型
描述
user_id
String
用户ID,用来唯一区分用户,不能为空。
gender
Bigint
用户性别:
1:男。
2:女。
\N:未知。
说明使用\N表示NULL值。
age
Bigint
用户年龄,\N表示未知。
说明使用\N表示NULL值。
reg_time
String
注册日期,格式为yyyymmdd,\N表示未知。
说明使用\N表示NULL值。
user_type
String
业务相关的用户分类。如果业务无分类可以设置为\N。
说明使用\N表示NULL值。
kvs_num
String
扩展的数值型用户属性,属性值支持整型与浮点型,格式为
k1:v1 k2:v2...。即一对属性及属性值由半角冒号(:)分隔,多个属性对由空格分隔,支持稀疏表示。命名规范如下所示(同样适用于其他维表):半角冒号(:)、半角逗号(,)和空格为保留字符,不能出现在属性名和字符型属性值中。例如:属性名a b、a:b、a,b与属性值c 、:d、,e都是不合法的。
属性名可以匿名化处理成编号,也可以使用原始属性名。例如:kvs_num字段配置为1:1.02:1.5 4:2.0。
支持稀疏表示:如果用户缺少某属性,可直接在kvs_num或kvs_str中跳过该属性。例如上述示例中缺少属性3,可以直接跳过。
kvs_str
String
扩展的字符型用户属性,格式为
k1:v1 k2:v2...。命名规范同kvs_num。物品基础维表(item)
用来记录静态物品属性,比如物品类目等。各字段定义如下表所示。
说明将业务中用户可交互的项目统称为物品(item),包括但不限于商品(购买交互)、电影(观影交互)、小说(阅读交互)等。
字段名称
字段类型
描述
item_id
String
物品ID,用来唯一区分物品,不能为空。
item_type
String
业务相关的物品类目。如果业务无分类可以设置为\N。
说明使用\N表示NULL值。
kvs_num
String
扩展的数值型物品属性,格式为
k1:v1 k2:v2...,例如:price:18。kvs_str
String
扩展的字符型物品属性,格式为
k1:v1 k2:v2...。行为维表(behavior)
用来记录用户行为。根据行为是否关联item中的物品,将行为划分为一元行为(不关联物品)和二元行为(关联物品),行为维表需按日分区,且每个分区包含当日产生的行为数据,建议提供6个月以上的数据。各字段定义如下表所示。
字段名称
字段类型
描述
user_id
String
用户ID,与user配置相同。
behavior
String
行为类型。必须包含login,其他建议包含:
一元行为:活跃、充值、搜索等。
二元行为:点击、收藏、喜欢、不喜欢、观看、投票、发消息等,
命名规范如下:
login=登录、active=活跃、recharge=充值、buy=消费、search=搜索、click=点击、collect=收藏、like=喜欢、dislike=不喜欢、play=观看、vote=投票、u2u_send_msg=用户间发消息。
不在以上范围的behavior,支持自定义名称。具体使用示例,请参见使用示例。
重要对于社交类服务的用户间行为,behavior命名必须以
u2u_开头,例如:将发消息行为命名为u2u_send_msg。如果后续使用智能发送方式触达人群,则必须包含click、login或search。
item_id
String
商品ID,与item配置相同。如果behavior为一元行为,该列设置为\N(统一使用该参数表示NULL值)。
说明对于社交类服务的用户间行为,比如发消息,item_id字段可以直接使用user_id。
kvs_num
String
扩展的数值型行为属性,例如:活跃时长、投票数量等,格式为
k1:v1 k2:v2...。属性名命名规范如下。
hour=小时、act00-act23=对应某小时里的用户活跃时长(单位秒)、hh=小时、province=省份、city=地市、cents=充值或者消费金额(单位分)、seconds=时长(单位秒)、tickets=投票张数、query=检索文本、msg=消息文本,不在以上范围内可自行命名。
重要如果后续使用智能发送方式触达人群,则该字段key值需配置为
hh00~hh23,例如:hh21:1,表示21点,频次为1。kvs_str
String
扩展的字符型行为属性,例如:搜索关键词、消息内容等。格式为
k1:v1 k2:v2...。属性名命名规范同kvs_num。表 1. 使用示例
user_id
behavior
item_id
kvs_num
kvs_str
10001
login
\N
hour:14
\N
10001
active
\N
act14:1800 act20:600
\N
10002
recharge
\N
cents:100
\N
10003
search
\N
\N
query:A
10004
click
90001
\N
\N
10005
watch
90002
seconds:60
\N
10006
u2u_send_msg
10001
\N
msg:Hi
例如行为维表的上级目录为:ds20210101,表中各行释义如下:
用户10001在20210101当日登录,具体登录时间为14:00-15:00之间(建议提供小时粒度的登录时间信息)。
用户10001在20210101当日14:00-15:00之间的活跃时长为1800秒,在20:00-21:00之间的活跃时长为600秒。即用户在单日的活跃时长统计对应一条行为记录,由act00-act23分别记录24个小时里的活跃时长,不活跃的小时直接忽略即可。
用户10002在20210101当日充值100分。
用户10003在20210101当日搜索A。
用户10004在20210101当日单击物品90001。
用户10005在20210101当日观看物品90002,时长60秒。
用户10006在20210101当日给用户10001发消息,内容为Hi。
运营记录维表(operation)
用来记录已经开展过的运营行为,按日期和运营目标分区,每个分区包含当日发起的指定运营目标的运营记录。各字段定义如下表所示。
说明如果您之前未做过运营行为(触达策略),为了能够更直观的查看前后对比效果,建议您沿用原有的触达策略或随机触达发送一次短信,统计下运营记录。
字段名称
字段类型
描述
user_id
String
用户ID。与user配置相同。
item_id
String
商品id,对应物品基础信息维表;运营行为无item时可配置为\N。
说明使用\N表示NULL值。
strategy
String
用户圈选策略。例如:rule、random(默认值)等。
您可以自定义圈选策略,系统会根据实际填写内容来处理。
kvs_num
String
扩展的数值型属性,例如短信发送时间(小时)等,格式为
k1:v1 k2:v2...。预留key值
hh00~hh23,用于存放运营行为的时间。kvs_str
String
扩展的字符型属性,例如短信文案、文案类型等。
重要如果后续使用智能发送方式触达人群,则必须包含buy、click或mix。
label
Bigint
运营成功标签。
1:成功。
0:失败。
target
String
分区字段,运营目标。
维表重要性评估如下表所示。
说明表名列的xxx请替换为客户名或客户名缩写。
维表
表名
必要性
ds目录含义
用户基础维表
dwd_xxx_user_df
必选
截止ds日(包含)的数据。
物品基础维表
dwd_xxx_item_df
可选
截止ds日(包含)的数据。
行为维表
dwd_xxx_behavior_di
必选
ds当日产生的数据。
运营记录维表
dwd_xxx_operation_di
可选
ds当日产生的数据。
建模数据量级要求
模型训练要求的数量级与目标转化行为相关联,需要您选择最近三个月内尽可能新的数据作为训练数据集。例如优化目标为降低用来召回用户花费的成本,优化层级为付费,具体数据要求说明如下:
全漏斗数据指从短信发送成功后的所有后链路数据。您可以将曝光(表示短信发送成功)、登录、点击、付费理解为一个全链路。
回传曝光后的全漏斗数据,包括曝光后登录、曝光后未登录、登录后付费、登录后未付费的用户数据。
上述全漏斗数据中,应包含至少20000条自曝光后有付费行为用户的全漏斗数据,即登录后付费的用户数据,作为正样本数据。
例如:当天一共有1万条短信发送成功,其中1000条短信召回用户并付费。则您需要回传1万条用户的全量数据,其中的1000条付费数据为正样本。回传多天全量数据,直到付费正样本数据累积到20000条。
数据验证
准备好训练数据后,您需要完成以下两项离线自测:
报表对比
当数据上传到OSS后,请您将生成的上传数据明细与您内部的数据报表进行比对,两份数据表现相似,单日单账号统计指标相差不超过5%,确保数据在传输过程中无错误和遗漏。
说明统计指标包括曝光量、转化量、转化率等。其中:
曝光量:发送成功的短信数量。
转化量:用户接收到短信后,登录、点击或付费的用户数量。
转化率:用户接收到短信后登录的用户比例、用户登录后发生点击的用户比例、用户点击后发生付费的用户比例等。
归因逻辑自洽
投放归因完整。当一行数据中后链路行为取值为1时,跨天登录等特殊行为情况除外,前链路指标逻辑上均为1。例如:一行数据的深转化(表示用户点击后发生付费行为)为1,浅转化(表示用户登录后发生点击行为)也应当为1。
说明您可以将曝光(表示短信发送成功)、登录、点击、付费理解为一个全链路。其中:
前链路可以表示曝光、登录等行为。
后链路可以表示登录、点击或付费等行为。