
该组件使用hit_rate_pai.py脚本,实现向量召回评估的功能。本文为您介绍该组件的配置方法。
使用限制
支持使用的计算引擎为MaxCompute。
组件配置
您可以使用以下任意一种方式,配置模型hitrate评估组件参数。
方式一:可视化配置参数
输入桩
输入桩(从左到右)
建议上游组件
对应PAI命令参数
是否必选
item embedding table name
参数会拼装成tables参数
是
ground truth table name
是
组件参数
页签
参数
是否必选
描述
对应PAI命令参数
默认值
参数设置
recall_type
否
召回类型,类型为String,取值如下:
u2i:user to item retrieval
i2i:item to item retrieval
recall_type
u2i:user to item retrieval
knn检索取top_k计算hitrate
否
召回的数目,类型为String。
top_k
200
user/item表征向量的维度emb_dim
否
Embedding表的Embedding维度 ,类型为INT。
emb_dim
32
定义距离计算方式knn_metric
否
召回相似度度量方式,类型为String,取值如下:
0: L2 distance
1: Inner Product similarity
knn_metric
0
是否使用精确的knn计算knn_strict
否
BOOL类型,取值如下:
True:使用精确的knn计算,会增加计算量。
False:不使用精确的knn计算。
knn_strict
True
batch_size
否
一次计算的样本数量,类型为INT。
batch_size
1024
最大的兴趣向量数num_interests
否
最大兴趣向量数,类型为INT。
num_interests
1
指定算法版本
是
支持自定义EasyRec的执行版本。
首先参考文档EasyRec版本更新,生成一个EasyRec的tar包。
上传对应版本的tar包到OSS Bucket路径。具体操作,请参见控制台上传文件。
在该参数中选中上传的tar文件所在的OSS全路径。
script
无
执行调优
ps数量
否
PS节点的数量。
完整的执行调优参数会拼装成cluster参数
2
ps CPU数量
否
PS CPU数量,PS申请的CPU数量,取值为1表示一个CPU核。
10
ps Memory用量
否
PS申请的内存,单位为MB,取值100表示100 MB。
40000
Worker数量
否
Worker的数量。
6
Worker CPU用量
否
Worker申请的CPU数量,取值1表示一个CPU核。
8
Worker Memory用量
否
Worker申请的内存,单位为MB,取值100表示100 MB。
40000
Worker GPU卡数
否
在EasyRec训练中,一般不需要使用GPU。
0
输出桩
输出桩(从左到右)
数据类型
对应PAI命令参数
是否必选
hit_rate_details
MaxCompute表
拼装成outputs参数
是
total_hit_rate
MaxCompute表
是
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name tensorflow1120_cpu_ext
-project algo_public
-Darn="acs:ram::xxx:role/aliyunodpspaidefaultrole"
-Dbuckets="oss://examplebucket/"
-DossHost="oss-cn-hangzhou-internal.aliyuncs.com"
-DentryFile="easy_rec/python/tools/hit_rate_pai.py"
-Dcluster="{\"ps\": {\"count\": 2, \"cpu\": 1000, \"memory\": 40000}, \"worker\": {\"count\": 6, \"cpu\": 800, \"gpu\": 0, \"memory\": 40000}}"
-Dtables="odps://pai_hangzhou/tables/pai_temp_flow_vjmgur2q5ca5lz****_node_j5c8mx2h26wqxu****_outputTable/,odps://pai_hangzhou/tables/pai_temp_flow_hfd4fk1z1ba9z5****_node_msqfceossxpy7v****_outputTable/"
-Doutputs="odps://pai_hangzhou/tables/pai_temp_flow_1y1h6j8bnl94ao****_node_74kp8xcaugwmy8****_hit_rate_details,odps://pai_hangzhou/tables/pai_temp_flow_1y1h6j8bnl94ao****_node_74kp8xcaugwmy8****_total_hit_rate"
-DuserDefinedParameters="--recall_type=u2i --top_k=200 --emb_dim=32 --knn_metric=0 --knn_strict=True --batch_size=1024 --num_interests=1"
-Dscript="oss://examplebucket/easy_rec_ext_0.6.1_res.tar.gz"参数名称 | 描述 | 是否必选 |
entryFile | 入口文件,执行hit_rate_pai.py脚本。 | 是 |
tables | 输入表,由item embedding table和ground truth table拼接而成,这两个表拼接时以半角逗号(,)分隔。 | 是 |
outputs | 输出表,由hit_rate_detail和total_hit_rate拼接而成,这两个表拼接时以半角逗号(,)分隔。 | 是 |
arn | 指定授权资源,您可以登录PAI控制台,在开通和授权>全部云产品依赖页面的Designer区域,单击操作列下的查看授权信息,获取arn。 | 是 |
ossHost | OSS各地域Endpoint。如何获取Endpoint,请参见访问域名和数据中心。 | 是 |
buckets | 模型文件所在的Bucket路径或保存模型的Bucket目录,如果有多个Bucket,使用半角逗号(,)分隔,例如 | 是 |
userDefinedParameters | 额外参数,PAIFlow上没有定义的参数,指定recall_type、top_k、emb_dim、knn_metric、knn_strict等参数。 | 否 |
script | 参考文档EasyRec版本更新生成EasyRec的tar包,并上传到OSS,指定tar包的OSS全路径。 | 否 |
使用示例
通过MaxCompute客户端,使用以下命令分别为item embedding和ground truth创建数据表,关于MaxCompute客户端的使用方法,请参见使用本地客户端(odpscmd)连接。
CREATE TABLE IF NOT EXISTS dssm_recall_item_embedding_tmp_for_eval_v1 ( item_id bigint ,item_emb string COMMENT '物料Embedding' ); CREATE TABLE IF NOT EXISTS dssm_recall_vector_recall_sample_eval_sequence_v1 ( requestid string ,item_ids string ,user_emb string COMMENT '用户Embedding' ,emb_num bigint );将下载的训练数据(item_embedding.csv)和测试数据(ground.csv)分别上传到已创建的MaxCompute表中。关于如何使用MaxCompute客户端上传数据,请参见Tunnel命令,您可以在.csv文件所在的目录中执行tunnel命令,或者指定文件的完整绝对路径来进行配置。
tunnel upload item_embedding.csv dssm_recall_item_embedding_tmp_for_eval_v1 -fd \t; tunnel upload ground.csv dssm_recall_vector_recall_sample_eval_sequence_v1 -fd \t;创建如下工作流。
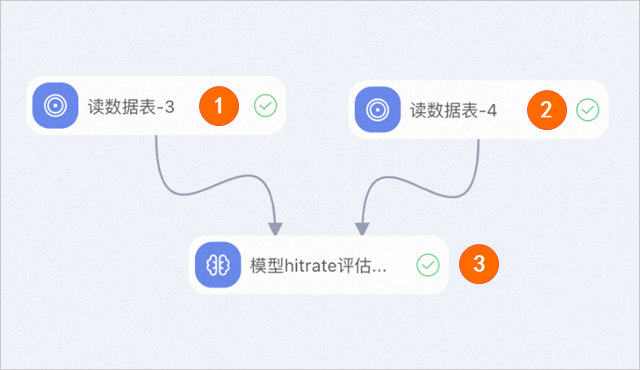
区域
描述
①
配置读数据表-3的表名参数为已创建的dssm_recall_item_embedding_tmp_for_eval_v1表。
②
配置读数据表-4的表名参数为已创建的dssm_recall_vector_recall_sample_eval_sequence_v1表。
③
配置模型hitrate评估组件,将左侧输入桩接入读数据表-3组件下游,将右侧输入桩接入读数据表-4组件下游,将参数指定算法版本配置为EasyRec的tar包所在的OSS全路径,如何准备tar包,请参见方式一:可视化配置参数。本示例使用推荐算法定制-DSSM向量召回案例节点18_rec_sln_demo_dssm_recall_total_hit_rate_v1_2配置的tar文件。
单击运行按钮
 ,运行工作流。
,运行工作流。工作流运行结束后,右键单击画布中的模型hitrate评估组件,在快捷菜单,单击查看数据。支持查看以下两种数据结果。
hit_rate_detail
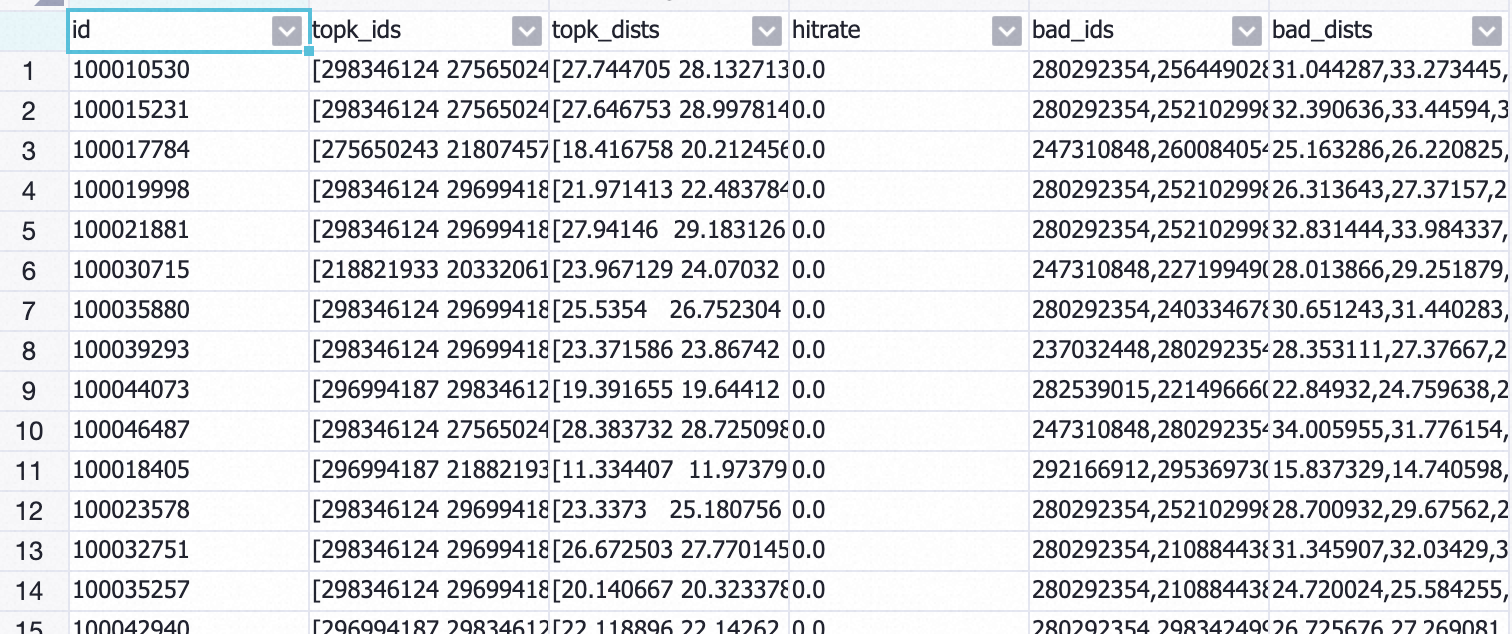
total_hit_rate

相关文档
关于该组件更完整的使用流程,请参考推荐算法定制-DSSM向量召回案例的节点18_rec_sln_demo_dssm_recall_total_hit_rate_v1_2,该节点使用了模型hitrate评估组件。