
本文为您介绍改进版swing相似度计算算法原理,包括工具包下载、工具包详细参数说明以及常见问题等。
改进版swing算法
改进1:限定common neighbour数量
原版的swing算法对于物品的同时被触达的用户数量过少的情况,并不适用。从统计学的角度来看,数据量过少,会导致结果的误差过大。也就是说当同时触达两个物品的用户数量过少时,这时候swing计算得出的结果误差会比较大。
举个极端的例子:
如下图所示,有A、B、C三个视频,X1到X10共10个皇马死忠球迷,只关注音乐的音乐爱好者Y。皇马死忠球迷会看与皇马相关的内容,不管是热门视频C,还是中低频视频A,他们都会观看,可以假定他们都看了200个关于皇马的视频。其中有一个球迷X1,被其他朋友推荐了一首冷门音乐B,听完发现不喜欢这种暗黑系古典音乐,还是喜欢比较激昂的皇马队歌A。音乐爱好者Y会听各种音乐,不管是A,还是B,都会播放。那么在这种情况下,由于视频A、B的共现用户量过少(只有2个),从而导致swing算法得出的分数s(A,B)=0.33 > s(A,C)=0.22。但是很明显,用户在观看视频A的时候,推荐视频C比推荐视频B要好。

解法方法:问题是由两个视频的同时被看的用户数量过少导致的,所以我们需要根据同时观看过两个视频的用户数量来对结果进行处理。我们在swing的基础上,往其公式中增加了指示函数 Id(.) 来达到去噪的目的。同时,引入行为权重来打压过热的用户或物品。改进后的公式如下:
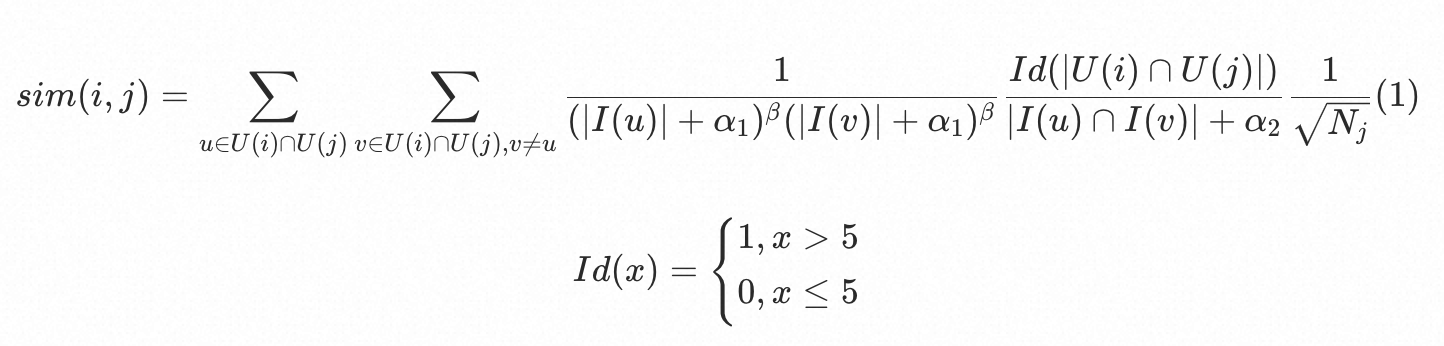
改进2:支持场景i2i
场景i2i —— 基于swing算法学习全网点击与场景点击的共现,倾向于预测用户在场景内的点击,形式化表示如下:
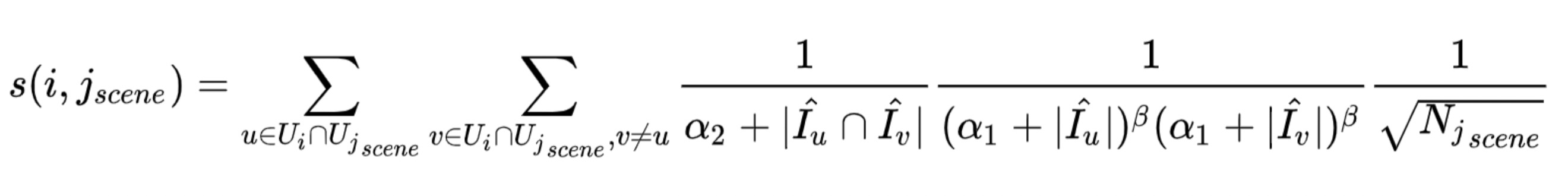
下图给出了全网i2i与场景i2i的结构图,与全网i2i相比,场景i2i不考虑无场景心智(场景内无点击)的用户,只保留用户与场景内点击的边。

改进版swing部署
-
下载算法包到本地:swing-1.0.jar。
如果下载不了,拷贝上述链接到浏览器打开。
-
在MaxCompute项目空间下添加Jar包资源。
在新建资源对话框中,资源类型选择 JAR,勾选上传为ODPS资源,上传本地文件
swing-1.0.jar,单击新建。备注:同一项目空间只需要部署一次。
输入输出格式
输入表(支持分区表)至少包含两列:
-
user_id: bigint/string类型(代码不检查具体类型)的用户ID或session id(推荐)
-
item_list: string类型的物品列表,物品与物品之间的分隔符为英文分号(;),每个物品用bigint类型的ID表示
item序列由分号分割,每个点击物品由至少3个字段构成,即item_id,norm,timestamp,scene,其中item_id需要在开头。
norm代表物品近期的热度(比如,统计该item被多少个用户点击过),即当前item的模,用于惩罚超级热门的item,解决“哈利波特效应”问题。如果不知道norm如何计算,或者数据本身“哈利波特效应”不严重,可以不填这一列。
“哈利波特效应”通常是指一种现象,即一个非常受欢迎和广泛知名的项目(比如《哈利波特》系列书籍或电影)会在推荐列表中占据主导地位,导致其它项目难以获得同等的关注。
备注:norm值仅跟当前物品相关,表示物品的全局热度,跟当前用户无关;在整个训练数据集里,同一物品的norm值必须要在多条记录里保持一致。
timestamp遵循 %Y%m%d%H%M%S(如:20190805223205) 的格式,如不需要可以用同一个timestamp填充。应按照点击时间顺序由远至近组织item_list。
scene是可选字段,为用户行为所在的场景,用于支持场景i2i。
|
user_id |
item_list |
|
12031602 |
558448406561,137,20190805223205;585456515773,39397,20190806170331;10200442969,81,20190807223820 |
|
3954442742 |
658448406561,137,20190805223206;485456515773,39397,20190806170335 |
注意:同一条record中的item_list不要有重复的item_id, 建议 <user, item> pair每天只保留一个, 输入表中的user_id的实际内容处理成 concat(user_id, date) 作为一个虚拟的session_id。
输出表格式(支持分区列):
-
item_id bigint类型的锚定物品ID
-
similar_items 相似物品列表
其中similar_items形如item_id1,score1,coccur1,ori_score1;item_id2,score2,coccur2,ori_score2;...其中,ori_score1 是原始相似度分;score1是最大值归一之后的分数;coccur1是共现次数。
注意:输出表需要预先创建好,column类型不能搞错,column name可自定义。
结果示例:
|
item_id |
similar_items |
|
1084315 |
7876717,0.000047,2,0.003601;6929557,0.000250,2,0.019373;1084342,0.000780,4,0.060325;1089552,0.000963,4,0.074516;1083467,0.008233,5,0.637016;66042,0.012925,6,1.000000 |
|
1090195 |
1090172,0.015136,1,1.000000 |
参考命令行
在DataWorks上新建 ODPS MR 节点(ODPS SQL类型的节点可能会报错),使用如下命令提交Job
jar [<GENERIC_OPTIONS>] <MAIN_CLASS> [ARGS];
-conf <configuration_file> Specify an application configuration file
-resources <resource_name_list> file\table resources used in mapper or reducer, seperate by comma
-classpath <local_file_list> classpaths used to run mainClass
-D<name>=<value> Property value pair, which will be used to run mainClass
ARGS: <in_table/input_partition> <out_table/output_partition>举例如下:
公有云(弹外)用户的命令:
##@resource_reference{"swing-1.0.jar"}
jar -resources swing-1.0.jar
-classpath swing-1.0.jar
-DtopN=150
-Dmax.user.behavior.count=500
-Dcommon.user.number.threshold=0
-Dmax.user.per.item=600
-Ddebug.info.print.number=10
-Dalpha1=5
-Dalpha2=1
-Dbeta=0.3
-Dodps.stage.mapper.split.size=1
com.alibaba.algo.PaiSwing
swing_click_input_table/ds=${bizdate}
swing_output/ds=${bizdate}
;注意:完整代码包括第一行的注释; -D<key>=<value>指定参数值,-D后面不能有空格
弹内用户的命令:
jar -resources swing-1.0.jar
-classpath http://schedule@{env}inside.cheetah.alibaba-inc.com/scheduler/res?id=XXXXX
-DtopN=150
-Dmax.user.behavior.count=500
-Dcommon.user.number.threshold=0
-Dmax.user.per.item=600
-Ddebug.info.print.number=10
-Dalpha1=5
-Dalpha2=1
-Dbeta=0.3
-Dodps.stage.mapper.split.size=1
com.alibaba.algo.PaiSwing
swing_click_input_table/ds=${bizdate}
swing_output/ds=${bizdate}
;弹内classpath的获取方式:
在DataWorks里右击swing资源包,点击“历史版本”获取文件路径(http开头)
参数说明
|
参数名称 |
参数描述 |
参数类型 |
|
common.user.number.threshold |
同时访问的用户数量(过滤力度的设定),设置过大会导致剩下的结果过少,该参数需要根据具体业务场景进行调整探索 |
默认为0 |
|
max.user.per.item |
每个物品使用多少个用户的点击序列来计算k近邻 |
整数,默认值为700 |
|
max.user.behavior.count |
每个用户的最长序列长度,如果超过该长度会对最近进行截断保留 |
整数,默认值为600 |
|
debug.info.print.number |
输出debug信息的记录数 |
整数,默认值为10 |
|
alpha1 |
swing算法参数,见公式[1] |
整数,默认值为5 |
|
beta |
swing算法参数,见公式[1] |
实数,默认值为0.3 |
|
alpha2 |
swing算法参数,见公式[1] |
整数,默认值为1 |
|
user.column.name |
用户或session ID的列名 |
字符串,默认值:"user_id" |
|
item.list.column.name |
{物品ID,Norm}列表字段的列名 |
字符串,默认值:"item_list" |
|
topN |
每个trigger物品保留的k近邻数目 |
整数,默认值为200 |
|
odps.stage.mapper.split.size |
【控制并发数】每个mapper处理的数据量 |
整数,单位M,默认值256 |
|
odps.stage.reducer.num |
【控制并发数】计算物品Pair相似度的reducer的数量 |
整数,默认值为200 |
|
item.delimiter |
input table中item list的分隔符 |
默认值英文分号 |
|
item.field.delimiter |
input table中item info的分隔符 |
默认值英文逗号 |
|
pos_norm |
物品热度所对应字段,从0开始,在上述样例中1 |
整数,默认值为1 |
|
pos_time |
pos_time timestamp对应的字段编号,从0开始,在上述样例中为2 |
整数,默认值为2 |
|
pos_scene |
场景名对应的字段编号,从0开始 |
整数,默认值为3 |
|
target.scene.name |
目标场景名,用于场景i2i建模 |
默认为全网i2i |
|
max.time.span |
认为两个物品存在邻居关系的最长点击间隔天数 |
整数,默认值为1 |
|
do_supplement_by_adamic_adar |
当相似item数量不足topN时,是否尝试用Adamic/Adar算法补足 |
boolean, 默认值为true |
FAQ
1. java.lang.ClassCastException: com.aliyun.odps.io.LongWritable cannot be cast to com.aliyun.odps.io.Text
FAILED: ODPS-0123131:User defined function exception - Traceback:
java.lang.ClassCastException: com.aliyun.odps.io.LongWritable cannot be cast to com.aliyun.odps.io.Text
at com.aliyun.odps.udf.impl.batch.TextBinary.put(TextBinary.java:55)
at com.aliyun.odps.udf.impl.batch.BaseWritableSerde.put(BaseWritableSerde.java:20)
at com.aliyun.odps.udf.impl.batch.BatchUDTFCollector.collect(BatchUDTFCollector.java:54)
at com.aliyun.odps.udf.UDTF.forward(UDTF.java:164)
at com.aliyun.odps.mapred.bridge.LotTaskUDTF.collect(LotTaskUDTF.java:62)
at com.aliyun.odps.mapred.bridge.LotReducerUDTF$ReduceContextImpl.write(LotReducerUDTF.java:167)
at com.aliyun.odps.mapred.bridge.LotReducerUDTF$ReduceContextImpl.write(LotReducerUDTF.java:162)
at com.aliyun.odps.mapred.bridge.LotReducerUDTF$ReduceContextImpl.write(LotReducerUDTF.java:151)
at com.alibaba.algo.Paiswing$swingI2IReducer.reduce(Paiswing.java:346)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.aliyun.odps.mapred.bridge.utils.MapReduceUtils.runReducer(MapReduceUtils.java:160)
at com.aliyun.odps.mapred.bridge.LotReducerUDTF.run(LotReducerUDTF.java:330)
at com.aliyun.odps.udf.impl.batch.BatchStandaloneUDTFEvaluator.run(BatchStandaloneUDTFEvaluator.java:53)输出表的item_id一定要是bigint类型,不能是string类型。注意create table语句的schema信息。
参考文档
基础版Swing算法:Swing算法工具