
swing是一种Item召回算法,您可以使用swing训练组件基于User-Item-User原理衡量Item的相似性。本文为您介绍swing训练的参数配置。
使用限制
支持运行的计算资源为MaxCompute和Flink。
组件配置
您可以通过以下任意一种方式,配置swing训练组件参数。
方式一:可视化方式
在Designer工作流页面配置组件参数。
页签 | 参数名称 | 描述 |
字段设置 | Item列列名 | Item列的名称。 |
User列列名 | User列的名称。 | |
参数设置 | alpha参数 | alpha参数,默认为1.0。 |
item参与计算的人数最大值 | Item参与计算的人数最大值,默认为1000。 说明 当item出现的次数大于该值时,算法会从所有用户中随机抽取的用户数量。 | |
用户互动的最大Item数量 | 用户互动的Item的最大数量,默认为1000。 说明 如果用户参与互动的Item的数量大于该值,则该用户不参与计算过程。 | |
用户互动的最小Item数量 | 用户互动的Item的最小数量,默认为10。 说明 如果用户参与互动的Item的数量小于该值,则该用户不参与计算过程。 | |
结果是否归一化 | 结果是否归一化。 | |
用户alpha参数 | 用户的alpha参数,默认为5.0。 | |
用户beta参数 | 用户的beta参数,默认为-0.35。 | |
执行调优 | 节点个数 | 节点个数,与参数单个节点内存大小配对使用,正整数。范围[1, 9999]。 |
单个节点内存大小,单位M | 单个节点内存大小,单位MB,正整数。范围[1024, 64*1024]。 |
方式二:Python代码方式
使用PyAlink脚本组件配置该组件参数。您可以使用PyAlink脚本组件进行Python代码调用,详情请参见PyAlink脚本。
参数名称 | 是否必选 | 描述 | 默认值 |
itemCol | 是 | Item列的列名。 | 无 |
userCol | 是 | User列的列名。 | 无 |
alpha | 否 | alpha参数,是一个平滑因子。 | 1.0 |
userAlpha | 否 | User的alpha参数。 说明 用于计算用户权重:user weight = 1.0/(userAlpha + userClickCount)^userBeta。 | 5.0 |
userBeta | 否 | User的Beta参数。 说明 用于计算用户权重:user weight = 1.0/(userAlpha + userClickCount)^userBeta。 | -0.35 |
resultNormalize | 否 | 是否归一化。 | false |
maxItemNumber | 否 | Item参与计算的人数最大值。 说明 如果Item出现的次数大于maxItemNumber,则算法会从所有用户中随机抽取maxItemNumber个用户。 | 1000 |
minUserItems | 否 | User互动的Item的最小数量。 说明 如果用户参与互动的Item的数量小于minUserItems,则该用户不参与计算过程。 | 10 |
maxUserItems | 否 | User互动的Item的最大数量。 说明 如果用户参与互动的Item的数量大于maxUserItems,则该用户不参与计算过程。 | 1000 |
Python代码方式的使用示例如下。
df_data = pd.DataFrame([
["a1", "11L", 2.2],
["a1", "12L", 2.0],
["a2", "11L", 2.0],
["a2", "12L", 2.0],
["a3", "12L", 2.0],
["a3", "13L", 2.0],
["a4", "13L", 2.0],
["a4", "14L", 2.0],
["a5", "14L", 2.0],
["a5", "15L", 2.0],
["a6", "15L", 2.0],
["a6", "16L", 2.0],
])
data = BatchOperator.fromDataframe(df_data, schemaStr='user string, item string, rating double')
model = SwingTrainBatchOp()\
.setUserCol("user")\
.setItemCol("item")\
.setMinUserItems(1)\
.linkFrom(data)
model.print()
predictor = SwingRecommBatchOp()\
.setItemCol("item")\
.setRecommCol("prediction_result")
predictor.linkFrom(model, data).print()使用示例
您可以使用swing训练组件构建如下工作流。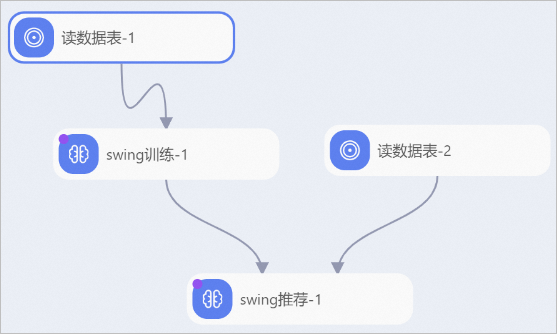 本示例中,您需要按照以下流程配置组件:
本示例中,您需要按照以下流程配置组件:
创建两个MaxCompute表,表1包含userid、itemid字段,表2包含itemid字段,字段类型均为STRING。通过MaxCompute客户端的Tunnel命令将训练数据集和测试数据集分别上传至MaxCompute的表1和表2,再将读数据表-1和读数据表-2的表名参数分别配置为表1和表2。关于MaxCompute客户端的安装及配置请参见使用本地客户端(odpscmd)连接,关于Tunnel命令详情请参见Tunnel命令。
将训练数据集接入swing训练组件,并配置具体参数,详情请参见上文的可视化配置组件参数。
将测试数据集和模型接入swing推荐组件,进行模型预测。