
本文介绍了如何免费体验弹性并行查询ePQ带来的查询加速及性能提升。
背景
PolarDB MySQL版8.0版本重磅推出弹性并行查询(Elastic Parallel Query,ePQ):将一个复杂查询任务拆分为多个子任务,子任务可以被派发到同集群内的任意节点并发完成计算,从而有效利用集群内其他节点的空闲计算资源(CPU、内存等)来加速查询,使查询耗时指数级下降,并有效提升集群的资源利用率。
弹性并行查询(ePQ)的优势如下:
实时性分析:统一的底层存储,数据实时可见
开箱即用:零附加成本和运维成本,随集群部署
性能优异:打通节点间的计算资源,突破单机硬件性能瓶颈,性能表现优异
提升能效:充分利用空闲计算资源,提升集群整体资源利用率
实时弹性:按需扩容,提供更灵活的弹性计算能力
阿里云提供了数据库解决方案功能体验馆,提供真实免费的PolarDB集群环境和开箱即用的测试方法,您可以在线快捷体验ePQ带来的查询效率提升。
影响
本功能体验不涉及生产环境的部署,因此不会影响业务。
费用
本次体验中,由于体验涉及到的资源不归属于您,因此不会产生任何费用,您可以放心体验。
体验内容
体验环境
在本免费体验中,阿里云提供了预置环境供您操作体验,预置环境的详情如下:
集群:提供了一个PolarDB MySQL版集群。具体如下:
内核版本: 8.0.2.2.19.1
产品版本:企业版
系列:集群版通用规格
集群规格:集群包含1个主节点和1个只读节点,规格都为8核 16GB
存储类型: PSL5
参数设置:
parallel_degree_policy参数初始设置为TYPICAL说明当
parallel_degree_policy参数被设定为TYPICAL时,PolarDB在选择查询并行度时将不会考虑数据库的当前负载情况(例如CPU使用率等),而是会尽可能地与max_parallel_degree参数所设定的并行度保持一致。
测试数据集:集群中预置了标准测试集TPCH 100G的数据集,其中具体查询所用的表为part表,数据量为20,000,000条数据。
观测指标
CPU占用率:集群中主节点和只读节点的平均CPU使用率。单位:%。
查询耗时:执行特定SQL所耗费的时间。单位:秒。
操作步骤
进入瑶池解决方案体验馆。
单击核心功能体验,然后单击弹性并行查询-PolarDB查询加速的免费体验按钮,进入如下页面:
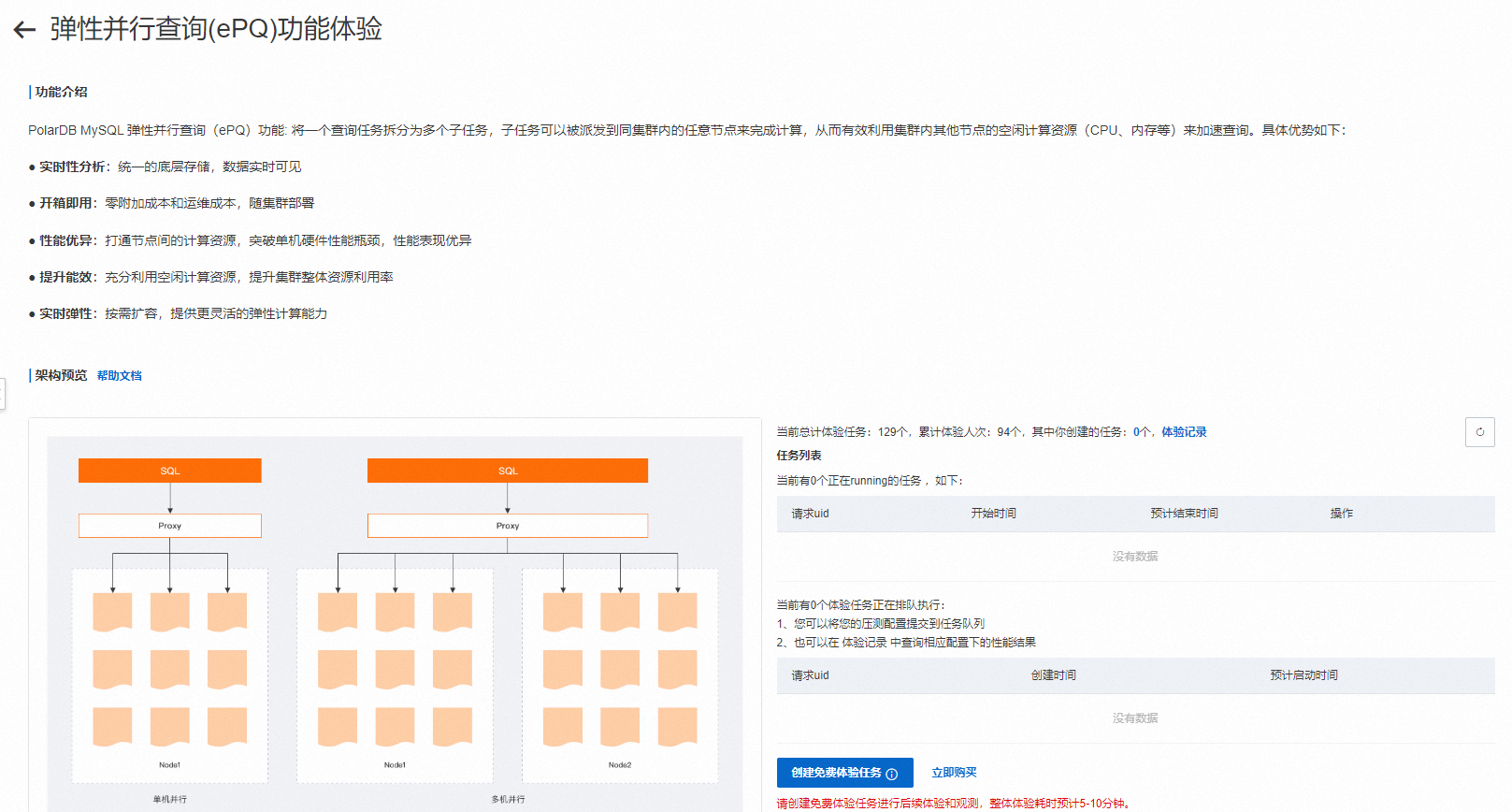
单击页面下方创建免费体验任务按钮。
稍等片刻后,单击
 刷新任务列表,可以看到您创建的体验任务已开始。
刷新任务列表,可以看到您创建的体验任务已开始。
单击查看详情,进入实时查询体验页面。
首先进行未开启ePQ的正常查询任务。
说明请根据页面按钮提示,手动点击按钮执行每一步操作。若在倒计时结束时没有手动点击执行,则会自动执行对应操作。
单击启动任务按钮开始体验。
单击配置查询库按钮,自动向PolarDB集群执行如下命令,切换至
tpch数据库:use tpch;单击配置并行策略为LOCAL按钮,自动执行如下命令,将数据库的并行策略设置为LOCAL,即
set parallel_workers_policy='LOCAL' ;单击配置并行度为0按钮,自动执行如下命令,将数据库的并行度设置为0。
set max_parallel_degree=0;单击查看执行计划按钮,自动执行如下命令,查看如下SQL的执行计划。
explain format=TREE SELECT SUM(p_retailprice), AVG(p_retailprice) -> , MIN(p_retailprice), MAX(p_retailprice) -> FROM part -> GROUP BY p_type -> ORDER BY 1 -> LIMIT 1;执行计划返回如下:
+------------------------------------------------------------------------------+ | EXPLAIN | +------------------------------------------------------------------------------+ | -> Limit: 1 row(s) -> Sort: <temporary>.sum(p_retailprice), limit input to 1 row(s) per chunk -> Table scan on <temporary> -> Aggregate using temporary table -> Table scan on part (cost=2123689.64 rows=19896680) | +------------------------------------------------------------------------------+ 1 row in set (0.00 sec)可以看到,在正常的查询计划中,表扫描和聚集计算都是在一个线程中串行完成。
单击执行SQL按钮,自动执行上一步执行计划中的SQL:
SELECT SUM(p_retailprice), AVG(p_retailprice) -> , MIN(p_retailprice), MAX(p_retailprice) -> FROM part -> GROUP BY p_type -> ORDER BY 1 -> LIMIT 1;返回结果如下,执行时间为22.47秒。
+--------------------+--------------------+--------------------+--------------------+ | SUM(p_retailprice) | AVG(p_retailprice) | MIN(p_retailprice) | MAX(p_retailprice) | +--------------------+--------------------+--------------------+--------------------+ | 198461679.87 | 1498.366804 | 901.47 | 2098.51 | +--------------------+--------------------+--------------------+--------------------+ 1 row in set (22.47 sec)整个过程中,您可以在左侧趋势图中观测集群平均CPU使用率的变化情况。
在正常查询完成后,任务将自动切至ePQ查询任务。请根据页面按钮提示,手动点击按钮执行每一步操作。若在倒计时结束时没有手动点击执行,则会自动执行对应操作。
单击配置跨机并行查询按钮,自动执行如下命令,开启ePQ功能。
set parallel_workers_policy='MULTI_NODES';单击配置并行度为4按钮,自动执行如下命令,设置ePQ的并行度为4。
set max_parallel_degree=4;单击查看执行计划按钮,自动执行如下命令,查看相同SQL的执行计划。
explain format=TREE SELECT SUM(p_retailprice), AVG(p_retailprice) -> , MIN(p_retailprice), MAX(p_retailprice) -> FROM part -> GROUP BY p_type -> ORDER BY 1 -> LIMIT 1;执行计划返回如下:
+-----------------------------------------------------------------------------------------------------------------------------------+ | EXPLAIN | +-----------------------------------------------------------------------------------------------------------------------------------+ | -> Limit: 1 row(s) (cost=2026377.94 rows=1) -> Gather (merge sort; slice: 1; workers: 8; nodes: 2) (cost=2026377.94 rows=8) -> Limit: 1 row(s) (cost=2026366.65 rows=1) -> Sort: <temporary>.sum(p_retailprice), limit input to 1 row(s) per chunk (cost=2026366.65 rows=248708) -> Table scan on <temporary> -> Aggregate using temporary table (cost=2026366.65 rows=248708) -> Repartition (hash keys: part.p_type; slice: 2; workers: 8; nodes: 2) (cost=1767690.54 rows=248709) -> Table scan on <temporary> -> Aggregate using temporary table (cost=1732861.35 rows=248708) -> Parallel table scan on part, with parallel partitions: 798 (cost=265461.20 rows=2487085) | +-----------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)可以看到,在ePQ下的查询中,该查询中的表扫描和聚集计算均被下推到了2个节点一共8个worker线程中并发计算。
单击执行SQL按钮,自动执行该SQL:
SELECT SUM(p_retailprice), AVG(p_retailprice) -> , MIN(p_retailprice), MAX(p_retailprice) -> FROM part -> GROUP BY p_type -> ORDER BY 1 -> LIMIT 1;返回结果如下,执行时间为2.82秒。
+--------------------+--------------------+--------------------+--------------------+ | SUM(p_retailprice) | AVG(p_retailprice) | MIN(p_retailprice) | MAX(p_retailprice) | +--------------------+--------------------+--------------------+--------------------+ | 198461679.87 | 1498.366804 | 901.47 | 2098.51 | +--------------------+--------------------+--------------------+--------------------+ 1 row in set (2.82 sec)整个执行SQL的过程中,您可以在左侧趋势图中观测集群平均CPU使用率的变化情况。
说明由于实时监控数据可能存在延迟,为了确保展示完整的CPU变化情况,趋势图中会在SQL执行完后,自动延长一定监控时间(2~3秒)。
(可选)对于已创建的任务,您可以在弹性并行查询ePQ页面,单击体验记录,在弹出的面板中,单击全部任务或我的任务,查看体验结果详情。
结果分析
ePQ极大地提升了查询效率
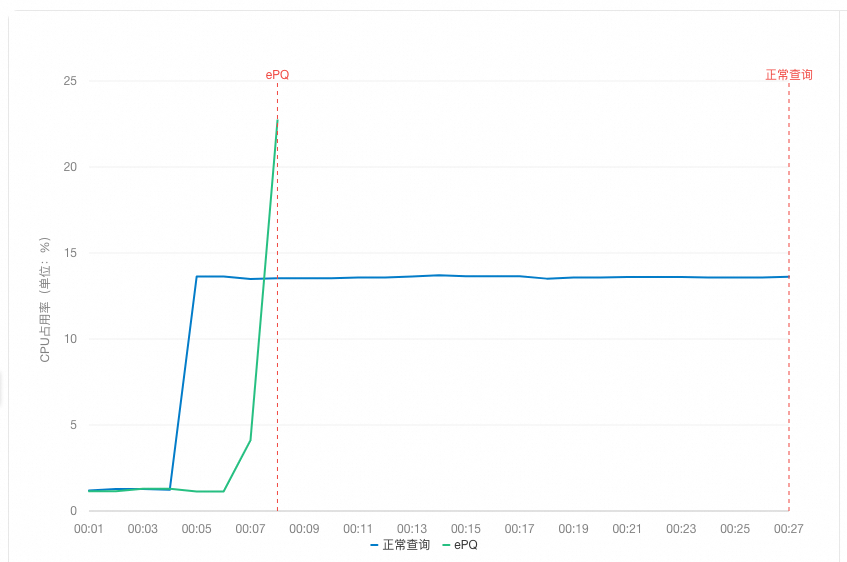
从执行时间上看,当开启ePQ后,复杂查询的执行时间大幅缩短,从22.47秒缩短至2.82秒。
从执行计划上看,执行的SQL语句是进行SUM聚集计算。
在正常查询的执行计划中,该查询中表扫描和聚集计算都是在一个线程中串行完成;
在ePQ查询的执行计划中,该查询中表扫描和聚集计算均被下推到了2个节点共8个worker线程中并发计算。
ePQ充分利用空闲计算资源,提升了集群整体资源利用率
从集群平均CPU占用率上看,ePQ查询下的CPU占用率比正常查询高。这是因为开启ePQ后,充分利用空闲计算资源,让空闲的计算节点也加入计算。
由于实时监控数据可能存在延迟,为了确保展示完整的CPU变化情况,趋势图中会在SQL执行完后,自动延长一定监控时间(2~3秒)。
在实际应用场景中,您可以自由设置并行度,从而实现对CPU占用率的调控。
相关内容
专家面对面
您可以加入官方钉钉群进行咨询,获取更多技术支持。钉钉群号:12810035247。