
冷数据归档功能可以为您有效的降低数据存储成本,同时保证查询性能,本文为您介绍TTL的技术原理。
名词解释
名词 | 说明 |
TTL | 在数据库领域中,TTL 是 "Time To Live" 的缩写,直译为"(数据的)存活时间",即数据存储在数据库中可以保存的时间长度,在这段时间之后,数据会被自动清理。 |
在线表 | 承载业务在线流量的业务表,通常存储在PolarDB-X实例的本地盘中。 |
TTL表 | 指所有被显式设置了TTL定义的逻辑表。 |
行存表 | 指对过期的冷数据进行清理后只保留在线热数据的TTL表。 |
归档表 | 指专于保存已归档历史数据的表,通常保存在高压缩低成本的存储介质中,例如对象存储(OSS)。 |
提前归档 | TTL表中的所有数据,无论是否已达到归档的时间点,都提前归档存储到OSS。 |
定期清理 | TTL表基于定时任务,清理TTL表中满足归档时间点的过期数据。 |
冷数据(过期数据) | 指基于TTL定义,在线表中存活时间超过指定的时间长度,且允许被自动清理的过期数据。 |
归档表列存索引 | 指专用与保存历史归档数据的列存索引,列存索引的数据存储格式默认具有高压缩率,适用于以低成本存储海量的历史数据,该列存索引通过订阅主表产生Binlog日志实现与主表数据的准实时同步。 |
背景
在实际生产中,有些业务只希望保留最近一段时间的数据(热数据),并对于使用频率很低且不断积累的过期数据(冷数据)采用存储成本更低的方式保存,同时又可以利用这些冷数据进行分析统计业务。综上所述,业务对处理冷数据,主要有以下需求:
可以定时清理冷数据。
更低的冷数据存储成本。
归档后仍然可以供后台业务进行分析统计。
PolarDB-X 2.0企业版为您提供了冷数据归档(TTL)能力,可以有效地解决上述问题。
冷数据归档功能介绍
技术架构
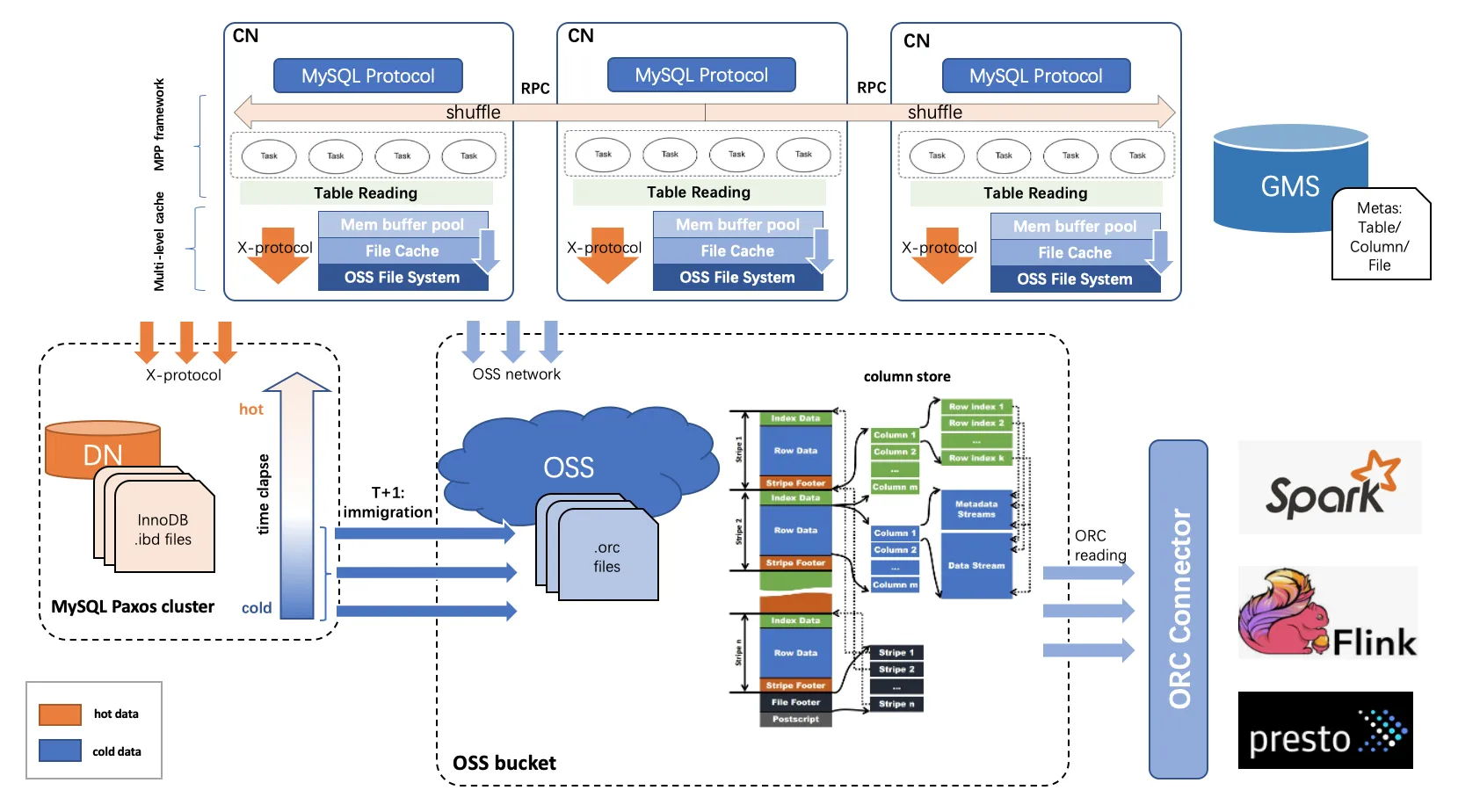
为了降低不断累积的历史数据的存储成本,PolarDB-X 2.0企业版为您提供冷数据归档功能,区别于之前数据默认存储在本地盘,冷数据归档功能可以把数据按照时间维度将数据分为冷热数据,并且把过期的冷数据从源表中剥离出来,归档至成本更低的对象存储(OSS)中,归档的数据也可以提供应用查询。
冷数据以列存格式存储在远程OSS对象存储上,热数据依然以行存格式存储在本地盘上。
一张在线表完成冷数据归档后,会形成行存表和归档表,其中:
行存表:即原来的业务表,但仅保留近期的热数据,数据存储在本地盘。
归档表:即原来的业务表的归档列存索引,存储所有过期的冷数据,数据存储于OSS。
在线表完成归档后,归档表在主实例与列存只读实例上均可以被直接查询。但归档表表名和行存表表名,在主实例与列存只读实例上的处理情况有如下区别:
主实例:归档表表名与行存表表名并不一样,归档表表名实质是一个查询图视的名字,这主要是归档表的查询性能通常不如行存表,两者对于查询SLA(并发数、查询RT等)并不一样。因此业务需要明确指定归档表或行存表进行查询。
列存只读实例:归档表表名与行存表表名是一样(可以像访问行存表一样访问归档表),应用可以直接用原业务表表名查询冷数据,通常在列存只读实例,查询归档表的性能比在主实例好,更适合满足复杂分析型查询的场景,因此若需要经常查询归档表数据的,建议使用列存只读实例。
冷数据压缩率
归档表按列存组织数据并存储于OSS,并且归档表的各个列均会进行数据压缩。通常情况下同样数据量,归档表的列存数据存储空间只有原来的行存的5%~10%左右。
冷数据存储费用
冷数据存储空间为单独计费,且仅支持按量付费模式,收费标准如下:
付费方式 | 存储价格 |
按量付费 | 0.000167元/GB/小时 |
基于列存索引的冷数据归档方案
列存归档的特点
PolarDB-X 2.0企业版提供的列存索引(CCI)功能,具备将行存InnoDB存储的数据实时同步到列存索引的OSS存储,能向业务提供低成本、高压缩率、实时性高、完全兼容MySQL、一体化透明的HTAP的能力。
基于OSS按列组织及存储数据,列存索引具备以下的三大特点:
高压缩率:列存索引是按表的各个列来组织和存储数据的,能针对各个列的数据类型自动选择最优的数据压缩算法,从而使整体数据存储具有很高的压缩率。
低存储成本:对象存储(OSS)本身的存储成本很低,具有良好的性价比。
实时性高、强一致性:列存索引是通订阅增量Binlog ,保持与主表的实时同步,列存索引会冗余主表的所有列,可以看作主表的一个只读副本(或镜像表)。
基于列存索引的冷数据归档方案,不仅能够一体化地解决了业务对冷数据的各种归档需求,也因继承了列存索引的若干优秀特性,使得冷数据归档方案具有以下几点明显优势:
冷数据基于订阅Binlog完成OSS归档,数据归档过程不会对线上业务产生任何影响(例如:不会有加锁阻塞、IO/CPU资源占用等现象)。
归档后的冷数据具有实时性高、强一致性特性,支持业务通过列存只读进行轻量级的AP查询。
归档后的冷数据具有高压缩率(平均压缩率大约是1/20~1/10),存储成本低。
冷数据归档的整体方案
冷数据归档主要由以下两步完成:
冷数据的转存:所有被清理的冷数据能够统一地迁移到成本更低、压缩率高更的存储,实现数据归档。
冷数据的清理:自动(或手动)清理业务表的过期的冷数据,最后只保留由业务所定义的最近一段时间的热数据。
与其它云数据库产品采用常规的“一边归档、一边清理”的归档方案不同,PolarDB-X 2.0企业版的冷数据归采用的是“提前归档、定期清理”的归档方案。
提前归档:
通过给在线表构建对应的列存索引,并将列存索引作为保存冷数据专用的归档表。在线表利用构建列存索引的能力,不仅会将所有存量数据上传到归档表的OSS存储,而且还能利用归档表列存索引的实时订阅在线表Binlog变更能力,使在线表所有的增量写入也全部实时同步到归档表的OSS存储。因此,在此阶段,在线表的所有数据,无论数据是否满足归档时间点,包括存量、增量的数据,都会全部上传到OSS存储,从而实现“提前归档”的效果。当用于保存归档数据的归档表创建完成后,冷数据归档的第一个目标,即冷数据的转存,已实质完成。

定期清理:
当业务表的所有数据已完成归档后,您可以通过自动或手动的方式,触发业务表预定义的TTL任务来清理过期数据。该TTL任务的内部会使用DELETE的DML语句(按行归档)或使用DROP PARTITION的DDL语句(按分区归档)对过期数据实施清理。该TTL任务在清理数据时,会生成含特殊标记的Binlog日志,这类Binlog日志会被列存节点直接忽略,因此,在线表的TTL任务所产生的DELETE操作(按行归档)或DROP PARTITION操作(按分区归档)不会对归档表的数据产生任何影响,从而使TTL任务达到只清理在线表中的过期数据,而不清理归档表的数据的效果。如此,冷数据归档第的第二个目标,冷数据的清理就完成了。

归档策略:
按照TTL表清理过期数据所采用的方案的不同,TTL表支持以下两种归档策略:


冷数据的归档过程
在创建TTL表对应的归档表时,其本质是在创建列存索引的过程,期间列存节点不仅会基于快照读将TTL表的存量数据上传至归档表的OSS存储中,还会实时订阅TTL表的Binlog,以此实时执行增量数据的行转列转换,并上传增量更新到归档表的OSS存储中。如下图所示:

TTL表冷数据清理算法
TTL表有以下两种数据清理策略:
按行清理:通过
DELETE的DML操作完成过期数据清理。按分区清理:通过删除RANGE分区的DDL操作完成过期数据清理。
按行清理
默认采用从前往后逐渐清理的算法,清理过程总是先清理表里最早时间的数据,反复多轮清理后即可动态保留最近一段时间的数据。
按行清理由于使用了DML语句及分布式事务,因此会产生行锁及Binlog日志。每天定时调度的TTL任务为避免在清理数据过程中,产生范围过大行锁或占用过多的CPU/IO资源,系统会自动根据TTL列的最小值计算合适的小范围时间区间并用于清理。
由于按行清理使用DELETE语句清理过期数据时会产生大量Binlog,若应用下游有通过PolarDB-X CDC订阅Binlog的需求,可以在主实例执行如下SQL,以使CDC自动过滤清理过程中产生的DELETE Binlog日志:
SET CDC GLOBAL TASK_EXTRACT_FILTER_ARCHIVE_ENABLED = TRUE;
STOP MASTER;
START MASTER;该SQL需使用高权限账号执行,且仅支持不含普通列存索引的TTL表,切勿在有列存索引的TTL表上执行此SQL。生效后,Binlog将不再生成由TTL表引发的DELETE删除事件。请在确认所有下游系统均不需要同步这些DELETE事件后,再执行此SQL。
清理范围算法
假设有TTL定义TTL_EXPR = `time` EXPIRE AFTER <NUM> MONTH TIMEZONE '+08:00',则该定义表示TTL表会保留最近NUM个月的数据,那么得出每轮清理任务的上边界如下:
// 清理时间区间的目标上界
CleanupMaxUpperBound = Now - ExpiredDataInterval
// 本轮清理时间区间的上界
CleanupUpperBound = MIN((MinValue + CleanupDataInterval), (Now - ExpiredDataInterval))参数说明:
参数 | 含义 | 详细说明 |
MinValue | TTL时间列的最小值经过时间颗粒调整后产生的值。 | 时间颗粒度调整指的是根据TTL定义的过期时间间隔单位
需要注意的是,当
|
Now | 当前时间经过时间颗粒调整后产生的值。 | |
CleanupDataInterval | 每轮清理数据所涉及的时间范围区间的长度。 | 计算方法为 |
ExpiredDataInterval | TTL表数据的保留时间。 | 例如: |
数据清理示例
示例TTL定义,且假设当前时间为2023-10-01:
CREATE TABLE `tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
PARTITION BY KEY(`id`)
PARTITIONS 8;
ALTER TABLE `tbl`
MODIFY TTL
SET
TTL_EXPR = `time` EXPIRE AFTER 1 MONTH TIMEZONE '+08:00';清理过程如下图所示:

Day 1:
TTL定义的时间列其最小时间值为2022-10-05(MinValue),再根据清理的时间范围(CleanupDataInterval,本例中为3个月)得出本轮清理的范围为2022-10-05≤Time<2023-01-01。以此类推其他清理范围分别是2023-01-01≤Time<2023-04-01、2023-04-01≤Time<2023-07-01、2023-07-01≤Time<2023-09-01。
Day 2:
同Day 1,清理时间列满足2023-01-01≤Time<2023-04-01条件的数据,即2023-04-01为本轮清理任务的上边界(CleanupUpperBound)。
Day 3:
同Day 1,清理时间列满足2023-04-01≤Time<2023-07-01条件的数据,即2023-07-01为本轮清理任务的上边界(CleanupUpperBound)。
Day 4:
与之前略有不同,清理时间列满足2023-07-01≤Time<2023-09-01条件的数据,时间范围为2个月。因为上图中假设的当前时间为2023-10-01(Now),且TTL表被设置为保留最近1个月(ExpiredDataInterval,TTL表的数据存活时间)的数据,所以本轮只能清理2023-09-01之前的数据,即2023-09-01为本轮清理任务的上边界(CleanupUpperBound)。
按分区清理
对于按分区归档的场景,根据不同的分区过期策略,会采用不同的清理逻辑:
按固定时间间隔过期:TTL任务根据TTL定义所设置数据过期的时间间隔,结合当前最新时间,计算出用于当前清理的目标时间区间,然后扫描所有Range分区,如果分区里的数据完全落在目标时间区间内,则该分区被视为过期分区并被删除。
按固定分区数目过期:TTL任务根据TTL定义所设置保留Range分区数目,从最小的Range分区开始,逐个分区判定过期,直到剩余分区数目刚好等于TTL所指定的保留分区数目。
按固定时间间隔过期示例
创建RANGE分区表
tbl:CREATE TABLE `tbl_range` (`time` DATETIME) PARTITION BY RANGE (`time`) ( PARTITION p20231001 VALUES LESS THAN('2023-10-01'), PARTITION p20231101 VALUES LESS THAN('2023-11-01'), PARTITION p20231201 VALUES LESS THAN('2023-12-01'), PARTITION p20240101 VALUES LESS THAN('2024-01-01') );tbl表指定如下的TTL定义:ALTER TABLE `tbl_range` MODIFY TTL SET TTL_EXPR = `time` EXPIRE AFTER 1 MONTH TIMEZONE '+08:00', TTL_PART_INTERVAL = INTERVAL(1, MONTH), ARCHIVE_TYPE = 'PARTITION';说明tbl的过期时间间隔为1个月,分区间隔为一个月,且是一级分区。清理过程如图所示:
 说明
说明如上图所示,当新一轮TTL任务运行时,若当前时间是
2023-12-03, 那么当前时间会按分区间隔单位MONTH先截断为2023-12-01,然后再减去过期时间间隔1个月,最终实际的过期时间点是2023-11-01。所以,分区p20231101与p20231001因其所有数据都满足time < '2023-11-01'的过期条件,它们都会被判定为过期分区并被删除。此外,TTL任务会在正式删除过期分区p20231101与p20231001之前,提前检查并按需自动补充新的Range分区p20240201。

按固定分区数目过期示例
该过期策略通常适用于TTL列为整数类型。
创建按照整数分4个分区的表
tbl:CREATE TABLE `tbl_int` (`uid` BIGINT) PARTITION BY RANGE (`uid`) ( PARTITION p2000000 VALUES LESS THAN(2000000), PARTITION p3000000 VALUES LESS THAN(3000000), PARTITION p4000000 VALUES LESS THAN(4000000), PARTITION p5000000 VALUES LESS THAN(5000000) );tbl的TTL定义:ALTER TABLE `tbl_int` MODIFY TTL SET TTL_EXPR = `uid` EXPIRE OVER 2 PARTITIONS, TTL_PART_INTERVAL = INTERVAL(1000000, NUMBER), ARCHIVE_TYPE = 'PARTITION';说明上述TTL表
tbl的Range分区间隔是一个分区1000000,最多保留2个分区,且按一级分区归档。清理过程如下图所示:
说明如上图所示,
p2000000、p3000000、p4000000与p5000000是TTL表tbl的当前已创建的RANGE分区。当新一轮TTL任务运行时,根据保留的最大分区数目,TTL任务优先从最小的分区p2000000开始数起,逐个分区判定是否过期,直到剩余分区数目为2个(即p4000000与p5000000),从而计算出待清理的过期分区集合(p2000000与p3000000)。之后,TTL任务在正式删除过期分区时,还会先自动补充完新的分区(p6000000),最后将过期分区删除。
