
JOIN是将多个表以某个或某些列为条件进行连接操作而检索出关联数据的过程,多个表之间以共同列关联在一起。本文主要介绍PolarDB-X如何优化和执行JOIN。
基本概念
JOIN是SQL查询中常见的操作,逻辑上说,它的语义等价于将两张表做笛卡尔积,然后根据过滤条件保留满足条件的数据。JOIN多数情况下是依赖等值条件做的JOIN,即Equi-Join,用来根据某个特定列的值连接两张表的数据。
子查询是指嵌套在SQL内部的查询块,子查询的结果作为输入,填入到外层查询中,从而用于计算外层查询的结果。子查询可以出现在SQL语句的很多地方,比如在SELECT子句中作为输出的数据,在FROM子句中作为输入的一个视图,在WHERE子句中作为过滤条件等。
本文讨论的均为不下推的JOIN算子。如果JOIN被下推到LogicalView中,其执行方式由存储层MySQL自行选择。
JOIN类型
PolarDB-X支持Inner Join,Left Outer Join和Right Outer Join这3种常见的JOIN类型。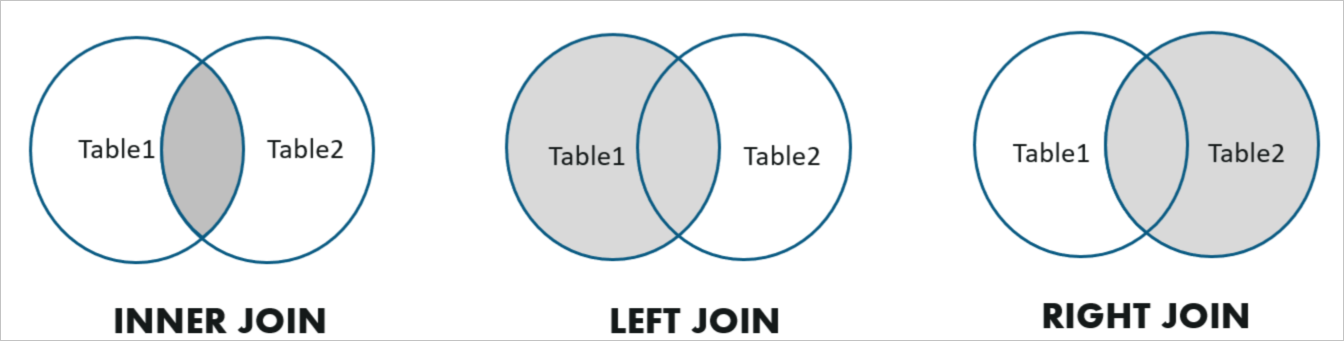 下面是几种不同类型JOIN示例:
下面是几种不同类型JOIN示例:
/* Inner Join */
SELECT * FROM A, B WHERE A.key = B.key;
/* Left Outer Join */
SELECT * FROM A LEFT JOIN B ON A.key = B.key;
/* Right Outer Join */
SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key;还支持Semi-Join和Anti-Join。Semi Join和Anti Join无法直接用SQL语句来表示,通常由包含关联项的EXISTS或IN子查询转换得到。如下为Semi-Join和Anti-Join的示例。
/* Semi Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName IN (
SELECT DeptName FROM Dept
)
/* Semi Join - 2 */
SELECT * FROM Emp WHERE EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)
/* Anti Join - 1 */
SELECT * FROM Emp WHERE Emp.DeptName NOT IN (
SELECT DeptName FROM Dept
)
/* Anti Join - 2 */
SELECT * FROM Emp WHERE NOT EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)JOIN算法
目前,PolarDB-X支持Nested-Loop Join、Hash Join、Sort-Merge Join和Lookup Join(BKAJoin)等JOIN算法。
Nested-Loop Join (NLJoin)
Nested-Loop Join通常用于非等值的JOIN。它的工作方式如下:
拉取内表(右表,通常是数据量较小的一边)的全部数据,缓存到内存中。
遍历外表数据,对于外表的每行:
对于每一条缓存在内存中的内表数据。
构造结果行,并检查是否满足JOIN条件,如果满足条件则输出。
如下为Nested-Loop Join示例:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey < s_suppkey; NlJoin(condition="ps_suppkey < s_suppkey", type="inner") Gather(concurrent=true) LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`") Gather(concurrent=true) LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")
通常来说,Nested-Loop Join是效率最低的JOIN操作,一般只有在JOIN条件不含等值(例如上面的例子)或者内表数据量极小的情况下才会使用。通过如下Hint可以强制PolarDB-X使用Nested-Loop Join以及确定JOIN顺序:
/*+TDDL:NL_JOIN(outer_table, inner_table)*/ SELECT ...其中inner_table 和outer_table也可以是多张表的JOIN结果,例如:
/*+TDDL:NL_JOIN((outer_table_a, outer_table_b), (inner_table_c, inner_table_d))*/ SELECT ...Hash Join
Hash Join是等值JOIN最常用的算法之一。它的原理如下所示:
拉取内表(右表,通常是数据量较小的一边)的全部数据,写进内存中的哈希表。
遍历外表数据,对于外表的每行:
根据等值条件JOIN Key查询哈希表,取出0-N匹配的行(JOIN Key相同)。
构造结果行,并检查是否满足JOIN条件,如果满足条件则输出。
Hash Join示例:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey; HashJoin(condition="ps_suppkey = s_suppkey", type="inner") Gather(concurrent=true) LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`") Gather(concurrent=true) LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")
Hash Join常出现在JOIN数据量较大的复杂查询、且无法通过索引Lookup来改善,这种情况下Hash Join是最优的选择。例如上面的例子中,partsupp表和supplier表均为全表扫描,数据量较大,适合使用HashJoin。由于Hash Join的内表需要用于构造内存中的哈希表,内表的数据量一般小于外表。通常优化器可以自动选择出最优的JOIN顺序。如果需要手动控制,也可以通过下面的Hint。
通过如下Hint可以强制PolarDB-X使用Hash Join以及确定JOIN顺序:
/*+TDDL:HASH_JOIN(table_outer, table_inner)*/ SELECT ...Lookup Join (BKAJoin)
Lookup Join是另一种常用的等值JOIN算法,常用于数据量较小的情况。它的原理如下:
遍历外表(左表,通常是数据量较小的一边)数据,对于外表中的每批(例如1000行)数据。
将这一批数据的JOIN Key拼成一个IN (....)条件,加到内表的查询中。
执行内表查询,得到JOIN匹配的行。
借助哈希表,为外表的每行找到匹配的内表行,组合并输出。
Lookup Join (BKAJoin)示例:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey AND ps_partkey = 123;
BKAJoin(condition="ps_suppkey = s_suppkey", type="inner")
LogicalView(tables="partsupp_3", sql="SELECT * FROM `partsupp` AS `partsupp` WHERE (`ps_partkey` = ?)")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` WHERE (`s_suppkey` IN ('?'))")Lookup Join通常用于外表数据量较小的情况,例如上面的例子中,左表partsupp由于存在ps_partkey = 123的过滤条件,仅有几行数据。此外,右表的s_suppkey IN ( ... )查询命中了主键索引,这也使得Lookup Join的查询代价进一步降低。
通过如下Hint可以强制PolarDB-X使用LookupJoin以及确定JOIN顺序:
/*+TDDL:BKA_JOIN(table_outer, table_inner)*/ SELECT ...Lookup Join的内表只能是单张表,不可以是多张表JOIN的结果。
Sort-Merge Join
Sort-Merge Join是另一种等值JOIN算法,它依赖左右两边输入的顺序,必须按JOIN Key排序。它的原理如下:
开始Sort-Merge Join之前,输入端必须排序(借助MergeSort或MemSort)。
比较当前左右表输入的行,并按以下方式操作,不断消费左右两边的输入:
如果左表的JOIN Key较小,则消费左表的下一条数据。
如果右表的JOIN Key较小,则消费右表的下一条数据。
如果左右表JOIN Key相等,说明获得了1条或多条匹配,检查是否满足JOIN条件并输出。
Sort-Merge Join示例:
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey ORDER BY s_suppkey;
SortMergeJoin(condition="ps_suppkey = s_suppkey", type="inner")
MergeSort(sort="ps_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp` ORDER BY `ps_suppkey`")
MergeSort(sort="s_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` ORDER BY `s_suppkey`")上面执行计划中的 MergeSort算子以及下推的ORDER BY,这保证了Sort-Merge Join两边的输入按JOIN Key即s_suppkey (ps_suppkey)排序。
Sort-Merge Join由于需要额外的排序步骤,通常Sort-Merge Join并不是最优的。但是,某些情况下客户端查询恰好也需要按JOIN Key排序(上面的例子),这时候使用Sort-Merge Join是较优的选择。
通过如下Hint可以强制PolarDB-X使用Sort-Merge Join
/*+TDDL:SORT_MERGE_JOIN(table_a, table_b)*/ SELECT ...JOIN顺序
在多表连接的场景中,优化器的一个很重要的任务是决定各个表之间的连接顺序,因为不同的连接顺序会影响中间结果集的大小,进而影响到计划整体的执行代价。
例如,对于4张表JOIN(暂不考虑下推的情形),JOIN Tree可以有如下3种形式,同时表的排列又有4! = 24种,一共有72种可能的JOIN顺序。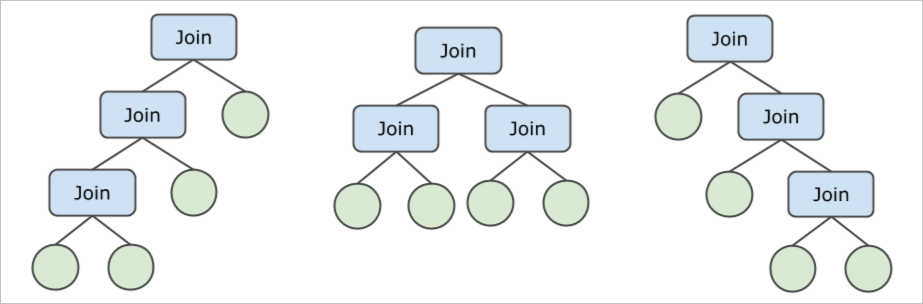
给定N个表的JOIN,PolarDB-X采用自适应的策略生成最佳JOIN计划:
当(未下推的)N较小时,采取Bushy枚举策略,会在所有JOIN顺序中选出最优的计划。
当(未下推的)表的数量较多时,采取Zig-Zag(锯齿状)或Left-Deep(左深树)的枚举策略,选出最优的Zig-Zag或Left-Deep执行计划,以减少枚举的次数和代价。
PolarDB-X使用基于代价的优化器(Cost-based Optimizer,CBO)选择出总代价最低的JOIN 顺序。详情参见查询优化器介绍
此外,各个JOIN算法对左右输入也有不同的偏好,例如,Hash Join中右表作为内表用于构建哈希表,因此应当将较小的表置于右侧。这些也同样会在CBO中被考虑到。
PolarDB-X支持了上述比较丰富的Join算法,优化器会根据统计信息选择相对于合理的Join算法。这里罗列下各个Join算法比较适合的场景。
JOIN算法 | 使用场景 |
NLJoin | 非等值JOIN场景。 |
HashJoin | 大部分等值Join都倾向于选择HashJoin,除非数据有严重倾斜。 |
BKAJoin | 外表数据量较小,内表数据比较大。 |
Sort-Merge-Join | 当数据严重倾斜或者数据输入已经是有序的时候优先选择Sort-Merge-Join。 |