
添加Serverless Spark数据源用于连通阿里云Serverless Spark数据库与Quick BI,连接成功后,您可以在Quick BI上进行数据的分析与展示。本文为您介绍如何添加阿里云Serverless Spark数据源。
前提条件
已创建阿里云E-MapReduce Serverless Spark版数据库,具体操作说明请参见EMR Serverless Spark。
操作步骤
添加白名单。
公网连接阿里云Serverless Spark数据库之前,需要将Quick BI的IP地址加入到阿里云Serverless Spark数据库的白名单中。添加阿里云Serverless Spark数据库白名单的操作请参见设置白名单。
登录Quick BI控制台。
从创建数据源入口进入创建数据源界面。
在阿里云数据库页签下,选择 E-MapReduce Serverless Spark版 数据源。

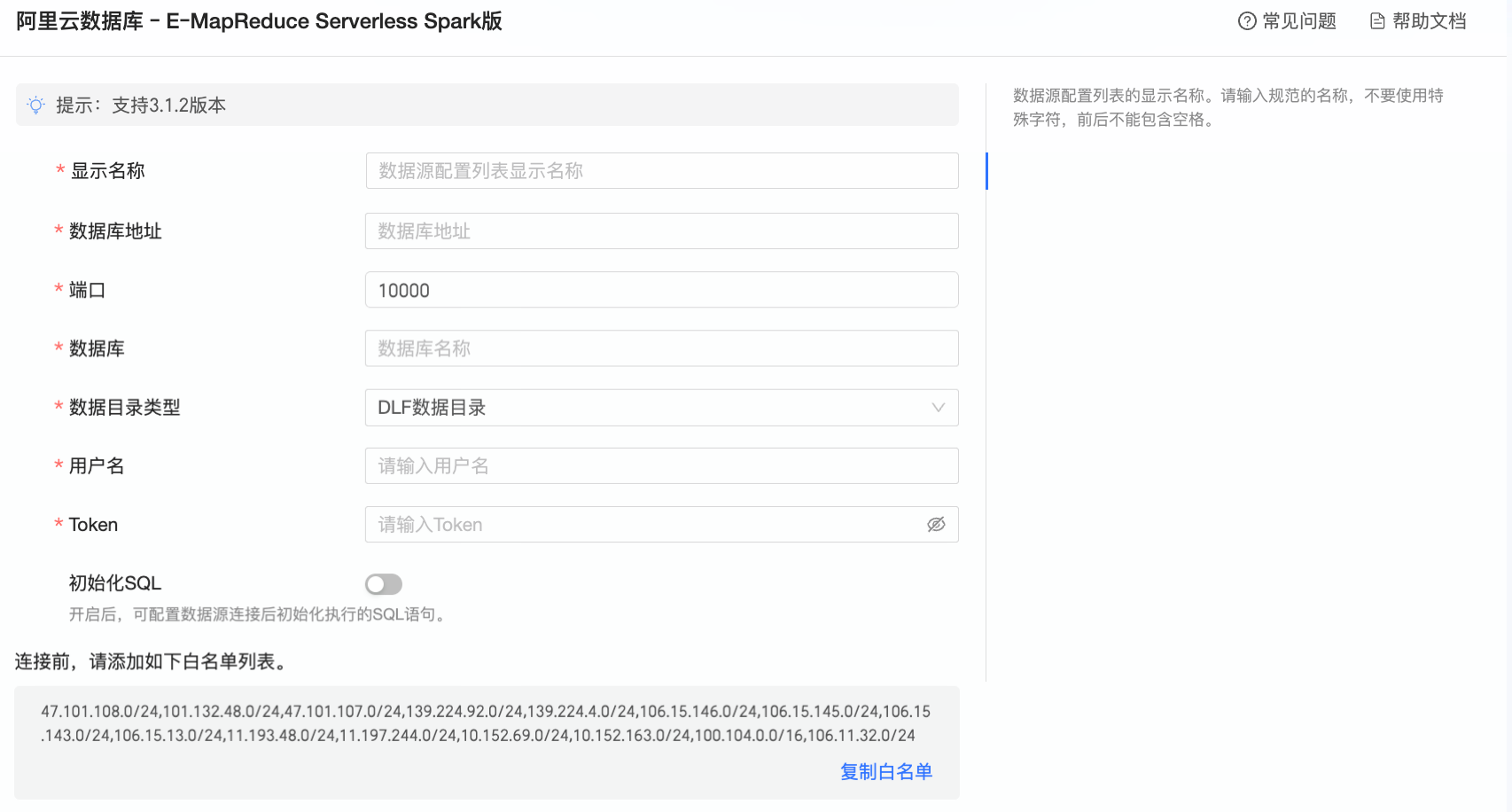
在配置连接对话框,您可以根据业务场景,完成以下配置。
名称
描述
显示名称
数据源配置列表的显示名称。
请输入规范的名称,不要使用特殊字符,前后不能包含空格。
数据库地址
访问E-MapReduce Serverless Spark数据库的公网地址(目前仅支持通过公网连接E-MapReduce Serverless Spark)。
请登录E-MapReduce管理控制台,在Kyuubi Gateway页面的详情总览页内,获取endpoint。例:emr-xxxxxxxxxxxxxxxxx.aliyuncs.com。
端口
数据库对应的端口号,默认为443。
数据库
需要连接的数据库名称。
数据目录类型
E-MapReduce Serverless Spark数据库所在的数据目录类型,支持选择DLF数据目录、其他。
用户名/Token名称
当数据目录类型为DLF数据目录时,您需要在此处填写您在访问控制中添加的RAM用户或RAM角色,使用前需提前进行授权。
说明请确保该用户具备数据库中表的create、insert、 update和delete权限。具体操作说明请参见通过Kyuubi Token对DLF数据的权限管控。
当数据目录类型为其他时,您需要在此处填写访问EMR Serverless Spark数据库的Token名称。请登录E-MapReduce管理控制台,在Gateway页面的Token页内获取名称。
Token
访问E-MapReduce Serverless Spark数据库的Token。
请登录E-MapReduce管理控制台,在Gateway页面的Token页内,获取Token。
初始化SQL
开启后,可配置数据源连接后初始化执行的SQL语句。
每次数据源连接后初始化执行的SQL语句,只允许SET语句,语句之间以分号分割。
单击连接测试,进行数据源连通性测试。
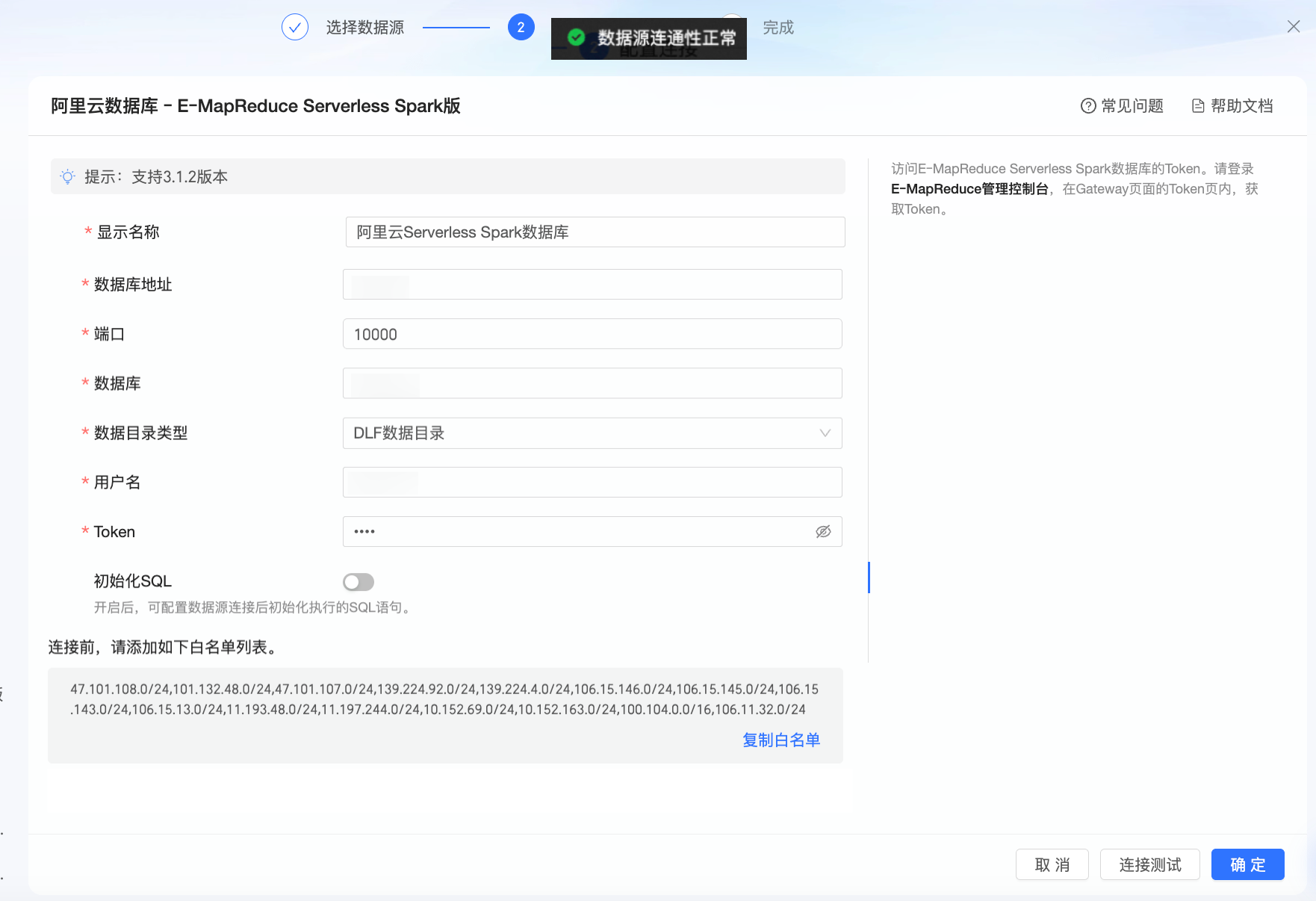
测试成功后,单击确定,完成数据源的添加。
后续步骤
创建数据源后,您还可以创建数据集并分析数据。
将阿里云Serverless Spark数据库中的数据表或自建的自定义SQL添加到Quick BI,请参见创建数据集。
钻取并深度分析数据,请参见步骤三:钻取设置与展示。