本文介绍如何创建Logtail采集配置来采集MySQL查询结果。
前提条件
-
已在服务器上安装Linux Logtail 0.16.0及以上版本或Windows Logtail 1.0.0.8及以上版本。具体操作,请参见安装、运行、升级、卸载Logtail。
重要请确保用于安装Logtail的服务器可连接目标MySQL数据库。
-
在MySQL数据库中,设置白名单为Logtail所在服务器的IP地址。
例如RDS MySQL数据库的白名单设置,请参见设置IP白名单。
-
使用CRD-AliyunPipelineConfig采集MySQL查询结果,需要确保集群已经安装Logtail组件。
具体操作,请参见安装Logtail组件。
操作步骤
日志服务控制台
登录日志服务控制台。
单击控制台页面右侧的快速接入数据卡片。

-
在接入数据页面,选择 MySQL查询结果-插件 。
-
选择目标Project和Logstore,单击下一步。
-
在机器组配置页面,配置机器组。
-
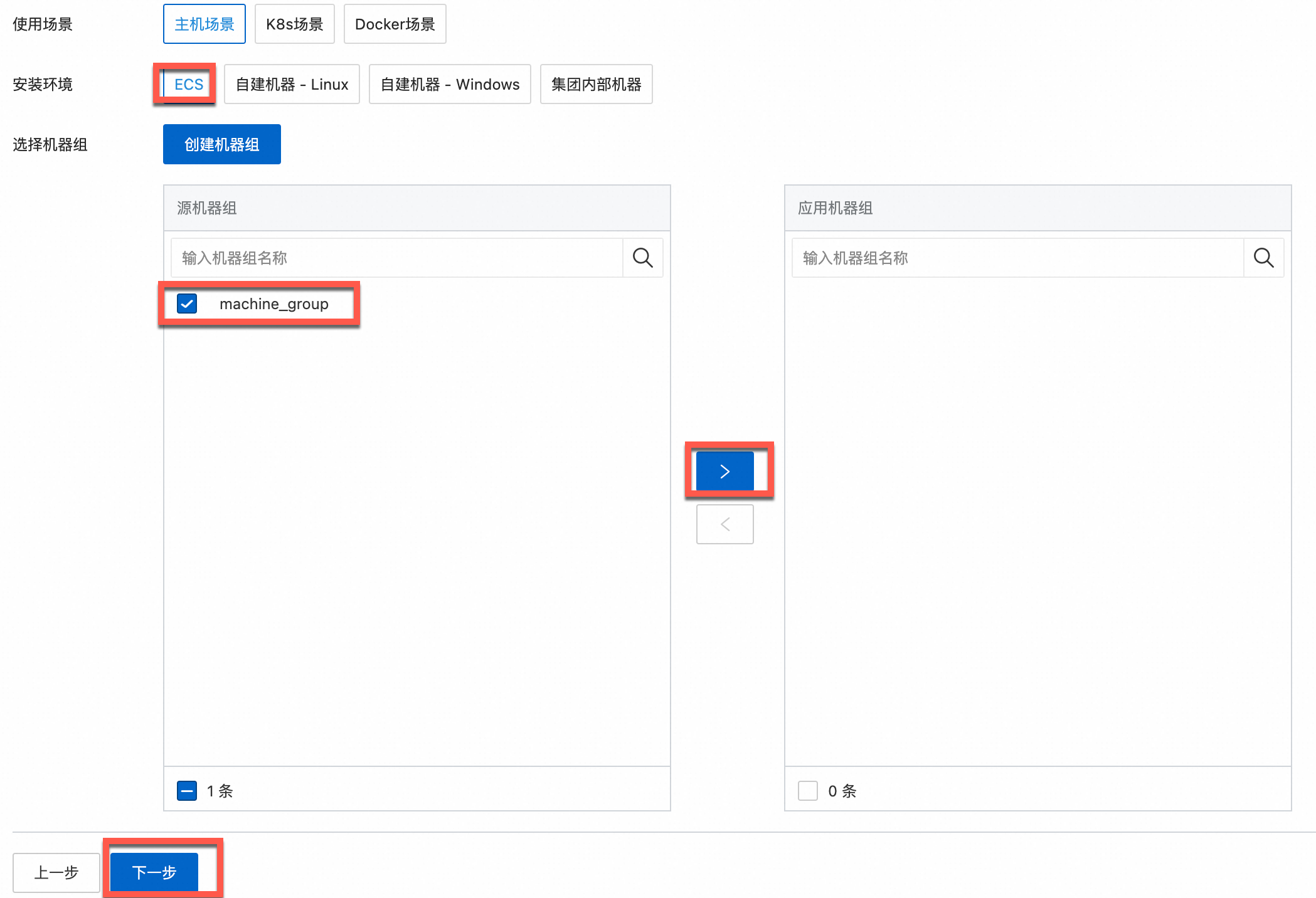
根据实际需求,选择使用场景和安装环境。
重要无论是否已有机器组,都必须根据实际需求正确选择使用场景和安装环境,这将影响后续的页面配置。
-
确认目标机器组已在应用机器组区域,单击下一步。
已有机器组
从源机器组列表选择目标机器组。
没有可用机器组
单击创建机器组,在创建机器组面板设置相关参数。机器组标识分为IP地址和用户自定义标识,更多信息请参见创建用户自定义标识机器组(推荐)或创建IP地址机器组。
重要创建机器组后立刻应用,可能因为连接未生效,导致心跳为FAIL,您可单击自动重试。如果还未解决,请参见Logtail机器组无心跳进行排查。
-
-
在数据源设置页签中,设置配置名称和插件配置,然后单击下一步。
您可以通过表单配置方式或编辑器配置(JSON配置)方式完成数据源设置。详细配置,请参见MySQL 输入插件。

-
创建索引和预览数据,然后单击下一步。日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果需要查询日志中的所有字段,建议使用全文索引。如果只需查询部分字段、建议使用字段索引,减少索引流量。如果需要对字段进行分析(SELECT语句),必须创建字段索引。
-
单击查询日志,系统将跳转至LogStore查询分析页面。
您需要等待1分钟左右,待索引生效后,才能在原始日志页签中,查看已采集到的日志。更多信息,请参见查询与分析快速指引。
CRD-AliyunPipelineConfig
本文以ACK集群为例,介绍如何创建采集配置。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
-
在集群列表页面中,单击目标集群操作列下的更多,然后单击管理集群。
-
创建名为example-k8s-file.yaml的文件。
参数说明
示例
apiVersion: telemetry.alibabacloud.com/v1alpha1 # 创建一个 ClusterAliyunPipelineConfig kind: ClusterAliyunPipelineConfig metadata: # 设置资源名,在当前Kubernetes集群内唯一。该名称也是创建出的iLogtail采集配置名 name: example-crd-mysql spec: # 指定目标project project: name: k8s-log-clusterid # 创建用于存储日志的 Logstore logstores: - name: crd-mysql-test # 定义iLogtail采集配置 config: # 日志样例(可不填写) sample: '' inputs: - Type: service_mysql Address: "rm-*.mysql.rds.aliyuncs.com" CheckPoint: true CheckPointColumn: id CheckPointColumnType: int CheckPointSavePerPage: true CheckPointStart: "0" Database: **** IntervalMs: 1000 Limit: true MaxSyncSize: 100 PageSize: 100 User: **** Password: ******* StateMent: "select * from test where id > ? order by id" # 定义输出插件 flushers: # 使用flusher_sls插件输出到指定Logstore。 - Type: flusher_sls Logstore: crd-mysql-test Endpoint: cn-hangzhou.log.aliyuncs.com Region: cn-hangzhou TelemetryType: logsType
string(必选)数据源类型,固定为service_mysql。
Address
string(可选)MySQL地址,例如
rm-****.mysql.rds.aliyuncs.com。默认值为127.0.0.1:3306。
地址类型:
内网(专有网络):仅用于同VPC下的实例(ECS、ACK等阿里云实例)内网访问。
外网地址:业务部署在其他VPC或本地机器上,需要通过外网地址访问实例,但您需提前手动申请外网地址。具体操作,请参见申请或释放外网地址。
说明由于外网网络易波动,建议在业务中使用内网地址进行连接。
User
string(可选)用于登录MySQL数据库的用户名称。默认值为root。
Password
string(可选)登录MySQL数据库的用户密码。
如果安全需求较高,建议将用户名称和密码配置为
xxx,待采集配置同步至本地机器后,在本地文件/usr/local/ilogtail/user_log_config.json中找到对应配置进行修改。具体操作,请参见采集MySQL查询结果。重要如果您在控制台上修改了此参数,同步至本地后会覆盖本地的配置。
DataBase
string(可选)MySQL数据库名称。
DialTimeOutMs
int(可选)连接MySQL数据库超时时间,默认值为5000,单位:ms。
ReadTimeOutMs
int(可选)读取MySQL查询结果的超时时间,默认值为5000,单位:ms。
StateMent
string(可选)SELECT语句。
设置CheckPoint为true时,Statement中SELECT语句的where条件中必须包含CheckPoint列(CheckPointColumn)。支持使用半角问号(?)表示替换符,与CheckPoint列配合使用。
例如设置CheckPointColumn为id,设置CheckPointStart为0,设置StateMent为
SELECT * from ... where id > ?。则每次采集后,系统会保存最后一条数据的ID作为Checkpoint,下次采集时查询语句中的半角问号(?)将被替换为该Checkpoint对应的ID。Limit
boolean(可选)是否使用Limit分页。
true:使用。
false(默认值):不使用。
建议使用Limit进行分页。设置Limit为true后,进行SQL查询时,系统将自动在SELECT语句中追加LIMIT语句。
PageSize
int(可选)分页大小,Limit 为 true 时必须配置。
MaxSyncSize
int(可选)每次同步最大记录数。默认值为 0,表示无限制。
CheckPoint
boolean(可选)是否使用 CheckPoint。
true:使用。
false(默认值):不使用。
CheckPoint 可作为下次采集数据的起点,实现数据增量采集。
CheckPointColumn
string(可选)CheckPoint列名称。
设置CheckPoint为true时,需要配置。
警告该列的值必须递增,否则可能会出现数据漏采集问题(每次查询结果中的最大值将作为下次查询的输入)。
CheckPointColumnType
string(可选)设置CheckPoint为true时,需要配置。
CheckPoint列的数据类型,支持int和time。int类型的内部存储为int64,time类型支持MySQL的date、datetime、time类型。
CheckPointStart
string(可选)设置CheckPoint为true时,需要配置。
CheckPoint列的初始值。
CheckPointSavePerPage
boolean(可选)设置CheckPoint为true时,需要配置。
是否每次分页时保存一次CheckPoint。
true(默认值):每次分页时保存一次CheckPoint。
false:每次同步完成后保存一次CheckPoint。
IntervalMs
int(必选)同步间隔,默认值为60000,单位:ms。
-
执行
kubectl apply -f example-k8s-file.yaml,Logtail开始采集MySQL数据。 登录日志服务控制台,在Project列表,单击打开目标Project。
-
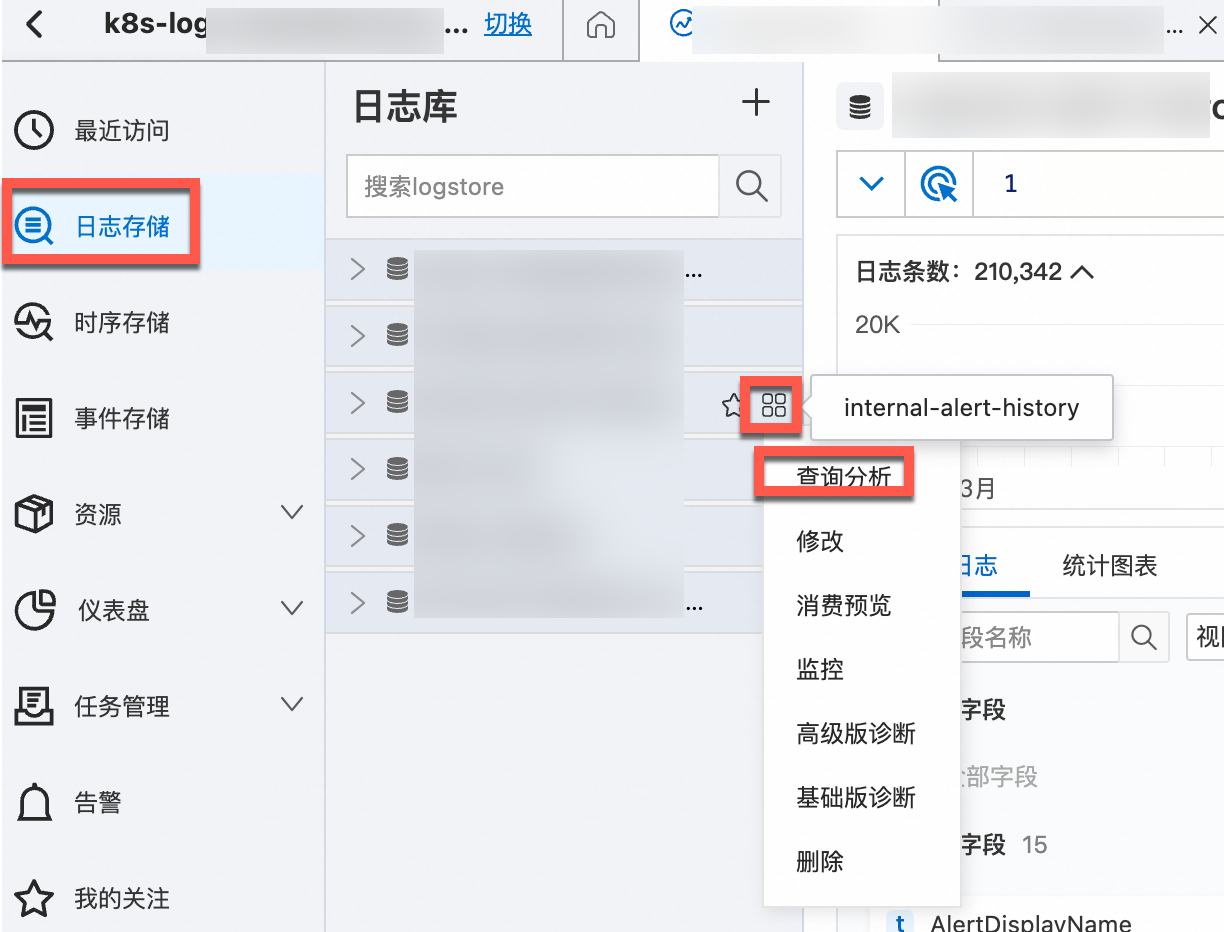
在对应的日志库右侧的
 图标,选择查询分析,查看查询日志。
图标,选择查询分析,查看查询日志。