本文以Linux系统为例介绍同阿里云账号跨地域采集日志的操作步骤。
前提条件
已创建Project和Logstore。更多信息,请参见创建项目Project和创建Logstore。
背景信息
某电商公司拥有两个电商应用,日志服务部署在地域B(成都)。
应用A部署在阿里云云服务器和日志服务Project属于不同地域(服务器为其他云厂商服务器或自建IDC)。
应用B部署在地域B(成都)下的集群。
现公司计划将两个应用的日志集中采集到地域B(成都)下的日志服务中,即将两个应用的日志分别采集到同一个日志服务Project下的不同Logstore中。因此您需要新增一个Logtail采集配置、机器组和Logstore,用于采集和存储应用A相关的日志。应用B相关的日志采集保持不变(使用原有的Logtail采集配置、机器组和Logstore)。
配置流程

使用限制
支持如下版本的Linux x86-64(64位)服务器。
Alibaba Cloud Linux 2
RedHat Enterprise 6、7、8
CentOS Linux 6、7、8
Debian GNU/Linux 8、9、10、11
Ubuntu 14.04、16.04、18.04、20.04
SUSE Linux Enterprise Server 11、12、15
OpenSUSE 15.1、15.2、42.3
其他基于glibc 2.5及以上版本的Linux操作系统
支持如下版本的Linux ARM(64位)服务器。
Alibaba Cloud Linux 3.2 ARM版
Anolis OS 8.2 ARM版及以上版本
CentOS 8.4 ARM版
Ubuntu 20.04 ARM版
Debian 11.2 ARM版
网络传输说明
传输方式 | 适用场景 |
公网 |
|
传输加速 | 服务器分布在海外各地的自建机房或者来自海外云厂商,使用公网传输数据可能会出现网络延迟高、传输不稳定等问题,推荐选择传输加速。更多信息,参见管理传输加速。 |
步骤一:应用A的服务器安装Logtail
根据日志服务Project所在地域,获取对应的
${your_region_name}。各个地域对应的
${your_region_name}请参见地域与安装参数对照表,例如华东 1(杭州)对应的${your_region_name}为cn-hangzhou。登录应用A所在的服务器,替换
${your_region_name}后,执行安装命令。公网
wget http://logtail-release-${your_region_name}.oss-${your_region_name}.aliyuncs.com/linux64/logtail.sh -O logtail.sh; chmod 755 logtail.sh; ./logtail.sh install ${your_region_name}-internet传输加速
wget http://logtail-release-${your_region_name}.oss-${your_region_name}.aliyuncs.com/linux64/logtail.sh -O logtail.sh; chmod 755 logtail.sh; ./logtail.sh install ${your_region_name}-acceleration
步骤二:创建IP地址机器组
获取服务器IP地址。
登录已安装Logtail的服务器。
打开app_info.json文件。
app_info.json文件路径说明如下表所示。
操作系统
Logtail
app_info.json文件路径
Linux
Logtail(64位程序)
/usr/local/ilogtail/app_info.json
Windows(64位操作系统)
Logtail(64位程序)
C:\Program Files\Alibaba\Logtail\app_info.json
Logtail(32位程序)
C:\Program Files (x86)\Alibaba\Logtail\app_info.json
Windows (32位操作系统)
Logtail(32位程序)
C:\Program Files\Alibaba\Logtail\app_info.json
查看app_info.json文件中的
ip字段值。Logtail自动获取的服务器IP地址记录在app_info.json文件的
ip字段中,如下图所示。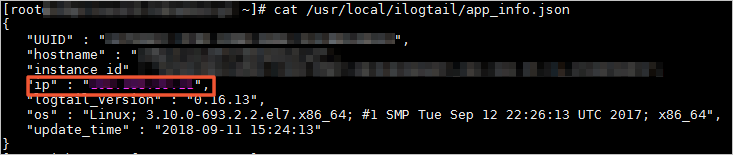
登录日志服务控制台。
在Project列表区域,单击目标Project。

在左侧导航栏中,选择。
选择机器组右侧的
 > 创建机器组。
> 创建机器组。在创建机器组对话框中,配置如下参数,单击确定。
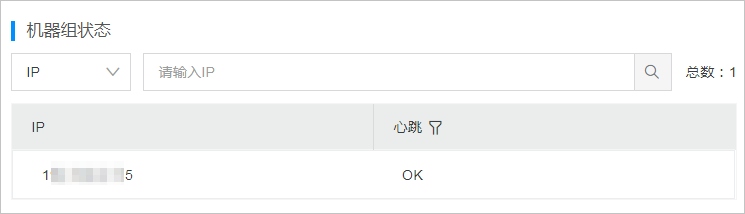
查看机器组状态。
在机器组列表中,单击目标机器组。
在机器组配置页面,查看服务器及其状态。
心跳为OK表示服务器上的Logtail实例与日志服务连接正常。如果显示FAIL,请参见Logtail机器组无心跳处理。
重要创建机器组大约需要2分钟。创建未生效,将导致心跳为FAIL。请2分钟后单击刷新进行重试。
步骤三:采集日志
登录日志服务控制台。
在接入数据区域中,根据需要选择包含文本日志后缀的入口。本文以采集主机中的多行文本日志为例。

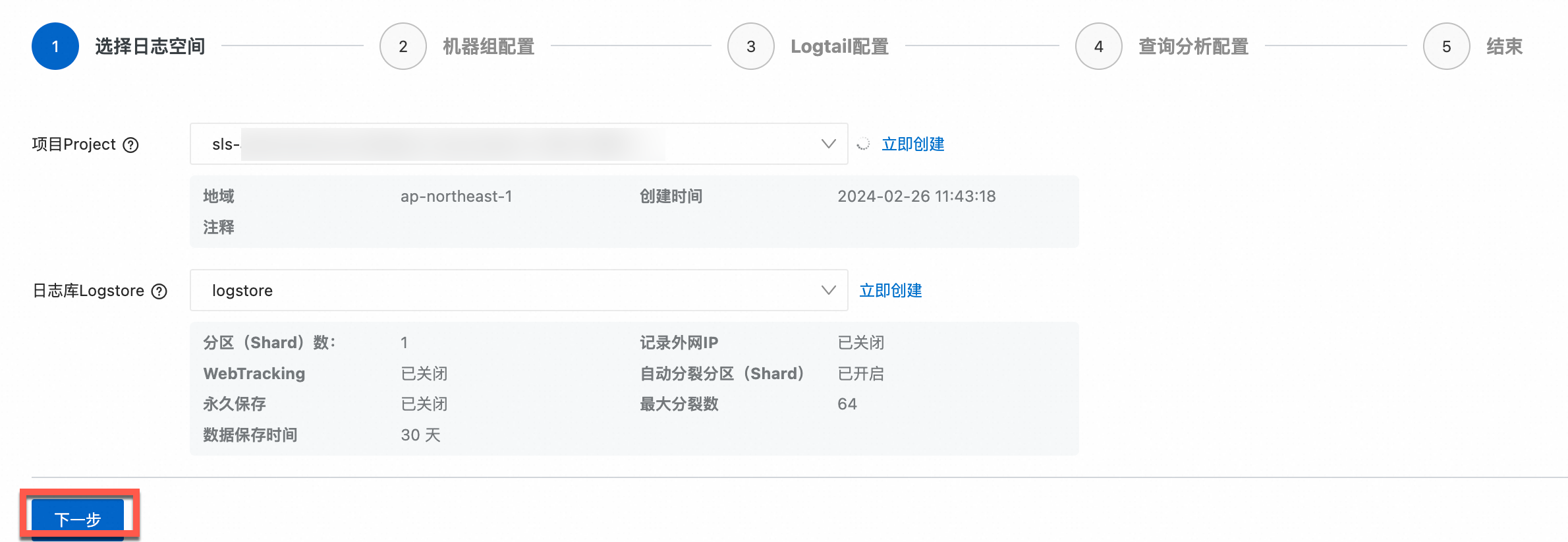
在选择日志空间页面,按照选择目标Project和Logstore,单击下一步。
在机器组配置页面,配置机器组。
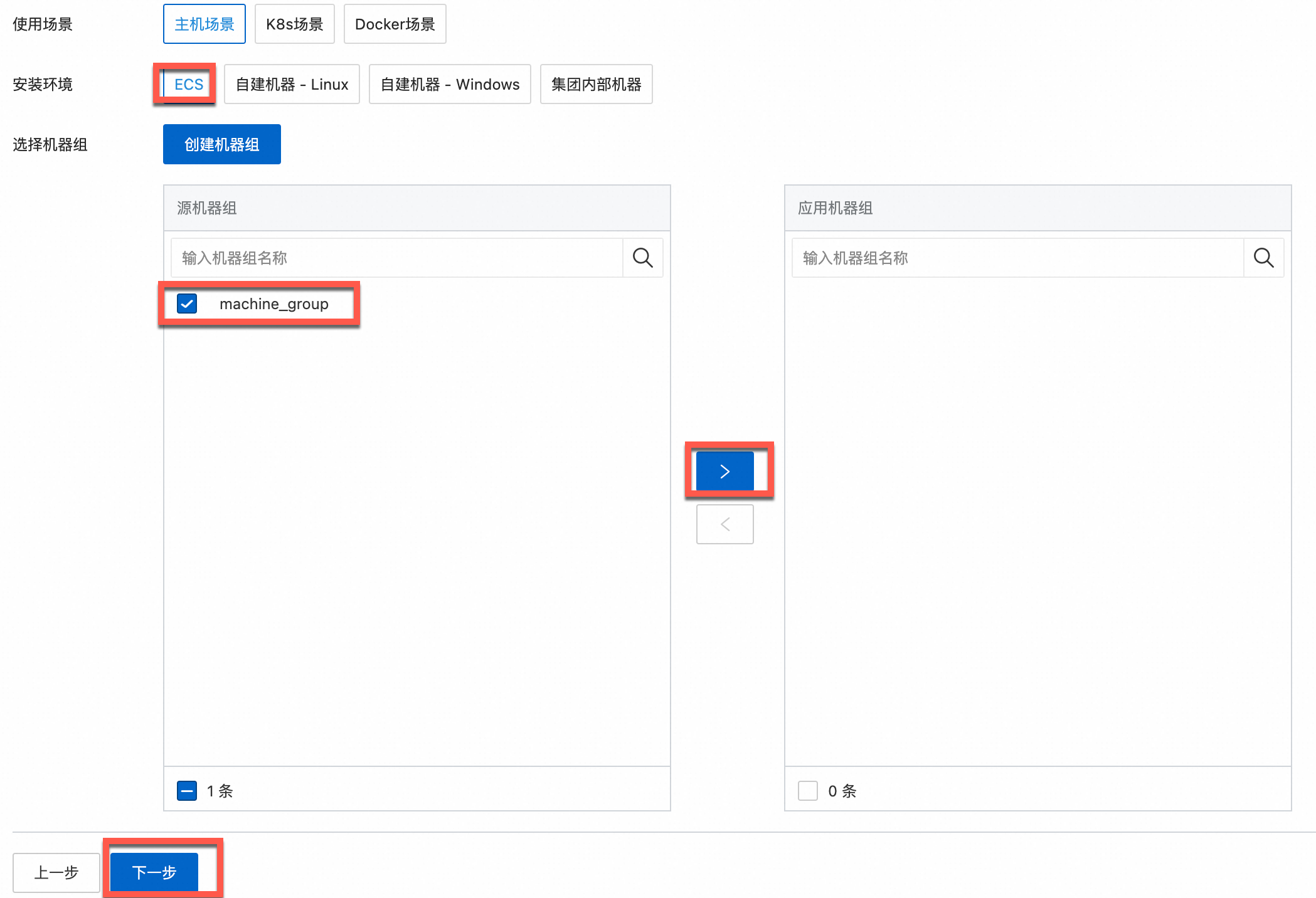
根据实际需求,选择使用场景和安装环境。
重要无论是否已有机器组,都必须根据实际需求正确选择使用场景和安装环境,这将影响后续的页面配置。
确认目标机器组已在应用机器组区域,单击下一步。
已有机器组
从源机器组列表选择目标机器组。
没有可用机器组
单击创建机器组,在创建机器组面板设置相关参数。机器组标识分为IP地址和用户自定义标识,更多信息请参见创建用户自定义标识机器组(推荐)或创建IP地址机器组。
重要创建机器组后立刻应用,可能因为连接未生效,导致心跳为FAIL,您可单击重试。如果还未解决,请参见Logtail机器组无心跳进行排查。
创建Logtail配置,单击下一步,创建Logtail配置。Logtail配置生效时间最长需要3分钟,请耐心等待。
创建索引和预览数据,然后单击下一步。日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果需要查询日志中的所有字段,建议使用全文索引。如果只需查询部分字段、建议使用字段索引,减少索引流量。如果需要对字段进行分析(SELECT语句),必须创建字段索引。
单击查询日志,系统将跳转至Logstore查询分析页面。
您需要等待1分钟左右,待索引生效后,才能在原始日志页签中,查看已采集到的日志。查询和分析日志的详细步骤,请参见查询和分析日志。
相关文档
使用Logtail采集日志后,如果预览页面为空或查询页面无数据,请按照Logtail采集日志失败的排查思路进行排查。在使用Logtail采集日志时,可能遇到正则解析失败、文件路径不正确、流量超过Shard服务能力等错误。查看Logtail采集错误的步骤,请参见如何查看Logtail采集错误信息。采集数据常见的错误类型请参见日志服务采集数据常见的错误类型。
默认情况下,一个日志文件只能匹配一个Logtail配置。如果同一份日志需要被采集多份,请参见如何实现文件中的日志被采集多份。
将企业内网服务器日志采集到日志服务,请参见采集企业内网服务器日志。