多元索引除了提供Long、Double、Boolean、Keyword、Text、Date、GeoPoint、Vector等基本类型外,还提供了数组类型和嵌套类型两种特殊类型。数组类型适用于存储一系列相同类型的数据,嵌套类型适用于存储具有层级结构的数据,类似于JSON。
数组类型
数组类型仅是多元索引中的概念,数据表中尚未支持数组。
数组类型和非数组类型在查询时的使用方式相同,只要数组中有一个value满足条件,即可返回该行。
向量Vector类型暂时不支持数组。
数组类型属于附加类型,可以附加在Long、Double、Boolean、Keyword、Text、Date、Geopoint等基本类型之上。例如Long类型+数组后,即为长整型数组,该字段中可以包括多个长整型数字。数组类型适用于存储一系列相同类型的数据。
数组格式
多元索引的基本类型数组格式请参见下表。
数组类型 | 说明 |
Long Array | 长整型的数组形式,格式为 |
Double Array | 浮点数的数组形式,格式为 |
Boolean Array | 布尔值的数组形式,格式为 |
Keyword Array | 字符串的数组形式,格式为JSON Array,例如 |
Text Array | 文本的数组形式,格式为JSON Array,例如 对于Text类型,一般无需使用数组形式。 |
Date Array | 日期的数组形式。如果日期类型为整型,则格式为 |
Geopoint Array | 地理位置点的数组形式,格式为 |
使用说明
对于多元索引中数组类型的字段,在数据表中必须为String类型,且对应的多元索引中的类型必须为相应的类型,如Long、Double等。
例如字段price是Double Array数组类型,则在数据表中price必须为String类型,在对应的多元索引中的类型必须为Double类型,且附加isArray=true属性。
使用示例
假设数据表名称为array_search_table,示例数据如下:
数据表包括主键列pk(String类型)和两个属性列col_keyword_array(String类型)、col_long_array(String类型)。
pk | col_keyword_array | col_long_array |
03#server#07 | ["开发环境", "测试环境", "物理服务器", "Linux" ] | [2020, 2023] |
4c#server#ae | ["生产环境", "云服务器", "Linux" ] | [2021, 2024] |
创建多元索引。
多元索引名称为
array_query_table_index,包括col_keyword_array(字符串数组类型)和col_long_array(长整型数组类型)两列。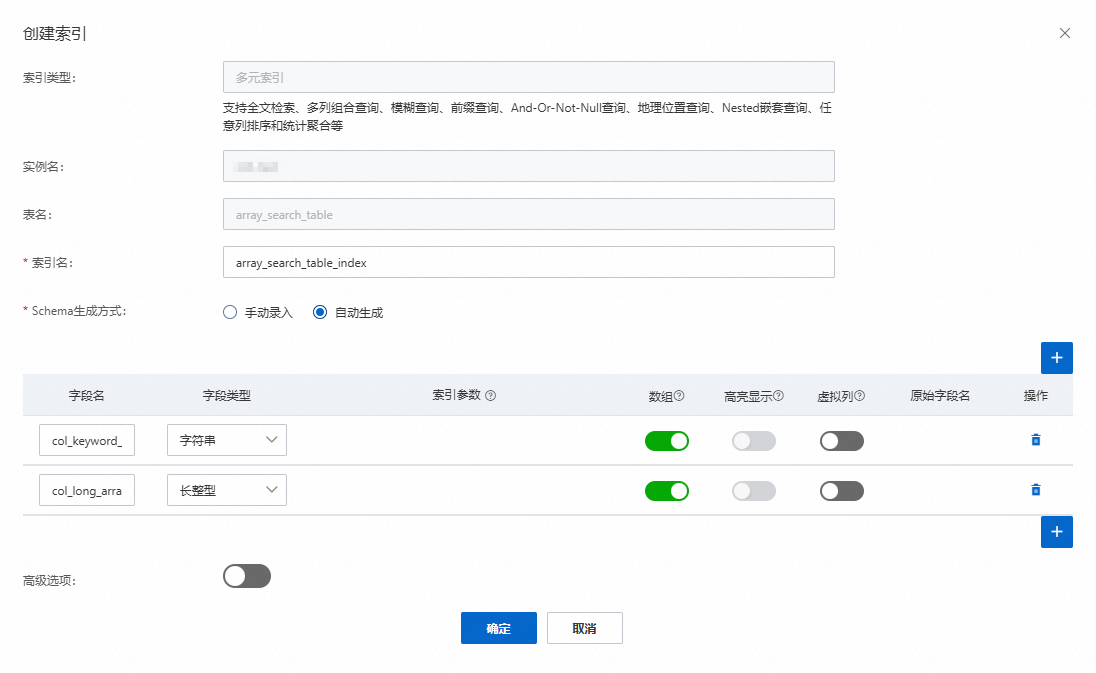
使用多元索引查询数组类型数据。
此处以Java代码为例,介绍如何查询数组类型数据。查询条件为
col_keyword_array数组列中存在精确匹配"云服务器"的元素,并且col_long_array数组列中存在等于2024的元素。说明如果您要使用SQL语句查询多元索引中数组类型的数据,请参见通过SQL查询数组类型的数据。
private static void query(SyncClient client) { //查询条件一:col_keyword_array数组列中存在精确匹配"云服务器"的元素 TermQuery keywordTermQuery = new TermQuery(); //设置查询类型为TermQuery。 keywordTermQuery.setFieldName("col_keyword_array"); //设置要匹配的字段。 keywordTermQuery.setTerm(ColumnValue.fromString("云服务器")); //设置要匹配的值。 //查询条件二:col_long_array数组列中存在等于2024的元素 TermQuery longTermQuery = new TermQuery(); //设置查询类型为TermQuery。 longTermQuery.setFieldName("col_long_array"); //设置要匹配的字段。 longTermQuery.setTerm(ColumnValue.fromLong(2024l)); //设置要匹配的值。 SearchQuery searchQuery = new SearchQuery(); //构造BoolQuery,设置查询条件为必须同时满足"查询条件一"和"查询条件二"。 BoolQuery boolQuery = new BoolQuery(); boolQuery.setMustQueries(Arrays.asList(keywordTermQuery, longTermQuery)); searchQuery.setQuery(boolQuery); //searchQuery.setGetTotalCount(true); //设置返回匹配的总行数。 SearchRequest searchRequest = new SearchRequest("<TABLE_NAME>", "<SEARCH_INDEX_NAME>", searchQuery); //通过设置columnsToGet参数可以指定返回的列或返回所有列,如果不设置此参数,则默认只返回主键列。 //SearchRequest.ColumnsToGet columnsToGet = new SearchRequest.ColumnsToGet(); //columnsToGet.setReturnAll(true); //设置为返回所有列。 //columnsToGet.setColumns(Arrays.asList("ColName1","ColName2")); //设置为返回指定列。 //searchRequest.setColumnsToGet(columnsToGet); SearchResponse resp = client.search(searchRequest); //System.out.println("TotalCount: " + resp.getTotalCount()); //打印匹配到的总行数,非返回行数。 System.out.println("Row: " + resp.getRows()); }
嵌套类型
嵌套类型(Nested)代表嵌套文档类型。嵌套文档是指对于一行数据(文档)可以包含多个子行(子文档),多个子行保存在一个嵌套类型字段中。嵌套类型适用于存储具有层级结构的数据。
对于嵌套类型字段,需要指定其子行的结构,即子行中包含哪些字段以及每个字段的属性。嵌套类型也是类似数组的多值结构,但是更接近JSON类型。
嵌套格式
根据数据的层级结构不同,嵌套类型包括单层级嵌套类型和多层级嵌套类型。具体说明请参见下表。
嵌套类型 | 说明 |
单层级嵌套类型 | 在一个数据结构中只包含一层其他数据结构,结构相对简单,能表示一定的层次关系。单层级嵌套类型适用于不需要过多层级但需要一定层级结构的场景。示例如下: |
多层级嵌套类型 | 在一个数据结构中包含了多层嵌套的其他数据结构,具有更复杂的层次关系。多层级嵌套类型适用于需要表示丰富层次、高度模块化或高度组织化的数据模型。示例如下: |
使用说明
对于多元索引中嵌套类型的字段,在数据表中必须为String类型,且对应的多元索引中的类型必须为嵌套类型。嵌套类型字段只能使用嵌套类型查询功能进行数据查询。
在写入数据到数据表时,多元索引嵌套类型字段对应数据表字段的写入格式必须为JSON对象的数组格式,例如[{"tagName":"tag1", "score":0.8,"time": 1730690237000 }, {"tagName":"tag2", "score":0.2,"time": 1730691557000}]。
即使只有一个子行,也必须按照JSON数组的格式构造字符串。
使用示例
单层级嵌套类型示例
单层级嵌套类型支持通过控制台或者SDK进行创建。
以Java代码为例介绍创建单层级嵌套类型。示例中嵌套类型字段的名称为tags,子行中包含三个字段,如下图所示。
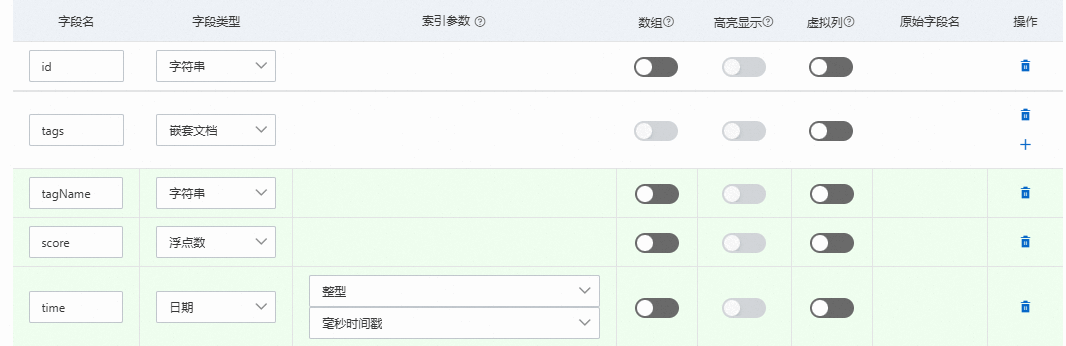
一个字段名称为tagName,类型为字符串类型(Keyword)。
一个字段名称为score,类型为浮点数(Double)。
一个字段名称为time,类型为日期时间类型(Date),取值单位为毫秒时间戳。
写入数据表时的数据样例为[{"tagName":"tag1", "score":0.8,"time": 1730690237000 }, {"tagName":"tag2", "score":0.2,"time": 1730691557000}]。
//构造子行的FieldSchema。
List<FieldSchema> subFieldSchemas = new ArrayList<FieldSchema>();
subFieldSchemas.add(new FieldSchema("tagName", FieldType.KEYWORD)
.setIndex(true).setEnableSortAndAgg(true));
subFieldSchemas.add(new FieldSchema("score", FieldType.DOUBLE)
.setIndex(true).setEnableSortAndAgg(true));
subFieldSchemas.add(new FieldSchema("time", FieldType.DATE)
.setDateFormats(Arrays.asList("epoch_millis")));
//将子行的FieldSchema设置到嵌套类型字段的subfieldSchemas中。
FieldSchema nestedFieldSchema = new FieldSchema("tags", FieldType.NESTED)
.setSubFieldSchemas(subFieldSchemas);多层级嵌套类型示例
多层级嵌套类型只能通过SDK进行创建。
以Java示例代码为例介绍创建多层级嵌套类型。示例中嵌套类型字段的名称为user,子行中包含四个基础类型字段和一个嵌套类型字段。
一个字段名称为name,类型为字符串类型(Keyword)。
一个字段名称为age,类型为长整型(Long)。
一个字段名称为birth,类型为日期时间类型(Date),取值为日期格式。
一个字段名称为phone,类型为字符串类型(Keyword)。
一个嵌套类型字段的名称为address,子行中包含的三个字段名称分别为province、city和street,类型均为字符串类型(Keyword)。
写入数据表时的数据样例为[ {"name":"张三","age":20,"brith":"2014-10-10 12:00:00.000","phone":"1390000****","address":[{"province":"浙江省","city":"杭州市","street":"阳光大道幸福小区1201号"}]}]。
//构造嵌套类型字段address的子行FieldSchema,子行中包含三个字段。查询子行中字段的数据时,子行中字段的路径为user.address。
List<FieldSchema> addressSubFiledSchemas = new ArrayList<>();
addressSubFiledSchemas.add(new FieldSchema("province",FieldType.KEYWORD));
addressSubFiledSchemas.add(new FieldSchema("city",FieldType.KEYWORD));
addressSubFiledSchemas.add(new FieldSchema("street",FieldType.KEYWORD));
//构造嵌套类型字段user的子行FieldSchema,子行中包含三个基础类型字段和一个嵌套类型字段address。查询子行中字段的数据时,子行中字段的路径为user。
List<FieldSchema> subFieldSchemas = new ArrayList<>();
subFieldSchemas.add(new FieldSchema("name",FieldType.KEYWORD));
subFieldSchemas.add(new FieldSchema("age",FieldType.LONG));
subFieldSchemas.add(new FieldSchema("birth",FieldType.DATE).setDateFormats(Arrays.asList("yyyy-MM-dd HH:mm:ss.SSS")));
subFieldSchemas.add(new FieldSchema("phone",FieldType.KEYWORD));
subFieldSchemas.add(new FieldSchema("address",FieldType.NESTED).setSubFieldSchemas(addressSubFiledSchemas));
//将嵌套类型字段user的子行FieldSchema设置到嵌套类型字段的subfieldSchemas中。
List<FieldSchema> fieldSchemas = new ArrayList<>();
fieldSchemas.add(new FieldSchema("user",FieldType.NESTED).setSubFieldSchemas(subFieldSchemas));嵌套类型的局限性
由于含有嵌套类型字段的多元索引不支持索引预排序(IndexSort),而索引预排序功能在很多场景下可以带来很大性能提升。
如果使用含有嵌套类型字段的多元索引查询数据且需要翻页,则必须在查询条件中指定数据返回的排序方式,否则当符合查询条件的数据未读取完时,服务端不会返回nextToken。
嵌套类型的查询性能相比其他类型的查询性能更低一些。
嵌套类型除了上述局限性外,和非嵌套类型支持的功能相同,支持所有的查询类型、排序和统计聚合。
相关文档
多元索引查询类型包括精确查询、多词精确查询、全匹配查询、匹配查询、短语匹配查询、范围查询、前缀查询、后缀查询、通配符查询、基于分词的通配符查询、组合查询、地理位置查询、嵌套类型查询、向量检索、和列存在性查询,您可以选择合适的查询类型进行多维度数据查询。
如果要对结果集进行排序或者翻页,您可以使用排序和翻页功能来实现。具体操作,请参见排序和翻页。
如果要按照某一列对结果集做折叠,使对应类型的数据在结果展示中只出现一次,您可以使用折叠(去重)功能来实现。具体操作,请参见折叠(去重)。
如果要进行数据分析,例如求最值、求和、统计行数等,您可以使用 Search 接口的统计聚合功能或者 SQL 查询来实现。具体操作,请参见统计聚合和SQL查询。
如果要快速导出数据,而不关心整个结果集的顺序时,您可以使用 ParallelScan 接口和 ComputeSplits 接口实现多并发导出数据。具体操作,请参见并发导出数据。