
如果需要将表格存储中新增和变化的数据定期同步到OSS中备份或者使用,您可以通过在DataWorks数据集成控制台新建和配置离线同步任务来实现周期性增量数据同步。
注意事项
准备工作
已开通OSS服务并创建存储空间Bucket。具体操作,请参见开通OSS服务和通过控制台创建存储空间。
已确认和记录表格存储中要同步到OSS的实例、数据表或者时序表信息。
已开通DataWorks服务并创建工作空间。具体操作,请参见开通DataWorks服务和创建工作空间。
已创建RAM用户并为RAM用户授予OSS完全管理权限(AliyunOSSFullAccess)和管理表格存储权限(AliyunOTSFullAccess)。具体操作,请参见创建RAM用户和为RAM用户授权。
由于配置时需要填写访问密钥AccessKey(AK)信息来执行授权,为避免阿里云账号泄露AccessKey带来的安全风险,建议您通过RAM用户来完成授权和AccessKey的创建。
已为RAM用户创建AccessKey。具体操作,请参见创建AccessKey。
已新增表格存储数据源和OSS数据源。具体操作,请参见步骤一:新增表格存储数据源和步骤二:新增OSS数据源。
步骤一:新建同步任务节点
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在DataStudio控制台的数据开发页面,单击业务流程节点下的目标业务流程。
如果需要新建业务流程,请参见创建业务流程。
在数据集成节点上右键选择新建节点 > 离线同步。
在新建节点对话框,选择路径并填写节点名称。
单击确认。
在数据集成节点下会显示新建的离线同步节点。
步骤二:配置离线同步任务并启动
配置表格存储到OSS的增量数据同步任务,请根据所用数据存储模型选择相应任务配置方式。
如果所用的数据存储模型是宽表模型(即使用数据表存储数据),则需要同步数据表中的数据,请按照同步数据表数据的任务配置进行配置。
如果所用的数据存储模型是时序模型(即使用时序表存储数据),则需要同步时序表中的数据,请按照同步时序表数据的任务配置进行配置。
在数据集成节点下,双击打开新建的离线同步任务节点。
配置同步网络链接。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
数据同步任务的执行必须经过资源组来实现,请选择资源组并保证资源组与读写两端的数据源能联通访问。
在网络与资源配置步骤,选择数据来源为Tablestore Stream,并选择数据源名称为表格存储数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
请与新增数据源时选择的资源组保持一致。
选择数据去向为OSS,并选择数据源名称为OSS数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务并保存。
使用向导模式时只能按照行的列值增量变化形式导出数据。使用脚本模式时支持按照行的列值增量变化形式导出数据或者按照行模式导出变化后的数据。如果要按照行模式导出变化后的数据请使用脚本模式。
(推荐)向导模式脚本模式在配置任务步骤的配置数据来源与去向区域,根据实际配置数据来源和数据去向。
数据来源配置数据去向配置参数
说明
表
表格存储中的数据表名称。
开始时间
增量读取数据的开始时间和结束时间,分别配置为变量形式
${startTime}和${endTime},具体格式在后续调度属性中配置。增量数据的时间范围为左闭右开的区间。结束时间
状态表
用于记录状态的表名称,默认值为TableStoreStreamReaderStatusTable。
最大重试次数
从TableStore中读取增量数据时,每次请求的最大重试次数。
导出时序信息
是否导出时序信息,时序信息包含了数据的写入时间等。
参数
说明
文本类型
写入OSS的文件类型,例如csv、txt。
不同文件类型支持的配置有差异,请以实际界面为准。
文件名(含路径)
当设置文本类型为text、csv或orc时才能配置该参数。
OSS中的文件名称,支持带有路径,例如
tablestore/20231130/myotsdata.csv。文件路径
当设置文本类型为parquet时才能配置该参数。
文件在OSS上的路径,例如
tablestore/20231130/。文件名
当设置文本类型为parquet时才能配置该参数。
OSS中的文件名称。
列分隔符
当设置文本类型为text或csv时才能配置该参数。
写入OSS文件时,列之间使用的分隔符。
行分隔符
当设置文本类型为text时才能配置才参数。
自定义的行分隔符,用来分隔不同数据行。例如配置为
\u0001。您需要使用数据中不存在的分隔符作为行分隔符。如果要使用Linux或Windows平台的默认行分隔符(
\n、\r\n)建议置空此配置,平台能自适应读取。编码
当设置文本类型为text或csv时才能配置该参数。
写入文件的编码配置。
null值
当设置文本类型为text、csv或orc时才能配置该参数。
源数据源中可以表示为null的字符串,例如配置为null,如果源数据是null,则系统会视作null字段。
时间格式
当设置文本类型为text或csv时才能配置该参数。
日期类型的数据写入到OSS文件时的时间格式,例如
yyyy-MM-dd。前缀冲突
当设置的文件名与OSS中已有文件名冲突时的处理方法。取值范围如下:
替换:删除原始文件,重建一个同名文件。
保留:保留原始文件,重建一个新文件,名称为原文件名加随机后缀。
报错:同步任务停止执行。
切分文件
当设置文本类型为text或csv时才能配置该参数。
写入OSS文件时,单个Object文件的最大大小。单位为MB。最大值为100 GB。当文件大小超过指定的切分文件大小时,系统会生成新文件继续写入数据,直到完成所有数据写入。
写为一个文件
当设置文本类型为text或csv时才能配置该参数。
写入数据到OSS时,是否写单个文件。默认写多个文件,当读不到任何数据时,如果配置了文件头,则会输出只包含文件头的空文件,否则只输出空文件。
如果需要写入到单个文件,请选中写为一个文件复选框。此时当读不到任何数据时, 不会产生空文件。
首行输出表头
当设置文本类型为text或csv时才能配置该参数。
写入文件时第一行是否输出表头。默认不输出表头。如果需要在第一行输出表头,请选中首行输出表头复选框。
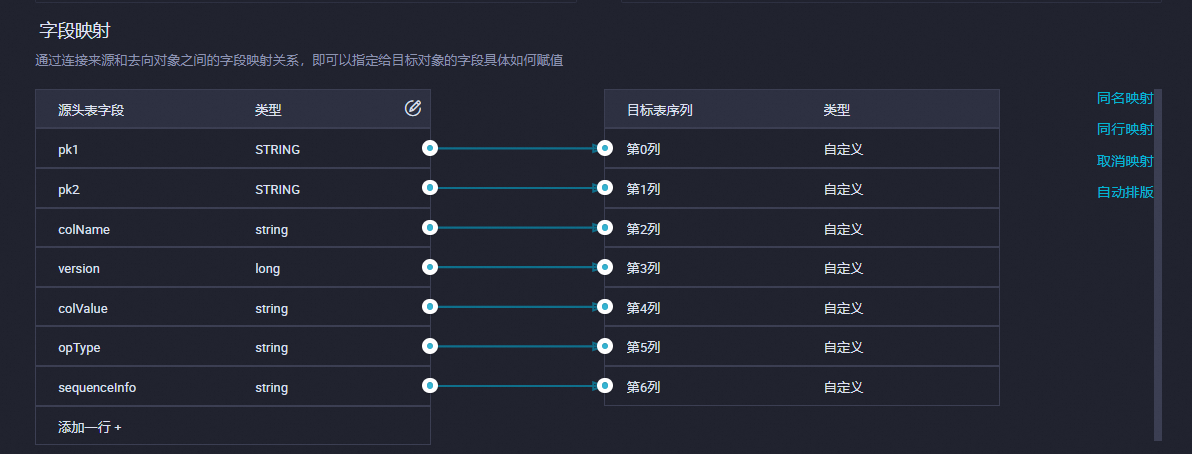
在字段映射区域,系统自动进行字段映射,保持默认配置即可。
来源字段中包括了表主键和增量变更信息,目标字段不支持配置。
在通道控制区域,配置任务运行参数,例如任务期望最大并发数、同步速率、脏数据同步策略、分布式处理能力等。关于参数配置的更多信息,请参见配置通道。
单击
 图标,保存配置。
图标,保存配置。执行后续操作时,如果未保存配置,则系统会出现保存确认的提示,单击确认即可。
增量数据的同步需要使用到OTSStream Reader和OSS Writer插件。脚本配置规则请参见Tablestore Stream数据源和OSS数据源。
任务转为脚本模式后,将无法转为向导模式,请谨慎操作。
在配置任务步骤,单击
 图标,然后在弹出的对话框中单击确认。
图标,然后在弹出的对话框中单击确认。在脚本配置页面,请根据如下示例完成配置。
为了便于理解,在配置示例中增加了注释内容,实际使用脚本时请删除所有注释内容。
按照行模式导出增量变化后的数据按照行的列值增量变化形式导出数据{ "type": "job", "version": "2.0", "steps": [ { "stepType": "otsstream", //插件名,不能修改。 "parameter": { "statusTable": "TableStoreStreamReaderStatusTable", //存储Tablestore Stream状态的表,一般无需修改。 "maxRetries": 30, //最大重试次数。 "isExportSequenceInfo": false, //是否导出时序信息,时序信息包含了数据的写入时间等。 "mode": "single_version_and_update_only", //Tablestore Stream导出数据的格式,目前需要设置为single_version_and_update_only。如果配置模板中无此项,则需要增加。 "datasource": "otssource", //数据源名称,请根据实际填写。 "envType": 1, "column": [ { "name": "pk1" }, { "name": "pk2" }, { "name": "col1" } ], "startTimeString": "${startTime}", //开始导出的时间点,由于是增量导出,需要循环启动此任务,则此处每次启动时的时间都不同,因此需要设置一个变量,例如${startTime}。 "table": "mytable", //Tablestore中的数据表名称。 "endTimeString": "${endTime}" //结束导出的时间点。此处也需要设置一个变量,例如${endTime}。 }, "name": "Reader", "category": "reader" }, { "stepType": "oss", //Writer插件的名称,不能修改。 "parameter": { //此处参数配置只适用于导出csv和text格式的文件。如果要导出为parquet和orc格式,请参照OSS数据源文档修改OSSWriter配置。 "fieldDelimiterOrigin": ",", "nullFormat": "null", //定义null值的字符串标识符方式,可以是空字符串。 "dateFormat": "yyyy-MM-dd HH:mm:ss", //时间格式。 "datasource": "osssource", //OSS数据源名称,请根据实际填写。 "envType": 1, "writeSingleObject": true, //是否写单个文件。设置此参数为true,表示写单个文件,当读不到任何数据时不会产生空文件;设置此参数为false,表示写多个文件,当读不到任何数据时,如果配置文件头会输出空文件只包含文件头,否则只输出空文件。 "writeMode": "truncate", //当同名文件存在时系统进行的操作,可选值包括truncate、append和nonConflict。truncate表示会清理已存在的同名文件,append表示会增加到已存在的同名文件内容后面,nonConflict表示当同名文件存在时会报错。 "encoding": "UTF-8", //编码类型。 "fieldDelimiter": ",", //每一列的分隔符。 "fileFormat": "csv", //文件类型,可选值包括csv、text、parquet和orc格式。 "object": "" //备份到OSS的文件名前缀,建议使用"Tablestore实例名/表名/date",例如"instance/table/{date}"。 }, "name": "Writer", "category": "writer" }, { "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" }, "name": "Processor", "category": "processor" } ], "setting": { "errorLimit": { "record": "0" //允许出错的个数。当错误超过这个数目的时候同步任务会失败。 }, "locale": "zh", "speed": { "throttle": false, //当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,需要配置mbps参数,表示限流。 "concurrent": 3 //作业并发数。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }{ "type": "job", "version": "2.0", "steps": [ { "stepType": "otsstream", //插件名,不能修改。 "parameter": { "statusTable": "TableStoreStreamReaderStatusTable", //存储Tablestore Stream状态的表,一般无需修改。 "maxRetries": 30, //最大重试次数。 "isExportSequenceInfo": false, //是否导出时序信息,时序信息包含了数据的写入时间等。 "datasource": "otssource", "envType": 1, "column": [//设置数据表中需要导出到OSS中的列,如果配置模板中无此项则需要增加,保持默认配置即可。 "pk1", //主键列名称,如果有多个主键列则需要全部配置。 "pk2", //主键列名称,如果有多个主键列则需要全部配置。 "colName", //表示有增量变化的属性列名称,无需修改。 "version", //表示增量变化后列的数据版本号,无需修改。格式为64位时间戳。单位为毫秒。 "colValue", //表示增量变化后属性列值,无需修改。 "opType", //表示增量操作类型,无需修改。 "sequenceInfo" //表示自增保序sequenceid,无需修改。 ], "startTimeString": "${startTime}", //开始导出的时间点,由于是增量导出,需要循环启动此任务,则此处每次启动时的时间都不同,因此需要设置一个变量,例如${startTime}。 "table": "mytable", //Tablestore中的数据表名称。 "endTimeString": "${endTime}" //结束导出的时间点。此处也需要设置一个变量,例如${endTime}。 }, "name": "Reader", "category": "reader" }, { "stepType": "oss", //Writer插件的名称,不能修改。 "parameter": { //此处参数配置只适用于导出csv和text格式的文件。如果要导出为parquet和orc格式,请参照OSS数据源文档修改OSSWriter配置。 "fieldDelimiterOrigin": ",", "nullFormat": "null", //定义null值的字符串标识符方式,可以是空字符串。 "dateFormat": "yyyy-MM-dd HH:mm:ss", //时间格式。 "datasource": "osssource", //OSS数据源名称,请根据实际填写。 "envType": 1, "writeSingleObject": true, //是否写单个文件。设置此参数为true,表示写单个文件,当读不到任何数据时不会产生空文件;设置此参数为false,表示写多个文件,当读不到任何数据时,如果配置文件头会输出空文件只包含文件头,否则只输出空文件。 "column": [ //导出到OSS的列,只需要用序号表示即可,无需修改。 "0", "1", "2", "3", "4", "5", "6" ], "writeMode": "truncate", //当同名文件存在时系统进行的操作,可选值包括truncate、append和nonConflict。truncate表示会清理已存在的同名文件,append表示会增加到已存在的同名文件内容后面,nonConflict表示当同名文件存在时会报错。 "encoding": "UTF-8", //编码类型。 "fieldDelimiter": ",", //每一列的分隔符。 "fileFormat": "csv", //文件类型,可选值包括csv和text格式。 "object": "" //备份到OSS的文件名前缀,建议使用"Tablestore实例名/表名/date",例如"instance/table/{date}"。 }, "name": "Writer", "category": "writer" }, { "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" }, "name": "Processor", "category": "processor" } ], "setting": { "errorLimit": { "record": "0" //允许出错的个数。当错误超过这个数目的时候同步任务会失败。 }, "locale": "zh", "speed": { "throttle": false, //当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,需要配置mbps参数,表示限流。 "concurrent": 3 //作业并发数。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }单击
图标,保存配置。执行后续操作时,如果未保存脚本,则系统会出现保存确认的提示,单击确认即可。
在数据集成节点下,双击打开新建的离线同步任务节点。
配置同步网络链接。
选择离线同步任务的数据来源、数据去向以及用于执行同步任务的资源组,并测试连通性。
数据同步任务的执行必须经过资源组来实现,请选择资源组并保证资源组与读写两端的数据源能联通访问。
在网络与资源配置步骤,选择数据来源为Tablestore Stream,并选择数据源名称为表格存储数据源。
选择资源组。
选择资源组后,系统会显示资源组的地域、规格等信息以及自动测试资源组与所选数据源之间连通性。
请与新增数据源时选择的资源组保持一致。
选择数据去向为OSS,并选择数据源名称为OSS数据源。
系统会自动测试资源组与所选数据源之间连通性。
测试可连通后,单击下一步。
配置任务。
同步时序表数据时只支持使用脚本模式进行任务配置。增量数据的同步需要使用到OTSStream Reader和OSS Writer插件。脚本配置规则请参见Tablestore Stream数据源和OSS数据源。
任务转为脚本模式后,将无法转为向导模式,请谨慎操作。
在配置任务步骤,单击
图标,然后在弹出的对话框中单击确认。在脚本配置页面,请根据如下示例完成配置。
时序表只支持按照行模式导出增量变化后的数据。
为了便于理解,在配置示例中增加了注释内容,实际使用脚本时请删除所有注释内容。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "otsstream", //插件名,不能修改。 "parameter": { "statusTable": "TableStoreStreamReaderStatusTable", //存储Tablestore Stream状态的表,一般无需修改。 "maxRetries": 30, //最大重试次数。 "isExportSequenceInfo": false, //是否导出时序信息,时序信息包含了数据的写入时间等。 "mode": "single_version_and_update_only", //Tablestore Stream导出数据的格式,目前需要设置为single_version_and_update_only。如果配置模板中无此项,则需要增加。 "isTimeseriesTable":"true", //是否为时序表。当要导出时序表数据到OSS时,您需要设置此参数为true。 "datasource": "otssource", //数据源名称,请根据实际填写。 "envType": 1, "column": [ //设置时序表中需要导出到OSS中的列,如果配置模板中无此项则需要增加。 { "name": "_m_name" //度量名称,无需修改。如果不需要导出,请删除该配置。 }, { "name": "_data_source", //数据源,无需修改。如果不需要导出,请删除该配置。 }, { "name": "_tags", //时间线标签,无需修改。如果不需要导出,请删除该配置。 }, { "name": "colname", //时间线数据中的列,请根据实际填写。如果需要导出多列,请添加相应列。 } ], "startTimeString": "${startTime}", //开始导出的时间点,由于是增量导出,需要循环启动此任务,则此处每次启动时的时间都不同,因此需要设置一个变量,例如${startTime}。 "table": "timeseriestable", //Tablestore中的时序表名称。 "endTimeString": "${endTime}" //结束导出的时间点。此处也需要设置一个变量,例如${endTime}。 }, "name": "Reader", "category": "reader" }, { "stepType": "oss", //Writer插件的名称,不能修改。 "parameter": { //此处参数配置只适用于导出csv和text格式的文件。如果要导出为parquet和orc格式,请参照OSS数据源文档修改OSSWriter配置。 "fieldDelimiterOrigin": ",", "nullFormat": "null", //定义null值的字符串标识符方式,可以是空字符串。 "dateFormat": "yyyy-MM-dd HH:mm:ss", //时间格式。 "datasource": "osssource", //OSS数据源名称,请根据实际填写。 "envType": 1, "writeSingleObject": false, //是否写单个文件。设置此参数为true,表示写单个文件,当读不到任何数据时不会产生空文件;设置此参数为false,表示写多个文件,当读不到任何数据时,如果配置文件头会输出空文件只包含文件头,否则只输出空文件。 "writeMode": "truncate", //当同名文件存在时系统进行的操作,可选值包括truncate、append和nonConflict。truncate表示会清理已存在的同名文件,append表示会增加到已存在的同名文件内容后面,nonConflict表示当同名文件存在时会报错。 "encoding": "UTF-8", //编码类型。 "fieldDelimiter": ",", //每一列的分隔符。 "fileFormat": "csv", //文件类型,可选值包括csv和text格式。 "object": "" //备份到OSS的文件名前缀,建议使用"Tablestore实例名/表名/date",例如"instance/table/{date}"。 }, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "0" //允许出错的个数。当错误超过这个数目的时候同步任务会失败。 }, "speed": { "concurrent": 2, //作业并发数。 "throttle": false //当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,需要配置mbps参数,表示限流。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }单击
图标,保存配置。执行后续操作时,如果未保存脚本,则系统会出现保存确认的提示,单击确认即可。
步骤三:配置调度属性
通过调度配置,您可以配置同步任务的执行时间、重跑属性、调度依赖等。
单击任务右侧的调度配置。
在调度配置面板的参数部分,单击新增参数,根据下表说明新增参数。更多信息,请参见调度参数支持的格式。
参数
参数值
参数
参数值
startTime
$[yyyymmddhh24-2/24]$[miss-10/24/60]
endTime
$[yyyymmddhh24-1/24]$[miss-10/24/60]
配置示例如下图所示。
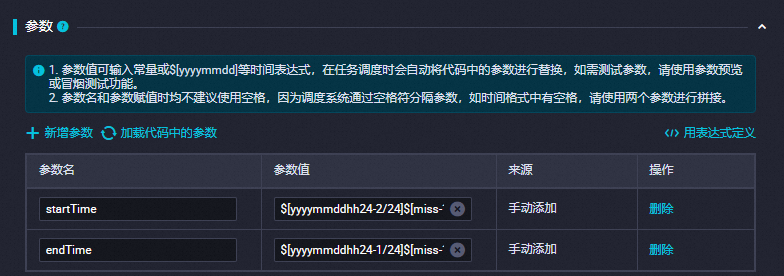
假如任务运行时的时间为2023年04月23日19:00:00点,则startTime为20230423175000,endTime为20230423185000。任务将会同步17:50到18:50时段内新增的数据。
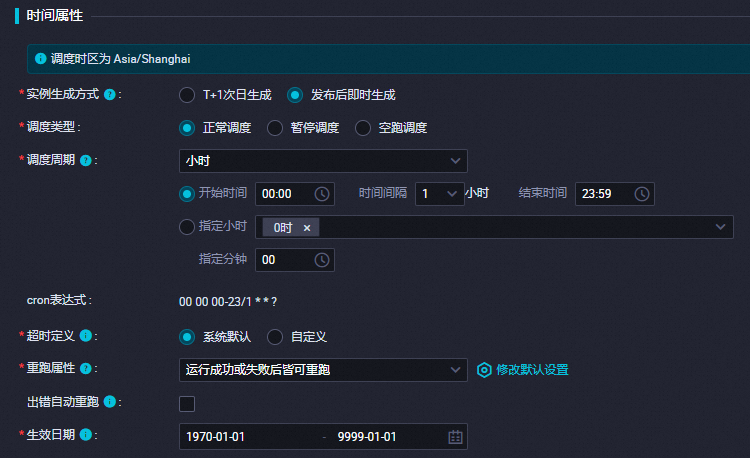
在时间属性部分,配置时间属性。更多信息,请参见时间属性配置说明。
此处以任务整点每小时自动运行为例介绍配置,如下图所示。
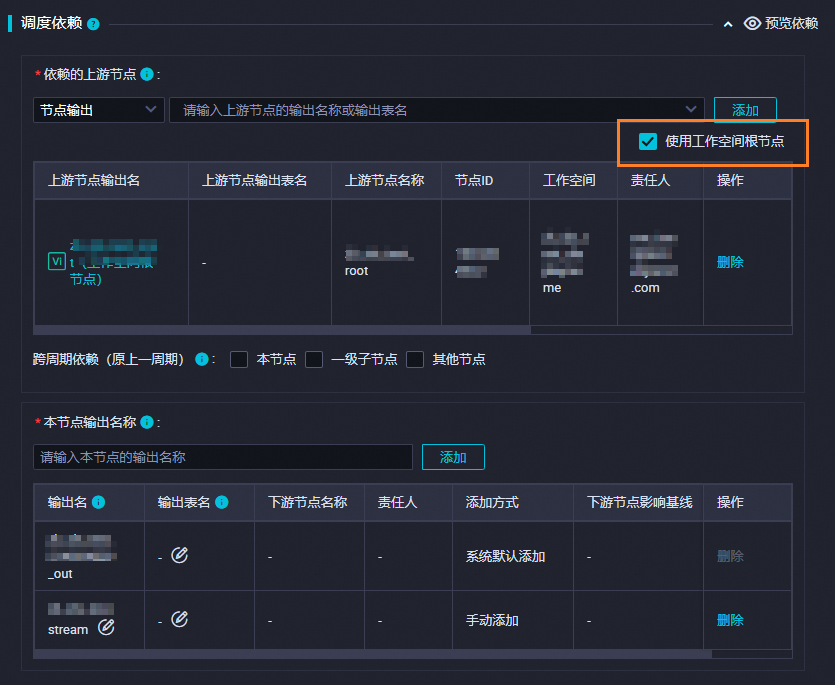
在调度依赖部分,选中使用工作空间根节点复选框,系统会自动生成依赖的上游节点信息。
使用工作空间根节点表示该任务无上游的依赖任务。
配置完成后,关闭配置调度面板。
步骤四:调试代码并提交任务
(可选)根据需要调试脚本代码。
通过调试脚本代码,确保同步任务能成功同步表格存储的增量数据到OSS中。
调试脚本代码时配置的时间范围内的数据可能会多次导入到OSS中,相同数据行会覆盖写入到OSS中。
单击
 图标。
图标。在参数对话框,选择运行资源组的名称,并配置自定义参数。
自定义参数的格式为
yyyyMMddHHmmss,例如20230423175000。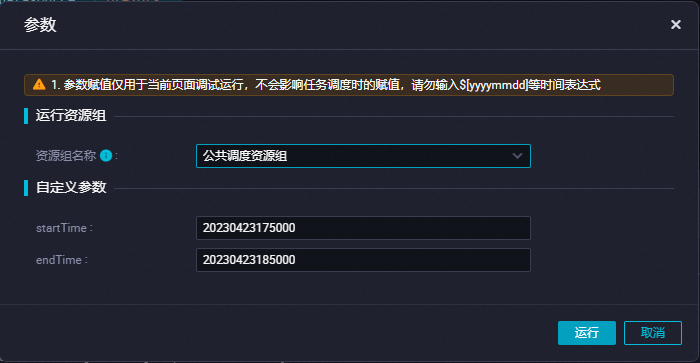
单击运行。
提交同步任务。
提交同步任务后,同步任务会按照配置的调度属性进行运行。
单击
 图标。
图标。在提交对话框,根据需要填写变更描述。
单击确认。
步骤五:查看任务执行结果
在DataWorks控制台查看任务运行状态。
单击同步任务工具栏右侧的运维。
在周期实例页面的实例视角页签,查看实例的运行状态。
在OSS管理控制台查看数据同步结果。
登录OSS管理控制台。
在Bucket列表页面,找到目标Bucket后,单击Bucket名称。
在文件列表页签,选择相应文件,下载后可查看内容是否符合预期。
常见问题
相关文档
- 本页导读 (1)
- 注意事项
- 准备工作
- 步骤一:新建同步任务节点
- 步骤二:配置离线同步任务并启动
- 同步数据表数据的任务配置
- 同步时序表数据的任务配置
- 步骤三:配置调度属性
- 步骤四:调试代码并提交任务
- 步骤五:查看任务执行结果
- 常见问题
- 相关文档