
通过DataWorks数据集成服务将表格存储中的全量数据导出到OSS,可实现以更低成本备份数据或将数据以文件形式导出到本地。全量数据导出到OSS后,可自由下载文件到本地进行进一步处理。
前提条件
开始数据导出前,需要完成以下准备工作:
获取Tablestore源表的实例名称、实例访问地址、地域ID等信息。
为阿里云账号或RAM用户(具备Tablestore与OSS服务的权限)创建AccessKey。
开通DataWorks服务,并在OSS存储空间或Tablestore实例所在地域创建工作空间。
创建Serverless资源组并绑定到工作空间。有关计费信息,请参见Serverless资源组计费。
当DataWorks和Tablestore实例位于不同地域时,需要创建VPC对等连接实现跨地域网络连通。
以下以源表实例位于华东2(上海)地域,DataWorks工作空间位于华东1(杭州)地域的场景为例进行说明。
-
为Tablestore实例绑定VPC。
-
登录表格存储控制台,在页面上方选择目标表所在地域。
-
单击实例别名进入实例管理页面。
-
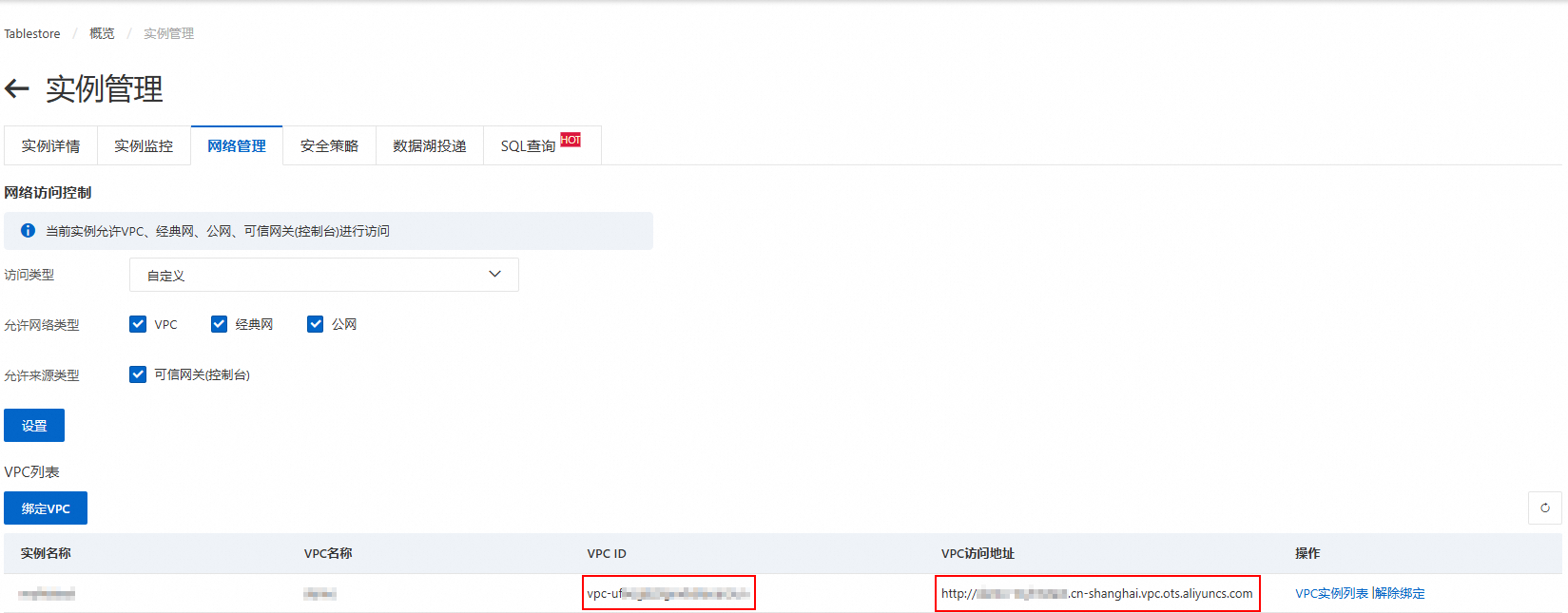
切换到网络管理页签,单击绑定VPC,选择VPC和交换机并填写VPC名称,然后单击确定。
-
等待VPC绑定完成,页面将自动刷新,可在VPC列表查看绑定的VPC ID和VPC访问地址。
说明在DataWorks控制台添加Tablestore数据源时,需使用该VPC访问地址。
-
-
获取DataWorks工作空间资源组的VPC信息。
-
登录DataWorks控制台,在页面上方选择工作空间所在地域,然后单击左侧工作空间菜单,进入工作空间列表页面。
-
单击工作空间名称进入空间详情页面,单击左侧资源组菜单,查看工作空间绑定的资源组列表。
-
在目标资源组右侧单击网络设置,在资源调度 & 数据集成区域查看绑定的专有网络,即VPC ID。
-
-
创建VPC对等连接并配置路由。
-
登录专有网络VPC控制台,在页面左侧单击VPC对等连接菜单,然后单击创建对等连接。
-
在创建对等连接页面,输入对等连接名称,选择发起端VPC实例、接收端账号类型、接收端地域和接收端VPC实例,单击确定。
-
在VPC对等连接页面,找到已创建的VPC对等连接,分别在发起端和接收端列单击配置路由条目。
目标网段需填写对端VPC的网段地址。即在发起端配置路由条目时,填写接收端的网段地址;在接收端配置路由条目时,填写发起端的网段地址。
-
操作步骤
按照以下步骤配置并执行数据导出任务。
步骤一:新增表格存储数据源
首先在DataWorks中配置表格存储数据源,建立与源数据的连接。
-
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
-
在左侧导航栏,单击数据源。
-
在数据源列表页面,单击新增数据源。
-
在新增数据源对话框,搜索并选择数据源类型为Tablestore。
-
在新增OTS数据源对话框,根据下表配置数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
地域
选择Tablestore实例所属地域。
Table Store实例名称
Tablestore实例的名称。
Endpoint
Tablestore实例的服务地址,推荐使用VPC地址。
AccessKey ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
AccessKey Secret
-
测试资源组连通性。
创建数据源时,需要测试资源组的连通性,确保同步任务使用的资源组能够与数据源正常连通,否则将无法正常执行数据同步任务。
-
在连接配置区域,单击相应资源组连通状态列的测试连通性。
-
测试连通性通过后,连通状态显示可连通,单击完成。可在数据源列表中查看新建的数据源。
如果测试连通性结果为无法通过,可使用连通性诊断工具自助解决。
-
步骤二:新增OSS数据源
配置OSS数据源作为数据导出的目标存储。
再次单击新增数据源,在对话框中搜索并选择数据源类型为OSS,并配置相关的数据源参数。
参数
说明
数据源名称
数据源名称必须以字母、数字、下划线(_)组合,且不能以数字和下划线(_)开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
访问模式
RAM角色授权模式:DataWorks服务账号以角色扮演的方式访问数据源。首次选择该模式时,请根据页面提示开启授权。
Access Key模式:通过阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret访问数据源。
选择角色
仅当访问模式为RAM角色授权模式时需要选择RAM角色。
AccessKey ID
仅当访问模式为Access Key模式时需要填写。阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
AccessKey Secret
地域
Bucket所在地域。
Endpoint
OSS访问域名,详见地域和Endpoint。
Bucket
Bucket名称。
完成参数和连通性测试后,单击完成添加数据源。
步骤三:配置离线同步任务
创建并配置数据同步任务,定义从表格存储到OSS的数据传输规则。
新建任务节点
进入数据开发页面。
登录DataWorks控制台。
在页面上方,选择资源组和地域。
在左侧导航栏,单击数据开发与运维 > 数据开发。
选择对应工作空间后单击进入Data Studio。
在Data Studio控制台的数据开发页面,单击项目目录右侧的
 图标,然后选择新建节点 > 数据集成 > 离线同步。
图标,然后选择新建节点 > 数据集成 > 离线同步。在新建节点对话框,选择路径,数据来源选择Tablestore,数据去向选择OSS,填写名称,然后单击确认。
配置同步任务
在项目目录下,单击打开新建的离线同步任务节点,通过向导模式或脚本模式配置同步任务。
向导模式(默认)
配置以下内容:
数据源:选择来源数据源和去向数据源。
运行资源:选择资源组,选择后会自动检测数据源连通性。
数据来源:
表:下拉选择来源数据表。
主键区间分布(起始):数据读取的起始主键,格式为JSON数组,
inf_min表示无限小。当主键包含1个
int类型的主键列id和1个string类型的主键列name时,示例配置如下:指定主键范围
全量数据
[ { "type": "int", "value": "000" }, { "type": "string", "value": "aaa" } ][ { "type": "inf_min" }, { "type": "inf_min" } ]主键区间分布(结束):数据读取的结束主键,格式为JSON数组,
inf_max表示无限大。当主键包含1个
int类型的主键列id和1个string类型的主键列name时,示例配置如下:指定主键范围
全量数据
[ { "type": "int", "value": "999" }, { "type": "string", "value": "zzz" } ][ { "type": "inf_max" }, { "type": "inf_max" } ]切分配置信息:自定义切分配置信息,格式为JSON数组,普通情况下不建议配置(设置为
[])。当Tablestore数据存储发生热点,且使用Tablestore Reader自动切分的策略不能生效时,建议使用自定义的切分规则。切分指定的是在主键起始和结束区间内的切分点,仅配置切分键,无需指定全部的主键。
数据去向:选择目标文本类型,并配置相关参数。
文本类型:可选类型包括csv、text、orc和parquet。
文件名(含路径):OSS Bucket内包含路径的文件名称,如
tablestore/resouce_table.csv。列分隔符:默认为
,,如果分隔符不可见,请填写Unicode编码,比如\u001b、\u007c。文件路径:仅当文本类型为parquet时填写,OSS Bucket内的文件路径。
文件名:仅当文本类型为parquet时填写,OSS Bucket内的文件名。
去向字段映射:配置来源数据表到目标文件的字段映射,一行表示一个字段,格式为JSON。
来源字段:包含来源数据表的主键字段和属性列字段。
当主键包含1个
int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age时,示例配置如下:{"name":"id","type":"int"} {"name":"name","type":"string"} {"name":"age","type":"int"}目标字段:包含来源数据表的主键字段和属性列字段。
当主键包含1个
int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age时,示例配置如下:{"name":"id","type":"int"} {"name":"name","type":"string"} {"name":"age","type":"int"}
配置完成后,单击页面上方的保存。
脚本模式
单击页面上方的脚本模式,在切换后的页面中编辑脚本。
以下示例配置以目标文件类型为csv为例,来源数据表主键包含1个int类型的主键列id和1个string类型的主键列name,属性列包含1个int类型的字段age。配置时请替换示例脚本内的数据源datasource、表名称table以及写入文件名object。
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "ots",
"parameter": {
"datasource": "source_data",
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"range": {
"begin": [
{
"type": "inf_min"
},
{
"type": "inf_min"
}
],
"end": [
{
"type": "inf_max"
},
{
"type": "inf_max"
}
],
"split": []
},
"table": "source_table",
"newVersion": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "oss",
"parameter": {
"dateFormat": "yyyy-MM-dd HH:mm:ss",
"datasource": "target_data",
"writeSingleObject": false,
"column": [
{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "int"
}
],
"writeMode": "truncate",
"encoding": "UTF-8",
"fieldDelimiter": ",",
"fileFormat": "csv",
"object": "tablestore/source_table.csv"
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 2,
"throttle": false
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}脚本编辑完成后,单击页面上方的保存。
运行同步任务
单击页面上方的运行,开始同步任务,首次运行时需确认调试配置。
步骤四:查看同步结果
运行同步任务后,可通过日志查看任务的执行状态,并在OSS Bucket查看同步结果文件。
-
在页面下方查看任务运行状态和结果,出现以下信息时表示同步任务运行成功。
2025-11-18 11:16:23 INFO Shell run successfully! 2025-11-18 11:16:23 INFO Current task status: FINISH 2025-11-18 11:16:23 INFO Cost time is: 77.208s 查看目标Bucket的文件。
前往Bucket列表,单击目标Bucket,查看或下载同步结果文件。