
该文档仅适用于召回引擎传统版实例,即实例创建时间在2024-06之前,在此之后创建的实例,对应文档请参见新版-多路召回实战。
方案架构
该文档主要介绍如何通过召回引擎版实现文本、向量多路召回。
该实践可用于有大模型算法的团队实现对话式搜索服务,方案架构如下(比较简略,后期会优化的):
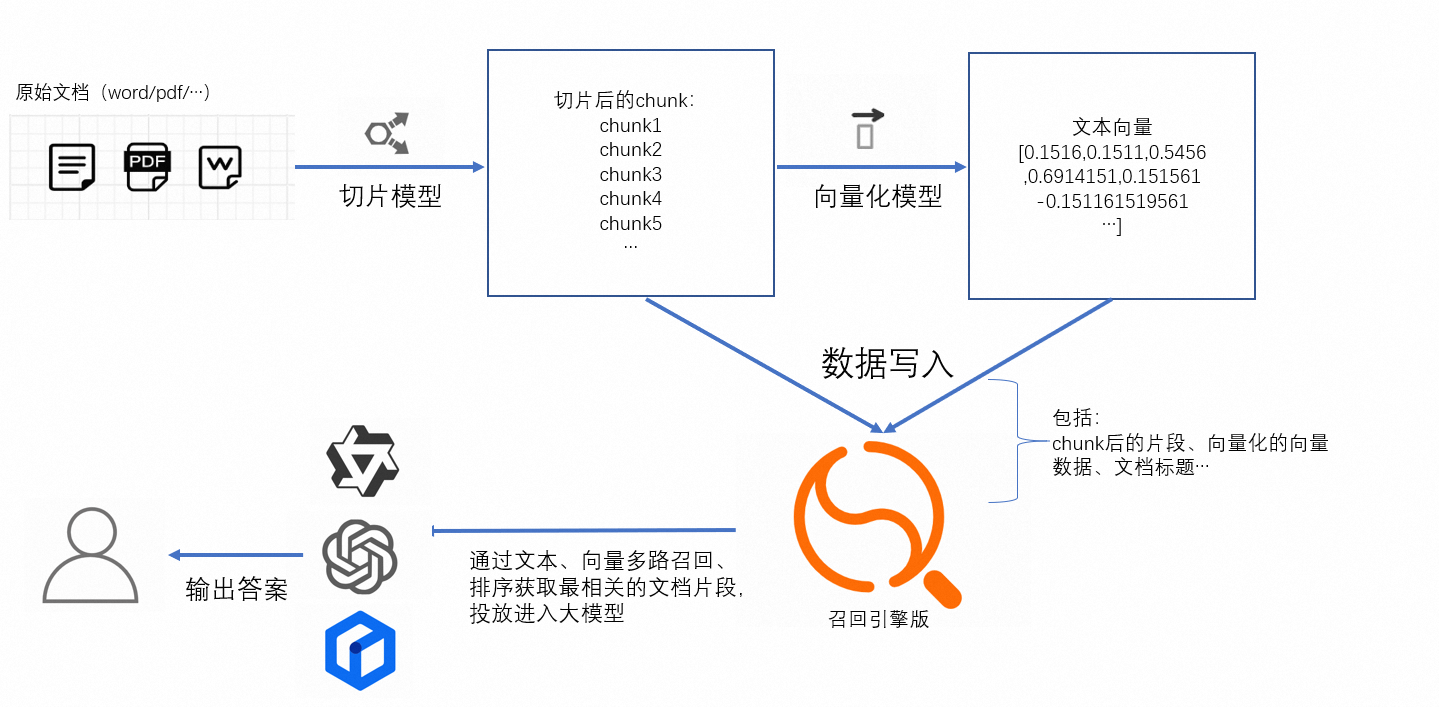
以上就是对话式搜索的简易架构,召回引擎版在整个架构中类似于向量检索数据库,支持用户通过向量和文本进行多路召回,同时支持丰富的排序函数和表达式,可以满足不同用户的不同排序需求,使得最终召回的结果最符合用户问题的答案。
以上架构使得整个对话式搜索服务变得更加灵活,用户可以根据自己的业务定制:切片模型、向量化模型,以及后面format的大模型。(此处召回引擎版仅支持文本向量化和图片向量化,其余的模型需要业务方有自己的算法团队进行探索)。
基于对话式搜索服务配置召回引擎实例
根据以往用户的问题,本文中会举出一些通用的配置方法和排序表达式,用户可以直接使用。
整个配置流程分3部分:
表结构的设计:此处将介绍对话式搜索服务需要的必选字段,以及这些字段如何在召回引擎版中配置索引
查询语法:此处将介绍如何通过ha3语法实现在召回引擎版的多路召回(文本、向量)功能。
文档排序:由于向量和文本是不同维度的,多路召回后有文本召回的doc,也有向量召回的doc,其中如何编写排序表达式,使得召回的结果中top1或者topN的结果为最相关的至关重要
表结构设计
基于对话式搜索的交互页面:(以智能问答版为例)
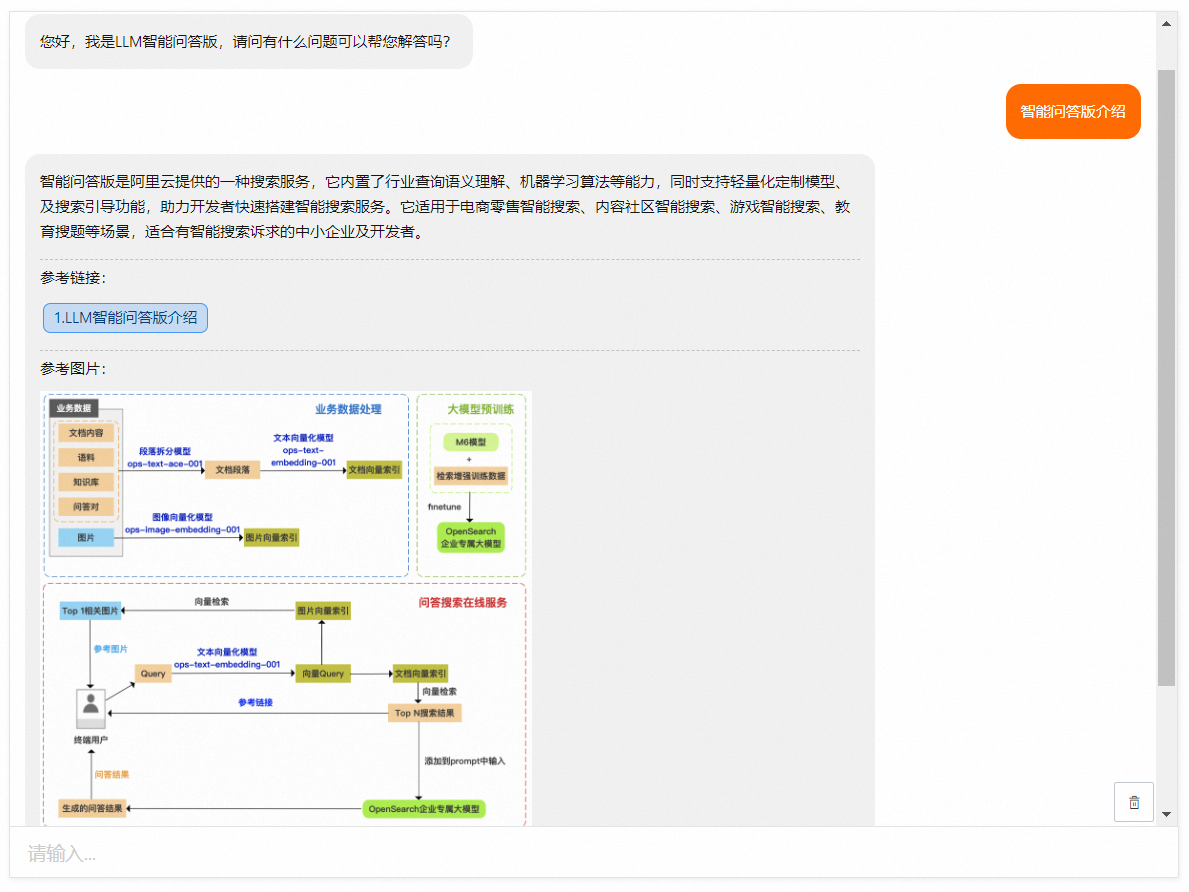
在设计表时需要有以下字段:
字段名称 | 类型 | 说明 | 是否必须 |
pk | STRING/INT64 | 主键 | 必须 |
chunk_id | STRING/INT64 | 片段的唯一标识 | 可选 |
doc_id | STRING/INT64 | 原始文档的唯一标识 | 可选 |
content | TEXT | 切片后的文档内容 | 必须 |
title | TEXT | 文档标题 | 可选 |
embedding | 多值float | content向量化后的向量 | 必须 |
url | STRING | 原文链接 | 可选 |
picture | 多值float | 图片向量化后的向量 | 可选 |
namespace | STRING | 命名空间 | 可选(用于不同类型的数据隔离) |
DUP_content | STRING | 基于content复制出的字段 | 必须(用于content的展示) |
以上字段仅供参考,业务有其他需求可以自定义其他字段。
索引设计:
索引名称 | 类型 | 包含字段 | 是否必须 | 说明 |
pk | PRIMARYKEY64 | pk | 必须 | 主键索引 |
default | PACK | content | 必须 | 用于文本一路召回 |
vector | CUSTOMIZED | pk,embedding (如果有namespace,可以配置上) | 必须 | 用于向量一路召回 |
title | PACK | title | 可选 | 用于标题召回 |
chunk_id | chunk_id | STRING | 可选 | 通过chunk_id召回片段 |
doc_id | doc_id | STRING | 可选 | 通过doc_id 召回该doc的所有片段 |
除此之外,所有的字段都需要配置搜索结果展示,非text类型的字段都勾选属性字段。
另外向量的维度根据算法生成的出的向量维度而定,向量举例为欧式距离和内积,如果需要余弦相似度,可以把向量归一化为[-1,1]然后取内积距离,向量检索算法有qc和HNSW,根据自己的算法而定。
配置截图如下:
字段配置:
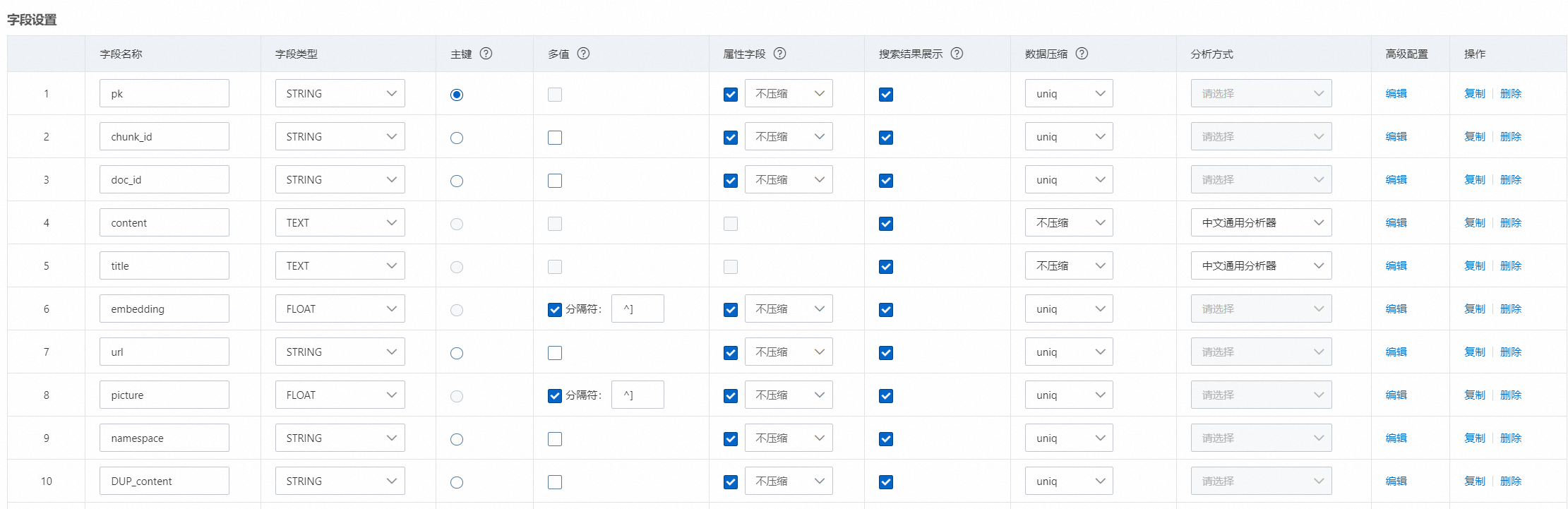
DUP_content字段需要在高级配置中配置,表示该字段的内容同content一致:
{
"copy_from": "content"
}索引配置:
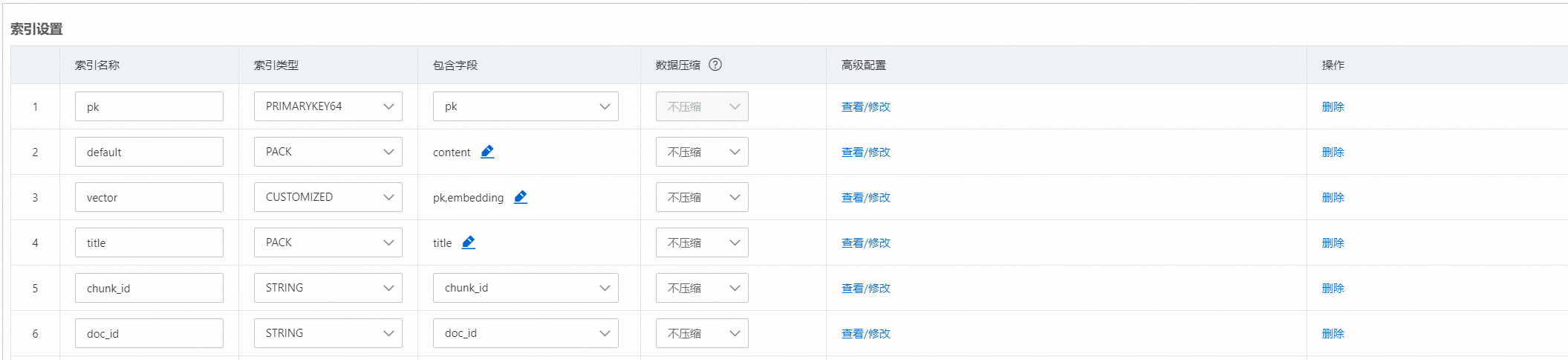
所有PACK类型的索引,必须在高级配置中配置如下内容:(在后面文本算分时会用到)
开发者模式的schema如下:
{
"file_compress": [
{
"name": "file_compressor",
"type": "zstd"
},
{
"name": "no_compressor",
"type": ""
}
],
"table_name": "main",
"summarys": {
"summary_fields": [
"pk",
"chunk_id",
"doc_id",
"content",
"title",
"embedding",
"url",
"picture",
"namespace",
"DUP_content"
],
"parameter": {
"file_compressor": "zstd"
}
},
"indexs": [
{
"index_name": "pk",
"index_type": "PRIMARYKEY64",
"index_fields": "pk",
"has_primary_key_attribute": true,
"is_primary_key_sorted": false
},
{
"index_name": "default",
"index_type": "PACK",
"index_fields": [
{
"boost": 1,
"field_name": "content"
}
],
"doc_payload_flag": 1,
"has_section_attribute": true,
"position_payload_flag": 1,
"term_frequency_bitmap": 0,
"position_list_flag": 1,
"term_payload_flag": 1,
"term_frequency_flag": 1,
"section_attribute_config": {
"has_field_id": true,
"has_section_weight": true
}
},
{
"index_name": "vector",
"index_type": "CUSTOMIZED",
"index_fields": [
{
"boost": 1,
"field_name": "pk"
},
{
"boost": 1,
"field_name": "embedding"
}
],
"indexer": "aitheta2_indexer",
"parameters": {
"enable_rt_build": "true",
"min_scan_doc_cnt": "20000",
"vector_index_type": "Qc",
"major_order": "col",
"builder_name": "QcBuilder",
"distance_type": "SquaredEuclidean",
"embedding_delimiter": ",",
"enable_recall_report": "true",
"ignore_invalid_doc": "true",
"is_embedding_saved": "false",
"linear_build_threshold": "5000",
"dimension": "128",
"rt_index_params": "{\"proxima.oswg.streamer.segment_size\":2048}",
"search_index_params": "{\"proxima.qc.searcher.scan_ratio\":0.01}",
"searcher_name": "QcSearcher",
"build_index_params": "{\"proxima.qc.builder.quantizer_class\":\"Int8QuantizerConverter\",\"proxima.qc.builder.quantize_by_centroid\":true,\"proxima.qc.builder.optimizer_class\":\"BruteForceBuilder\",\"proxima.qc.builder.thread_count\":10,\"proxima.qc.builder.optimizer_params\":{\"proxima.linear.builder.column_major_order\":true},\"proxima.qc.builder.store_original_features\":false,\"proxima.qc.builder.train_sample_count\":3000000,\"proxima.qc.builder.train_sample_ratio\":0.5}"
}
},
{
"index_name": "title",
"index_type": "PACK",
"index_fields": [
{
"boost": 1,
"field_name": "title"
}
],
"doc_payload_flag": 1,
"has_section_attribute": true,
"position_payload_flag": 1,
"term_frequency_bitmap": 0,
"position_list_flag": 1,
"term_payload_flag": 1,
"term_frequency_flag": 1,
"section_attribute_config": {
"has_field_id": true,
"has_section_weight": true
}
},
{
"index_name": "chunk_id",
"index_type": "STRING",
"index_fields": "chunk_id"
},
{
"index_name": "doc_id",
"index_type": "STRING",
"index_fields": "doc_id"
}
],
"attributes": [
{
"field_name": "pk",
"file_compress": "no_compressor"
},
{
"field_name": "chunk_id",
"file_compress": "no_compressor"
},
{
"field_name": "doc_id",
"file_compress": "no_compressor"
},
{
"field_name": "embedding",
"file_compress": "no_compressor"
},
{
"field_name": "url",
"file_compress": "no_compressor"
},
{
"field_name": "picture",
"file_compress": "no_compressor"
},
{
"field_name": "namespace",
"file_compress": "no_compressor"
},
{
"field_name": "DUP_content",
"file_compress": "no_compressor"
}
],
"fields": [
{
"user_defined_param": {},
"field_name": "pk",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "chunk_id",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"field_name": "doc_id",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"user_defined_param": {},
"field_name": "content",
"field_type": "TEXT",
"analyzer": "chn_standard"
},
{
"user_defined_param": {},
"field_name": "title",
"field_type": "TEXT",
"analyzer": "chn_standard"
},
{
"user_defined_param": {},
"field_name": "embedding",
"field_type": "FLOAT",
"compress_type": "uniq",
"multi_value": true
},
{
"field_name": "url",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"user_defined_param": {},
"field_name": "picture",
"field_type": "FLOAT",
"compress_type": "uniq",
"multi_value": true
},
{
"field_name": "namespace",
"field_type": "STRING",
"compress_type": "uniq"
},
{
"user_defined_param": {
"copy_from": "content"
},
"field_name": "DUP_content",
"field_type": "STRING",
"compress_type": "uniq"
}
]
}查询语法说明
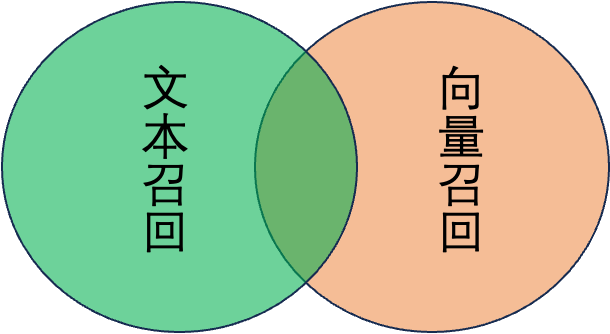
如图所示,多路召回其中有一部分文档,是只用向量检索回来的,有一部分是用文本检索回来的,而有一部分可以匹配两路的查询。那么在查询的时候如何进行组合呢?
这里需要说明不同组合方式的区别:
首先在大的方面,以上述配置的schema为例:
文本与向量 AND 召回:
query=default:'xxx' AND vector:'xxx'此种方式召回即为向量和文本同时命中的部分,召回逻辑是,比如向量一路召回取100个结果,则先通过向量召回100个相关度最高的结果,再在100个结果里进行文本匹配,两路全部匹配的内容作为最终的召回结果。
弊端:此种组合方式经常会出现召回不全的情况,或一些相关度比较高的doc并未召回的情况。
文本与向量 OR 召回:
query=default:'xxx' OR vector:'xxx'此种方式召回即取文本召回和向量召回的并集。
弊端:会引入一些文本召回的bad caase,比如:搜索“歌曲黑色毛衣”,有两个doc,content分别为“周杰伦的歌曲《黑色毛衣》”和“我在下雨天穿着一件黑色的毛衣,嘴里哼着一首悲伤的歌曲”,很明显前一个doc更符合预期同时向量召回该doc的相关度也比较高,但是文本一路的召回后一个doc的相关度也比较高。
其次,针对与文本一路,又有2种召回方式:
and方式:文本内容分词后的term全匹配召回
or 方式:文本分词后的term匹配上一个即可召回
举个简单的例子,搜索“我在杭州等你”,其中有两个doc内容分别为“杭州欢迎你”和“我在杭州余杭,等你”
如果是and的方式只能召回后一个doc,如果是or方式可以将两个doc都召回。
and的方式的弊端:会因为分词的bad case导致相关的结果无法召回,比如:“德意澳,三日游”,分词可能是“德意|澳,三|日|游”,如果搜索“德”就无法把这条doc召回,出现了空结果的情况
or方式的弊端:很显然or 的方式是为了扩大召回而使用,该种情况会召回大量不相关的doc,干扰排序结果。
经过多年经验沉淀,以上组合方式中,召回率较高,同时效果较好的召回方式为:
query=vector:'xxx&n=100&sf=1.100000' OR default:'xxx'其中向量索引中的:
n:表示向量召回的topN
sf:控制向量相似度得分,欧式距离为上限,内积距离为下限
如果不在config里配置default_operator参数,默认文本召回为and方式召回,详情可参考config子句
如果向量模型相对优秀的话,也可以仅仅用向量召回即可。
补充:相关文档参考
文档排序
该步骤中,在通过文本、向量多路召回后,召回后的doc是没有顺序的,或者说顺序是不符合我们预期的,因此需要通过排序表达式去干预已召回文档的排序,使top1或者top5是最相关的答案。
以上根据经验给出不同方式召回的排序表达式:
文本 OR 向量:
formula:if(query_min_slide_window(title\, true\, title)>0.99\, 1\, 0)+
if(query_min_slide_window(content\, true\, default)>0.99\, 0.5\, 0)
+text_relevance(content)*0.2+normalize(score)*0.1-proxima_score(vector)其中formula表示精排算分表达式,引擎在排序时有2阶段排序,先粗排first_formula,然后在精排formula,进入精排的文档默认分会+10000分,引擎通过config中的rerank_size() 控制进入精排的doc数。
proxima_score()函数,在多路召回中,如果文档是文本召回的但向量未召回,该函数的得分默认会是10000分,如果需要调整可以加入另一个参数,proxima_score(vector,default_value),其中default_value表示在未通过向量召回时该函数的默认得分。
补充:相关参考文档
以下给出一个完整的查询语句,仅供参考:
query=vector:'xxx&n=100&sf=1.100000' OR default:"1948年在城南庄发生了什么"
OR title:'1948年在城南庄发生了什么'&&cluster=general&&sort=-RANK
&&config=start:0,hit:3,rerank_size:100,format:json
&&kvpairs=fetch_fields:pk;content,
formula:if(query_min_slide_window(title\, true\, title)>0.99\, 1\, 0)
+if(query_min_slide_window(content\, true\, default)>0.99\, 0.5\, 0)
+text_relevance(content)*0.2+normalize(score)*0.1-proxima_score(vector)召回 & 排序 bad case
短查询场景下,提升文本分数权重:
用户输入的查询为 "arthas性能分析"。
下面是上述query串得到的排序最靠前的文档:

可以看到,召回的内容并不相关,通过打开trace开关,可以发现,该文档是通过向量一路召回的。文档的召回无法调节,但是可以分析文档排到最前面的原因,通过排序表达式将更相关的文档排序到前面。
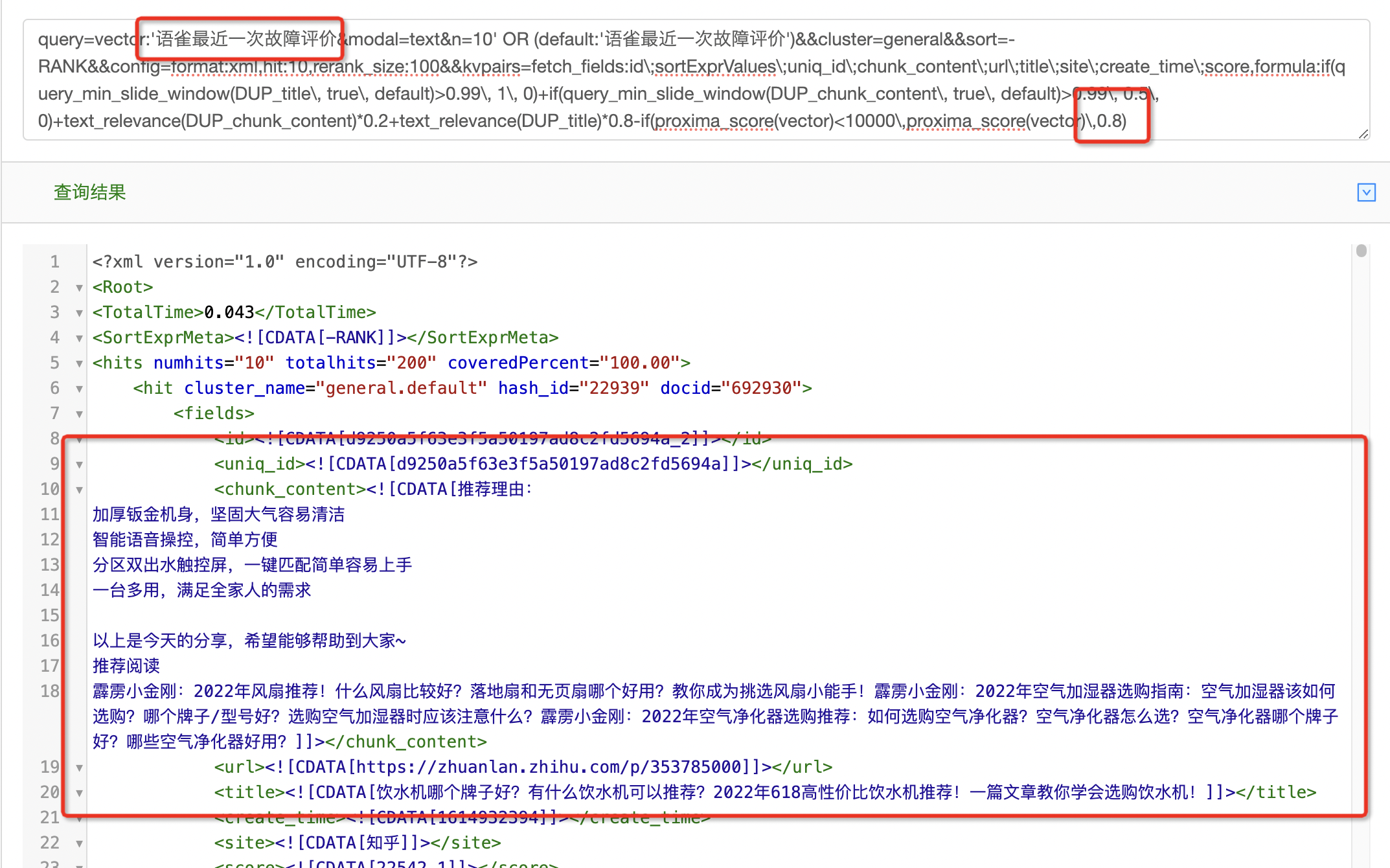
通过对上述query进行分析,可以看到,上述query串会优先将向量召回的结果排到前面。其原因在于,如果文档是通过文本召回的,proxima_score的分数是10000,整个表达式的分数会变得很小,因此,文本召回的文档在排序中并不占有优势。因此,在这里,将proxima_score相关的部分修改为
if(proxima_score(vector)<10000\,proxima_score(vector)\,a)通过对参数a的设置,可以调节向量分数和文本分数之间的权重关系。
将a设置为0,则表示优先使用文本召回的文档

可以看到,针对"arthas性能分析"的查询,文本召回可以得到更好的结果。
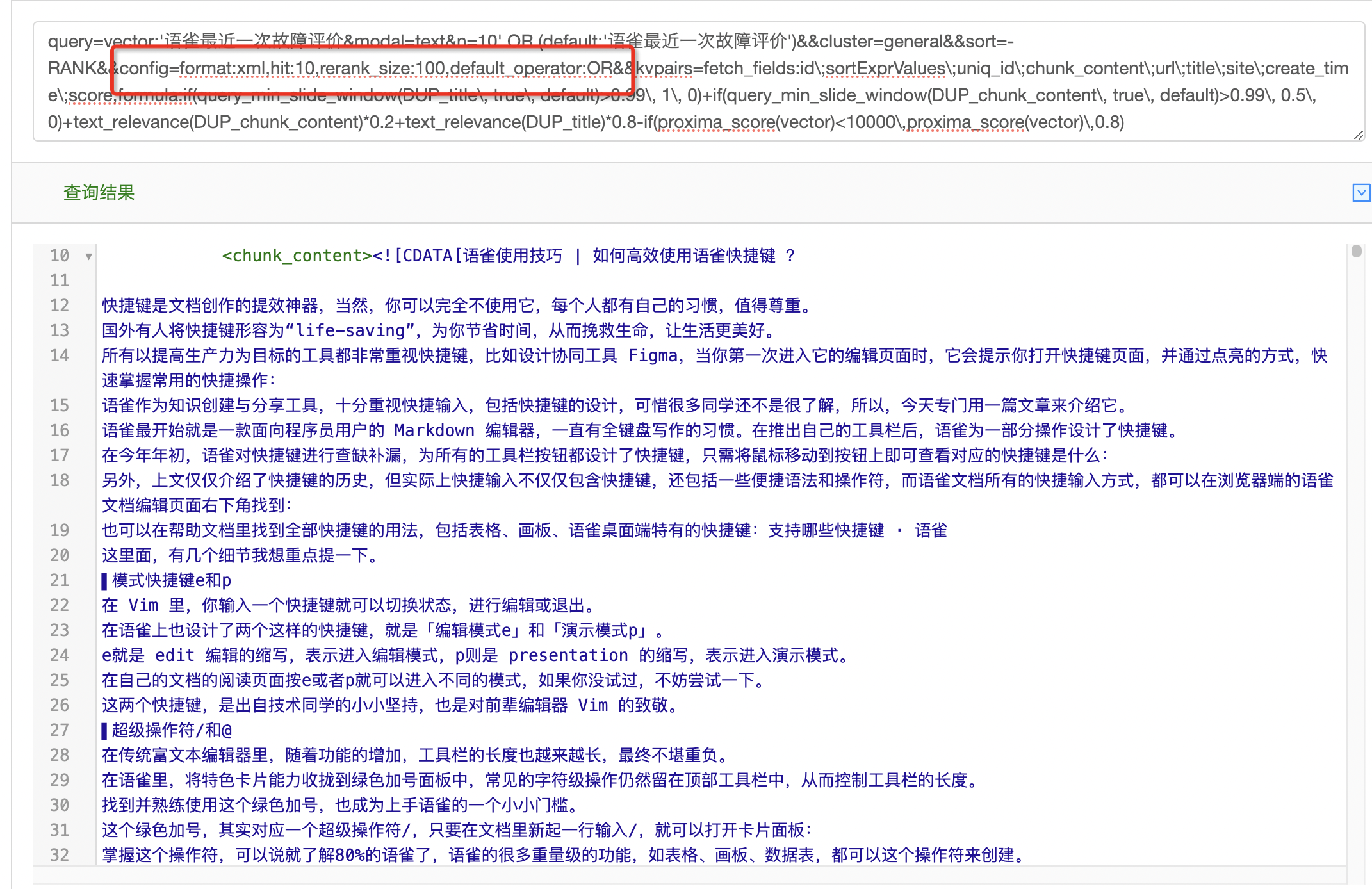
文本召回使用OR 逻辑,增强召回内容相关性
上述查询串中,文本召回的逻辑默认是AND:查询串进行分词之后,索引中的文本需要匹配所有分词才会召回。这样的逻辑固然会增加召回结果的相关性,但是也会有文本召回结果为空的情况。在上述查询串中,还有向量召回一路,因此,该情况下只会使用向量召回的结果,最后结果的排序也只会使用向量相似度。
如使用上述模板,有如下查询结果:
可以看到,召回结果第一条明显是不相关的内容。通过trace可以看到,这条数据是通过向量一路召回的。向量召回的结果,相关性完全取决于向量模型,而如果使用的是通用的模型,往往会有召回不准确的情况。
文本召回一定程度上可以保证召回的文档是相关的,而让更多的文档参与到最后的结果中,可以将上述文本召回的逻辑由AND改为OR。
可以看到,召回的文档相比上面的结果有提升。