
场景说明
本文主要介绍,如何在向量检索版中使用static_bm25函数、text_relevance函数在粗排和精排阶段获取文本相关性得分并排序。
重要
该文档仅适用于召回引擎传统版实例,即实例创建时间在2024-06之前,在此之后创建的实例,对应文档请参见新版-通过pack索引实现文本相关性排序。
pack索引配置
这里通过演示2个字段组合pack:
首先,需要设置pack索引的两个字段,类型设置为text,同时分析方式需要相同:
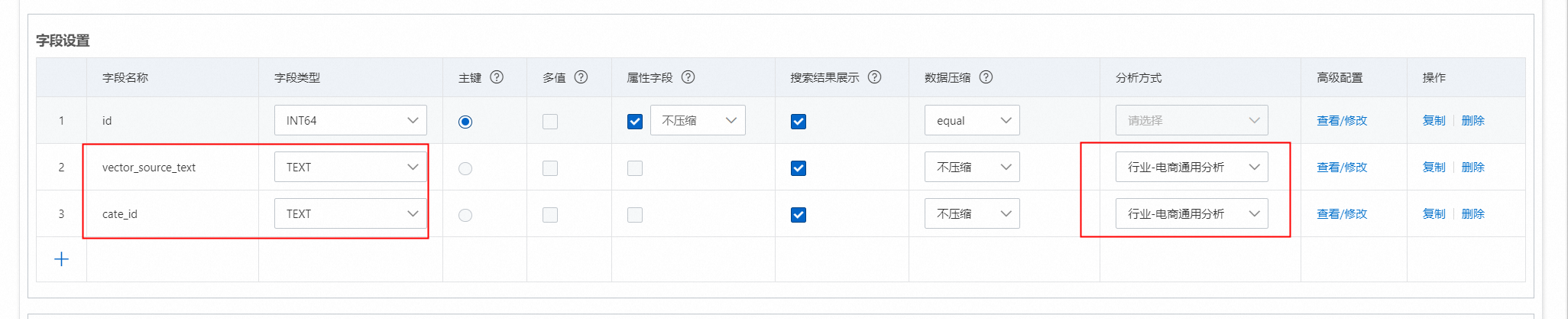
然后,设置索引,索引类型设置PACK,设置包含字段:
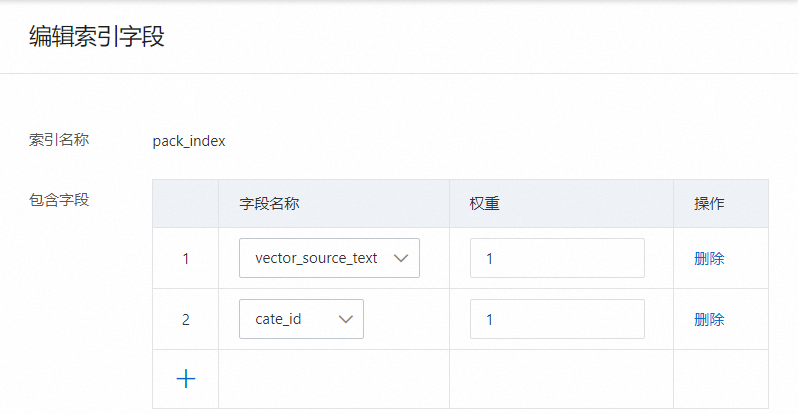
这里需要注意,如果上述设置字段时,顺序为vector_source_text在前、cate_id在后,那么编辑pack索引的字段时,也需要按照这个顺序,否则在保存发布时会报错。
接下来,设置pack索引的高级配置:
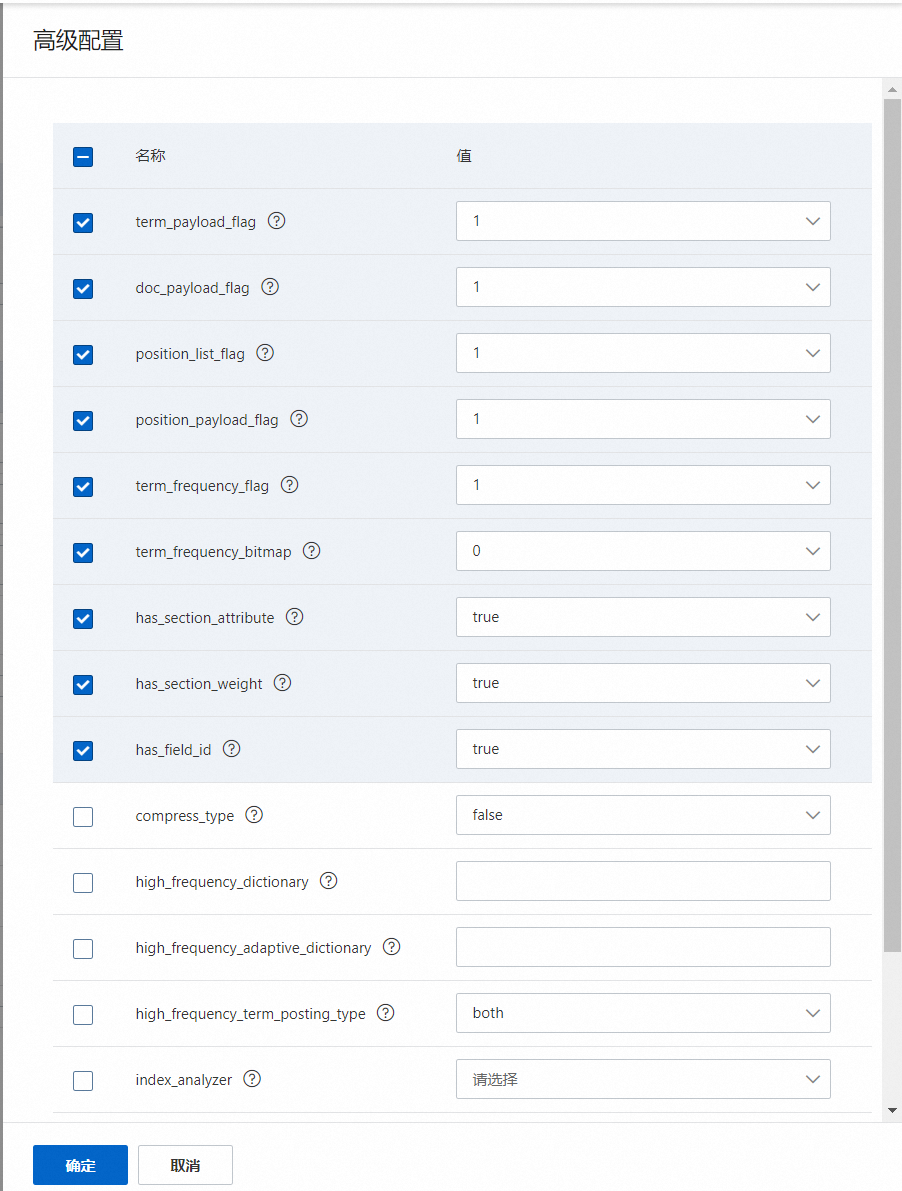
pack索引配置示例:
{
"index_name": "pack_index",
"index_type": "PACK",
"index_fields": [
{
"boost": 1,
"field_name": "vector_source_text"
},
{
"boost": 1,
"field_name": "cate_id"
}
],
"doc_payload_flag": 1,
"has_section_attribute": true,
"position_payload_flag": 1,
"term_frequency_bitmap": 0,
"position_list_flag": 1,
"term_payload_flag": 1,
"term_frequency_flag": 1,
"section_attribute_config": {
"has_field_id": true,
"has_section_weight": true
}
}最后,点击发布即可。
发布完成后,推送离线配置,并索引重建,即可进行查询测试
查询配置
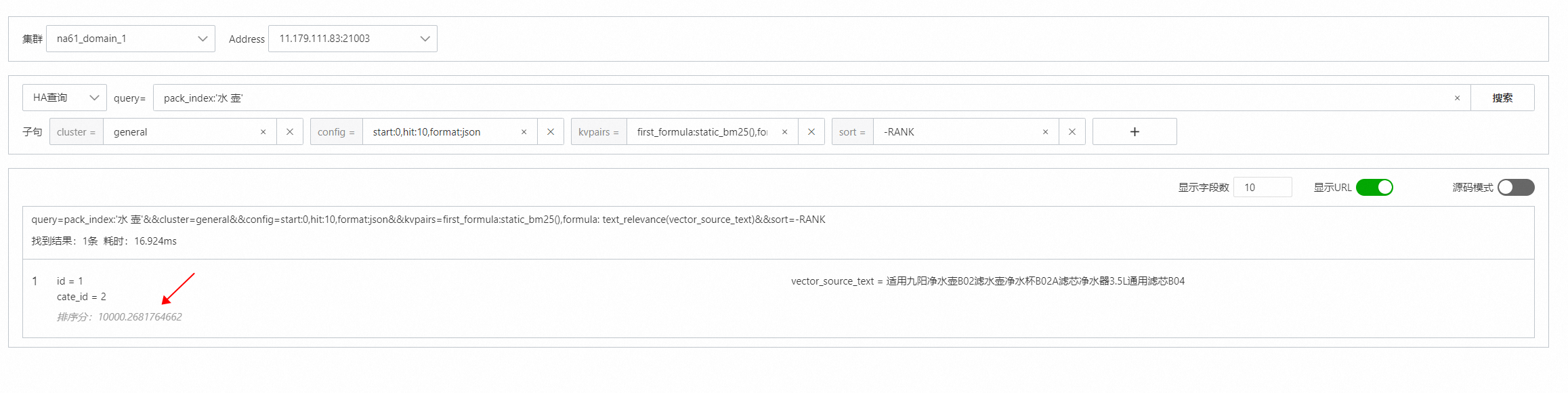
通过ha语法进行查询:
query=pack_index:'水 壶'&&cluster=general&&config=start:0,hit:10,format:json
&&kvpairs=first_formula:static_bm25(),
formula: text_relevance(vector_source_text)&&sort=-RANKfirst_formula设置粗排表达式
●formula设置精排表达式
●sort=-RANK 设置doc使用文本得分排序
结果展示:
算分信息查看:(在config子句中添加rank_trace:all)
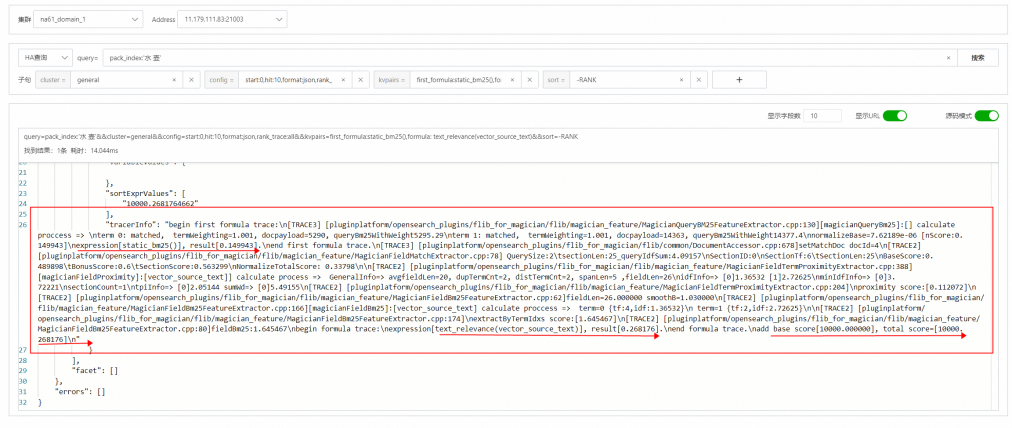
常见问题
用户反馈:
粗排配置没问题,但是得分一直是10000:
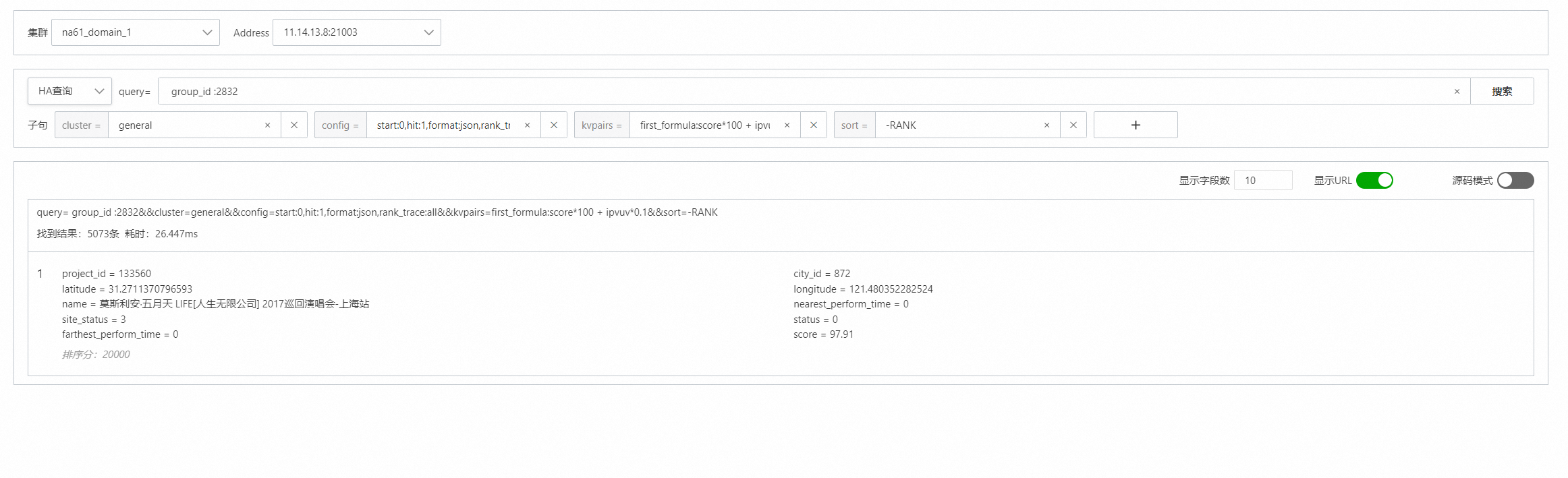
config里加一个参数:rank_trace:all
"tracerInfo": "begin first formula trace:\nexpression[ipvuv],
result[8819].\nexpression[ipvuv*0.1], result[881.900024].\nexpression[score],
result[97.910000].\nexpression[score*100],
result[9791.000000].\nexpression[score*100+ipvuv*0.1],
result[10672.900024].\nscore [10000.000000] is larger
than max_first_score [10000.000000], adjust it to max_first_score.\nend
first formula trace.\n"这是因为粗排最大是10000分,超过10000,则默认设置为10000。
该文章对您有帮助吗?