
Quick Audience接入数据源后,您就可以将要导入的数据表存储在计算源,然后在Quick Audience声明数据表的表结构,执行调度任务,将表中的数据导入到Quick Audience,准备用于后续的分析、应用。
数据导入流程
进行ID类型管理,设置Quick Audience支持的用户ID类型,以及用户ID参与ID Mapping的策略。
进行用户属性管理,构建用户属性信息体系。
配置表结构:
说明Quick Audience对以下各类型数据表的格式要求,请参见数据表要求。
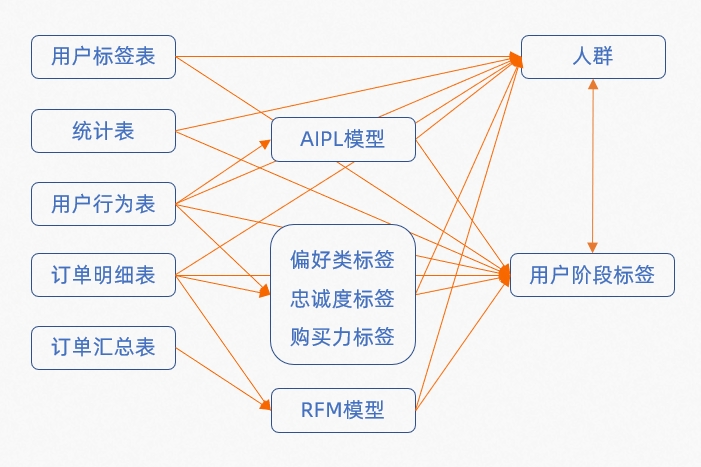
用户标签表:用户标签表记录用户的一系列特征属性,用于透视分析、人群筛选等。
配置用户标签表结构时,将同时指定哪些标签携带了用户属性信息。
用户行为表:用户行为表记录用户的浏览、加购、收藏、购买等行为。基于用户行为数据,可以进行人群筛选,还可以生成AIPL模型、偏好类标签等自定义标签,AIPL模型可用于AIPL用户分析、AIPL流转分析、人群筛选等。
订单明细表:订单明细表记录子订单粒度的订单信息。基于用户行为数据,可以进行人群筛选,还可以生成RFM模型、偏好类标签等自定义标签,RFM模型可用于RFM分析、人群筛选等。
订单汇总表:订单汇总表记录将近N天内的订单数据按用户粒度进行汇总而成的数据。导入的数据可生成RFM模型,RFM模型可用于RFM分析、人群筛选等。
说明您也可以通过API接口导入以上所有类型的数据表,请向接口人获取API说明。
各类表生成AIPL/RFM模型、自定义标签、人群的链路如下图所示。
执行调度任务:
针对已配置的表结构,通过调度任务,手动调度或周期性调度执行数据导入,同时进行计算整合。
一个导入任务至少需要调度执行一次,否则Quick Audience侧无相应数据;若计算源侧数据已更新,请再次调度执行导入任务,以便在后续的分析中使用最新数据。
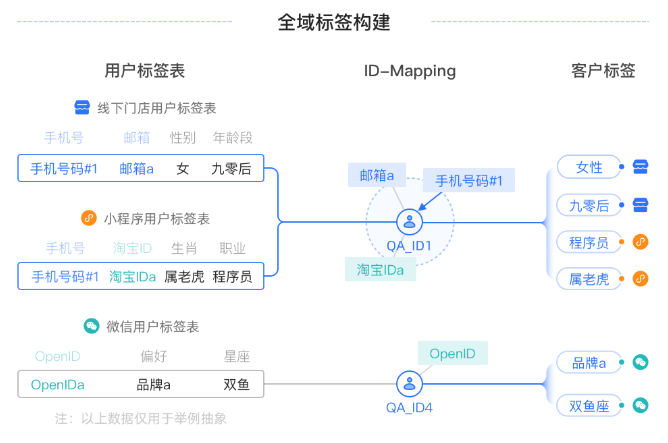
导入时,系统将基于ID进行用户身份识别(将同一个ID识别为同一个用户,进行去重),对去重后的用户赋予一个QAID,这一计算过程称为ID Mapping。具体计算逻辑,请参见ID Mapping与用户唯一标识QAID。
说明由于每次调度时都需要对所有数据表涉及的用户重新进行ID Mapping计算,为了避免频繁占用计算资源,建议您将所有数据表的调度创建为同一个任务。
在后续的用户分析、人群筛选等操作中,QAID将作为用户的唯一身份标识。不论用户或人群来自哪个表,均通过其QAID去查询所有ID类型和标签、行为等数据,实现跨渠道数据整合,最终构建一个全渠道标签系统。
FAQ
导入数据表时有哪些注意事项?
答:在您进行数据表结构配置和调度任务配置时,请注意:
由于数据表在MaxCompute计算源中存储时名称均为英文,设置数据表别名能更方便地识别已导入的表,您可以在数据表别名中加入数据来源、品牌、表类型、用途等信息。
配置表结构时,请正确选择ID字段的类型和当前加密状态,支持选择MD5、SHA256、AES、未加密。
其中,若ID字段已AES加密,则您需要在组织系统配置中输入密钥,导入后系统将对密文进行解密,在使用时将使用原文。
在后续的推送、营销等使用场景下,某些渠道仅支持特定的ID类型和加密类型。
由于每次调度时都需要对所有数据表涉及的用户重新进行ID Mapping计算,为了避免频繁占用计算资源,建议您将所有数据表的调度创建为同一个任务。
不支持为同一个数据表配置多个数据表结构。不支持将同一个数据表加入多个调度任务。
若一个调度任务显示为执行成功,代表该任务包含的所有表导入成功;若显示执行失败,请将鼠标移动到执行失败上方查看每个表的报错信息,整改后单击
 图标手动重试。
图标手动重试。