宽表模型(WideColumn)是类Bigtable/HBase模型,可应用于元数据、大数据等多种场景。宽表模型通过数据表存储数据,单表支持PB级数据存储和千万QPS。数据表具有Schema-Free、宽行、多版本数据以及生命周期管理特点,支持主键列自增、局部事务、原子计数器、过滤器、条件更新等功能。
模型介绍
表格存储宽表模型是类Bigtable/HBase模型,通过数据表采用三维结构(行、列和时间)存储数据。数据表的每一行可以有不同的列,可以动态增加或者减少属性列,创建表时无需为表的属性列定义严格的Schema。
模型构成
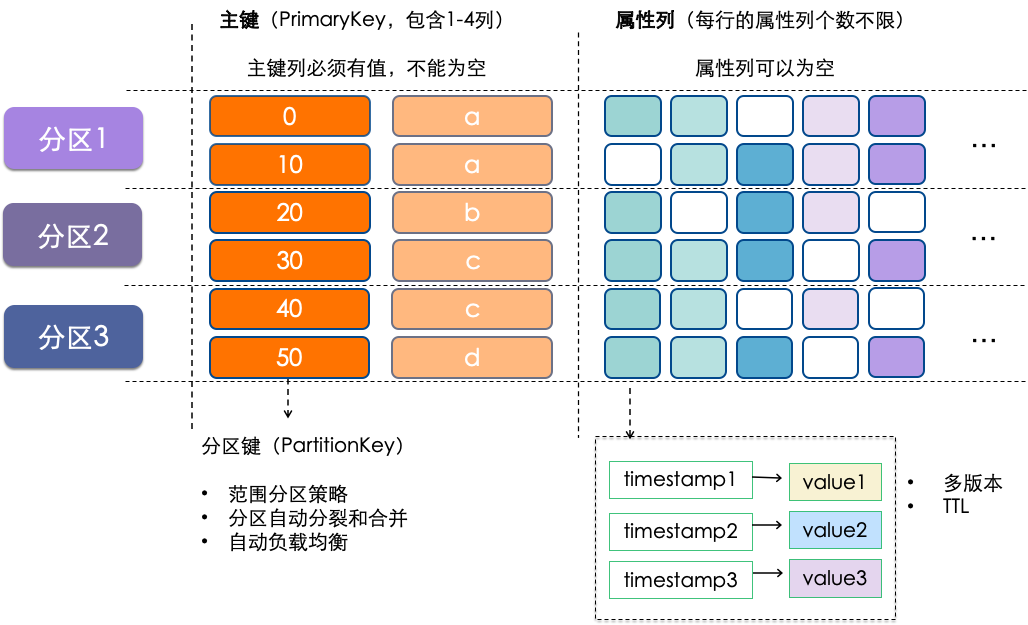
宽表模型如上图所示,由以下几个部分组成。
组成部分 | 描述 |
主键(Primary Key) | 主键是数据表中每一行的唯一标识,主键由1到4个主键列组成。 |
分区键(Partition Key) | 主键的第一列称为分区键。表格存储按照分区键对数据表的数据进行分区,具有相同分区键的行会被划分到同一个分区,实现数据访问负载均衡。 |
属性列(Attribute Column) | 一行中除主键列外,其余都是属性列。属性列会对应多个值,不同值对应不同的版本,每行的属性列个数没有限制。 |
版本(Version) | 每一个值对应不同的版本,版本的值是一个时间戳,用于定义数据的生命周期。更多信息,请参见版本号。 |
数据类型(Data Type) | 表格存储支持多种数据类型,包含String、Binary、Double、Integer和Boolean。更多信息,请参见数据类型。 |
生命周期(Time To Live) | 每个数据表可定义数据生命周期。例如生命周期配置为一个月,则表格存储会自动清理一个月前写入数据表的数据。更多信息,请参见数据生命周期。 |
最大版本数(Max Versions) | 每个数据表可定义每个属性列的数据最多保存的版本个数,用于控制属性列数据的版本个数。当一个属性列数据的版本个数超过Max Versions时,表格存储会异步删除较早版本的数据。更多信息,请参见最大版本数。 |
核心组件
数据表、行、主键和属性是表格存储宽表模型的核心组件。数据表是行的集合,而每个行是主键和属性的集合。组成主键的第一个主键列称为分区键。
主键、属性和分区键的具体说明请参见下表。
关于主键列和属性列的数据类型的更多信息,请参见命名规则和数据类型。
组件 | 说明 |
主键 | 主键是数据表中每一行的唯一标识,主键由1到4个主键列组成。创建数据表时,必须指定主键的组成、每一个主键列的名称、数据类型以及主键的顺序。 表格存储根据数据表的主键索引数据,数据表中的行默认按照主键进行升序排序。 |
分区键 | 组成主键的第一个主键列称为分区键。表格存储会根据数据表中每一行分区键的值所属范围自动将一行数据分配到对应的分区和机器上来达到负载均衡的目的。具有相同分区键值的行属于同一个数据分区,一个分区可能包含多个分区键值。表格存储服务会自动根据特定的规则对分区进行分裂和合并。 说明 分区键值是最小的分区单位,相同的分区键值的数据无法再做切分。为了防止分区过大无法切分,单个分区键值所有行的大小总和建议不超过10 GB。关于分区键选择的更多信息,请参见表操作篇。 |
属性 | 属性由多个属性列组成。每行的属性列个数无限制,且每行的属性列可不同。属性列在某一行的值可以为空。同一个属性列的值可以有多种数据类型。 属性列具有版本特征,属性列的值可以根据需求保留多个版本,用于查询和使用;属性列的值可以设置生命周期(TTL)。更多信息,请参见数据版本和生命周期。 |
与关系模型区别
宽表模型和关系模型的区别请参见下表。
模型 | 特点 |
宽表模型 | 三维结构(行、列和时间)、Schema-Free、宽行、多版本数据以及生命周期管理。 |
关系模型 | 二维(行、列)以及固定的Schema。 |
使用限制
使用宽表模型时的通用限制,请参见使用限制。
功能列表
功能特性 | 描述 | 相关文档 |
表操作 | 支持列出实例中的全部数据表、创建一张数据表、查询数据表的配置信息、更新数据表的配置信息以及删除一张数据表。 | |
基础数据操作 | 表格存储提供了PutRow、GetRow、UpdateRow和DeleteRow的单行数据操作接口以及BatchWriteRow、BatchGetRow和GetRange的多行数据操作接口。您可以通过单行数据操作接口或者多行数据操作接口读写表中数据。 | |
数据版本和生命周期 | 使用数据版本以及数据生命周期(TTL)功能,您可以有效的管理数据,减少数据存储空间,降低存储成本。 | |
主键列自增 | 设置非分区键的主键列为自增列后,在写入数据时,无需为自增列设置具体值,表格存储会自动生成自增列的值。该值在分区键级别唯一且严格递增。 | |
条件更新 | 只有满足条件时,才能对数据表中的数据进行更新;当不满足条件时,更新失败。 | |
局部事务 | 创建数据范围在一个分区键值内的局部事务。对局部事务中的数据进行读写操作后,可以根据实际情况提交或者丢弃局部事务。 | |
原子计数器 | 将列当成一个原子计数器使用,对该列进行原子计数操作,可用于为某些在线应用提供实时统计功能,例如统计帖子的PV(实时浏览量)等。 | |
过滤器 | 在服务端对读取的结果再进行一次过滤,根据过滤器中的条件决定返回哪些行。由于只返回符合条件的数据行,所以在大部分场景下,可以有效降低网络传输的数据量,减少响应时间。 | |
二级索引 | 通过创建一张或多张索引表,使用索引表的主键列查询,相当于把数据表的主键查询能力扩展到了不同的列。二级索引包括全局二级索引和本地二级索引。
| |
多元索引 | 多元索引基于倒排索引和列式存储,可以解决大数据的复杂查询难题,包括非主键列查询、全文检索、前缀查询、模糊查询、多条件组合查询、嵌套查询、地理位置查询、统计聚合(max、min、count、sum、avg、distinct_count、group_by)、并发导出数据等功能。 | |
SQL查询 | SQL查询功能为多数据引擎提供统一的访问接口。通过SQL查询功能,您可以对表格存储中数据进行复杂的查询和高效的分析。使用SQL查询数据时,您还可以配合索引来优化查询。 | |
通道服务 | 表格存储提供了增量、全量、增量加全量三种类型的分布式数据实时消费通道,可以实现对表中历史存量和新增数据的消费处理。 |
计费说明
表格存储支持VCU模式(原预留模式)和CU模式(原按量模式)两种计费模式,请根据所用的实例模型参考相应计费模式了解计费信息。更多信息,请参见计费概述。
VCU模式(原预留模式):计费项包括计算能力、数据存储量和外网下行流量,其中数据存储量包括高性能存储、容量型存储和多元索引存储。
CU模式(原按量模式):计费项包括读吞吐量、写吞吐量、数据存储量和外网下行流量。
常见问题
相关文档
如果要实现实例数据的机房级容灾,您可以通过创建同城冗余类型的实例实现。更多信息,请参见同城冗余。
如果要保证数据存储安全和网络访问安全,您可以使用数据表加密、VPC网络访问等方式实现。更多信息,请参见数据加密和网络安全管理。
如果要防止重要数据被误删除,您可以使用数据备份功能实现定期备份重要数据。更多信息,请参见备份Tablestore数据。
如果要对表中历史存量和新增数据的消费处理,您可以使用通道服务实现。更多信息,请参见通道服务。
如果要为监控指标配置报警通知,您可以使用云监控实现。更多信息,请参见监控与告警。
如果要以图表等形式可视化展示数据,您可以使用DataV或者Grafana实现。更多信息,请参见数据可视化。
使用宽表模型可以实现元数据、大数据等多种场景的解决方案,例如搭建海量智能元数据管理系统、亿量级订单管理方案、基于多元索引搭建亿量级店铺搜索系统、表格存储结合Spark流批处理实现一体化存储和计算、表格存储结合实时计算Flink进行大数据分析。更多方案介绍,请参见场景实战-典型场景架构与实现。
基于物联网场景中多源异构数据存储、高并发吞吐、海量数据高性价比存储、多维度数据处理与分析等需求,表格存储推出了一站式物联网存储IoTstore解决方案,为物联网设备元数据、消息数据、时序轨迹等海量数据提供存储、查询、检索、分析、同步等能力。更多信息, 请参见物联网存储简介、时序数据接入、设备时序数据开发、设备元数据接入和时序分析存储。