
数仓版快速入门
欢迎使用云原生数据仓库 AnalyticDB MySQL 版数仓版入门指南。云原生数据仓库 AnalyticDB MySQL 版(AnalyticDB for MySQL)是云端托管的PB级高并发实时数据仓库,是专注于服务OLAP领域的数据仓库。本指南将指引您使用数仓版集群。
数仓版目前已停止新购。您可以购买企业版或基础版。如果您已购买数仓版集群,仍可以参考本指南继续使用数仓版集群。
数仓版快速入门视频指导
使用流程
如果您是首次使用AnalyticDB for MySQL数仓版的用户,我们建议您先阅读以下部分:
产品简介:本内容概述了AnalyticDB for MySQL的产品概念、产品优势及应用场景等内容。
产品定价:本内容介绍了AnalyticDB for MySQL的产品定价、计费方式等信息。
入门指南(本指南):本指南提供了有关AnalyticDB for MySQL数仓版的使用教程。
在本教程中,操作流程概览如下:

步骤一:创建数据库账号
AnalyticDB for MySQL支持高权限账号和普通账号这两种数据库账号,两种账号的区别,请参见数据库账号类型。
创建高权限账号
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击账号管理。
在账号管理页面,单击创建高权限账号。
在创建账号面板,设置相关参数。
参数
说明
数据库账号
高权限账号的账号名称,根据控制台提示输入符合要求的名称。
账号类型
数仓版集群固定为高权限账号,无需配置。
新密码
高权限账号的密码,根据控制台提示输入符合要求的账号密码。
确认密码
再次输入高权限账号的密码。
描述
备注该账号的相关信息,便于后续账号管理。可选。
单击确定完成账号创建。
创建和授权普通账号
数仓版集群通过SQL语句创建的普通账号,不会在控制台显示。
创建数据库账号,请参见CREATE USER。
授权数据库账号,请参见GRANT。
撤销数据库账号权限,请参见REVOKE。
更改数据库账号名,请参见RENAME USER。
删除数据库账号,请参见DROP USER。
步骤二:设置白名单
集群默认的白名单只包含IP地址127.0.0.1,表示任何设备均无法访问该集群。您可以通过设置白名单允许其他设备访问集群,例如填写IP段10.10.10.0/24,表示10.10.10.X的IP地址都可以访问该集群。若您需要添加多个IP地址或IP段,请用英文逗号(,)隔开(逗号前后都不能有空格),例如192.168.0.1,172.16.213.9。
警告设置白名单时,禁止输入IP:0.0.0.0。
若您的公网IP经常变动,需要开放所有公网IP访问AnalyticDB for MySQL集群,请联系技术支持。
白名单可以为AnalyticDB for MySQL集群得到高级别的访问安全保护,建议您定期维护白名单。
设置白名单不会影响AnalyticDB for MySQL集群的正常运行。设置白名单后,新的白名单将于1分钟后生效。
操作步骤
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏单击数据安全。
在白名单设置页面,单击default白名单分组右侧的修改。
说明您也可以单击创建白名单分组创建自定义分组。
在修改白名单分组对话框中,删除默认IP 127.0.0.1,填写需要访问该集群的IP地址或IP段,然后单击确定。
说明如果需要将客户端出口IP地址添加到白名单中,请先查询IP地址,详情请参见连接。
步骤三:连接集群
AnalyticDB for MySQL支持通过DMS(Data Management Service)、MySQL客户端(Navicat for MySQL、DBeaver、DBVisualizer、SQL WorkBench/J)、BI可视化工具、或者MySQL命令行工具连AnalyticDB for MySQL集群。您也可以在应用程序中通过配置集群连接地址、端口、数据库账号等信息连AnalyticDB for MySQL集群。
使用DMS连接AnalyticDB for MySQL
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在集群信息页面,单击右上角登录数据库。
在弹出的对话框中,填写登录信息。
参数
说明
数据库类型
默认为AnalyticDB MySQL 3.0,无需选择。
实例地区
默认为当前实例所在地域,无需选择。
实例ID
默认为当前集群的集群ID,无需选择。
数据库账号
集群的账号名称。
数据库密码
账号名对应的密码。
说明您可以选中记住密码,方便之后再次登录当前AnalyticDB for MySQL集群时,无需输入数据库账号和密码即可自动登录。
单击登录即可。
应用开发中通过代码连接到AnalyticDB for MySQL
通过MySQL命令行工具连接到AnalyticDB for MySQL
通过客户端连接到AnalyticDB for MySQL
将AnalyticDB for MySQL连接到数据可视化工具
步骤四:创建数据库
每个集群可创建数据库的最大值为2048。
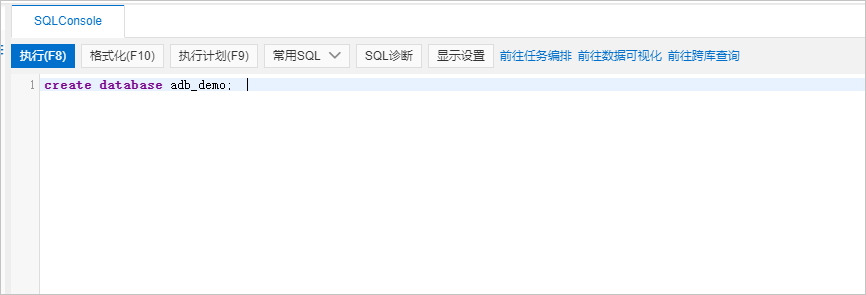
在SQL INFORMATION_SCHEMA页签下,在SQL Console中输入CREATE DATABASE语句创建数据库。
语法:
CREATE DATABASE [IF NOT EXISTS] $db_name参数说明:
db_name:数据库名。以小写字符开头,可包含字母、数字以及下划线(_),但不能包含连续两个及以上的下划线(_),长度不超过64个字符。说明数据库名不能是analyticdb,analyticdb是内置数据库。
示例:
create database adb_demo;create database if not exists adb_demo2;
单击左上角的执行,数据库创建成功。
步骤五:导入数据并查询
前提条件
通过以下步骤在OSS中创建存储AnalyticDB for MySQL数据的目录。
开通OSS服务。详情请参见开通OSS服务。
创建存储空间。详情请参见控制台创建存储空间。
重要OSS的存储空间与AnalyticDB for MySQL所属地域相同。
创建目录。详情请参见创建目录。
上传测试文件。详情请参见控制台上传文件。
本示例将
oss_import_test_data.txt文件上传至OSS中的<bucket-name>.oss-cn-hangzhou.aliyuncs.com/adb/目录,数据行分隔符为换行符,列分隔符为;,文件示例数据如下所示:uid;other 12;hello_world_1 27;hello_world_2 28;hello_world_3 33;hello_world_4 37;hello_world_5 40;hello_world_6 ...
根据AnalyticDB for MySQL入门指南,完成创建集群、设置白名单、创建账号和数据库等准备工作,详情请参见使用流程。
操作步骤
通过CREATE TABLE,在
adb_demo数据库中创建外表。创建CSV、Parquet或TEXT格式OSS外表的建表语法请参见OSS外表语法。查询OSS数据。
查询外表映射表和查询AnalyticDB for MySQL内表语法没有区别,您可以方便地直接进行查询,如本步骤的示例代码所示。
select uid, other from oss_import_test_external_table where uid < 100 limit 10;对于数据量较大的CSV或TEXT数据文件,强烈建议您按照后续步骤导入AnalyticDB for MySQL后再做查询,否则查询性能可能会较差。
对于Parquet格式数据文件,直接查询的性能一般也比较高,您可以根据需要决定是否进一步导入到AnalyticDB for MySQL后再做查询。
通过CREATE TABLE,在
adb_demo数据库中创建目标表adb_oss_import_test存储从OSS中导入的数据。CREATE TABLE IF NOT EXISTS adb_oss_import_test ( uid string, other string ) DISTRIBUTED BY HASH(uid);执行INSERT语句将OSS外表数据导入AnalyticDB for MySQL。
重要使用
INSERT INTO或INSERT OVERWRITE SELECT导入数据时,默认是同步执行流程。如果数据量较大,达到几百GB,客户端到AnalyticDB for MySQL服务端的连接需要保持较长时间。在此期间,可能会因为网络因素导致连接中断,进而导致数据导入失败。因此,如果您的数据量较大时,推荐使用SUBMIT JOB INSERT OVERWRITE SELECT异步执行导入。方式一:执行
INSERT INTO导入数据,当主键重复时会自动忽略当前写入数据,不进行更新覆盖,作用等同于INSERT IGNORE INTO,详情请参见INSERT INTO。示例如下:INSERT INTO adb_oss_import_test SELECT * FROM oss_import_test_external_table;方式二:执行INSERT OVERWRITE导入数据,会覆盖表中原有的数据。示例如下:
INSERT OVERWRITE adb_oss_import_test SELECT * FROM oss_import_test_external_table;方式三:异步执行
INSERT OVERWRITE导入数据。 通常使用SUBMIT JOB提交异步任务,由后台调度,可以在写入任务前增加Hint(/*+ direct_batch_load=true*/)加速写入任务。详情请参见异步写入。示例如下:SUBMIT JOB INSERT OVERWRITE adb_oss_import_test SELECT * FROM oss_import_test_external_table;返回结果如下:
+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** |关于异步提交任务详情,请参见异步提交导入任务。
执行以下命令,查询
adb_oss_import_test表的数据。SELECT * FROM adb_oss_import_test;
OSS外表语法
OSS非分区外表
CREATE TABLE [IF NOT EXISTS] table_name
(column_name column_type[, …])
ENGINE='OSS'
TABLE_PROPERTIES='{
"endpoint":"endpoint",
"url":"OSS_LOCATION",
"accessid":"accesskey_id",
"accesskey":"accesskey_secret",
"format":"CSV|ORC|Parquet",
"delimiter":";",
"skip_header_line_count":1,
"charset":"utf-8"
}';外表类型 | 参数 | 是否必填 | 说明 |
CSV格式、Parquet格式或OSS ORC格式外表 | ENGINE='OSS' | 是 | 表引擎,固定填写为OSS。 |
endpoint | OSS的EndPoint(地域节点)。 目前仅支持AnalyticDB for MySQL通过VPC网络访问OSS。 说明 您可登录OSS控制台,单击目标Bucket,在Bucket概览页面查看EndPoint(地域节点)。 | ||
url | 指定OSS文件或目录所在的路径。
| ||
accessid | 阿里云账号或者具备OSS管理权限的RAM用户的AccessKey ID。 如何获取AccessKey ID,请参见账号与权限。 | ||
accesskey | 阿里云账号或者具备OSS管理权限的RAM用户的AccessKey Secret。 如何获取AccessKey Secret,请参见账号与权限。 | ||
CSV格式外表 | delimiter | 定义CSV数据文件的列分隔符。 | |
Parquet格式、OSS ORC格式外表 | format | 数据文件的格式。
说明
| |
CSV格式外表 | null_value | 否 | 定义CSV数据文件的 重要 仅内核版本为3.1.4.2及以上的集群支持配置该参数。 |
ossnull | 选择CSV数据文件中
说明 上述各示例的前提为 | ||
skip_header_line_count | 定义导入数据时需要在开头跳过的行数。CSV文件第一行为表头,若设置该参数为1,导入数据时可自动跳过第一行的表头。 默认取值为0,即不跳过。 | ||
oss_ignore_quote_and_escape | 是否忽略字段值中的引号和转义。默认取值为false,即不忽略字段值中的引号和转义。 重要 仅内核版本为3.1.4.2及以上的集群支持配置该参数。 | ||
charset | OSS外表字符集,取值说明:
重要 仅内核版本为3.1.10.4及以上的集群支持配置该参数。 |
外表创建语句中的列名需与Parquet或ORC文件中该列的名称完全相同(可忽略大小写),且列的顺序需要一致。
创建外表时,可以仅选择Parquet或ORC文件中的部分列作为外表中的列,未被选择的列不会被导入。
如果创建外表创建语句中出现了Parquet或ORC文件中不存在的列,针对该列的查询结果均会返回NULL。
AnalyticDB for MySQL支持通过OSS的CSV格式的外表读写Hive TEXT文件。建表语句如下:
CREATE TABLE adb_csv_hive_format_oss (
a tinyint,
b smallint,
c int,
d bigint,
e boolean,
f float,
g double,
h varchar,
i varchar, -- binary
j timestamp,
k DECIMAL(10, 4),
l varchar, -- char(10)
m varchar, -- varchar(100)
n date
) ENGINE = 'OSS' TABLE_PROPERTIES='{
"format": "csv",
"endpoint":"oss-cn-hangzhou-internal.aliyuncs.com",
"accessid":"LTAI****************",
"accesskey":"yourAccessKeySecret",
"url":"oss://testBucketname/adb_data/",
"delimiter": "\\1",
"null_value": "\\\\N",
"oss_ignore_quote_and_escape": "true",
"ossnull": 2
}';在创建OSS的CSV格式的外表来读取Hive TEXT文件时,需注意如下几点:
Hive TEXT文件的默认列分隔符为
\1。若您需要通过OSS的CSV格式的外表读写Hive TEXT文件,您可以在配置delimiter参数时将其转义为\\1。Hive TEXT文件的默认
NULL值为\N。若您需要通过OSS的CSV格式的外表读写Hive TEXT文件,您可以在配置null_value参数时将其转义为\\\\N。Hive的其他基本数据类型(如
BOOLEAN)与AnalyticDB for MySQL的数据类型一一对应,但BINARY、CHAR(n)和VARCHAR(n)类型均对应AnalyticDB for MySQL中的VARCHAR类型。
OSS分区外表
如果OSS数据源是包含分区的,会在OSS上形成一个分层目录,类似如下内容:
parquet_partition_classic/
├── p1=2020-01-01
│ ├── p2=4
│ │ ├── p3=SHANGHAI
│ │ │ ├── 000000_0
│ │ │ └── 000000_1
│ │ └── p3=SHENZHEN
│ │ └── 000000_0
│ └── p2=6
│ └── p3=SHENZHEN
│ └── 000000_0
├── p1=2020-01-02
│ └── p2=8
│ ├── p3=SHANGHAI
│ │ └── 000000_0
│ └── p3=SHENZHEN
│ └── 000000_0
└── p1=2020-01-03
└── p2=6
├── p2=HANGZHOU
└── p3=SHENZHEN
└── 000000_0上述数据中p1为第1级分区,p2为第2级分区,p3为第3级分区。对应这种数据源,一般都希望以分区的模式进行查询,那么就需要在创建OSS外表时指明分区列。以Parquet格式为例,创建带有分区的OSS外表的语句如下:
CREATE TABLE [IF NOT EXISTS] table_name
(column_name column_type[, …])
ENGINE='OSS'
TABLE_PROPERTIES='{
"endpoint":"endpoint",
"url":"OSS_LOCATION",
"accessid":"accesskey_id",
"accesskey":"accesskey_secret",
"format":"parquet",
"partition_column":"p1, p2, p3"
}';TABLE_PROPERTIES中的partition_column参数用于指定分区列(本例中的p1、p2、p3)。且partition_column参数中的分区列必须按照第1级、第2级、第3级的顺序声明(本例中p1为第1级分区,p2为第2级分区,p3为第3级分区)。列定义中必须定义分区列(本例中的p1、p2、p3)及类型,且分区列需要置于列定义的末尾。
列定义中分区列的先后顺序需要与
partition_column中分区列的顺序保持一致。分区列支持的数据类型包括:
BOOLEAN、TINYINT、SMALLINT、INT、INTEGER、BIGINT、FLOAT、DOUBLE、DECIMAL、VARCHAR、STRING、DATE、TIMESTAMP。查询数据时,分区列和其它数据列的展示和用法没有区别。
不指定format时,默认格式为CSV。
其他参数的详细说明,请参见参数说明。
相关文档
更多导入数据方式,请参见支持的数据源。