本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
针对实例启动过程中因操作系统内配置异常、异常关机等问题导致操作系统无法正常启动的情况,您可以通过VNC登录实例发现的启动异常或者实例健康诊断工具返回的异常字段,在本文查看此类问题的解决方案。
Windows
1662001135:Windows系统因异常进入恢复环境
问题现象
Windows系统ECS实例在较长时间段内正常运行,但是重启实例后无法进入操作系统。通过VNC登录实例时,Windows系统启动界面显示系统恢复选项。
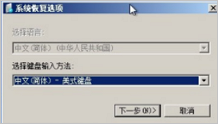
问题原因
系统恢复选项表示Windows系统进入了Windows恢复环境,Windows操作系统在遇到异常、无法启动的情况下,会进入恢复环境。可能原因如下:
系统注册表损坏、云盘问题、驱动问题、系统文件损坏或丢失、启动配置数据(Boot Configuration Data,BCD)文件损坏等。
用户误操作、病毒、第三方杀毒软件、异常强制重启。
解决方案
针对系统进入修复模式,建议您采用微软官方技术支持提出的方案进行处理。具体操作,请参见How Windows RE Works。
为了避免实例重启后进入系统恢复界面,确保系统能够从故障中恢复,在日常使用中,可以参考以下操作避免产生故障。
将重要数据放在数据盘。
定期对系统盘、数据盘创建快照,以便发生问题时可以恢复数据。
在修改系统注册表前备份注册表文件,避免误操作修改了系统文件。
定期运行Windows Update,确保安装微软最新安全更新。
在ECS中启用云安全中心或其他商业版杀毒防护工具,定期杀毒、定期更新杀毒软件版本。
1662001136:Windows系统的文件系统出现异常
问题现象
通过VNC登录实例时,Windows系统启动界面显示Checking file system on、CHKDSK is verifying files或CHKDSK is verifying indexes错误信息。
问题原因
导致该问题的可能原因如下:
ECS实例异常关机。
Windows内部系统损坏。
解决方案
方案一:使用快照恢复系统盘
在存有快照的情况下,您可以使用快照来恢复系统盘的部分数据和配置。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。

在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
方案二:重置系统盘
您可以重置系统盘来修复系统异常。具体操作如下:
重置系统盘操作会清空云盘已写入数据,建议操作前创建快照备份数据。具体操作,请参见手动创建单个快照。
停止ECS实例。
访问ECS控制台-实例。
在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例进入实例详情页,单击全部操作展开所有操作面板,然后搜索并单击停止。
重新初始化系统盘。
找到需要重新初始化系统盘的实例,单击全部操作展开所有操作面板,然后搜索并单击重新初始化云盘。
在弹出的重新初始化云盘对话框里,配置重新初始化参数。
单击确定。
完成重新初始化后,实例会自动启动。
1662001137:Windows系统出现内部错误
问题现象
通过VNC登录实例时,Windows启动界面显示出现内部错误或系统找不到指定的文件错误信息。
问题原因
该问题可能是因为Windows操作系统损坏,导致系统启动失败出现报错。
解决方案
您可以尝试重启实例来修复该错误,如无法修复,可以选择恢复系统盘或重置系统盘进行修复。
方案一:重启实例
您可以尝试重启实例来修复系统错误。具体操作如下:
访问ECS控制台-实例,在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例ID进入实例详情页,在页面右上角单击重启。
在弹窗中,选择重启模式。
不勾选强制重启实例(默认):操作系统会尝试正常关闭所有进程后,执行重启操作。
勾选强制重启实例:相当于执行断电操作,存在丢失内存数据和文件系统损坏的风险,建议仅在实例无法响应非强制重启时使用。
单击确定即可。
方案二:使用快照恢复系统盘
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
方案三:重置系统盘
您可以重置系统盘来修复系统异常。具体操作如下:
重置系统盘操作会清空云盘已写入数据,建议操作前创建快照备份数据。具体操作,请参见手动创建单个快照。
停止ECS实例。
访问ECS控制台-实例。
在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例进入实例详情页,单击全部操作展开所有操作面板,然后搜索并单击停止。
重新初始化系统盘。
找到需要重新初始化系统盘的实例,单击全部操作展开所有操作面板,然后搜索并单击重新初始化云盘。
在弹出的重新初始化云盘对话框里,配置重新初始化参数。
单击确定。
完成重新初始化后,实例会自动启动。
1662001138:Windows系统引导配置数据(BCD)中的文件丢失或损坏
问题现象
通过VNC登录实例时,Windows启动界面显示An error occurred while attempting to read the boot configuration data错误信息。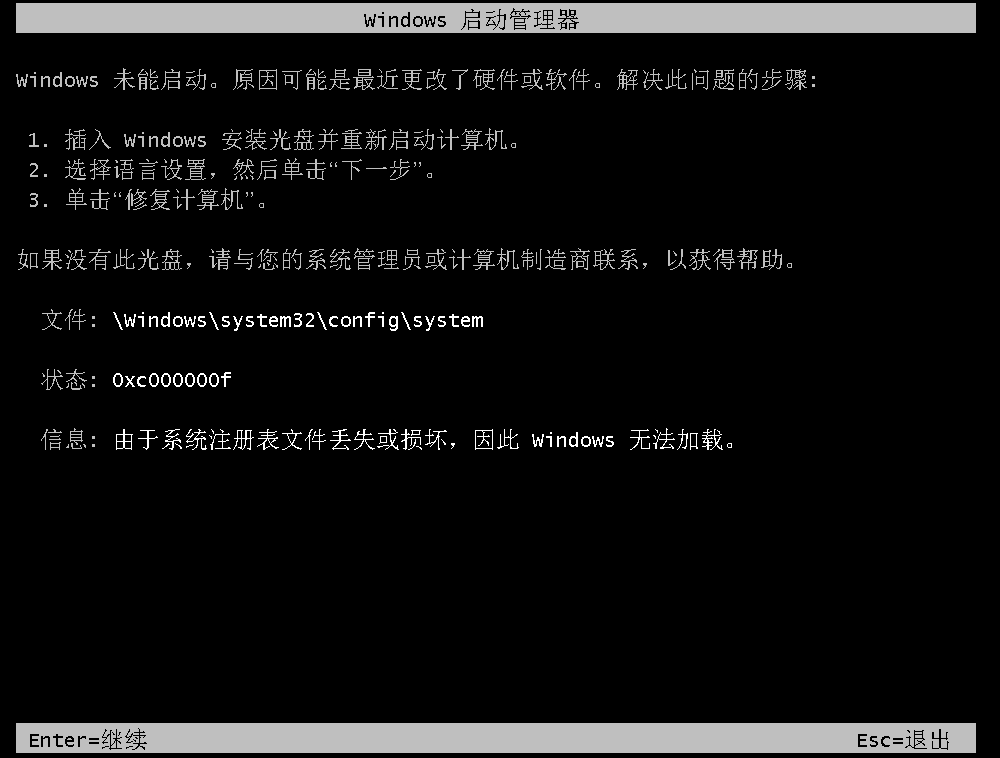
问题原因
该问题可能是因为Windows系统引导配置数据(Boot Configuration Data,BCD)配置文件丢失或者损坏,导致系统启动失败。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1662001139:Windows系统的引导扇区或驱动文件丢失或损坏
问题现象
通过VNC登录实例时,Windows系统启动界面蓝屏,显示INACCESSIBLE BOOT DEVICE错误信息。
问题原因
出现该问题的可能原因如下:
Windows系统引导扇区丢失或损坏。
Windows系统驱动文件丢失或损坏。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1662001140:Windows系统的Bootmgr配置丢失或损坏
问题现象
通过VNC登录实例时,Windows系统启动界面显示bootmgr is missing错误信息。
问题原因
该问题可能是因为Windows系统启动管理器(Bootmgr)丢失或者被破坏,导致系统启动失败。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1662001141:Windows系统的系统文件丢失或损坏
问题现象
通过VNC登录实例时,Windows系统启动失败,启动界面显示missing operating system错误信息。
问题原因
该问题可能是因为Windows操作系统文件丢失或者损坏,导致系统启动失败。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1662001142:Windows系统的注册表丢失或者损坏
问题现象
通过VNC登录实例时,Windows系统启动失败,启动界面显示Windows未能启动,原因可能是最近更改了硬件或软件错误信息。
问题原因
该问题可能是因为Windows系统注册表丢失或者损坏,导致系统无法加载。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1662001151:Windows sysprep因实例重启未正常完成,导致操作系统初始化异常
问题现象
ECS实例意外重启或遇到错误,通过VNC登录实例时,Windows启动界面显示Windows无法完成安装错误信息。
问题原因
该问题可能是由于系统准备(Sysprep)未完成,重启实例导致出现异常。
解决方案
重置系统盘操作会清空云盘已写入数据,建议操作前创建快照备份数据。具体操作,请参见手动创建单个快照。
停止ECS实例。
访问ECS控制台-实例。
在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例进入实例详情页,单击全部操作展开所有操作面板,然后搜索并单击停止。
重新初始化系统盘。
找到需要重新初始化系统盘的实例,单击全部操作展开所有操作面板,然后搜索并单击重新初始化云盘。
在弹出的重新初始化云盘对话框里,配置重新初始化参数。
单击确定。
完成重新初始化后,实例会自动启动。
1671696280:Windows系统BCD配置异常或云盘文件系统故障,导致系统启动失败
问题现象
通过VNC登录实例时,Windows系统启动失败,启动界面显示Windows未能启动,原因可能是最近更改了硬件或软件错误信息,且状态为0xc0000001。
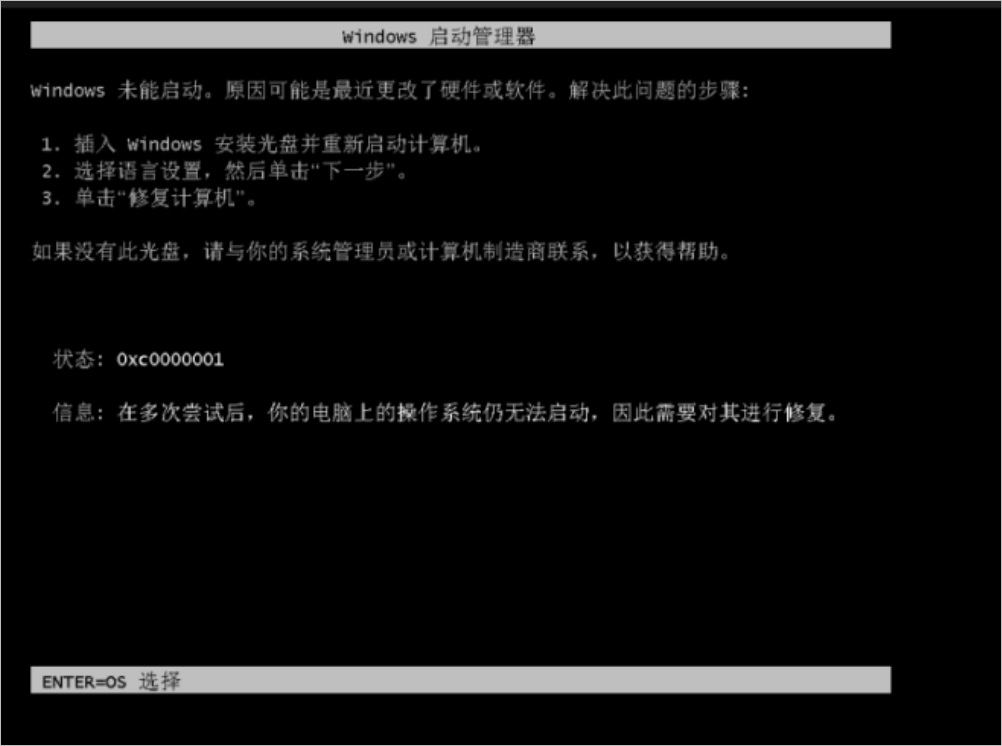
问题原因
该问题可能是因为Windows系统引导配置数据(Boot Configuration Data,BCD)配置异常或者云盘文件系统故障,导致系统无法加载。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1671696281:Windows系统文件损坏或者驱动不兼容,导致系统启动失败
问题现象
通过VNC登录实例时,Windows系统启动失败,启动界面卡在选择键盘布局界面。
问题原因
该问题可能是因为Windows系统文件损坏或者驱动不兼容,导致系统无法启动。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1671696282:Windows系统盘故障或硬件变动,导致系统启动失败
问题现象
通过VNC登录实例时,Windows系统启动失败,启动界面卡在Windows Error Recovery界面。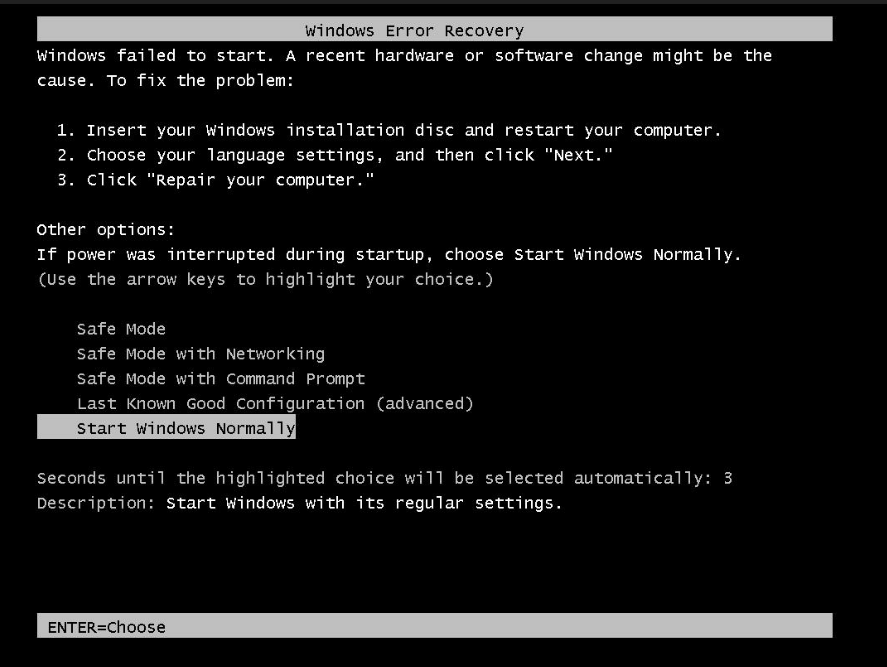
问题原因
该问题可能是因为Windows系统云盘故障或硬件变动,导致系统无法启动。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1671696284:Windows无法找到可用的系统引导启动,导致系统启动失败
问题现象
通过VNC登录实例时,Windows启动界面显示An operating system wasn't found. Try disconnecting any drives that don't contain an operating system.错误信息。
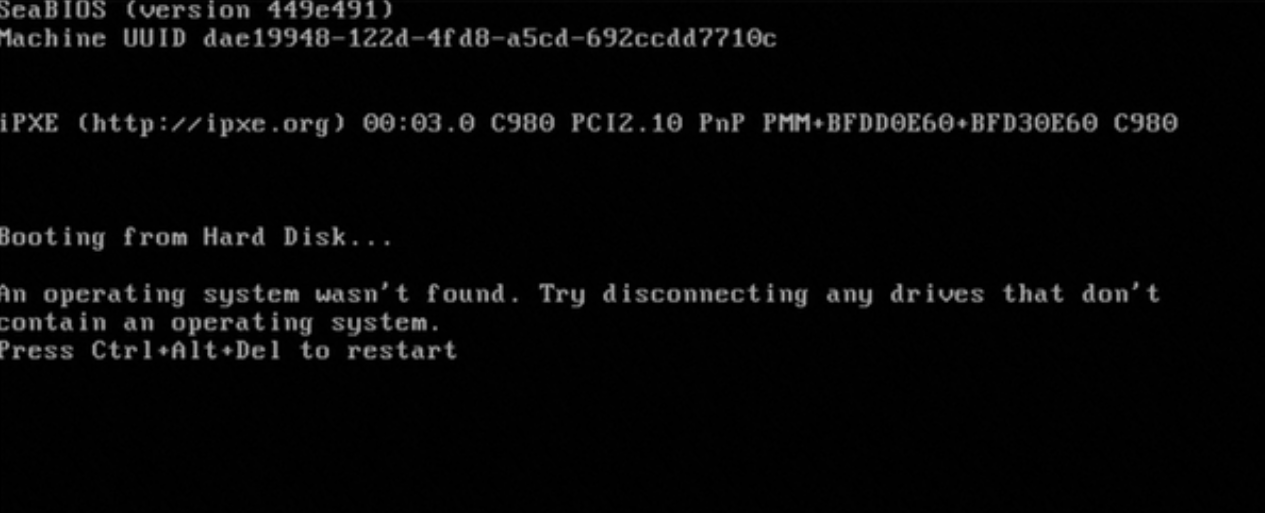
问题原因
该问题可能是因为Windows系统无法找到可用的系统引导启动,导致系统无法启动。
解决方案
在存有快照的情况下,您可以使用快照来恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1706506808:找不到启动盘
问题现象
Windows系统的ECS实例无法启动,提示“no bootable device”错误。
当操作系统无法启动时,只能通过VNC方式远程访问实例。

问题原因
出现该问题的原因较多,您可以使用健康诊断工具,根据实例健康诊断功能返回的信息,确定具体原因。关于如何使用健康诊断工具,请参见自助问题排查功能修复实例问题的操作指南。
解决方案
您可以根据实例健康诊断功能返回的信息,选择具体的修复方案。具体操作,请参见启动Windows实例时,提示“no bootable device”错误怎么办?。
1706506809:操作系统异常崩溃
问题现象
Windows操作系统的ECS实例在运行过程中出现内核panic、内存溢出OOM(Out Of Memory)、蓝屏卡死等问题。
问题原因
实例出现操作系统崩溃时,说明该ECS实例发生宕机。宕机的原因较多,系统核心服务进程异常退出、内核或驱动访问非法内存、内核数据结构遭到破坏等,都可能导致宕机。
解决方案
您可以通过自助诊断工具或系统事件来定位原因并解决,具体操作,请参见Windows系统实例的宕机问题排查。
1706506811:操作系统处于启动模式选择中
问题现象
启动Windows实例时,操作系统加载失败,进入修复模式(Preparing Automatic Repair)。
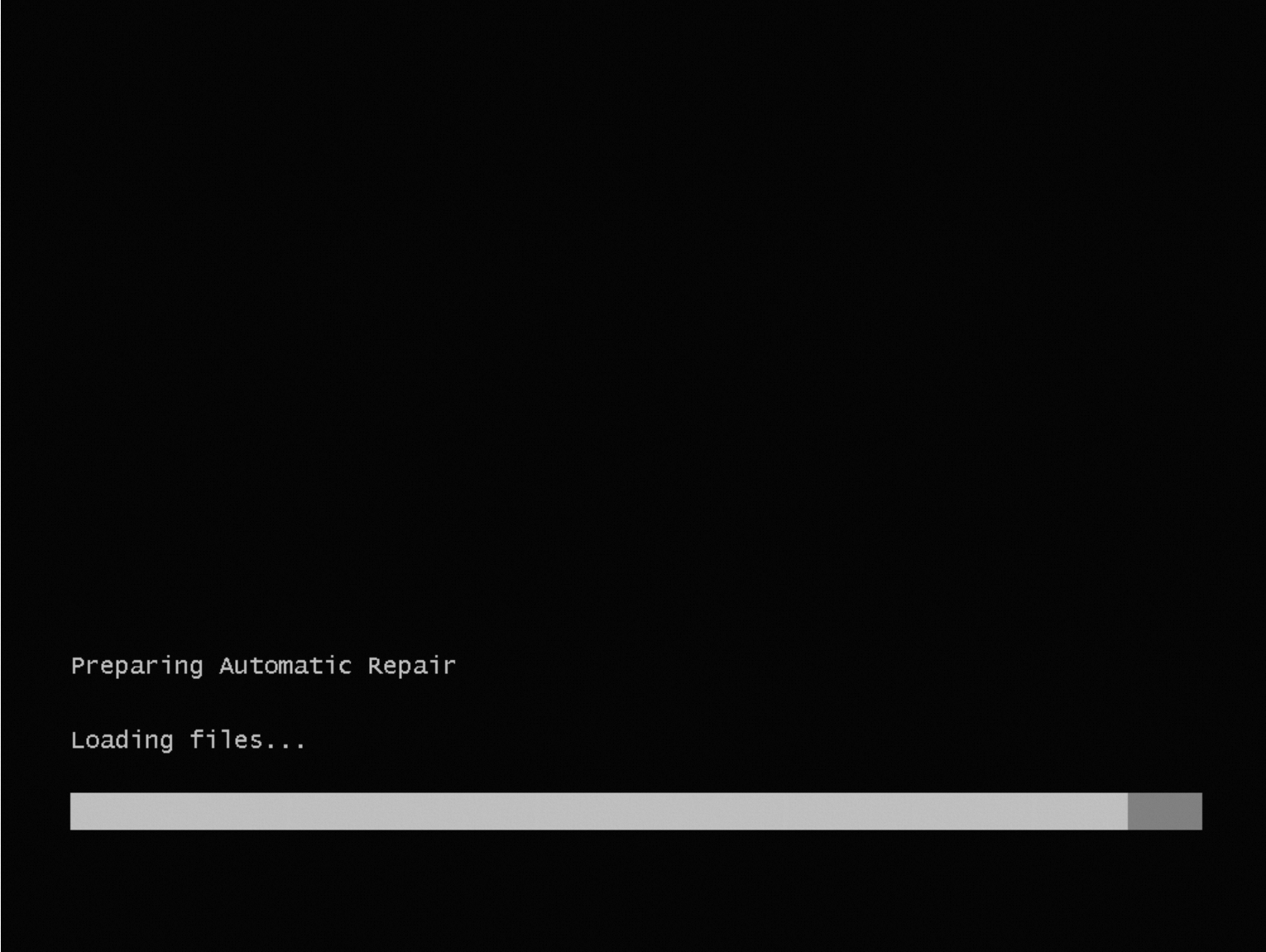
问题原因
出现该问题的原因较多,您可以使用健康诊断工具,根据实例健康诊断功能返回的信息,确定具体原因。关于如何使用健康诊断工具,请参见自助问题排查功能修复实例问题的操作指南。
解决方案
您可以根据实例健康诊断功能返回的信息,选择具体的修复方案。具体操作,启动Windows实例时,操作系统进入“Preparing Automatic Repair”模式怎么办?
1706506813:注册表破坏
问题现象
启动Windows实例时,提示“Windows未能启动,原因可能是最近更改了硬件或软件”。
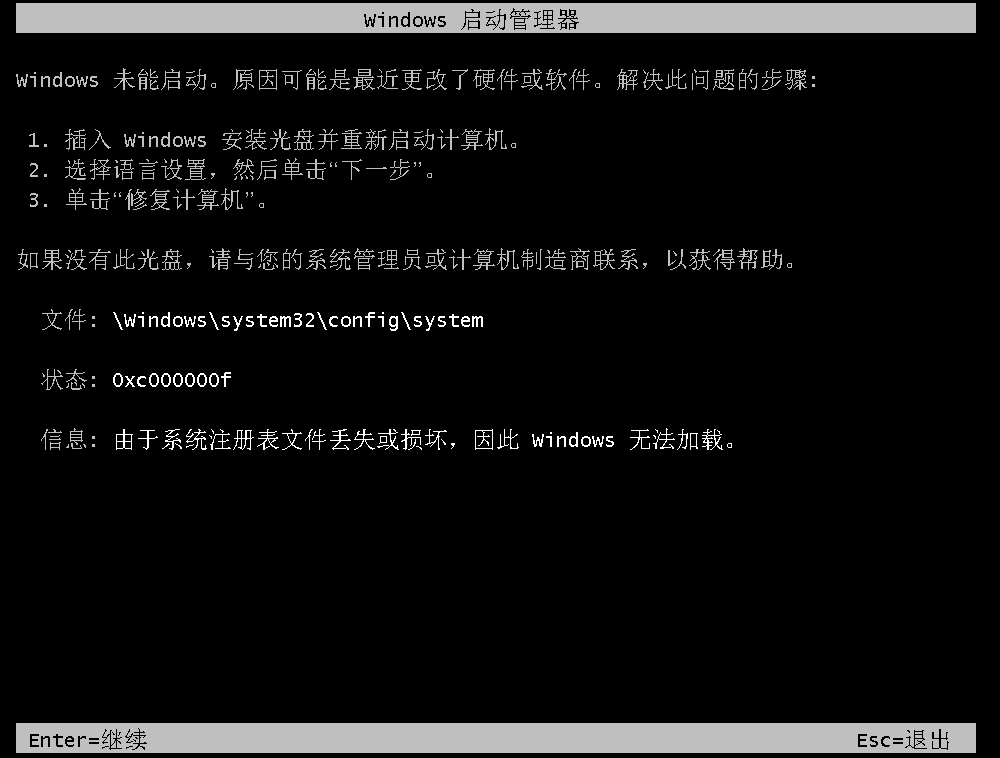
问题原因
该实例的关键注册表文件不存在或被破坏,导致操作系统无法正常启动。
解决方案
您可以进入修复模式或在修复实例中修复损坏的注册表文件以解决该问题,具体操作,请参见修复损坏的注册表文件。
1706506814:关键文件损坏
问题现象
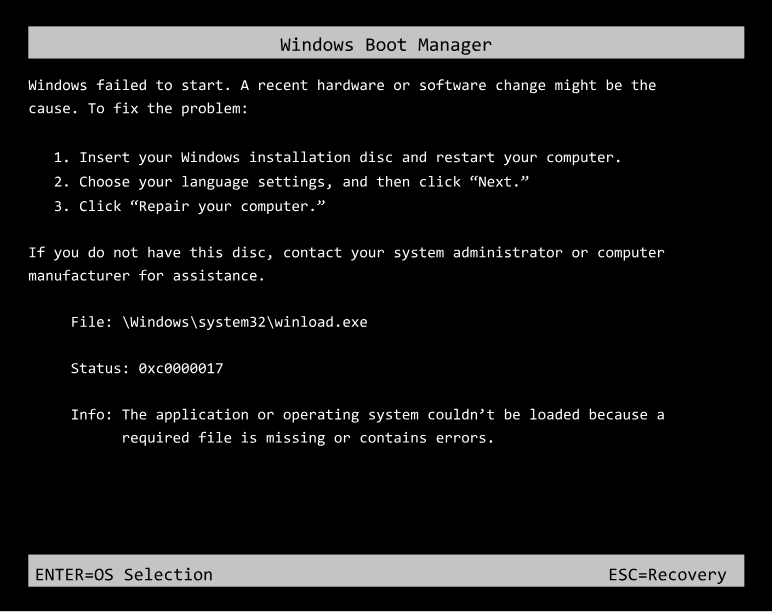
问题原因
导致该问题的根本原因是Windows核心组件异常,主要有以下两种情况:
基于预览体验版构建的镜像过期。
系统文件损坏:系统文件被删除或者内容被损坏,导致无法启动。
解决方案
基于预览体验版构建的镜像过期:如果您当前ECS实例是基于预览体验版构建的自定义镜像,出现此问题时,只能重新构建镜像。具体操作,请参见镜像构建服务最佳实践。
系统文件损坏:系统文件被删除或者内容被损坏,导致无法启动。此时,需要修复损坏的系统文件。具体操作,请参见Windows实例无法正常启动,通过VNC登录时提示“0xc0000017”错误怎么办?。
1706506815:系统无法识别数字签名
问题现象
Windows实例无法正常启动,通过VNC登录时提示“状态:0xc0000428”错误。
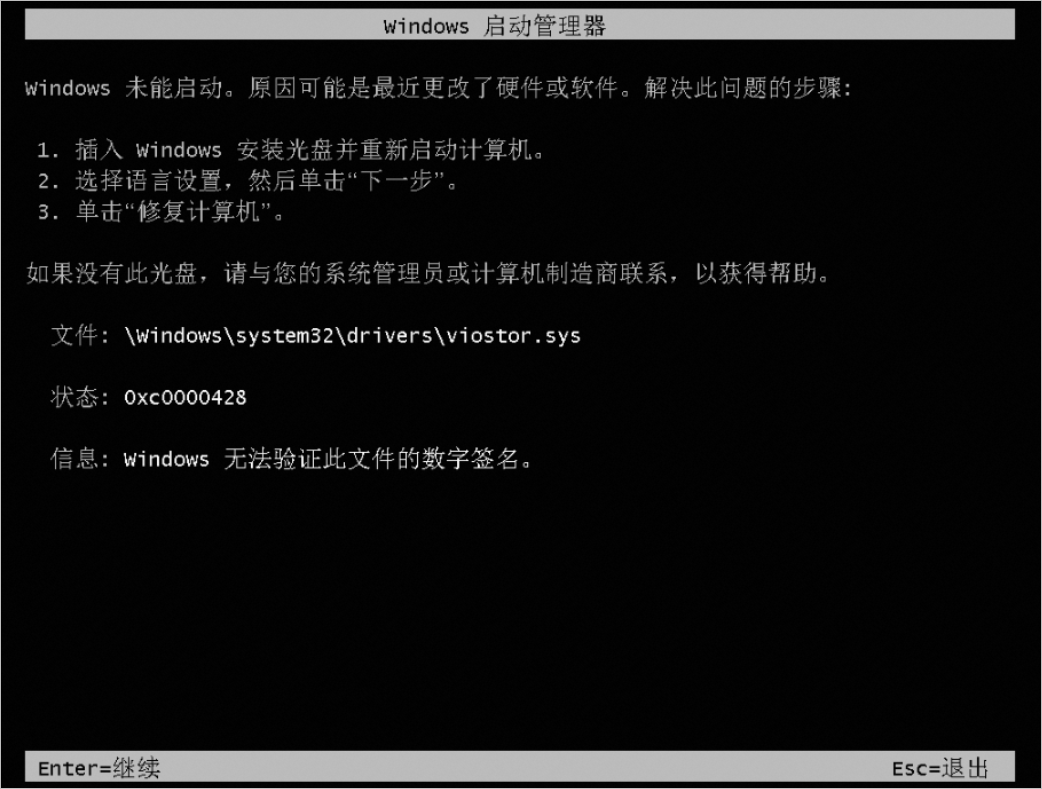
问题原因
Windows实例操作系统无法正确识别viostor.sys驱动使用的SHA256签名,导致实例无法成功启动。
解决方案
您需要暂时禁用驱动程序签名强制模式来进入Windows系统,然后在Windows实例内安装KB3033929补丁以支持SHA256算法,确保系统能够识别viostor.sys驱动使用的SHA256签名。具体操作,请参见Windows实例无法正常启动,通过VNC登录时提示“状态:0xc0000428”错误怎么办?。
1706506816:镜像启动模式不匹配
问题现象
启动Windows系统的ECS实例时,实例内部操作系统启动失败,通过VNC远程连接实例时,发现进入了EFI Shell界面。
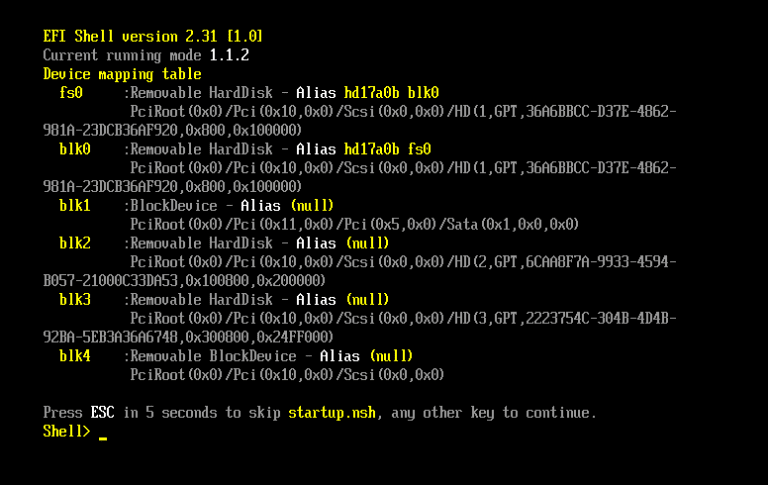
问题原因
出现该提示表示通过UEFI模式启动ECS实例失败,可能有以下原因:
实例的镜像不支持UEFI,但是镜像的启动模式被修改为UEFI,该错误通常出现在启动自定义镜像创建的ECS实例时。
实例的镜像支持UEFI,但是镜像内部UEFI固件损坏。
解决方案
您可以通过修改镜像的启动模式或修复UEFI固件来解决该问题。具体操作,请参见Linux系统的ECS实例内部操作系统启动失败,提示“UEFI Interactive Shell”错误怎么办?。
Linux
1662001143:Linux系统GRUB引导失败
问题现象
通过VNC登录实例时,可以看到grub>或grub rescue>错误信息,这会导致ECS实例的操作系统启动失败。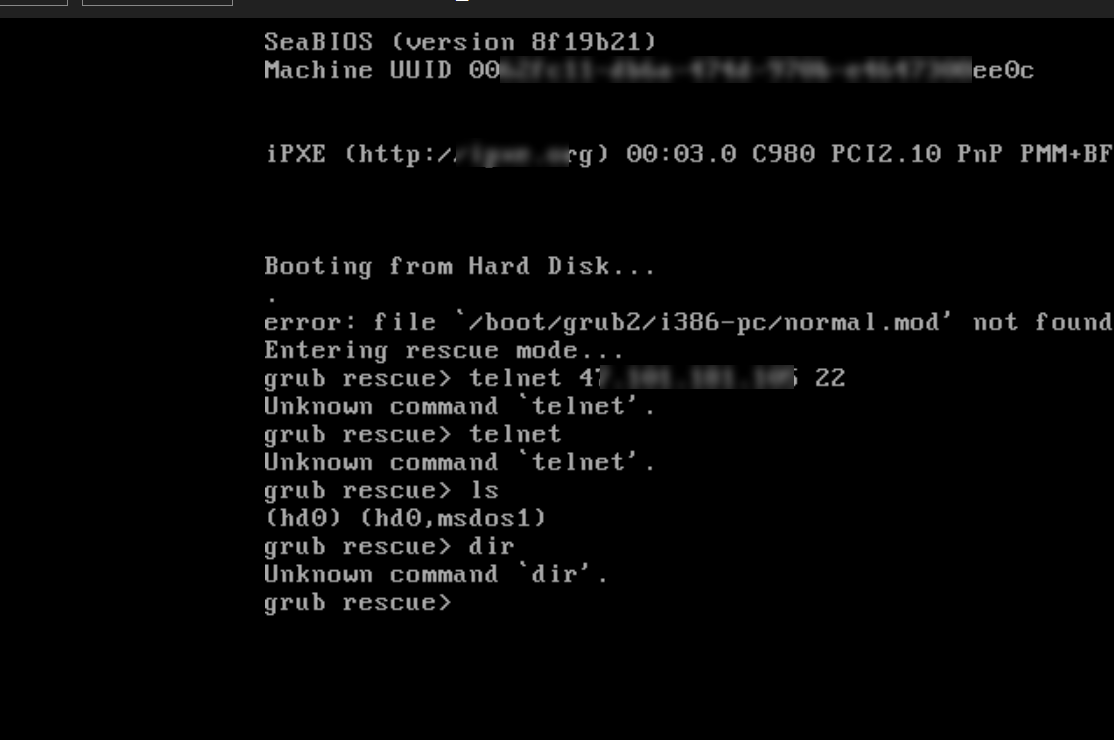
问题原因
grub引导失败进而导致操作系统启动过程无法继续。
grub引导失败的可能原因有很多种,包括如下原因:
grub组件相关文件缺失,比如/boot/grub2/grub.cfg文件缺失。
grub2内配置不正确或者云盘上grub2引导已经损坏。
如果在VNC界面显示类似
/boot/grub2/i386-pc/normal.mod notfound.内容,表示有grub2关键依赖的mod缺失。如果在VNC界面有显示类似
error:no suchpartition内容,表示grub2无法识别到对应的分区。如果在VNC界面有显示类似
error:unknown filesystem内容,表示grub2无法识别所在的分区文件系统类型。
解决方案
方案一:修复异常ECS实例的数据盘
卸载异常ECS实例的系统盘,并将该云盘作为数据盘挂载到正常ECS实例中。
具体操作,请参见Linux实例数据恢复最佳实践的步骤一~步骤二。
说明本步骤执行完毕,如果您未退出chroot环境,则需要在正常ECS实例上继续执行
exit命令退出chroot环境。执行如下操作,修复系统盘。
方法一:如果grub2关键依赖的mod缺失或者grub2在云盘上的信息损坏,您可以在chroot环境中执行
grub2-install /dev/vdb命令,重新安装grub2来修复对应问题,操作如下:通过云盘序列号查找对应异常系统盘挂载之后的在OS内的设备名。
具体操作,请参见查看块存储序列号,此处以/dev/vdb为例。
登录正常ECS实例,切换到root用户,依次执行以下命令,进入正常实例的挂载目录(以/mnt为例)。
mount -o bind /proc/ /mnt/proc/ mount -o bind /sys/ /mnt/sys/ mount -o bind /dev/ /mnt/dev/ chroot /mnt登录正常ECS实例,切换到root用户,依次执行以下命令,进入正常实例的挂载目录(以/mnt为例)。
执行
grub2-install /dev/vdb命令,重新安装系统盘上的grub。在正常ECS实例上输入
exit命令,退出chroot。
方法二:在ECS控制台上初始化系统盘,具体操作,请参见重新初始化系统盘(重置操作系统)。
警告重新初始化操作会清空云盘已写入数据,建议操作前创建快照备份数据。创建快照的具体操作,请参见手动创建单个快照。
在异常ECS实例中恢复挂载系统盘。
具体操作,请参见Linux实例数据恢复最佳实践的步骤三。
通过SSH或VNC远程登录已修复的异常ECS实例,确认ECS实例恢复正常。
方案二:使用快照恢复系统盘
如果方案一操作之后还是无法恢复系统盘grub2引导实例启动,您可以选择如下方案进行操作:
如果在您存有快照的情况下,您可以使用快照恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
方案三:重置系统盘
如果在您系统盘内没有重要数据的情况下,您可以重置系统盘。具体操作如下:
重置系统盘操作会清空云盘已写入数据,建议操作前创建快照备份数据。具体操作,请参见手动创建单个快照。
停止ECS实例。
访问ECS控制台-实例。
在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例进入实例详情页,单击全部操作展开所有操作面板,然后搜索并单击停止。
重新初始化系统盘。
找到需要重新初始化系统盘的实例,单击全部操作展开所有操作面板,然后搜索并单击重新初始化云盘。
在弹出的重新初始化云盘对话框里,配置重新初始化参数。
单击确定。
完成重新初始化后,实例会自动启动。
1662001144:Linux系统GRUB配置中root根目录的UUID错误
问题现象
通过VNC登录实例时,从VNC控制台上可以看到以下日志:
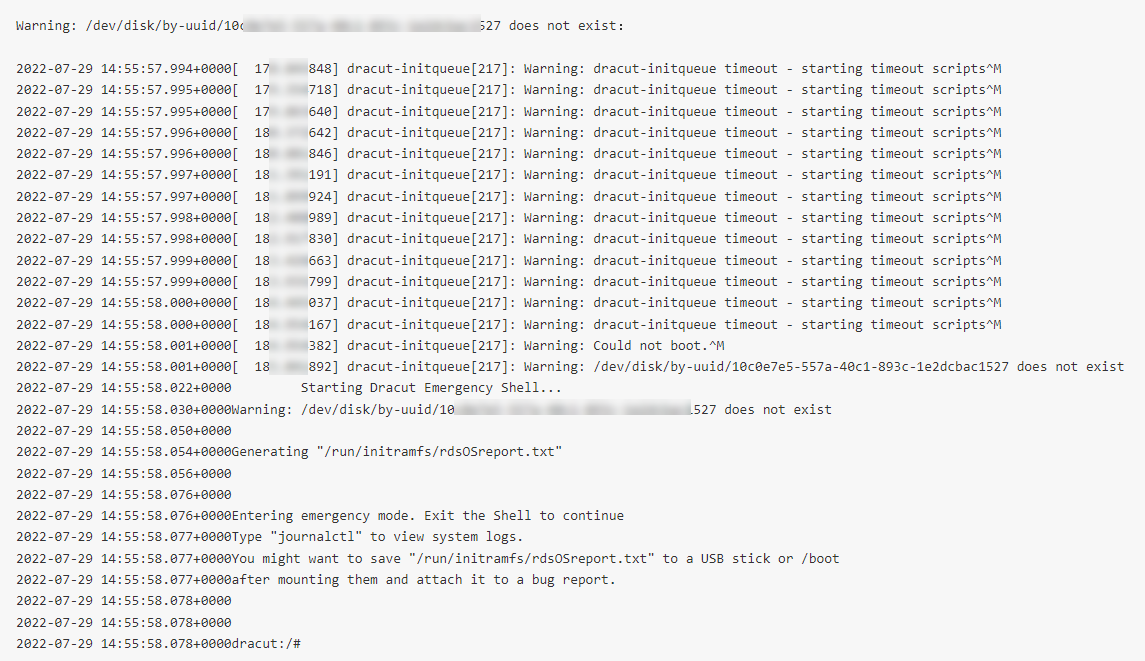
问题原因
出现该问题通常是因为grub.cfg内配置了UUID设备,但对应设备不存在导致。
例如:图中配置了root=UUID=10c0e7e5-557a-40c1-893c-1e2dcba*****的UUID设备,但ECS实例中不存在该设备。

解决方案
卸载异常ECS实例的系统盘,并将该云盘作为数据盘挂载到正常ECS实例中。
具体操作,请参见Linux实例数据恢复最佳实践的步骤一~步骤二。
进入正常实例中,通过云盘序列号查找对应异常系统盘挂载之后在OS内的设备名。
具体操作,请参见查看块存储序列号,此处以/dev/vdb为例。
执行如下命令,查询
/dev/vdb1对应的文件系统UUID 。blkid /dev/vdb1显示结果即为文件系统UUID。
/dev/vdb1: UUID="10c0e7e5-557a-40c1-893c-1e2dcba*****" TYPE="ext4"将异常系统盘的
grub2.cfg文件内的UUID替换为上述获取到的UUID值。恢复异常ECS实例的系统盘。
具体操作,请参见Linux实例数据恢复最佳实践的步骤三。
通过SSH或VNC远程登录已修复的ECS实例,若不再出现该错误,说明该问题已修复。
1662001145:Linux系统关机时卡住
问题现象
ECS实例一直处于停止中状态,通过VNC登录实例,界面显示如下错误信息。
CentOS release 5.8(Final)
Kernel 2.6.18-308.el5 on anx 86_64
iZuf6isbofkgfnm5qp***** login:md:stopping allmddevices.
System halted.问题原因
出现该问题通常是系统在关机过程中因未知原因卡住,详细根因需要具体分析系统日志。
解决方案
您可以尝试在ECS控制台强制重启实例来修复问题。具体操作如下:
强制重启实例时,可能会造成内存中的缓存数据丢失。
访问ECS控制台-实例,在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例ID进入实例详情页,在页面右上角单击重启。
在弹窗中,选择重启模式。
勾选强制重启实例:相当于执行断电操作,存在丢失内存数据和文件系统损坏的风险,建议仅在实例无法响应非强制重启时使用。
单击确定即可。
1662001146:Linux系统/etc/fstab文件中配置的某个挂载点对应的设备不存在
问题现象
通过VNC访问实例,发现界面上不断打印出A start job is running错误信息。
Booting from 0000:7c00
/: clean, 53966/2621440 files, 648440/10485499 blocks
A start job is running for dev-xvda1.device (5s / 1min 30s)
A start job is running for dev-xvda1.device (6s / 1min 30s)
A start job is running for dev-xvda1.device (7s / 1min 30s)
......问题原因
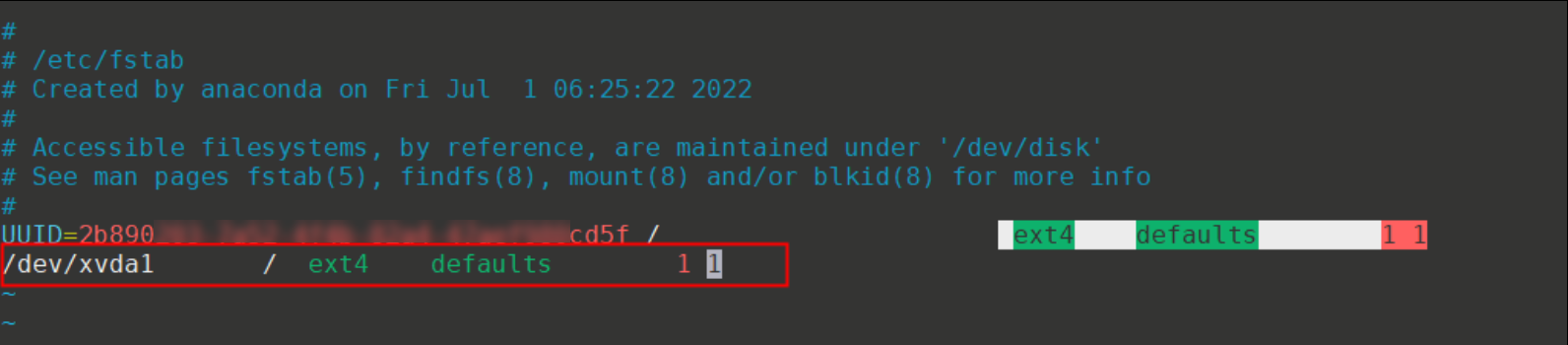
该问题可能是因为ECS实例内部/etc/fstab配置了不存在的设备挂载点。
如下图,实例内部/etc/fstab配置的/dev/xvda1设备不存在,则会提示A start job is running for dev-xvda1.device。
解决方案
等待系统检测完成。
例如检测完成后出现类似如下界面:
输入实例登录密码(非VNC密码) ,进入OS内部。
执行
mount -a命令查看具体报错的行。回显如下所示,表示
/etc/fstab配置文件中第11行存在错误
执行
vim /etc/fstab,编辑/etc/fstab文件。注释(#)或者删除
/etc/fstab文件中该行配置,输入:wq,键入Enter,保存并退出。重启ECS实例。
具体操作,请参见重启实例。
远程连接ECS实例,若不再出现该问题,说明问题已修复。
1662001147:Linux系统出现操作系统崩溃
问题现象
ECS实例内部OS启动失败,通过VNC登录实例后,在/var/log/dmesg、/var/log/messages等日志出现Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block错误信息。
问题原因
出现Kernel panic的原因有很多种,可能是内核问题、业务问题或者其他问题。具体错误信息如下:
Kernel panic - not syncingfatal exception in interruptKernel panic - not syncing: Attempted to kill the idle task!Kernel panic - not syncing: killing interrupt handler!Kernel panic - not syncing: Attempted to kill init!
解决方案
您可以根据您的需求选择适合的解决方案。
重启ECS实例
如果您希望快速恢复业务正常使用,则可以在控制台强制重启实例。具体操作如下:
强制重启ECS实例时,可能会造成内存中的缓存数据丢失。
访问ECS控制台-实例,在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例ID进入实例详情页,在页面右上角单击重启。
在弹窗中,选择重启模式。
勾选强制重启实例:相当于执行断电操作,存在丢失内存数据和文件系统损坏的风险,建议仅在实例无法响应非强制重启时使用。
单击确定即可。
开启Kdump服务
出现Kernel panic通常是因为ECS实例中,应用程序或者操作系统内核故障导致系统崩溃。您可以开启Kdump服务获取内核文件分析问题原因。具体操作,请参见Linux实例如何开启Kdump服务。
1662001148:Linux系统的关键系统文件缺失
问题现象
ECS实例内部OS启动失败,通过VNC登录实例时,启动界面显示execute/bin/sh, giving up:No such file or directory错误信息。
0K] Stopped dracut cmdline hook.
Stopping dracut cmdline hook...
OK] Stopped Create Static Device Nodes in/dev.
Stopping Create Static Device Nodes in/dev...
OK] Stopped Create list of required sta...ce nodes for the current kernel.
Stopping Create list of required st...nodes for the current kernel...
OK]ClOSed udev Control Socket.
OK]ClOSed udev Kernel Socket.
Starting Cleanup udev dDB.
[OK] Started Cleanup udev dDB.
6.573859] system d-journald[106] :Received SIGTERM from PID 1(system d) .
[DK]Reached target Switch Root.
[OK] Started Plymouth switch root service.
Starting Switch Root...
[6.583367] systemd[1] :No /sbin/init, trying fallback
[6.584388] systemd[1] :Failed to execute/bin/sh, giving up:No such file or directory
[892.889761] random:crn gin it done问题原因
该问题可能是由于ECS实例内部的/bin/sh或者/bin/bash文件或者软链接被删除,导致实例启动失败。
解决方案
方案一:修复异常ECS实例的数据盘
卸载异常ECS实例的系统盘,并将该云盘作为数据盘挂载到正常ECS实例中。
具体操作,请参见Linux实例数据恢复最佳实践的步骤一~步骤二。
在正常ECS实例中,将对应的/bin/sh或者/bin/bash文件拷贝到异常ECS系统盘内。
如将正常ECS实例的/bin/sh拷贝到异常ECS实例(192.168.XXX.XXX)中。
scp /bin/sh root@192.168.XXX.XXX:/bin/sh恢复异常ECS实例的系统盘。
具体操作,请参见Linux实例数据恢复最佳实践的步骤三。
通过SSH或VNC远程登录已修复的ECS实例,若不再出现该问题,说明该问题已修复。
方案二:使用快照恢复系统盘
如果方案一操作之后还是无法恢复系统盘grub2引导实例启动,您可以选择如下方案进行操作。
如果在您存有快照的情况下,您可以使用快照恢复系统盘。具体操作如下:
回滚云盘是不可逆操作,从快照的创建日期到回滚云盘时这段时间内的数据会丢失。为避免误操作,建议您在回滚前为云盘创建一份快照备份数据。具体操作,请参见手动创建单个快照。
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
方案三:重置系统盘
如果您系统盘内没有重要数据,则您可以重置系统盘。具体操作如下:
重置系统盘操作会清空云盘已写入数据,建议操作前创建快照备份数据。具体操作,请参见手动创建单个快照。
停止ECS实例。
访问ECS控制台-实例。
在页面左侧顶部,选择目标资源所在的资源组和地域。
单击目标实例进入实例详情页,单击全部操作展开所有操作面板,然后搜索并单击停止。
重新初始化系统盘。
找到需要重新初始化系统盘的实例,单击全部操作展开所有操作面板,然后搜索并单击重新初始化云盘。
在弹出的重新初始化云盘对话框里,配置重新初始化参数。
单击确定。
完成重新初始化后,实例会自动启动。
1662001149:Linux系统启动过程中文件系统fsck检查出异常
问题现象
ECS实例启动阶段OS启动卡住,通过VNC登录时,可以看到类似如下错误信息:
fsck from util-linux 2.20.1
fsck from util-linux 2.20.1
:clean, 193163/ 1310720 files, 2415199/ 5242368 blocks
/dev/vdb:Superblock last write tine(Tue Nou 2300:31:582021,
now=WedNou1018:28:552021) is in the future.
/dev/vdb:UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY.
(i.e., without-a or-p options)
mountall:fsck /data[294] terminated with status 4
mountall:File system has errors:/data
Errors were found while checking the disk dr iue for/data.
Press F to attempt to fix the errors, It oig more, S to skip mounting, or M for问题原因
/data挂载点对应的文件系统/dev/vdb存在异常,执行fsck的时候返回报错,需要人工确认是否修复。
解决方案
本解决方案仅针对出现该问题时的修复方案,实际问题中需要根据不同的fsck问题原因,进行不同的修复。
按照提示按
F自动修复。如果修复失败,可以再尝试按
S跳过对应的/data挂载,继续启动OS。进入OS之后,执行如下命令,修复对应挂载点
/data所在的文件系统/dev/vdb异常。fsck -y /dev/vdb修复完成后,执行如下命令重启实例。
reboot远程连接实例,若不再出现该问题,说明该问题已修复。
1662001150:Linux系统中/etc/fstab文件中配置的某个挂载点对应的设备不存在,或系统启动过程中文件系统fsck检查出异常
问题现象
ECS实例内部OS启动卡在Give root password for maintenance等待输入密码页面。如下所示:
Booting from Hard Disk...
Booting from 0000:7c00
[ 2.845229] EXT4-fs (vdb1): Unrecognized mount option "default" or missing value
Welcome to emergency mode! After logging in, type "journalctl -xb" to view
system logs, "systemctl reboot" to reboot, "systemctl default" or ^D to
try again to boot into default mode.
Give root password for maintenance
(or press Control-D to continue):问题原因
可能存在的原因如下:
ECS实例中
/etc/fstab文件配置的挂载点对应的设备不存在。配置了开机fsck自检文件系统,fsck自检时发现文件系统存在异常,需要人工参与修复。
解决方案
您可以根据实际问题原因来选择适合您的解决方案。
方案一:修复错误配置
输入密码进入系统。
执行如下命令,修改根分区的挂载模式为读写。
mount / -o remount,rw执行如下命令,查看具体报错信息。
journalctl -xb如
[ 2.845229] EXT4-fs (vdb1): Unrecognized mount option "default" or missing value表示/etc/fstab文件中/dev/vdb1挂载模式为default存在错误,需要修改为defaults。修改
/etc/fstab配置文件中/dev/vdb1挂载模式为defaults。执行如下命令,打开
/etc/fstab配置文件。vim /etc/fstab按
i键进入编辑模式。将
/dev/vdb1挂载模式修改为defaults。/dev/vdb1 / ext4 default l l按Esc键,输入
:wq保存并退出编辑。
重启ECS实例。
具体操作,请参见重启实例。
远程连接实例,若不再出现该问题,说明该问题已修复。
方案二:修复文件系统异常
输入密码进入系统之后,执行fsck检测的对应的错误,根据实际情况选择对应解决方案进行修复。
1671696288:Linux系统initrd switch root失败
问题现象
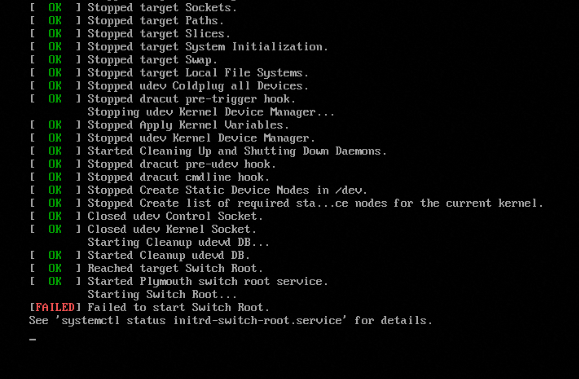
Linux系统启动失败。通过VNC登录时,可以看到类似Failed to start Switch Root的错误信息。如下图:
问题原因
Linux系统在启动过程中执行switch root时发生失败的原因可能有很多种,如下:
常见的可能原因是
/etc/os-release或/usr/lib/os-release文件缺失,请参考方案一:创建缺失文件进行修复。其他可能原因导致switch root失败,请参考方案二:使用快照恢复系统盘进行修复。
解决方案
方案一:创建缺失文件
卸载异常ECS实例的系统盘,并将该云盘作为数据盘挂载到正常ECS实例中。
具体操作,请参见Linux实例数据恢复最佳实践的步骤一~步骤二。
说明该正常实例最好是与异常实例运行相同的Linux发行版本,以方便后续恢复
/etc/os-release文件的操作。在正常ECS实例中,根据异常系统盘内是否存在
/etc/os-release文件执行相应操作。说明本示例中,假设异常系统盘中的文件系统挂载到了/mnt目录下。
可能情况
具体操作
/etc/os-release文件不存在根据正常ECS实例与异常ECS实例Linux发行版本是否相同,进行相应操作。
Linux发行版本相同:执行
cp /etc/os-release /mnt/etc/os-release命令将正常实例中的/etc/os-release文件复制到异常ECS实例。Linux发行版本不同:执行
vi /mnt/etc/os-release命令手动创建并编辑/etc/os-release文件。/etc/os-release文件的内容参照同一Linux发行版本的正常实例中的/etc/os-release文件内容进行填写。
说明可能会发现参照同一Linux发行版本的正常实例中的
/etc/os-release文件是一个指向其他文件的符号链接。您可根据实际情况选择一种操作进行修复。参考上述操作直接恢复包含实际内容的
/etc/os-release文件。因为
/etc/os-release和/usr/lib/os-release文件只要其中一个存在即可被systemd正确识别。参考下述的操作,先恢复
/etc/os-release指向的包含实际内容的其他文件,然后再恢复/etc/os-release符号链接,以确保系统文件的完整性和一致性。
/etc/os-release文件存在执行
ls -hal /etc/os-release命令。系统返回类似如下信息时,表明/etc/os-release文件是一个指向/usr/lib/os-release的符号链接。lrwxrwxrwx 1 root root 19 Dec 20 15:13 os-release -> /usr/lib/os-release根据
/usr/lib/os-release文件是否缺失,执行相应操作。/usr/lib/os-release文件不存在:Linux发行版本相同:执行
cp /usr/lib/os-release /mnt/usr/lib/os-release命令将正常实例中的/usr/lib/os-release文件复制到异常ECS实例。Linux发行版本不同:执行
vi /mnt/usr/lib/os-release命令手动创建并编辑/usr/lib/os-release文件。/usr/lib/os-release文件的内容参照同一Linux发行版本的正常实例中的/usr/lib/os-release文件内容进行填写。
/usr/lib/os-release文件存在:使用快照恢复系统盘进行修复,具体操作,请参见使用快照回滚云盘。
恢复异常ECS实例的系统盘。
具体操作,请参见Linux实例数据恢复最佳实践的步骤三。
通过SSH或VNC远程登录已修复的ECS实例,确认ECS实例恢复正常。
方案二:使用快照恢复系统盘
访问ECS控制台-快照。
在页面左侧顶部,选择目标资源所在的资源组和地域。
在云盘快照页签中找到待回滚云盘的快照,在操作列中单击回滚云盘。
在弹出的对话框中,单击确定。
1684829582:Linux实例的内存空间不足,导致操作系统出现内存溢出
问题现象
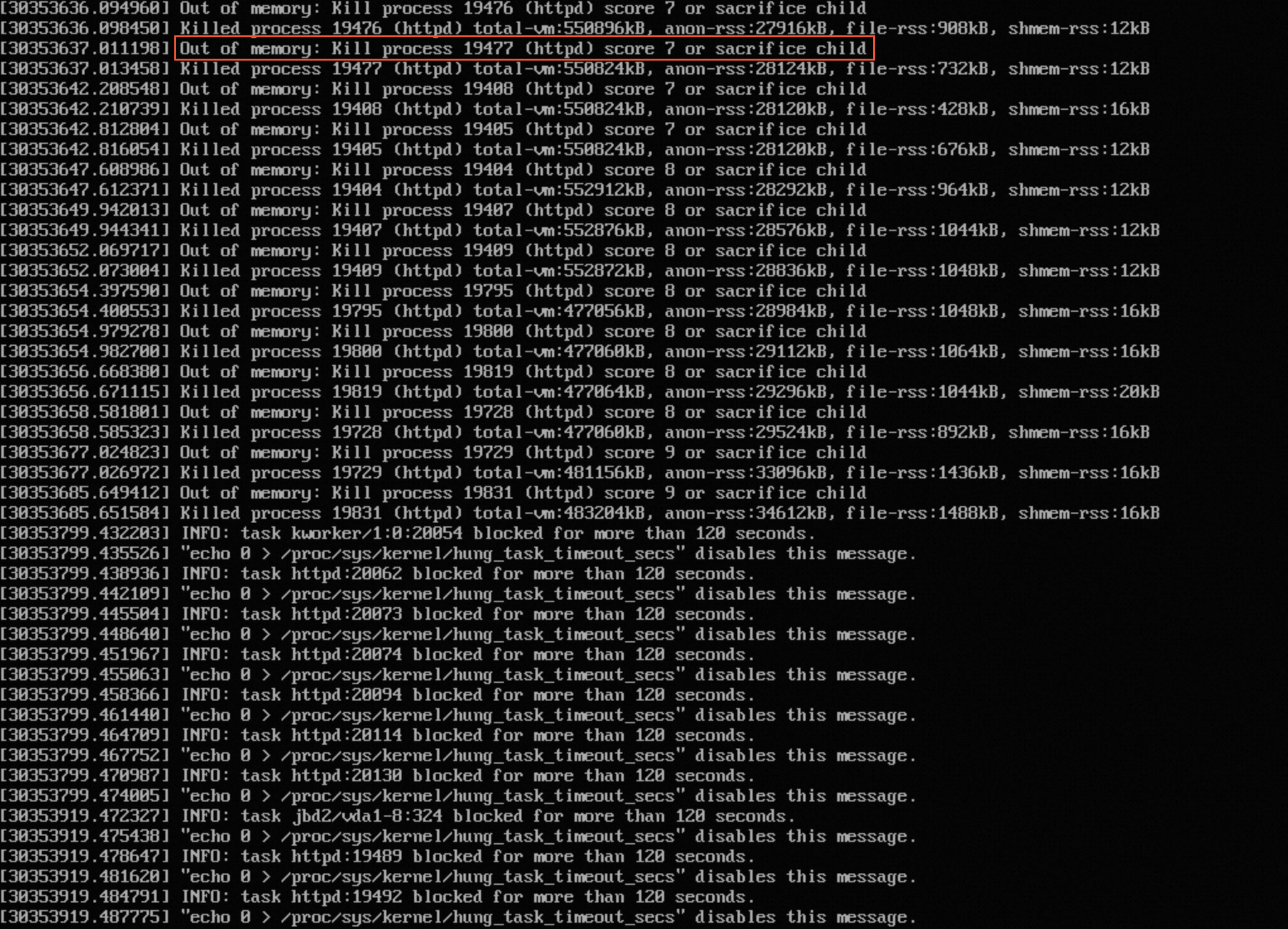
使用Linux实例时,出现程序崩溃、进程读写异常、ECS实例夯住(Hang)、ECS实例运行卡顿等现象,在系统日志/var/log/message中出现大量的Out of Memory(OOM)信息,如下图所示:
问题原因
Out of Memory(OOM)是Linux内核在系统内存严重不足时,强行释放进程内存的一种机制。
出现大量的Out of Memory信息可能是因为系统内存资源不足,系统无法为程序或者进程分配足够的内存空间,从而导致程序无法正常运行或者进程无法读写数据。
解决方案
触发OOM的原因较多(系统资源不足、内存泄漏、不合理的系统配置、内存分配不合理等),您可以通过以下步骤进行排查。
远程登录该ECS实例。
具体操作,请参见使用Workbench登录Linux实例。
执行如下命令,查看并记录OOM发生的进程、时间和频率。
cat /var/log/message查看发生OOM时间段内,Linux实例系统负载情况及业务应用日志。
查看Linux实例的系统负载情况。
使用云监控查询ECS实例负载信息。
通过
free、top或sar命令查看系统负载信息。更多信息,请参见Linux实例负载高问题排查和异常处理。
查看业务应用日志中触发OOM的原因。
使用Valgrind、jprofiler、jmap等内存分析工具分析应用程序的内存占用情况。
根据Linux实例系统负载及业务日志,分析OOM原因并进行相应处理。
如果是您当前Linux实例的内存不足以支撑业务运行。
根据业务需要,升级实例内存配置。具体操作,请参见包年包月实例升配规格或更改按量付费实例规格。
您的应用代码存在缺陷(例如内存泄漏、过度分配内存、不合理内存分配等)。
请根据您的业务应用日志中出现的问题优化您的业务代码。
继续观察ECS实例运行情况,当OOM问题不再出现,说明该问题已解决。