
导致阿里云Elasticsearch(简称ES)的负载不均问题的原因很多,目前主要包括shard设置不合理、segment大小不均、冷热数据需求、负载均衡及多可用区架构部署的长连接不释放等。本文介绍ES集群负载不均问题的分析方法及解决方案。
问题现象
节点间磁盘使用率差距不大,监控中节点CPU使用率或load_1m呈现明显的负载不均衡现象。
节点间磁盘使用率差距很大,监控中节点CPU使用率或load_1m呈现明显的负载不均衡现象。
问题原因
- 重要
大多数负载不均问题是由于shard设置不合理导致,建议优先排查。
存在典型的冷热数据需求场景。
重要冷热数据场景(例如查询中添加了routing、查询频率较高的热点数据)必然导致数据出现负载不均。
采用负载均衡及多可用区架构部署时,由于长连接不释放可能会导致流量不均(很少出现),详情请参见长连接不均匀。
其他情况导致的负载不均问题,请联系阿里云技术支持工程师排查。
Shard设置不合理
场景
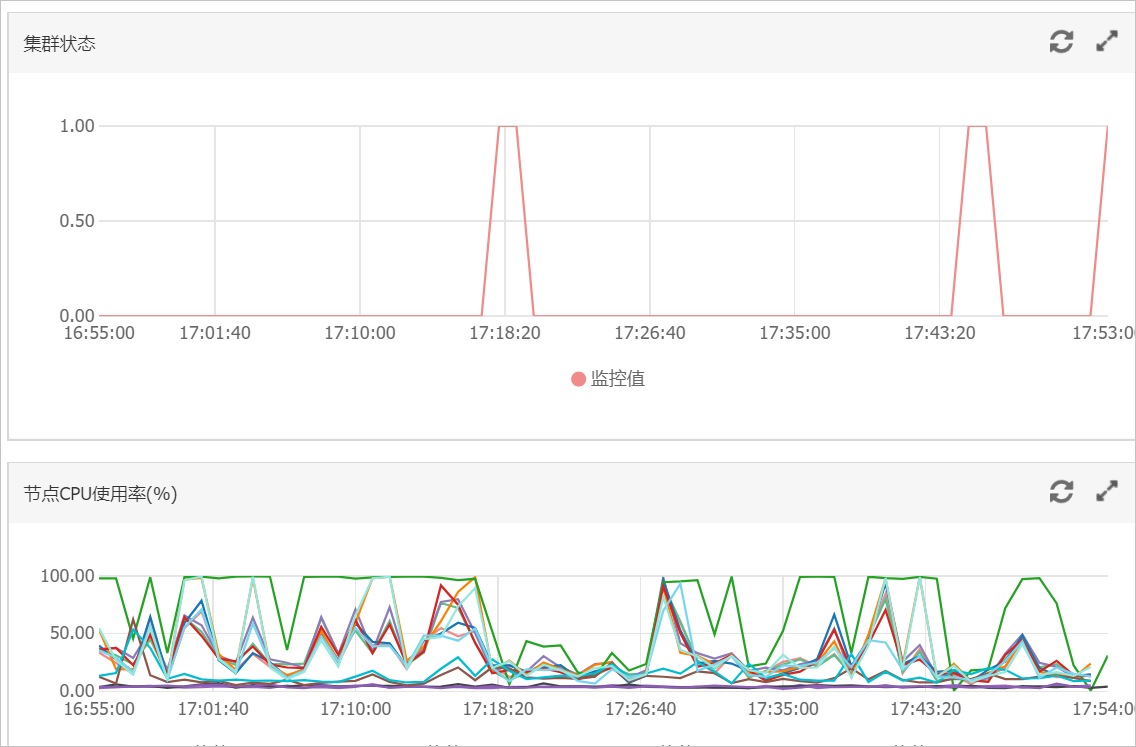
A公司有一个阿里云ES实例,该实例配置为:3个主节点16核32GB、9个数据节点32核64GB,主要数据保存在test索引上。当在业务高峰期的时候(16:21~18:00左右),查询QPS为2000左右(查询中没有冷热数据分离)、写入QPS为1000、2个节点的CPU达到100,负载过高影响ES服务。
分析
优先检查查询期间的网络及ECS情况。如果ECS环境正常,再查看网络流量监控。
根据监控结果发现异常期间(16:21)网络请求上升,查询QPS上升,对应的CPU节点负载大幅增高。结合查询策略,初步判断负载高的节点主要承担了查询请求。
使用
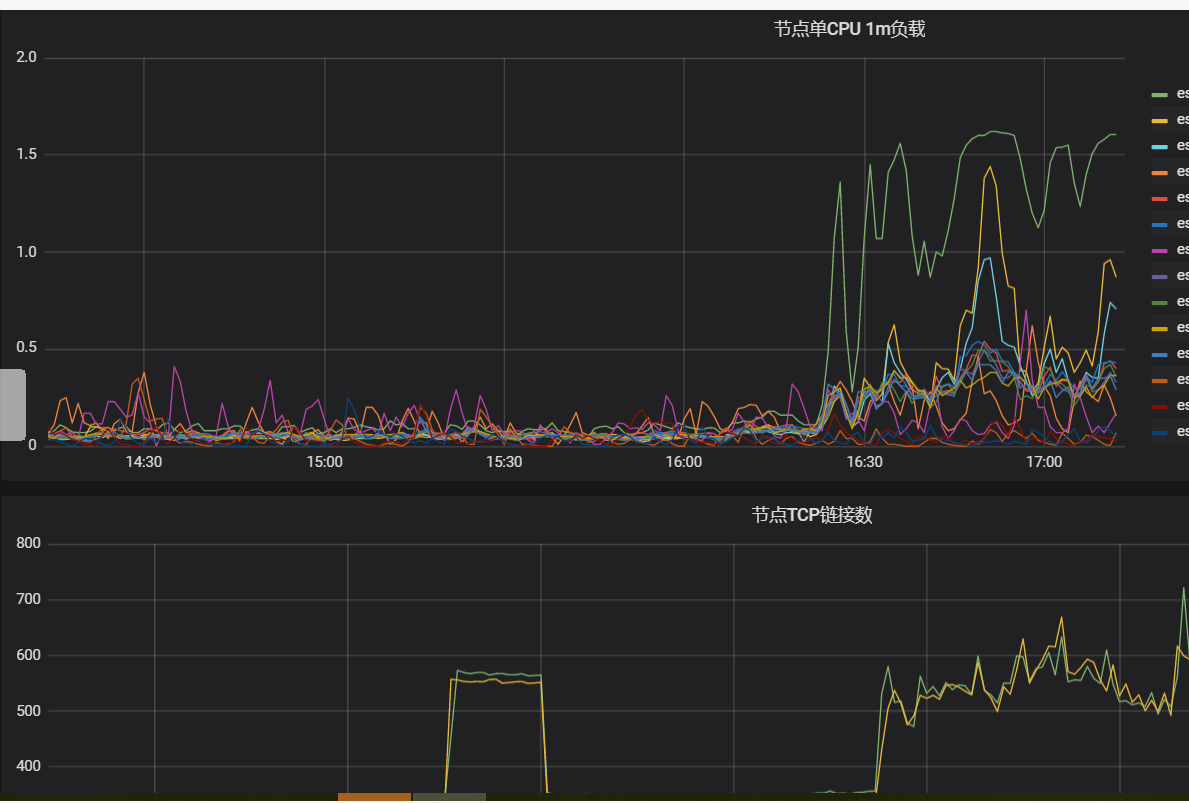
GET _cat/shards?v,查看索引的shard信息。从结果可以看到test索引的shard在负载高的节点上呈现的数量较多,说明shard分配不均;然后查看磁盘使用率监控图,显示负载高的节点使用率比其他节点高。由此可以得出,shard分配不均衡导致存储不均,在业务查询或写入中,存储高的节点承担主要的查询和写入。
使用
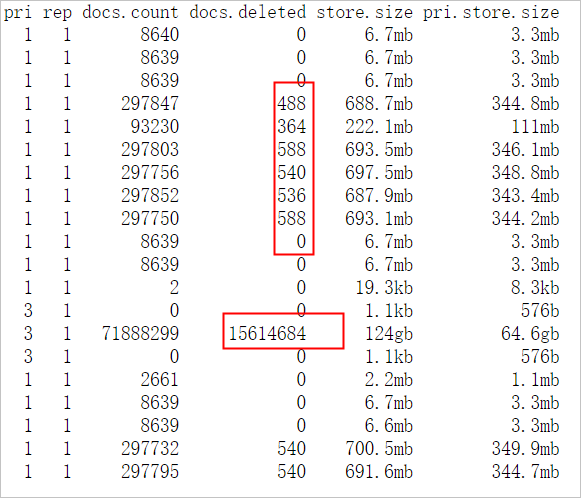
GET _cat/indices?v,查看索引信息。从结果可以看到索引的主shard数量为5,副shard数量为1。结合集群配置,发现存在节点shard分配不均的现象,其次集群中存在被删除的文档。ES在检索过程中也会检索.del文件,然后过滤标记有.del的文档,大大地降低检索效率,耗费规格资源,建议在业务低峰期进行force merge。
查看主日志及searching慢日志。
从结果可以看到查询请求都是普通的term查询,且主日志正常,可以排除ES集群本身出现问题以及存在消耗CPU的查询语句的情况。
总结
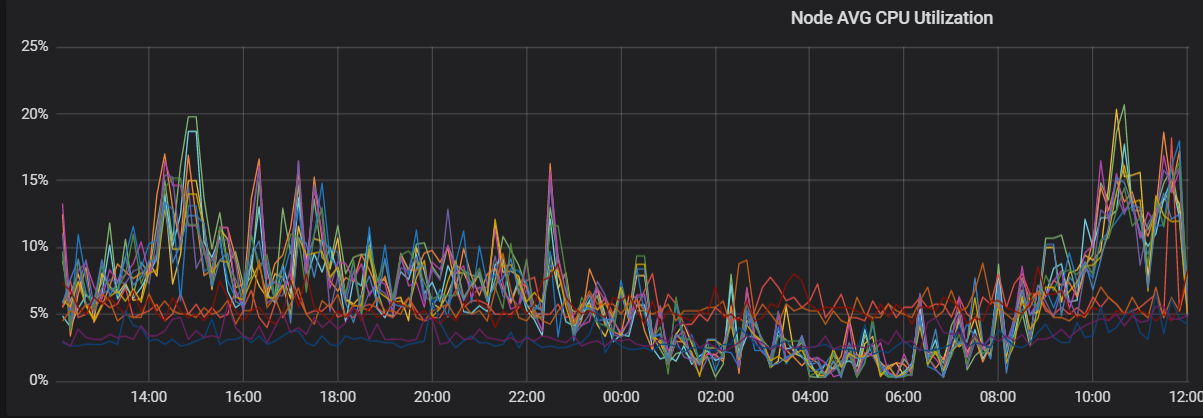
通过以上分析,可以判断CPU负载不均主要是由于shard分布不均导致的。重新分配分片,确保主shard数与副shard数之和是集群数据节点的整数倍,集群的CPU负载趋于稳定。优化后的CPU趋势图如下。
解决方案
在创建索引时,合理规划shard,详情请参见Shard评估建议。
Shard评估建议
Shard大小和数量是影响ES集群稳定性和性能的重要因素之一。ES集群中任何一个索引都需要有一个合理的shard规划。合理的shard规划能够防止因业务不明确,导致分片庞大消耗ES本身性能的问题。
ES 7.x以下版本的索引默认包含5个主shard,1个副shard;ES 7.x 及以上版本的索引默认包含1个主shard,1个副shard。
建议在小规格节点下,单个shard大小不要超过30GB。对于更高规格的节点,单个shard大小不要超过50GB。
对于日志分析或者超大索引场景,建议单个shard大小不要超过100GB。
建议shard的个数(包括副本)要尽可能等于数据节点数,或者是数据节点数的整数倍。
说明主分片不是越多越好,因为主分片越多,ES性能开销也会越大。
建议单节点shard总数按照单节点内存*30进行评估,如果shard数量太多,极易引起文件句柄耗尽,导致集群故障。
建议单个节点上同一索引的shard个数不要超5个。
如果您使用了自动创建索引功能,可通过设置场景模板,调整索引shard均衡,详情请参见修改场景化配置模板。
Segment大小不均
场景
A公司ES集群忽然出现单个节点CPU飙升,影响查询性能。查询主要集中在test索引、shard设置为3主1副、shard分配均衡、索引中存在大量的delete.doc,且优先排除了底层主机问题。
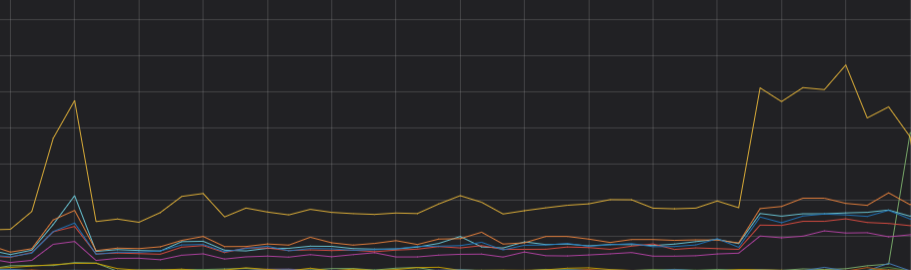
分析
在查询body中添加
"profile": true。根据结果可以看到test索引的1号shard查询时间比其他shard长。
查询中分别指定
preference=_primary和preference=_replica,body中添加"profile": true,分别查看主副shard查询消耗的时间。根据结果定位出索引的1号shard耗时主要体现在主shard上,判断和shard有关。
使用
GET _cat/segments/index?v&h=shard,segment,size,size.memory,ip及GET _cat/shards?v,查看索引的1号shard的信息。从结果可以看到索引的1号shard中存在比较大的segment,且doc数量比正常的副shard多。由此可以判断负载不均与segment大小不均有关。
说明造成主副shard的doc数量不一致的原因有很多,例如以下两种情况:
如果一直有doc写入shard,由于主副数据同步有一定延迟,会导致数据不一致。但一般停止写入后,主副doc数量是一致的。
如果使用自动生成docid的方式写入doc,由于主shard写入完成后会转发请求到副shard,因此在此期间,如果执行了删除操作,例如并行发送Delete by Query请求删除了主分片上刚写完的doc,那么副shard也会执行此删除请求;然后主shard又转发写入请求到副shard上,对于自动生成的id,doc将直接写入副shard,不进行检查,最终导致主副shard的doc数量不一致,同时在
doc.delete中也可以看到主shard中存在大量的删除文档。
解决方案(任选一种)
在业务低峰期进行force merge,将缓存中的delete.doc彻底删除,将小segment合并成大segment。
重启主shard所在节点,触发副shard升级为主shard。并且重新生成副shard,副shard复制新的主shard中的数据,保持主副shard的segment一致。
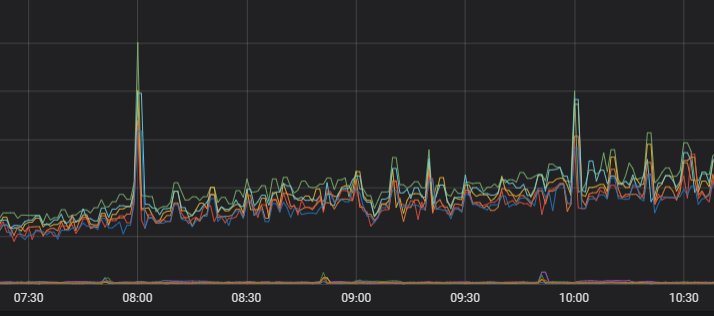
优化后的负载监控图如下。

长连接不均匀
场景
A公司为实现ES集群跨区域容灾部署,分别在b区和c区部署高可用架构,在持续提供业务操作时,集群中c区节点负载明显比b区高,并且已经排除数据分配不均及硬件问题。
分析
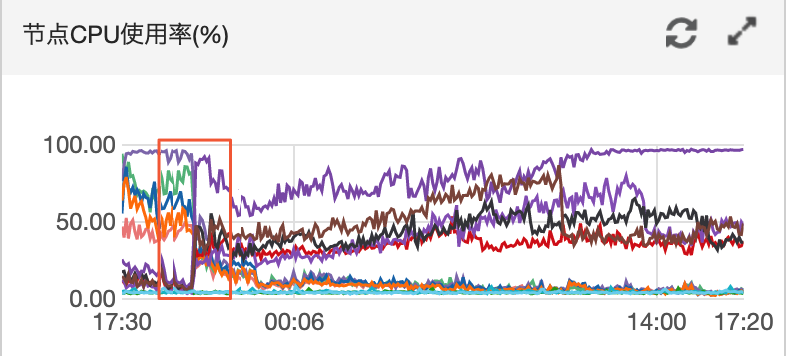
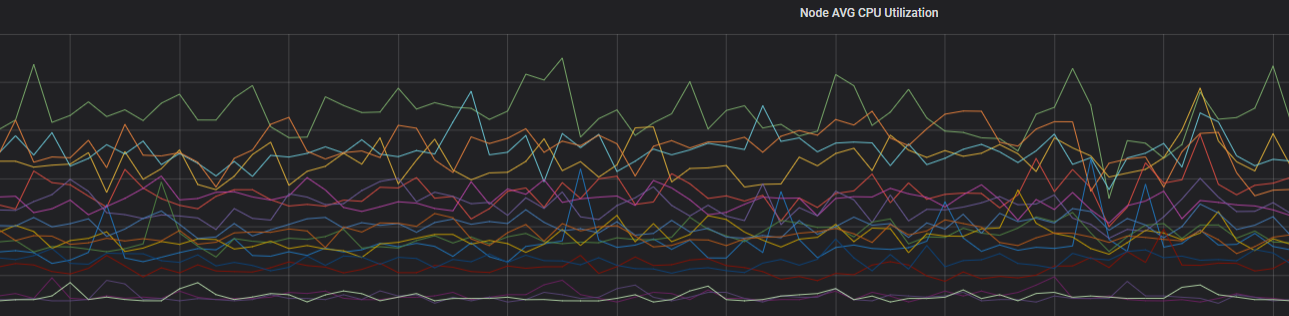
观察近4天两区域节点的CPU监控。
根据结果可以看到两区域节点CPU出现较大负载变动。
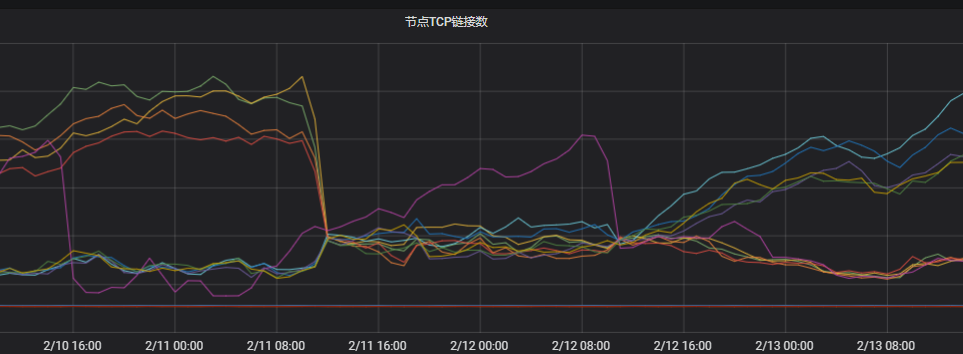
观察节点TCP连接。
根据结果可以看到两个区域下的连接数相差很大。判定与网络不均相关。
排查客户端的连接情况。
客户端使用长连接,新建连接比较少,恰恰命中了多可用区网络独立调度的风险(网络服务是基于连接数独立调度的,每个调度单元会选择自己认为最优的节点进行创建,独立调度的性能会更高,但独立调度的风险是当新连接比较少的时候,有一定概率出现大部分调度单元都选择相同的节点去建立连接)。ES的协调节点对于请求的转发是同区域优先,即ES将请求转到其他区域的可能性较小,这样就导致当前区域出现负载不均的问题。
解决方案(任选一种)
客户端配置
httpClientBuilder.setConnectionTimeToLive()。例如,配置连接有效时长为5分钟:httpClientBuilder.setConnectionTimeToLive(5, TimeUnit.MINUTES)。详细信息,请参见HttpAsyncClientBuilder。说明客户端配置链接有效时长需要使用ES推荐的httpClientBuilder.setConnectionTimeToLive(),配置别的参数效果可能不太明显,例如:httpClientBuilder.setKeepAliveStrategy()。
并发重启客户端,重新建立连接。
使用单独的协调节点,通过工作职责划分来降低风险。使用协调节点转发复杂流量,即使负载高,也不会影响到后面的数据节点。
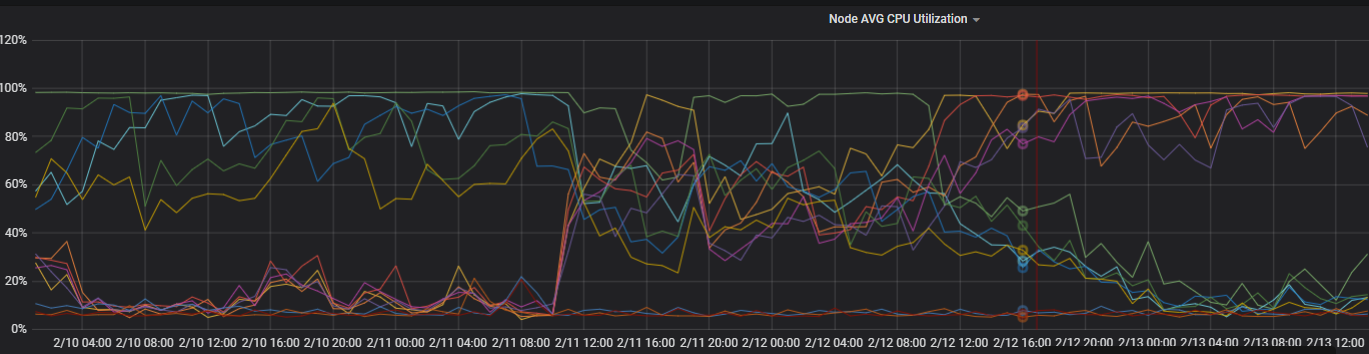
优化后的负载监控图如下。
单个索引分片不均匀
场景:观察每个节点分片较均衡,但是业务索引在负载较高的节点分布的分片数比较多或承载单分片数据量多。
解决方案:设置控制每个节点上分配给单个索引的最大分片数量index.routing.allocation.total_shards_per_node,参数取值计算公式为
(主+副本数)/数据节点个数,参数值需为整数,小数向上取整。PUT index_name/_settings { { "index.routing.allocation.total_shards_per_node" : "3" } }