
您可在检索增强型应用(8.17版)中通过Inference API调用AI模型,实现包括但不限于文本结构化提取、文档智能分片、文本向量化转化处理等高级功能。通过与AI模型的深度融合,应用在搜索准确性、响应效率及数据处理智能化方面得到显著提升,助力您构建更高效、精准的检索系统,全面增强其在复杂业务场景下的数据分析与语义理解能力。
背景信息
AI搜索开放平台是智能开放搜索OpenSearch的子产品,围绕智能搜索及RAG场景,将AI搜索链路中用到的算法服务以组件化形式提供,内置文档解析、文档切片、文本向量化、查询分析、召回、排序、效果评估以及LLM模型服务,开发者可根据自身情况灵活选择组件服务进行搜索业务开发。
在检索增强型应用(8.17版)中,可通过Inference API调用模型服务,进行数据处理、查询改写、文本生成等操作。
计费说明
使用AI模型服务将由AI搜索开放平台收费,并按实际模型调用量计费,不使用则不收费。
费用产生后,您可登录费用与成本系统查看消费明细。
前提条件
步骤一:开通并初始化AI模型
使用AI模型前,您需先开通AI搜索开放平台服务并完成初始化操作,该操作执行后,系统将自动为您生成调用模型所需的信息并将相关模型创建至您的应用中。
进入应用详情页。
登录Elasticsearch Serverless控制台,在顶部菜单栏切换至目标地域。
在左侧导航栏单击应用管理,单击已创建的应用名称,进入应用详情页。
在左侧导航栏,单击,进入模型管理页面。
开通并初始化AI模型服务。
若当前登录账号之前未开通AI搜索开放平台,请在模型管理页面单击开通服务并初始化模型,按照界面指引开通AI模型服务。开通后,系统将自动进行初始化,生成调用模型所需的API Key、模型服务空间、模型服务接入地址等信息,并将其注册至AI搜索开放平台。同时,系统会创建检索增强型应用(8.17版)支持的AI模型,您可直接调用相关模型进行数据处理。
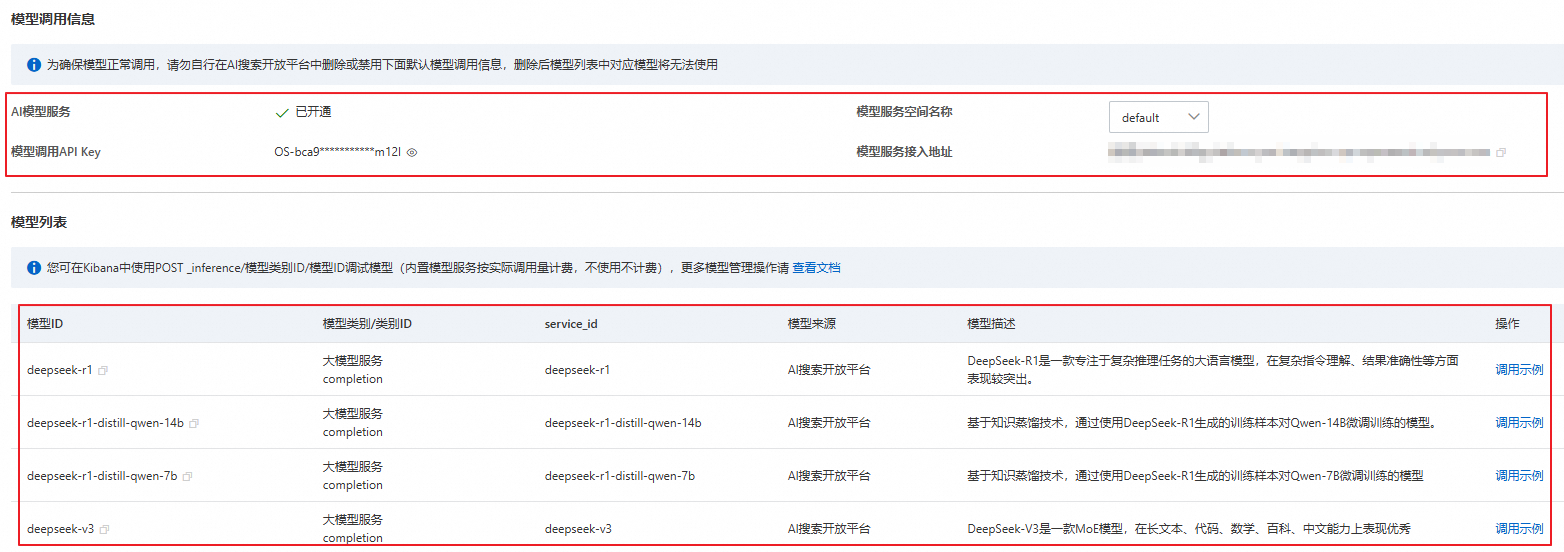
模型调用信息介绍如下:
模型服务空间名称:空间用于隔离及管理数据。首次开通AI搜索开放平台后,系统会自动创建一个名为
Default的默认空间。您也可按需创建空间。说明如需使用自定义空间,请在模型管理页面切换空间后,按照界面指引重新进行模型初始化,以确保系统生成当前空间调用模型所需的API Key,并将检索增强型应用(8.17版)支持的AI模型创建至当前空间。模型创建完成后,才可在该空间中使用相应模型。
模型调用API Key:调用AI模型相关的API或SDK时,可通过API Key进行身份认证,以确保调用操作安全、可靠。
模型服务接入地址:检索增强型应用(8.17版)可通过该私有网络地址访问AI搜索开放平台,调用相关模型。如需使用公共网络调用AI模型,请参见获取服务接入地址。
说明当前登录账号首次开通AI搜索开放平台时,系统会自动生成API Key及接入地址,并且该账号下所有应用在调用模型时均可使用此API Key及接入地址。
步骤二:在应用中调用AI模型
模型初始化完成后,您可按需调用合适模型进行文档内容解析、文档切分、查询分析等多种场景的应用。本文通过Kibana调用AI模型,进行相关数据推理操作。
调用操作
进入Kibana开发页面。
说明登录Kibana前,请确认待访问设备已加入公网或私网访问Kibana的白名单中;登录账号及密码,可参考操作步骤获取。
在模型管理页面,单击右上角的访问Kibana,按照界面指引进入Kibana操作界面。
单击左上角的
 图标,选择,进入Kibana开发页面。
图标,选择,进入Kibana开发页面。
调用AI模型。
您可在Kibana中直接使用系统创建的模型进行数据推理操作,调用模型的语句格式如下。模型类别ID及模型ID,可参考模型列表获取。
POST _inference/模型类别ID/模型ID示例调用
ops-query-analyze-001模型进行查询分析,语句如下。POST _inference/query_analyze/ops-query-analyze-001说明检索增强型应用(8.17版)支持多种类别的Inference APIs及AI模型,您可按需选择。
更多模型的创建及调用操作,请参见AI搜索开放平台内置模型服务。
调用示例
示例一:调用AI模型进行文档内容解析
在Kibana中调用系统自动创建的ops-document-analyze-001模型,解析非结构化文档数据,并将其转换为结构化数据。
您可按需选择同步调用或异步调用,请求模板如下。
同步调用和异步调用为文档分析任务的执行模式。
同步调用:提交文档分析任务后,Elasticsearch Serverless会立即阻塞当前请求线程,等待AI搜索开放平台服务处理。处理完成后,将结果直接返回给客户端。
异步调用:提交文档分析任务后,Elasticsearch Serverless会立即返回任务ID,不会等待处理结果。客户端需发起独立请求查询任务状态和结果。
POST _inference/doc_analyze/ops-document-analyze-001
{
"input": ["<document_url_or_content>"],
"task_settings": {
"document": {
"input_type": "<url_or_content_or_task_id>",
"file_name": "<optional_file_name>",
"file_type": "<optional_file_type>"
},
"output": {
"image_storage": "<base64_or_url>"
},
"is_async": "<true_or_false>"
}
}核心参数说明如下。
参数 | 描述 |
input | 需要进行解析的文档。输入可以是URL、内容或任务ID。 |
task_settings | 任务的设置。 |
document.input_type | 文档的类型,取值如下:
|
document.file_name | 文件名。若该参数为空,系统会根据URL进行推断,如果URL也为空,则需您指定该参数。 |
document.file_type | 文件类型。若该参数为空,系统会根据 |
output.image_storage | 图片的存储方式,取值如下:
|
is_async | 本次调用是否为异步调用,取值如下:
|
同步调用示例
说明该操作执行后,系统将直接返回处理结果。
POST _inference/doc_analyze/ops-document-analyze-001 { "input": ["http://opensearch-shanghai.oss-cn-shanghai.aliyuncs.com/chatos/rag/file-parser/samples/GB10767.pdf"] }返回结果示例如下图。

异步调用示例
执行调用操作,示例代码如下。
说明该操作执行后,系统会返回
task_id(即异步任务的ID),您可通过该ID查询任务结果。POST _inference/doc_analyze/ops-document-analyze-001 { "input": ["http://opensearch-shanghai.oss-cn-shanghai.aliyuncs.com/chatos/rag/file-parser/samples/GB10767.pdf"], "task_settings": { "document": { "input_type": "url" }, "is_async": true } }返回结果示例如下图。
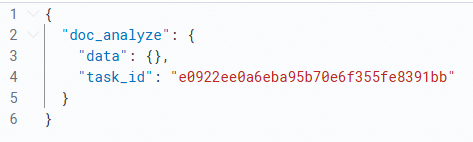
获取异步结果,示例代码如下。
# 此处输入的input为上一步返回的task_id。 POST _inference/doc_analyze/ops-document-analyze-001 { "input": ["e0922ee0a6eba95b70e6f355fe8391bb"], "task_settings": { "input_type": "task_id", "is_async": true } }返回结果示例。

示例二:调用AI模型进行文档切片
在Kibana中调用系统自动创建的ops-document-split-001模型,实现对输入文档进行文档切片。
请求模板如下。input表示需要切片的文本内容。
根据JSON标准,String字段如果包含\\、\"、\/、\b、\f、\n、\r或\t字符,则需要转义。常用JSON库生成的JSON字符串无需手动转义。
POST _inference/doc_split/ops-document-split-001
{
"input":"<input>"
}调用示例如下。
POST _inference/doc_split/ops-document-split-001
{
"input":"Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:一个分布式的实时文档存储,每个字段可以被索引与搜索.一个分布式实时分析搜索引擎.能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据.Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。就 Elasticsearch 而言,起步很简单。对于初学者来说,它预设了一些适当的默认值,并隐藏了复杂的搜索理论知识。 它 开箱即用。只需最少的理解,你很快就能具有生产力。随着你知识的积累,你可以利用 Elasticsearch 更多的高级特性,它的整个引擎是可配置并且灵活的。 从众多高级特性中,挑选恰当去修饰的 Elasticsearch,使它能解决你本地遇到的问题。你可以免费下载,使用,修改 Elasticsearch。它在 Apache 2 license 协议下发布的, 这是众多灵活的开源协议之一。Elasticsearch 的源码被托管在 Github 上 github.com/elastic/elasticsearch。 如果你想加入我们这个令人惊奇的 contributors 社区,看这里 Contributing to Elasticsearch。如果你对 Elasticsearch 有任何相关的问题,包括特定的特性(specific features)、语言客户端(language clients)、插件(plugins),可以在这里 discuss.elastic.co 加入讨论。"
}返回结果示例如下。
{
"doc_split": {
"rich_texts": [],
"nodes": [
{
"parent_id": "cfe3181f03344e208a6e63efd4a674ff",
"id": "cfe3181f03344e208a6e63efd4a674ff",
"type": "root"
},
{
"parent_id": "cfe3181f03344e208a6e63efd4a674ff",
"id": "7574e031dd8c4880b42975f601783305",
"type": "sentence_node"
},
{
"parent_id": "cfe3181f03344e208a6e63efd4a674ff",
"id": "8ca382cf6d8f4cb38f4a2f6433de47af",
"type": "sentence_node"
}
],
"chunks": [
{
"meta": {
"parent_id": "cfe3181f03344e208a6e63efd4a674ff",
"hierarchy": [],
"id": "7574e031dd8c4880b42975f601783305",
"type": "text",
"token": 298
},
"content": "Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:一个分布式的实时文档存储,每个字段可以被索引与搜索.一个分布式实时分析搜索引擎.能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据.Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。就 Elasticsearch 而言,起步很简单。对于初学者来说,它预设了一些适当的默认值,并隐藏了复杂的搜索理论知识。 它 开箱即用"
},
{
"meta": {
"parent_id": "cfe3181f03344e208a6e63efd4a674ff",
"hierarchy": [],
"id": "8ca382cf6d8f4cb38f4a2f6433de47af",
"type": "text",
"token": 160
},
"content": "只需最少的理解,你很快就能具有生产力。随着你知识的积累,你可以利用 Elasticsearch 更多的高级特性,它的整个引擎是可配置并且灵活的。 从众多高级特性中,挑选恰当去修饰的 Elasticsearch,使它能解决你本地遇到的问题。你可以免费下载,使用,修改 Elasticsearch。它在 Apache 2 license 协议下发布的, 这是众多灵活的开源协议之一。Elasticsearch 的源码被托管在 Github 上 github.com/elastic/elasticsearch。 如果你想加入我们这个令人惊奇的 contributors 社区,看这里 Contributing to Elasticsearch。如果你对 Elasticsearch 有任何相关的问题,包括特定的特性(specific features)、语言客户端(language clients)、插件(plugins),可以在这里 discuss.elastic.co 加入讨论。"
}
],
"sentences": []
}
}示例三:调用AI模型进行文本向量化
在Kibana中调用系统自动创建的ops-text-embedding-001模型,实现将输入文本转换为数值向量。输出的向量可捕捉文本的语义信息,便于后续的相似性计算、聚类、分类等任务。
请求模板如下。input表示输入的文本内容。
每次请求最多支持输入32条文本,每条文本的长度不超过300Token,并且不支持空字符串。不同文本向量化模型支持的文本长度存在差异,详情请参见模型列表。
POST _inference/text_embedding/ops-text-embedding-001
{
"input":[<input>]
}调用示例如下。
POST _inference/text_embedding/ops-text-embedding-001
{
"input":["科学技术是第一生产力",
"elasticsearch产品文档"]
}返回结果示例如下。
{
"text_embedding": [
{
"embedding": [
-0.029408421,
0.061318535,
...
]
},
{
"embedding": [
0.01568979,
0.065073475,
...
]
}
]
}附录一:支持的Inference APIs
检索增强型应用(8.17版)支持的Inference APIs如下表。
接口 | 描述 |
支持从非结构化文档中提取标题、分段等逻辑层级结构,以及文本、表格、图片等信息,并以结构化的格式输出。 | |
| |
提供通用的文本切片策略,可基于文档段落格式、文本语义、指定规则,对HTML、Markdown、TXT格式的结构化数据进行拆分。同时,支持提取富文本形式的Code、Image、Table。 | |
支持将文本数据转化为稠密向量形式表达,可用于信息检索、文本分类、相似性比较等场景。 | |
支持将文本数据转化为稀疏向量形式表达,稀疏向量存储空间更小,常用于表达关键词和词频信息,可与稠密向量搭配进行混合检索,提升检索效果。 | |
提供Query内容分析服务,基于大语言模型及NLP能力,可对您输入的查询内容进行意图识别、相似问题扩展、NL2SQL处理等,有效提升RAG场景中检索问答效果。 | |
提供通用的文档打分能力,可根据Query与文档内容的相关性,按分数对Doc进行降序排序,并输出对应的打分结果。 | |
调用包含基于阿里巴巴自研模型底座微调的RAG专属大模型服务。可结合文档处理、检索服务等,在RAG场景中广泛应用,提升答案的准确率,降低幻觉率。 |
附录二:支持的模型列表
检索增强型应用(8.17版)已接入的AI模型如下表。
模型类别 | 模型类别ID | 模型ID | 模型描述 |
大模型服务 | completion | deepseek-r1 | 专注于复杂推理任务的大语言模型,在复杂指令理解、结果准确性等方面表现较突出。 |
deepseek-r1-distill-qwen-14b | 基于知识蒸馏技术,利用 | ||
deepseek-r1-distill-qwen-7b | 基于知识蒸馏技术,利用 | ||
deepseek-v3 | 一款MoE模型,在长文本、代码、数学、百科、中文等能力表现优秀。 | ||
ops-qwen-turbo | 以 | ||
qwen-max | 千问 | ||
qwen-plus | 千问的超大规模语言模型的增强版,支持中文、英文等不同语言的输入。 | ||
qwen-turbo | 千问的超大规模语言模型,支持中文、英文等不同语言的输入。 | ||
多模态向量 | multi_modal_embedding | ops-gme-qwen2-vl-2b-instruct | 基于 |
ops-m2-encoder | 中、英双语多模态服务。基于 | ||
ops-m2-encoder-large | 中、英双语多模态服务。相较 | ||
重排序 | rerank | ops-bge-reranker-larger | 提供基于BGE模型的文档打分服务,可根据查询(即Query)与文档内容的相关性,按分数对文档(即Doc)进行降序排序,并输出对应的打分结果。
|
ops-text-reranker-001 | OpenSearch自研的重排模型。融合了多个行业的数据集进行训练,提供高水准的重排服务,可根据查询(即Query)及文档(即Doc)的语义相关性,对文档进行降序排序。
| ||
文档内容解析 | doc_analyze | ops-document-analyze-001 | 提供通用的文档解析服务,支持从非结构化文档中提取标题、分段等逻辑层级结构,以及文本、表格、图片等信息,并以结构化的格式输出。 |
文档切片 | doc_split | ops-document-split-001 | 提供通用的文本切片策略,可基于文档段落格式、文本语义、指定规则,对HTML、Markdown、TXT格式的结构化数据进行拆分。同时,支持从富文本形式提取Code、Image、Table。 |
图片内容解析 | img_analyze | ops-image-analyze-ocr-001 | 提供图片内容OCR(Optical Character Recognition,光学字符识别)识别服务,可基于OCR能力对图片的文字信息进行识别及提取,用于图片检索及问答等场景。 |
ops-image-analyze-vlm-001 | 提供图片内容解析服务,可基于多模态大模型对图片内容进行解析及文字识别,解析后的文本可用于图片检索及问答等场景。 | ||
查询分析 | query_analyze | ops-query-analyze-001 | 提供通用的查询分析服务,可基于大语言模型对您输入的Query进行意图理解及相似问题扩展。 |
文本向量化 | text_embedding | ops-text-embedding-001 | 提供40多种语言的文本向量化服务,输入文本的最大长度为 |
ops-text-embedding-002 | 提供100多种语言的文本向量化服务,输入文本的最大长度为 | ||
ops-text-embedding-en-001 | 提供英文文本向量化服务,输入文本的最大长度为 | ||
ops-text-embedding-zh-001 | 提供中文文本向量化服务,输入文本的最大长度为 | ||
文本稀疏向量化 | sparse_embedding | ops-text-sparse-embedding-001 | 提供100多种语言的文本向量化服务,输入文本的最大长度为 |
相关文档
更多关于AI搜索的介绍及其场景应用,请参见: