
社交类业务场景的数据模型天然具备高度连接的特点,图数据库GDB可以为社交类业务提供天然的图模型支持,更加完美的匹配和理解您的数据。使用图数据库GDB,可以显著提升社交类业务程序的开发效率和质量,减少数据模型转换带来的额外损耗。
1、数据模型
以社交领域公开数据集Twitter社交关系为例。更多信息,请参见数据模型参考下载。
图数据库GDB使用属性图模型来表示和处理数据,可以将数据模型抽象为下图:
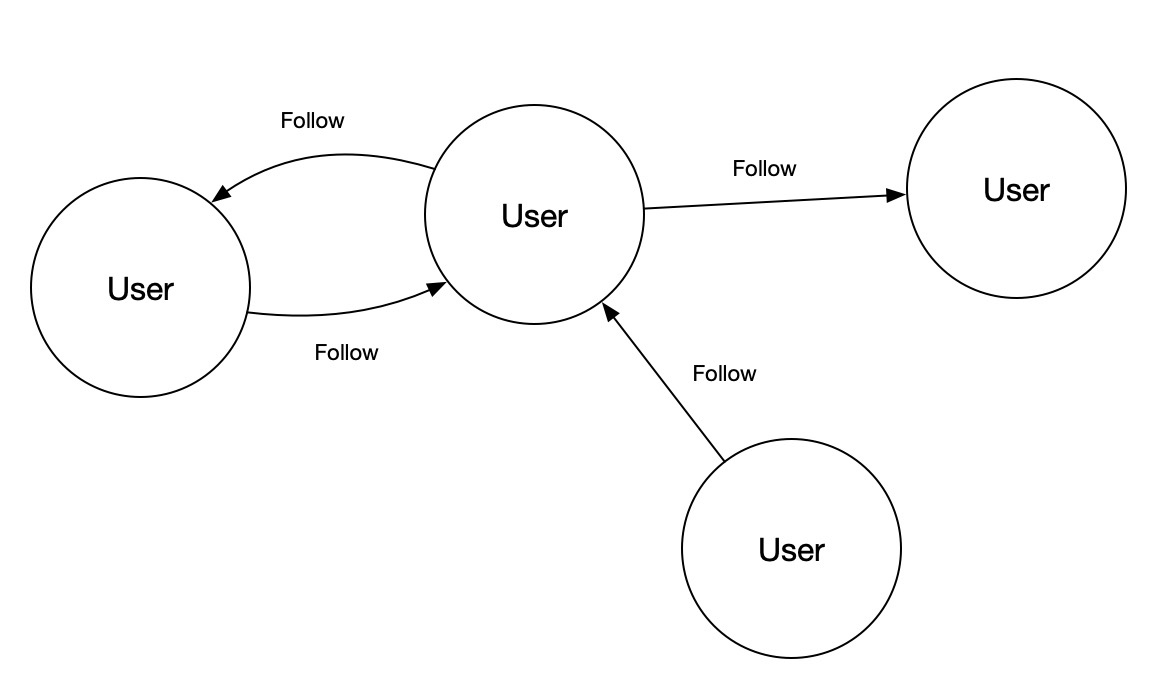
说明
- User:用户节点。
- Follow:代表单向的好友关系。比如关注,或者是对方的粉丝。
示例数据如下:
- 点文件:
~id,name:string 1,a0e05a4a-65c0-11e9-a5ce-00163e0416f8 2,a0e05e28-65c0-11e9-a5ce-00163e0416f8 3,a0e05f86-65c0-11e9-a5ce-00163e0416f8 4,a0e0606c-65c0-11e9-a5ce-00163e0416f8 5,a0e0613e-65c0-11e9-a5ce-00163e0416f8 6,a0e06206-65c0-11e9-a5ce-00163e0416f8 - 边文件:
~id,~from,~to,weight:double 212416660,1116299,4377946,0.443259 212416661,1116300,4377946,0.0303036 212416662,181406,4377946,0.753659 212416663,4084735,4377946,0.991974 212416664,1937755,4377946,0.79248
2、创建实例
3、数据导入
图数据库GDB支持从多种数据源将数据导入至图数据库GDB,您可以使用以下两种方式进行数据导入:
4、连接实例
图数据库GDB支持多种方法连接实例,您可以通过以下五种方式连接实例:
- 通过GDB控制台直接登录数据管理服务DMS,更加方便快捷地远程访问、在线管理您的GDB数据库。具体操作,请参见通过DMS登录GDB数据库。
- 通过开源组件GDB Console可视化控制台登录图数据库,可视化界面,操作简单,并可根据业务需求对可视化界面进行二次开发。具体操作,请参见通过开源组件GDB Console登录图数据库。
- 通过Gremlin Console连接实例,命令行模式,适合Gremlin内核版本,适合用于查询语句性能优化。具体操作,请参见通过Gremlin Console连接实例。
- 通过Cypher Shell连接实例,命令行模式,适合Cypher内核版本。具体操作,请参见通过Cypher Shell连接实例 。
- 通过SDK连接,支持Java、Python、.Net、Go、Node.js五种SDK。具体操作,请参见SDK参考。
5、使用范例
- 简单查询
- 数据统计:
//统计点的数目 gremlin> g.V().count() ==>41999999 //统计边的数目 gremlin> g.E().count() ==>22191165 - 过滤查询、排序查询:
//查询name为a0e05a4a-65c0-11e9-a5ce-00163e0416f8的用户。 gremlin> g.V().has('name','a0e05a4a-65c0-11e9-a5ce-00163e0416f8').valueMap(true) //条件查询,类似select ... where ...,根据业务修改has()中的内容即可。 ==>[id:1,label:vertex,name:[a0e05a4a-65c0-11e9-a5ce-00163e0416f8]] //查询name为a0e05a4a-65c0-11e9-a5ce-00163e0416f8的用户的关注列表。 gremlin> g.V().has('name','a0e05a4a-65c0-11e9-a5ce-00163e0416f8').outE().valueMap(true) //条件查询,类似select ... where ...,根据业务修改has()中的内容即可 ==>[id:217089344,label:edge,weight:0.769055] ==>[id:220429042,label:edge,weight:0.290449] ==>[id:227652991,label:edge,weight:0.962171] ==>[id:234881614,label:edge,weight:0.0887247] ==>[id:250193757,label:edge,weight:0.756271] ==>[id:252223359,label:edge,weight:0.990445] ==>[id:252494754,label:edge,weight:0.494867] ==>[id:254012304,label:edge,weight:0.788503] ==>[id:260893506,label:edge,weight:0.247677] ==>[id:228404583,label:edge,weight:0.0742597] ==>[id:243912806,label:edge,weight:0.906016] ==>[id:262031400,label:edge,weight:0.649892] //查询name为a0e05a4a-65c0-11e9-a5ce-00163e0416f8的用户的关注列表,并按照权重倒序排序。 gremlin> g.V().has('name','a0e05a4a-65c0-11e9-a5ce-00163e0416f8').outE().order().by('weight', decr).valueMap(true) //has()部分控制查询条件,order().by()部分控制排序条件。 ==>[id:252223359,label:edge,weight:0.990445] ==>[id:227652991,label:edge,weight:0.962171] ==>[id:243912806,label:edge,weight:0.906016] ==>[id:254012304,label:edge,weight:0.788503] ==>[id:217089344,label:edge,weight:0.769055] ==>[id:250193757,label:edge,weight:0.756271] ==>[id:262031400,label:edge,weight:0.649892] ==>[id:310064671,label:edge,weight:0.639453] ==>[id:316084412,label:edge,weight:0.595669] ==>[id:277559997,label:edge,weight:0.538571] ==>[id:252494754,label:edge,weight:0.494867] ==>[id:291708246,label:edge,weight:0.387777] ==>[id:281304400,label:edge,weight:0.382627] ==>[id:310008546,label:edge,weight:0.333313] ==>[id:220429042,label:edge,weight:0.290449] ==>[id:260893506,label:edge,weight:0.247677] ==>[id:300018487,label:edge,weight:0.228707] ==>[id:234881614,label:edge,weight:0.0887247] ==>[id:289510146,label:edge,weight:0.078113] ==>[id:228404583,label:edge,weight:0.0742597]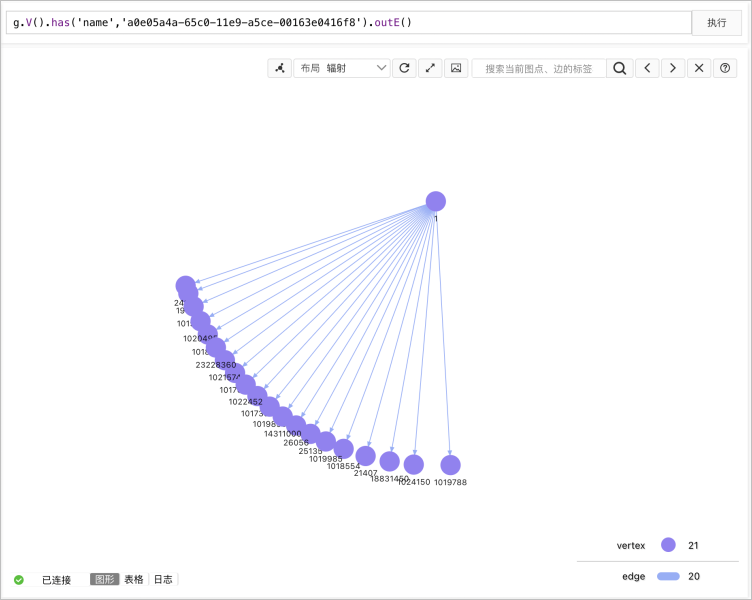
- 数据统计:
- 通用场景:
- k阶邻居:
//查询用户ID为23的2跳关注关系。 gremlin> g.V(23).repeat(outE('edge').otherV().simplePath()).times(2).path() //outE()部分控制查询边类型,times()部分查询深度。 ==>[v[23],e[239197952][23-edge->19201],v[19201],e[229218134][19201-edge->18246],v[18246]] ==>[v[23],e[239197952][23-edge->19201],v[19201],e[216091024][19201-edge->2586961],v[2586961]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[225145280][2587481-edge->1018015],v[1018015]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[284567757][2587481-edge->1022162],v[1022162]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[235313604][2587481-edge->10467758],v[10467758]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[265280161][2587481-edge->15350178],v[15350178]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[280654355][2587481-edge->1796334],v[1796334]] ......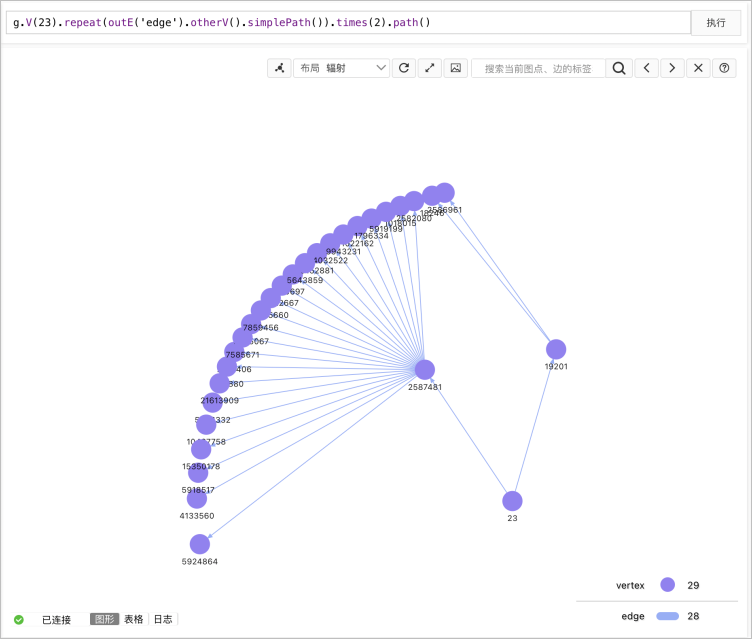
- 最短路径:
//查询ID为23和ID为5924864 的最短路径,最大深度为2。 gremlin> g.V(23).repeat(bothE().otherV().simplePath()) .until(hasId(5924864).or().loops().is(gt(2L))) //hasId()部分控制结束ID,gt()部分查询深度。 .hasId(5924864).path().dedup() ==>[v[23],v[2587481],v[5924864]]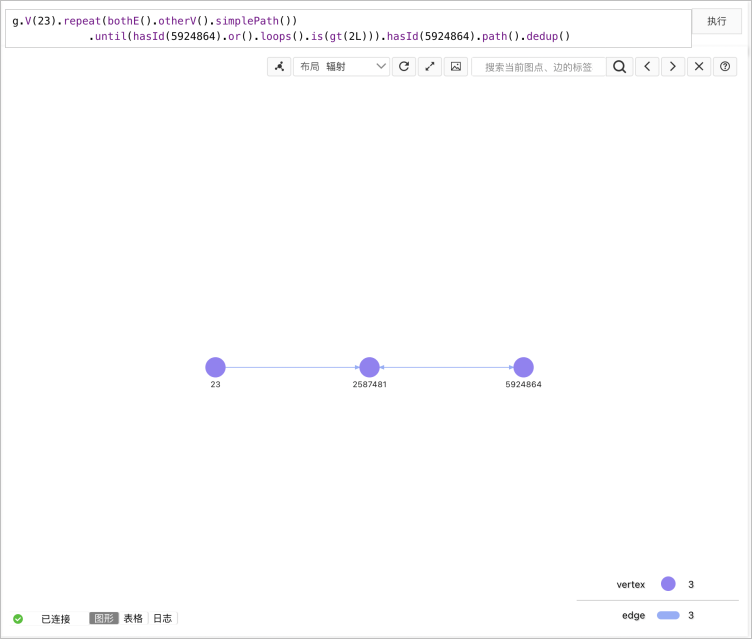
- 共同邻居:
//查询ID为23和ID为5924864的共同邻居。 gremlin> g.V(23).repeat(bothE().otherV().simplePath()).times(2).hasId(5924864).path().dedup() //hasId()部分控制结束ID。 ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[267070009][5924864-edge->2587481],v[5924864]]
- 大V查找:
//社交场景中,大V往往是根据粉丝的数量来衡量,粉丝越多说明越受欢迎,我们要找到拥有粉丝最多的三个大V。 gremlin> g.V().project('user','degree').by().by(inE().count()).order().by(select('degree'), desc).limit(3) // by(inE().count()) 部分控制统计逻辑,order().by(select('degree'), desc).limit(3) 控制排序逻辑 ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[267070009][5924864-edge->2587481],v[5924864]] ==>[v[23],e[267069904][23-edge->2587481],v[2587481],e[316011732][2587481-edge->5924864],v[5924864]] ==>[user:v[1],degree:1090] ==>[user:v[24],degree:890] ==>[user:v[65],degree:768] - 协同推荐:
//推荐和ID为1的用户,有共同邻居的用户,并按照共同邻居的个数进行排序。 gremlin> g.V(1).both().aggregate("my_friend").both().has(id, neq(1)).as("ff") .flatMap(__.both().where(within("my_friend")).count()).as("comm_cnt").order().by(desc) .select("ff", "comm_cnt").dedup() ==>[ff:v[591712],comm_cnt:10] ==>[ff:v[60911],comm_cnt:10] ==>[ff:v[4470],comm_cnt:10] ==>[ff:v[47129],comm_cnt:10] ==>[ff:v[1],comm_cnt:10] ==>[ff:v[316284],comm_cnt:10] ==>[ff:v[472652],comm_cnt:9] ==>[ff:v[52057],comm_cnt:9] ==>[ff:v[531386],comm_cnt:9] ...
- k阶邻居:
6、 客户效果
某社交领域互联网公司,图数据规模为点(用户数据)1亿,边(社交关系)16亿,之前通过MySQL存储(32core,256GB),面临MySQL查询性能过低的问题,经常出现查询超时。通过使用图数据库GDB,以用户为节点、用户在线状态为属性,好友关系为边构建社交图谱,查询性能提升超过100倍,从超时提升到毫秒级。