offline.py
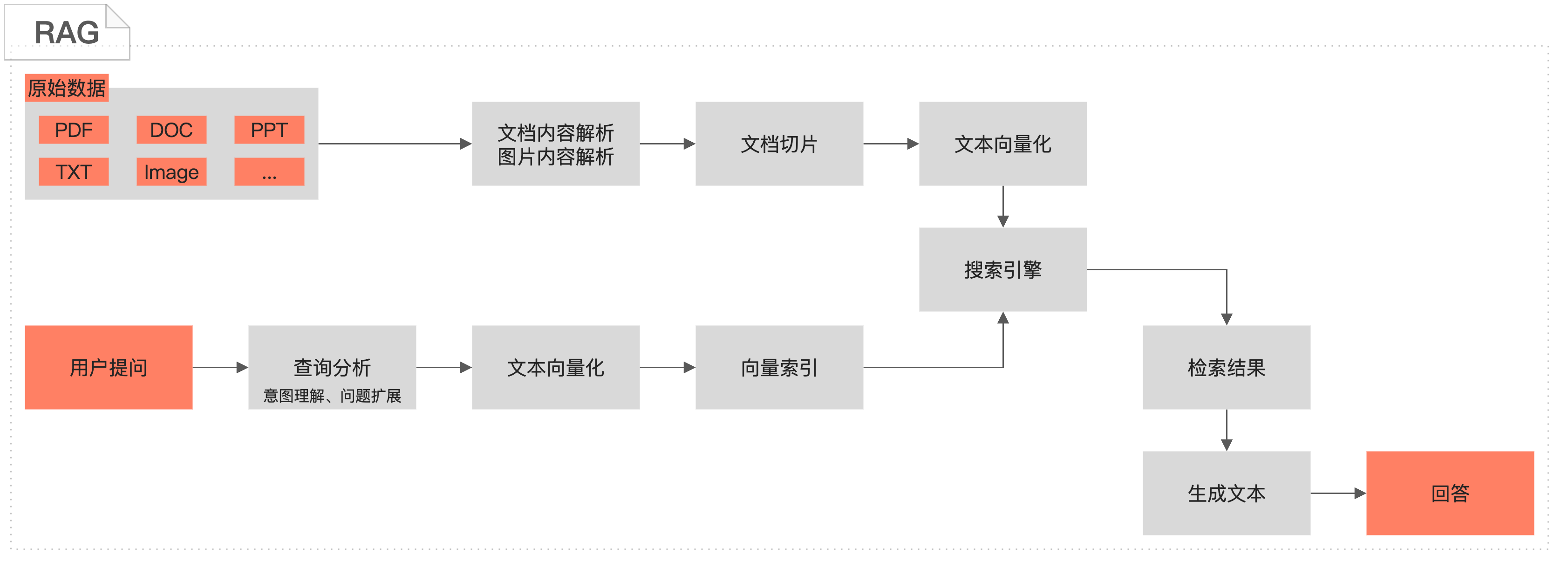
# RAG离线链路-ElasticSearch引擎
# 环境需求:
# Python版本:3.7及以上
# ES集群版本:8.9及以上:如果是阿里云ES需要提前开通并设置访问ip白名单 https://help.aliyun.com/zh/es/user-guide/configure-a-public-or-private-ip-address-whitelist-for-an-elasticsearch-cluster
# 包需求:
# pip install alibabacloud_searchplat20240529
# pip install elasticsearch
# AI搜索开放平台配置
aisearch_endpoint = "xxx.platform-cn-shanghai.opensearch.aliyuncs.com"
api_key = "OS-xxx"
workspace_name = "default"
service_id_config = {"extract": "ops-document-analyze-001",
"split": "ops-document-split-001",
"text_embedding": "ops-text-embedding-001",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"image_analyze": "ops-image-analyze-ocr-001"}
# ES配置
es_host = 'http://es-cn-xxx.public.elasticsearch.aliyuncs.com:9200'
es_auth = ('elastic', 'xxx')
# 输入文档url,示例文档为AI搜索开放平台产品说明文档
document_url = "https://help.aliyun.com/zh/open-search/search-platform/product-overview/introduction-to-search-platform?spm=a2c4g.11186623.0.0.7ab93526WDzQ8z"
import asyncio
from typing import List
from elasticsearch import AsyncElasticsearch
from elasticsearch import helpers
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import GetDocumentSplitRequest, CreateDocumentAnalyzeTaskRequest, \
CreateDocumentAnalyzeTaskRequestDocument, GetDocumentAnalyzeTaskStatusRequest, \
GetDocumentSplitRequestDocument, GetTextEmbeddingRequest, GetTextEmbeddingResponseBodyResultEmbeddings, \
GetTextSparseEmbeddingRequest, GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings, \
CreateImageAnalyzeTaskRequestDocument, CreateImageAnalyzeTaskRequest, CreateImageAnalyzeTaskResponse, \
GetImageAnalyzeTaskStatusRequest, GetImageAnalyzeTaskStatusResponse
async def poll_task_result(ops_client, task_id, service_id, interval=5):
while True:
request = GetDocumentAnalyzeTaskStatusRequest(task_id=task_id)
response = await ops_client.get_document_analyze_task_status_async(workspace_name, service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(interval)
elif status == "SUCCESS":
return response
else:
raise Exception("document analyze task failed")
def is_analyzable_url(url:str):
if not url:
return False
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.tiff'}
return url.lower().endswith(tuple(image_extensions))
async def image_analyze(ops_client, url):
try:
print("image analyze :" + url)
if url.startswith("//"):
url = "https:" + url
if not is_analyzable_url(url):
print(url + " is not analyzable.")
return url
image_analyze_service_id = service_id_config["image_analyze"]
document = CreateImageAnalyzeTaskRequestDocument(
url=url,
)
request = CreateImageAnalyzeTaskRequest(document=document)
response: CreateImageAnalyzeTaskResponse = ops_client.create_image_analyze_task(workspace_name, image_analyze_service_id, request)
task_id = response.body.result.task_id
while True:
request = GetImageAnalyzeTaskStatusRequest(task_id=task_id)
response: GetImageAnalyzeTaskStatusResponse = ops_client.get_image_analyze_task_status(workspace_name, image_analyze_service_id, request)
status = response.body.result.status
if status == "PENDING":
await asyncio.sleep(5)
elif status == "SUCCESS":
return url + response.body.result.data.content
else:
print("image analyze error: " + response.body.result.error)
return url
except Exception as e:
print(f"image analyze Exception : {e}")
def chunk_list(lst, chunk_size):
for i in range(0, len(lst), chunk_size):
yield lst[i:i + chunk_size]
async def write_to_es(doc_list):
es = AsyncElasticsearch(
[es_host],
basic_auth=es_auth,
verify_certs=False, # 不使用SSL证书校验
request_timeout=30,
max_retries=10,
retry_on_timeout=True
)
index_name = 'dense_vertex_index'
# 删除已有索引
if await es.indices.exists(index=index_name):
await es.indices.delete(index=index_name)
# 创建向量索引, 指定embedding字段为dense_vector, content字段为text, source字段为keyword
index_mappings = {
"mappings": {
"properties": {
"emb": {
"type": "dense_vector",
"index": True,
"similarity": "cosine",
"dims": 1536 # 根据embedding模型输出维度修改
},
"content": {
"type": "text"
},
"source_doc": {
"type": "keyword"
}
}
}
}
await es.indices.create(index=index_name, body=index_mappings)
# 上传embedding结果到上一步创建好的索引
actions = []
for i, doc in enumerate(doc_list):
action = {
"_index": index_name,
"_id": doc['id'],
"_source": {
"emb": doc['embedding'],
"content": doc['content'],
"source_doc": document_url
}
}
actions.append(action)
try:
await helpers.async_bulk(es, actions)
except Exception as e:
for error in e.errors:
print(error)
# 确认上传成功
await asyncio.sleep(2)
query = {
"query": {
"ids": {
"values": [doc_list[0]["id"]]
}
}
}
res = await es.search(index=index_name, body=query)
if len(res['hits']['hits']) > 0:
print("ES write success")
await es.close()
async def document_pipeline_execute(document_url: str = None, document_base64: str = None, file_name: str = None):
# 生成opensearch开发平台client
config = Config(bearer_token=api_key, endpoint=aisearch_endpoint, protocol="http")
ops_client = Client(config=config)
# Step 1: 文档解析
document_analyze_request = CreateDocumentAnalyzeTaskRequest(
document=CreateDocumentAnalyzeTaskRequestDocument(url=document_url, content=document_base64,
file_name=file_name, file_type='html'))
document_analyze_response = await ops_client.create_document_analyze_task_async(workspace_name=workspace_name,
service_id=service_id_config[
"extract"],
request=document_analyze_request)
print("document-analyze task_id:" + document_analyze_response.body.result.task_id)
extraction_result = await poll_task_result(ops_client, document_analyze_response.body.result.task_id,
service_id_config["extract"])
print("document-analyze done")
document_content = extraction_result.body.result.data.content
content_type = extraction_result.body.result.data.content_type
# Step 2: 文档切片
document_split_request = GetDocumentSplitRequest(
GetDocumentSplitRequestDocument(content=document_content, content_type=content_type))
document_split_result = await ops_client.get_document_split_async(workspace_name, service_id_config["split"],
document_split_request)
print("document-split done, chunks count: " + str(len(document_split_result.body.result.chunks))
+ " rich text count:" + str(len(document_split_result.body.result.rich_texts)))
# Step 3: 文本向量化
# 提取切片结果。图片切片会通过图片解析服务提取出文本内容
doc_list = ([{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in
document_split_result.body.result.chunks]
+ [{"id": chunk.meta.get("id"), "content": chunk.content} for chunk in
document_split_result.body.result.rich_texts if chunk.meta.get("type") != "image"]
+ [{"id": chunk.meta.get("id"), "content": await image_analyze(ops_client, chunk.content)} for chunk in
document_split_result.body.result.rich_texts if chunk.meta.get("type") == "image"]
)
chunk_size = 32 # 一次最多允许计算32个embedding
all_text_embeddings: List[GetTextEmbeddingResponseBodyResultEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_embedding_async(workspace_name, service_id_config["text_embedding"],
GetTextEmbeddingRequest(chunk))
all_text_embeddings.extend(response.body.result.embeddings)
all_text_sparse_embeddings: List[GetTextSparseEmbeddingResponseBodyResultSparseEmbeddings] = []
for chunk in chunk_list([text["content"] for text in doc_list], chunk_size):
response = await ops_client.get_text_sparse_embedding_async(workspace_name,
service_id_config["text_sparse_embedding"],
GetTextSparseEmbeddingRequest(chunk,
input_type="document",
return_token=True))
all_text_sparse_embeddings.extend(response.body.result.sparse_embeddings)
for i in range(len(doc_list)):
doc_list[i]["embedding"] = all_text_embeddings[i].embedding
doc_list[i]["sparse_embedding"] = all_text_sparse_embeddings[i].embedding
print("text-embedding done")
# Step 4: 写入ElasticSearch存储引擎
await write_to_es(doc_list)
if __name__ == "__main__":
# 运行异步任务
# import nest_asyncio # 如果在Jupyter notebook中运行,反注释这两行
# nest_asyncio.apply() # 如果在Jupyter notebook中运行,反注释这两行
asyncio.run(document_pipeline_execute(document_url))
# asyncio.run(document_pipeline_execute(document_base64="eHh4eHh4eHg...", file_name="attention.pdf")) #另外一种调用方式
online.py
# RAG在线链路-ElasticSearch引擎
# 环境需求:
# Python版本:3.7及以上
# ES集群版本:8.9以上(如果是阿里云ES 需要提前开通并设置访问ip白名单 https://help.aliyun.com/zh/es/user-guide/configure-a-public-or-private-ip-address-whitelist-for-an-elasticsearch-cluster)
# 包需求:
# pip install alibabacloud_searchplat20240529
# pip install elasticsearch
# OpenSearch搜索开发工作台配置
api_key = "OS-xxx"
aisearch_endpoint = "xxx.platform-cn-shanghai.opensearch.aliyuncs.com"
workspace_name = "default"
service_id_config = {
"rank": "ops-bge-reranker-larger",
"text_embedding": "ops-text-embedding-001",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"llm": "ops-qwen-turbo",
"query_analyze": "ops-query-analyze-001"
}
# ES配置
es_host = 'http://es-cn-xxx.public.elasticsearch.aliyuncs.com:9200'
es_auth = ('elastic', 'xxx')
# 用户query:
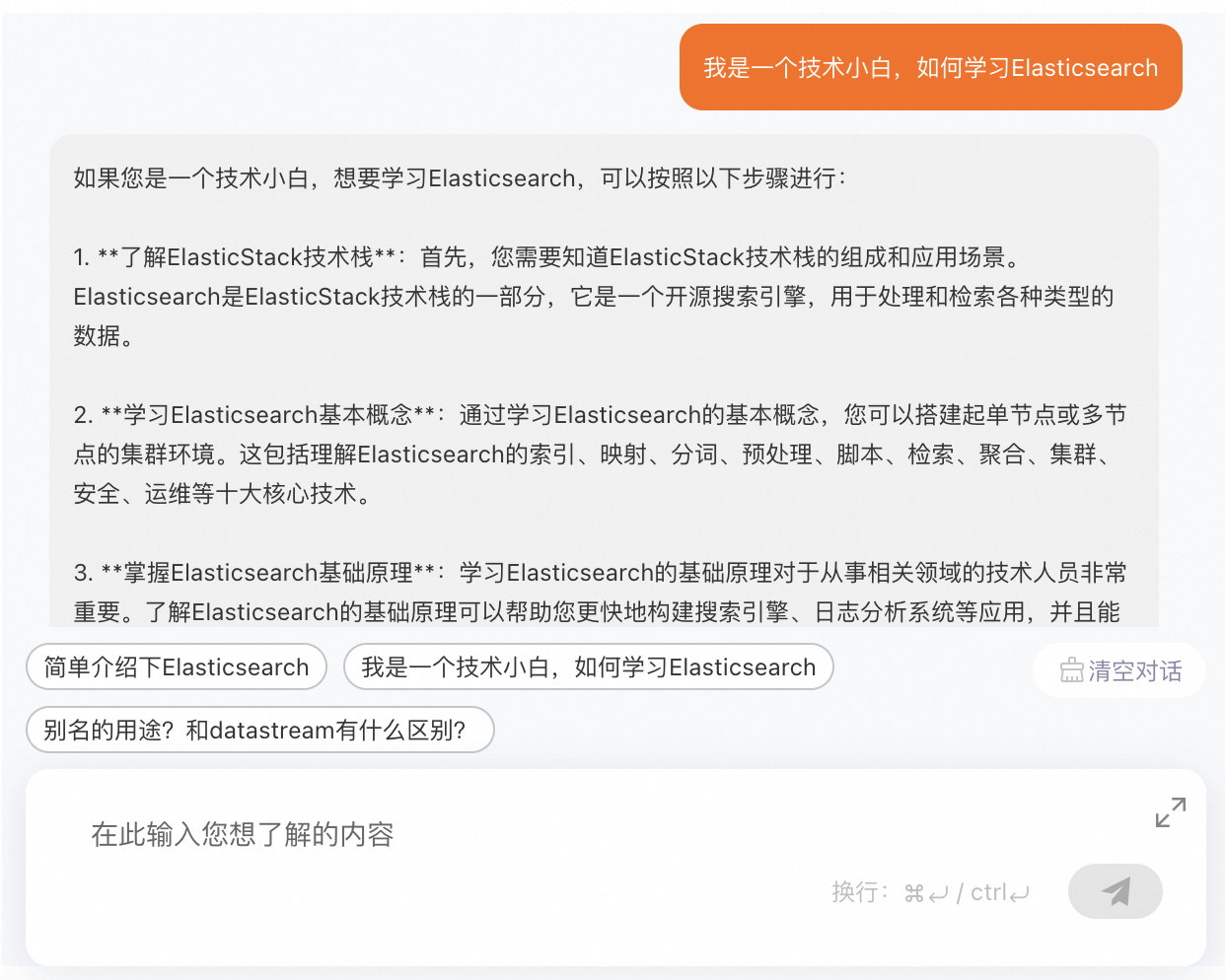
user_query = "OpenSearch搜索开发平台可以做什么?"
import asyncio
from elasticsearch import AsyncElasticsearch
from alibabacloud_tea_openapi.models import Config
from alibabacloud_searchplat20240529.client import Client
from alibabacloud_searchplat20240529.models import GetTextEmbeddingRequest, \
GetDocumentRankRequest, GetTextGenerationRequest, GetTextGenerationRequestMessages, \
GetQueryAnalysisRequest
# 生成opensearch开发平台client
config = Config(bearer_token=api_key, endpoint=aisearch_endpoint, protocol="http")
ops_client = Client(config=config)
async def es_retrieve(query):
es = AsyncElasticsearch(
[es_host],
basic_auth=es_auth,
verify_certs=False,
request_timeout=30,
max_retries=10,
retry_on_timeout=True
)
index_name = 'dense_vertex_index'
# query向量化
query_emb_result = await ops_client.get_text_embedding_async(workspace_name, service_id_config["text_embedding"],
GetTextEmbeddingRequest(input=[query],
input_type="query"))
query_emb = query_emb_result.body.result.embeddings[0].embedding
query = {
"field": "emb",
"query_vector": query_emb,
"k": 5, # 返回文档切片数量
"num_candidates": 100 # HNSW搜索参数efsearch
}
res = await es.search(index=index_name, knn=query)
search_results = [item['_source']['content'] for item in res['hits']['hits']]
await es.close()
return search_results
# 在线问答流水线,输入是用户问题
async def query_pipeline_execute():
# Step 1: query分析
query_analyze_response = ops_client.get_query_analysis(workspace_name, service_id_config['query_analyze'],
GetQueryAnalysisRequest(query=user_query))
print("query analysis rewrite result:" + query_analyze_response.body.result.query)
# Step 2: 召回文档
all_query_results = []
user_query_results = await es_retrieve(user_query)
all_query_results.extend(user_query_results)
rewrite_query_results = await es_retrieve(query_analyze_response.body.result.query)
all_query_results.extend(rewrite_query_results)
for extend_query in query_analyze_response.body.result.queries:
extend_query_result = await es_retrieve(extend_query)
all_query_results.extend(extend_query_result)
# 对所有召回结果进行去重
remove_duplicate_results = list(set(all_query_results))
# Step 3: 对召回文档进行重排序
rerank_top_k = 8
score_results = await ops_client.get_document_rank_async(workspace_name, service_id_config["rank"],GetDocumentRankRequest(remove_duplicate_results, user_query))
rerank_results = [remove_duplicate_results[item.index] for item in score_results.body.result.scores[:rerank_top_k]]
# Step 4: 调用大模型回答问题
docs = '\n'.join([f"<article>{s}</article>" for s in rerank_results])
messages = [
GetTextGenerationRequestMessages(role="system", content="You are a helpful assistant."),
GetTextGenerationRequestMessages(role="user",
content=f"""已知信息包含多个独立文档,每个文档在<article>和</article>之间,已知信息如下:\n'''{docs}'''
\n\n根据上述已知信息,详细且有条理地回答用户的问题。确保答案充分回答了问题并且正确使用了已知信息。如果信息不足以回答问题,请说“根据已知信息无法回答该问题”。
不要使用不在已知信息中的内容生成答案,确保答案中每一个陈述在上述已知信息中有相应内容支撑。答案请使用中文。
\n问题是:'''{user_query}'''""""")
]
response = await ops_client.get_text_generation_async(workspace_name, service_id_config["llm"],
GetTextGenerationRequest(messages=messages))
print("大模型最终回答: ", response.body.result.text)
if __name__ == "__main__":
# import nest_asyncio # 如果在Jupyter notebook中运行,反注释这两行
# nest_asyncio.apply() # 如果在Jupyter notebook中运行,反注释这两行
asyncio.run(query_pipeline_execute())