
本文详细介绍了如何将数据湖构建(DLF)作为数据源,将多模态向量数据同步至阿里云OpenSearch的完整流程。文档重点展示了OpenSearch强大的多模态数据处理能力,支持从DLF中自动提取文本、图片和视频数据,通过内置模型或AI搜索开放平台进行向量化处理和内容解析,将非结构化数据转换为结构化向量并同步至OpenSearch。该方案支持Paimon、Lance和Object Table等多种数据格式,提供全面的向量索引配置选项,包括向量维度、距离类型和检索算法设置,使用户能够高效构建多模态检索应用,满足图片搜索、文本语义搜索和视频搜索等场景需求。
前置条件
了解数据湖构建。
已配置数据湖构建数据目录ID、数据库和数据表,将在配置数据同步中使用。
添加数据湖(DLF)数据源
在实例详情>表管理页,点击添加表:
填写表的基础信息,点击下一步:
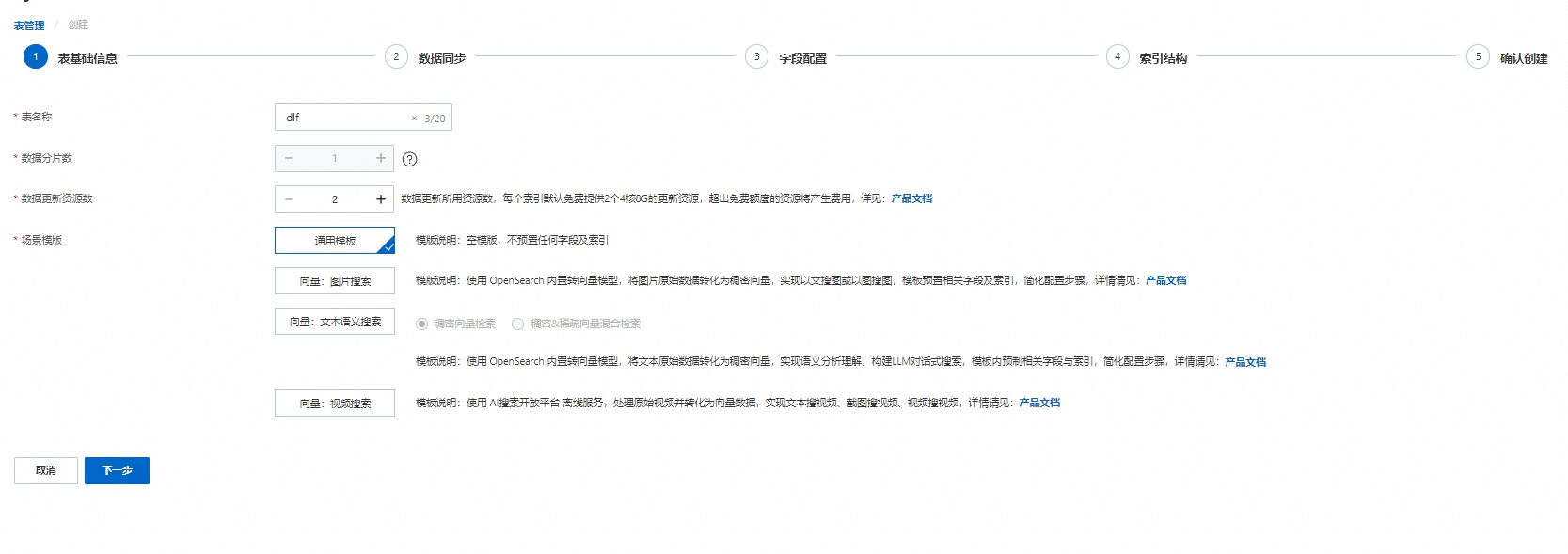 配置说明:
配置说明:
表名称:可自定义。
数据分片数:分片数设置时,各索引表分片数需保持一致;或至少一个索引表分片数为1,其余索引表分片数一致。
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版计费概述
场景模板:向量检索版内置了4种模板可供用户选择:通用模板、向量:图片搜索、向量:文本语义模板、向量:视频搜索(该模板暂不支持数据湖作为全量数据来源)。
数据同步,配置数据源,校验通过后,点击下一步:
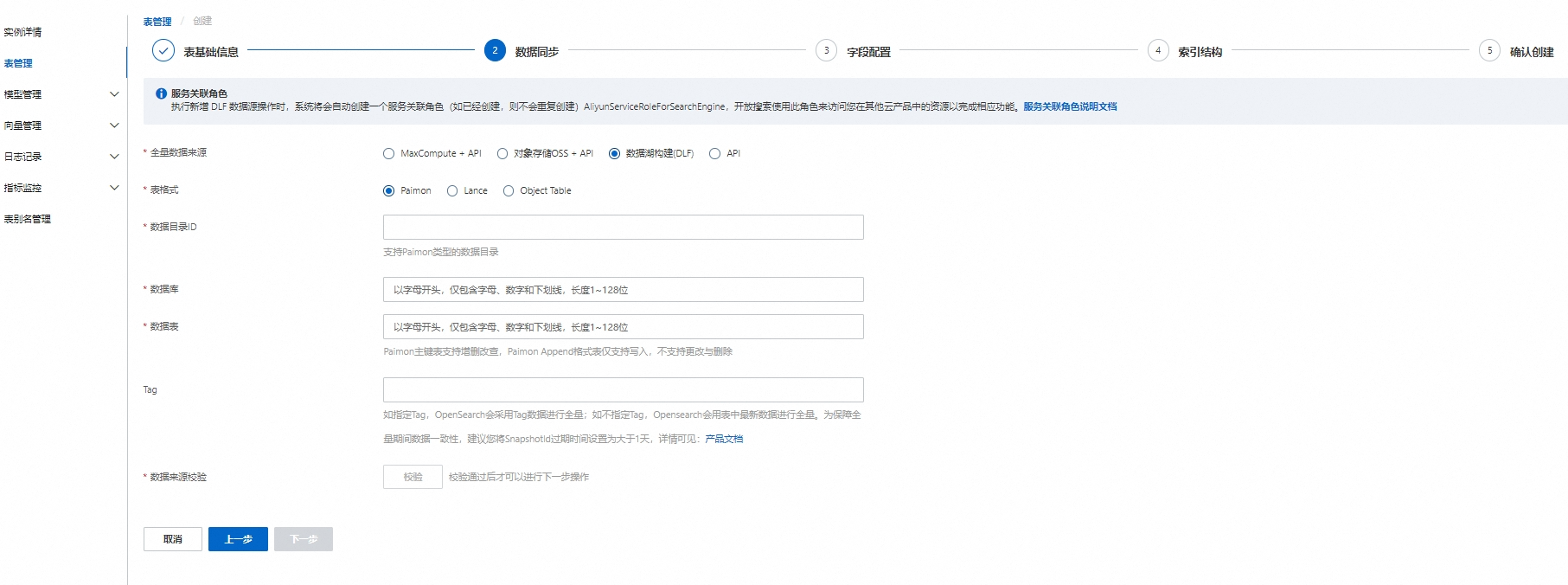
全量数据来源:选择数据湖构建(DLF)。
表格式:支持Paimon、Lance和Object Table。
Paimon是一种湖仓表,能像数据库一样实时更新数据,并同时支持流处理和批处理。
Lance是一种向量表,专为AI设计,能对向量进行超高速的相似性搜索。
Object Table是一种元数据表,能让您用SQL直接查询和定位存储在云端的各类文件。
数据目录:访问的目标数据湖构建的数据目录ID。
数据库:访问的目标数据目录下的数据库。
数据表:访问的目标数据库下的数据表。
说明存量实例选择数据湖构建(DLF)类型需升级引擎版本后使用。
通用模板与向量:图片搜索模板支持Pamion、Lance与Object Table表格式。向量:文本语义搜索模板支持Paimon类型数据目录。
Paimon主键表支持增删改查,Paimon Append格式表仅支持写入,不支持更改与删除。
相对路径:表格式为Object Table时访问对象表中文件的相对路径。
数据格式:表格式为Object Table时需选择数据为ha3或json数据格式。
Tag:数据版本标签,指定Tag后OpenSearch会采用Tag数据进行全量,不指定Tag,OpenSearch会用表中最新数据进行全量。
Paimon提供Tag标签功能用于保留特定快照的元数据和数据文件,防止因快照过期导致历史数据丢失。标签可基于写入任务自动创建,支持按处理时间或水印时间定期生成,也可手动创建、删除或回滚到指定标签。通过配置保留策略,可控制标签的最大数量或保留时长,确保历史数据可查询。详情请参见Paimon标签。
Lance使用Tag标签功能标记数据集历史中的特定版本便于追踪数据集演变,尤其适用于频繁更新的机器学习流程。用户可对标签执行创建、更新。删除和列出操作。标签不会生成新版本,而是作为独立目录中的元数据存在。带有标签的版本不会被“cleanup_old_versions”清理,需先删除标签方可移除对应版本。详情请参见Lance标签。
数据来源校验:校验通过后可进行下一步操作。
字段配置,配置完成后,点击下一步:
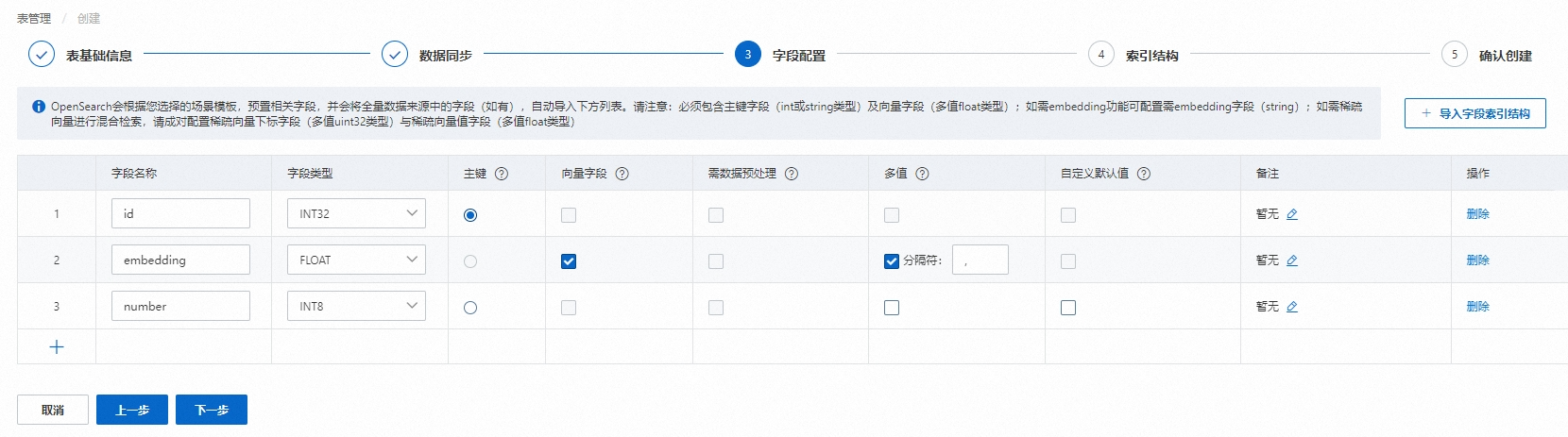
必选字段有:主键字段和向量字段,主键字段为int或string类型并且需要勾选主键按钮,向量字段为float类型并且需要勾选向量字段按钮。
向量字段默认为多值的float类型。
需数据预处理:支持String类型的字段,勾选后点击去配置 可调用模型对该字段进行数据预处理。
文本数据类型
图片数据类型
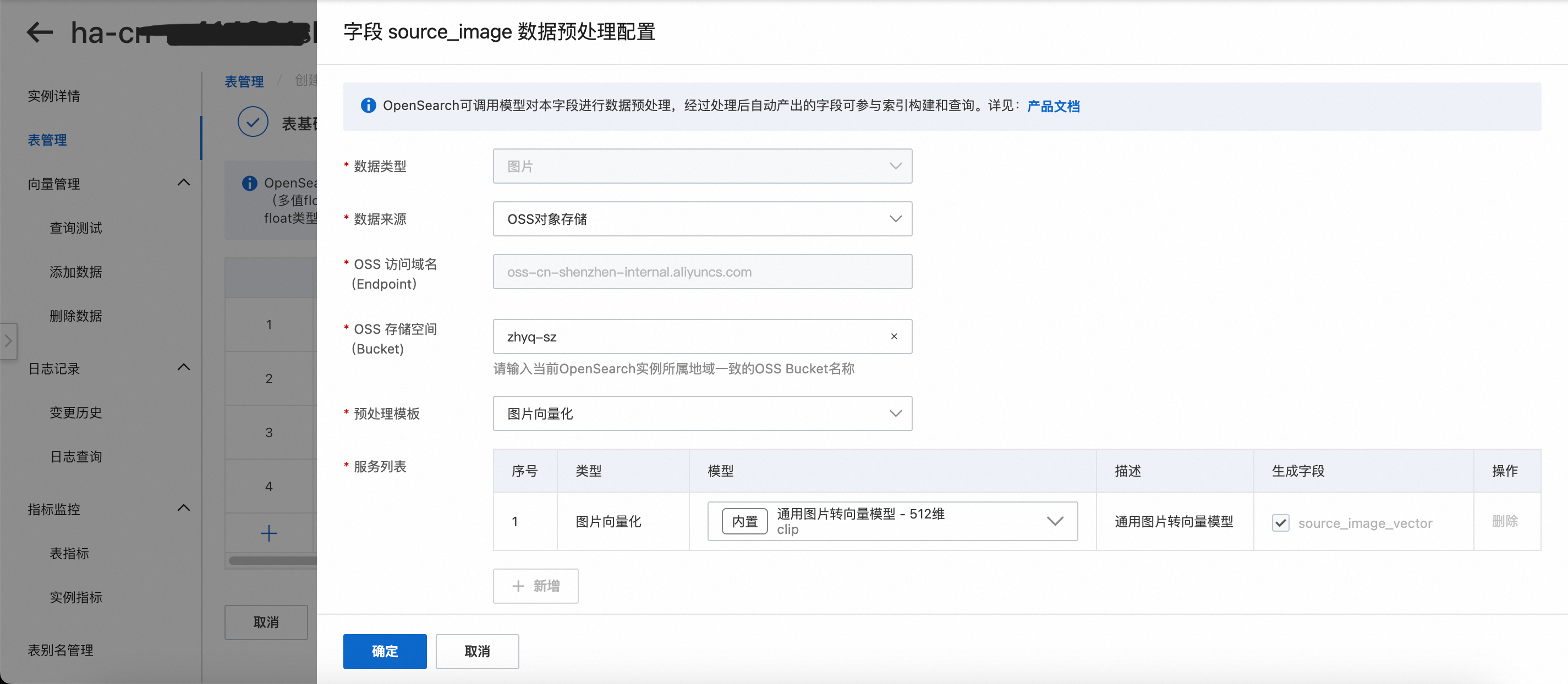
数据类型:图片。
数据来源:OSS对象存储、Base64编码和DLF-Object Table。
OSS对象存储:需要填写OSS路径,其实就是将图片存放在OSS的文件夹里面,从OSS直接导入。
Base64编码:相当于需要先将图片进行一次编码,然后存储在数据库中,或者直接用API方式进行传输。
DLF-Object Table:数据湖Object表格式的表,需填写对应的数据目录、数据库、数据表。
预处理模板:图片向量化、图片内容解析、图片内容解析+图片向量化。
服务列表:
选定预处理模板后,自动出现模板下的服务列表,展示该模板下所用到的模型种类。
可选的模型来源:
视频数据类型
当数据中缺少字段或字段为空时,系统将自动补充默认值,数字类型默认补0,STRING类型默认补空字符串,支持自定义默认值。
索引结构配置,配置完成后,点击下一步:
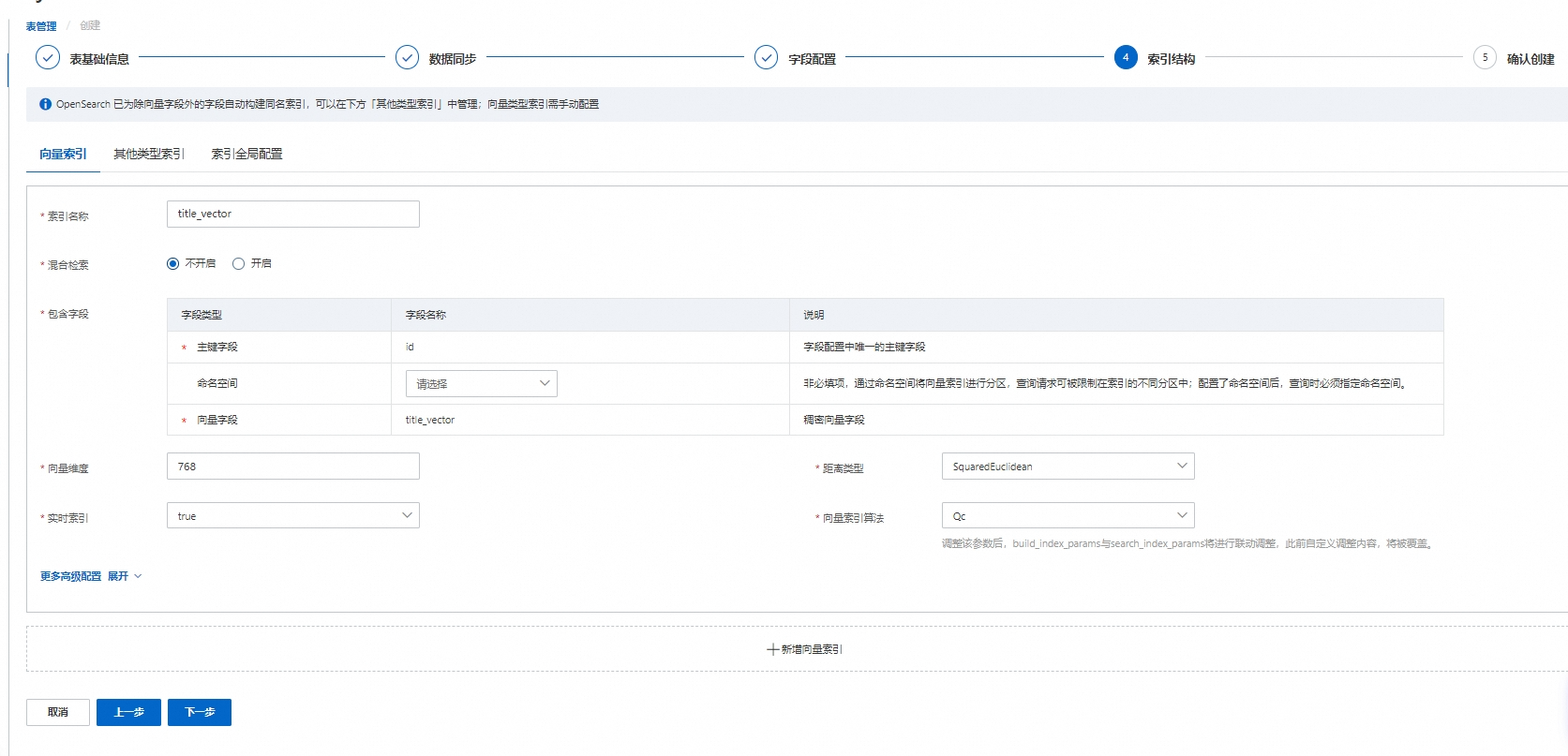
向量索引:
其他类型索引:系统生成的pk字段、生成主键索引,其余非向量类型的字段默认生成同名索引。
索引全局配置:可以设置文档过期自动清理,开启后,当前时间-文档时间 > 过期时间时,该文档将被自动清理。
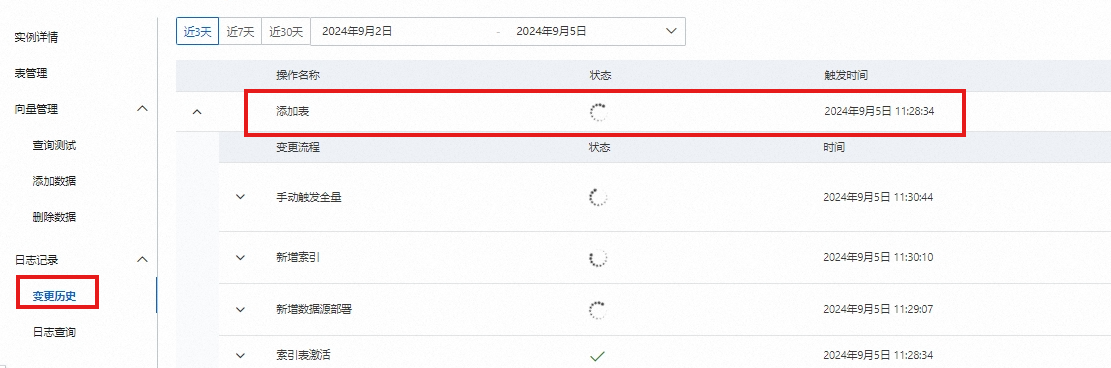
确认创建,点击确认创建后,系统将自动创建配置好的表,可在变更历史中查看创建表进度:

当表状态在使用中时,即可在查询测试页面进行查询测试。

注意事项
DLF的Paimon表有新数据写入时,OpenSearch会基于新数据自动触发实时索引构建,如果通过API手动写入数据,可能引起数据一致性问题,请谨慎操作。