
背景介绍
多主体识别介绍:
图像搜索的多主体识别是指在图像搜索任务中,系统能够识别并理解图像中存在的多个主体(物体、人物、场景等)。多主体识别技术使得搜索引擎不仅能够找到包含单一物体的图像,还能够识别和检索出包含多个相关物体的复杂图像。
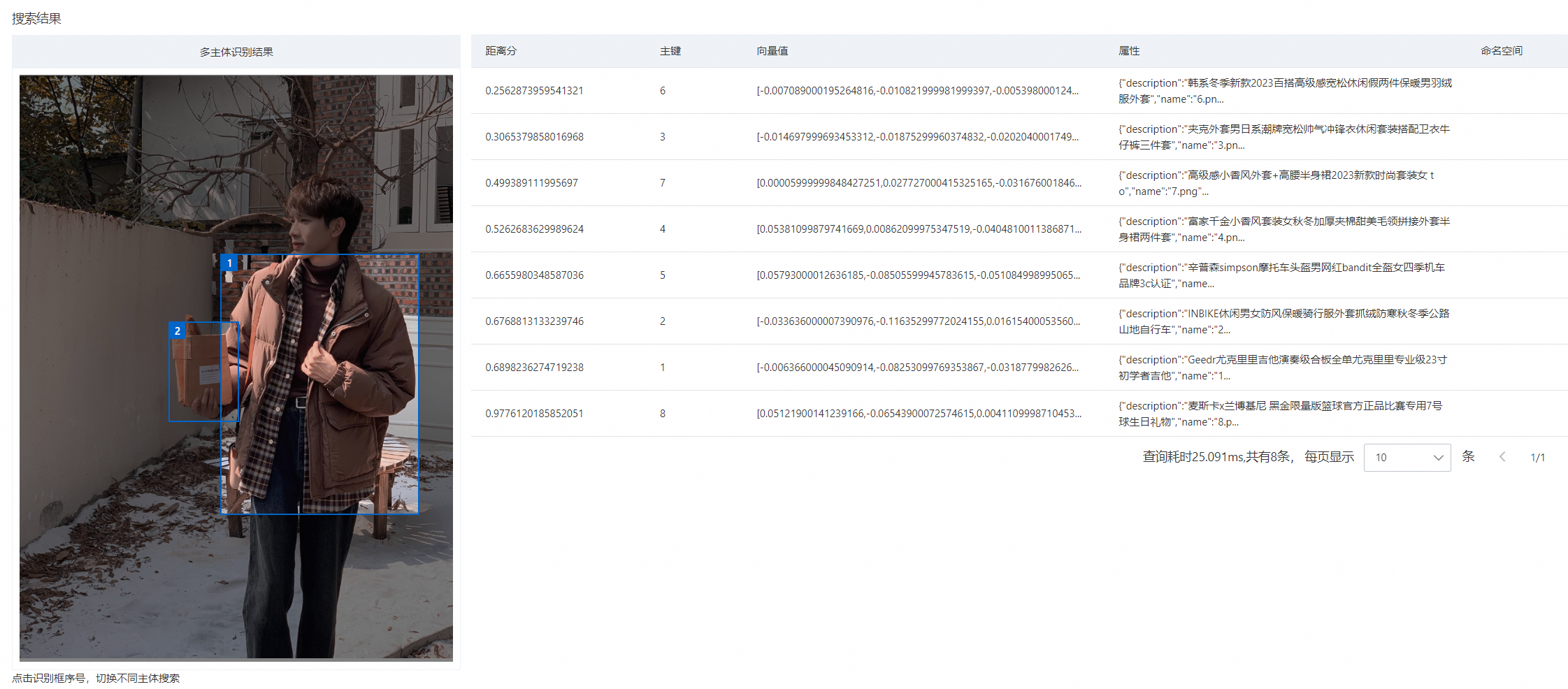
在实际应用中,这意味着当用户对某一图像进行搜索时,搜索引擎可以通过分析图像的视觉内容,判断出图像中所有显著的元素,并将这些信息用于搜索匹配。例如下图,头盔、骑行服、自行车、骑行手套都是该图片中的主体,向量检索版启用了多主体识别可以同时识别这些元素,并根据用户的查询提供相关的搜索结果。

多主体识别对于提高图像搜索的准确性和相关性非常重要,尤其是在复杂的搜索场景中,用户希望根据多个不同特征找到相关图像时。通过识别图像中的多个主体,搜索引擎可以更好地理解用户的搜索意图,并提供更精确的结果。
向量检索版的主体识别:
向量检索版的主体识别通过两个参数进行控制:
crop:在图片搜索过程中是否需要对上传图片进行主体识别
主体识别方式(range):range表示主体在图片中的区域,四个数分别表示主体区域左上角点的(x, y)坐标,宽度width,高度height
由系统自动进行主体识别,以识别的主体进行搜索,主体识别结果可以在Response中获取
自定义主体区域:可自定义主体识别区域。格式为x1,y1,x2,y2,四个数分别表示主体区域左上角点的(x, y)坐标,宽度width,高度height。若不设置自定义主体区域,则以识别出最大的主体进行搜索。
配置实例
详细的配置步骤,可参考《端到端图搜解决方案》中的环境准备、购买实例、配置实例几个步骤。
效果测试
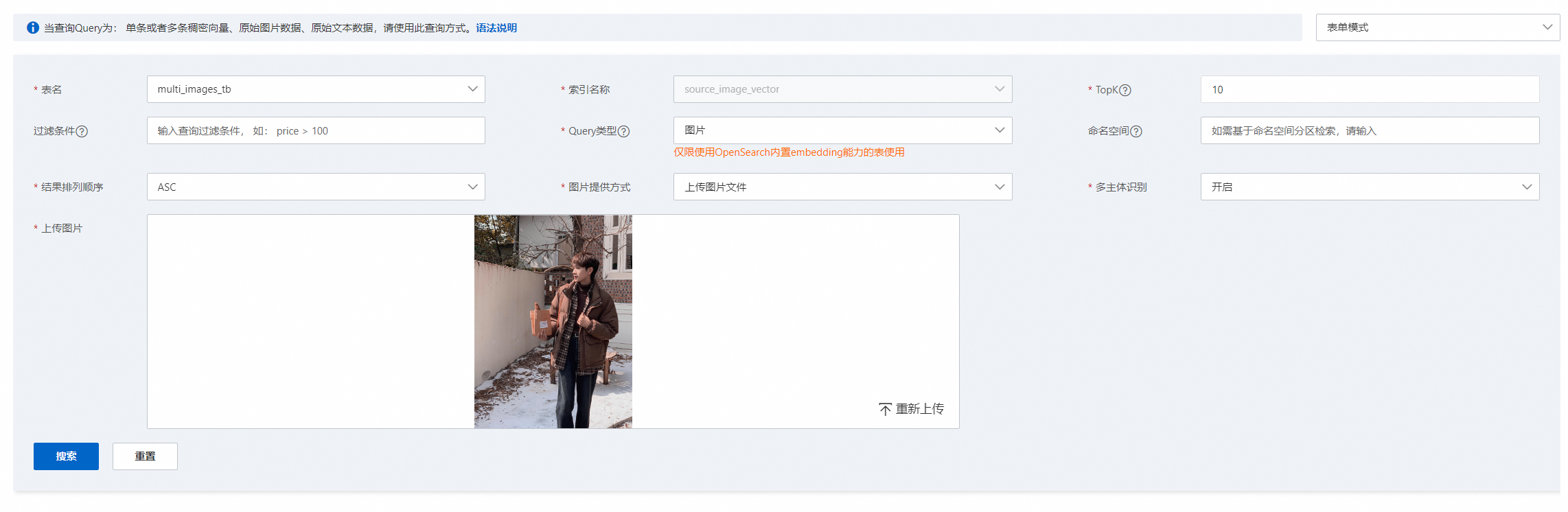
在控制台中的查询测试页里,选择表名、query类型选择图片,图片提供方式选择上传图片文件,开启多主体识别:
可在搜索结果中查看,主体识别的结果:
语法说明
SDK中使用多主体识别
该文章对您有帮助吗?