混合检索将语义检索与关键词检索相结合,能够有效地支持文本数据的检索,从而实现更好的搜索效果。
背景介绍
OpenSearch-向量检索版的混合搜索
在向量检索版中,您可以使用稀疏-稠密向量进行混合检索。对比传统的文本+向量多路召回,向量检索版中的稀疏-稠密向量是将稠密向量和稀疏向量嵌入组合为单个向量,而其中的稀疏向量是将文本向量化成稀疏向量,稠密向量是传统的向量。稀疏向量和稠密向量代表不同类型的信息并支持不同类型的搜索。
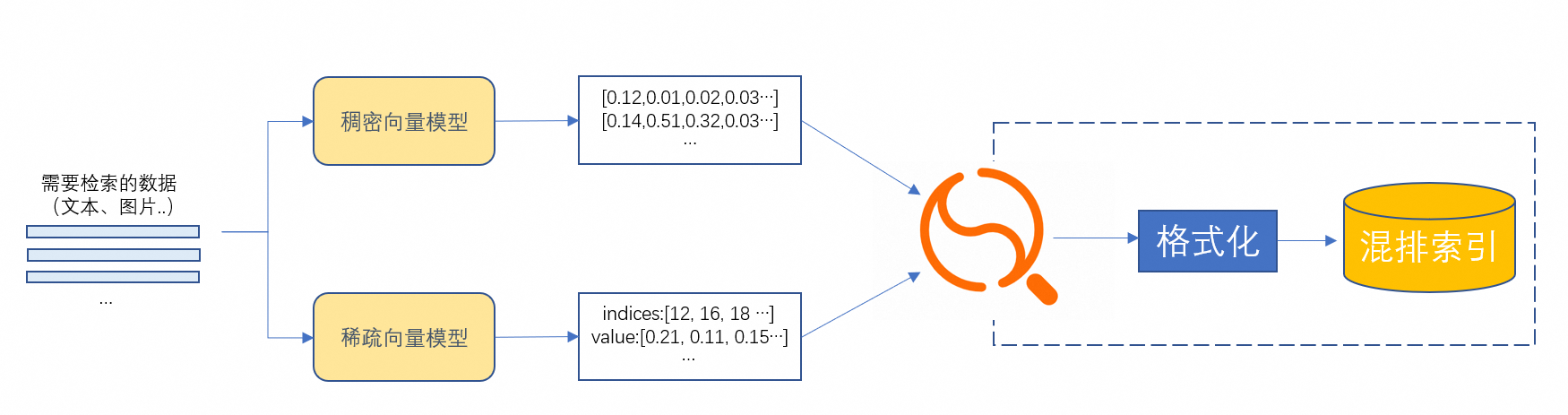
通过OpenSearch-向量检索版进行混合搜索的步骤如下:
通过外部的稠密向量模型生成稠密向量
通过外部的稀疏向量模型生成稀疏向量
购买OpenSearch-向量检索版实例,并配置稀疏-稠密向量索引
将稠密向量和稀疏向量更新到OpenSearch-向量检索版实例的索引中
使用稀疏-稠密向量索引搜索
OpenSearch-向量检索版实例返回相应搜索到的数据
稠密向量(Dense vectors)
向量检索版中基本的向量类型是稠密向量,稠密向量使得语义搜索成为可能,语义搜索根据特定的距离度量返回最相似的结果,即使没有完全匹配的项也可以。传统的文本搜索是将query和doc内容根据一定的分词规则进行分词,在检索时对query分词后的term与doc分词后的term进行匹配,只有完全匹配时query才能将doc进行召回,而语义搜索则没有文本搜索的限制,只要语义相近通过向量就能将其召回。
稀疏向量(Sparse vectors)
稀疏向量具有非常大的维度数,其中只有很小一部分的值为非零。当用于关键词搜索时,每个稀疏向量表示一个文档;维度表示来自字典的单词,值表示这些单词在文档中的重要性。关键字搜索算法根据关键字匹配的数量、频率和其他因素来计算文本文档的相关性。
稀疏向量的表示:
V=[0,0,0,0,2,0,4,0,0,0]
对于向量V,其稀疏表示为(10,[4,6],[2,4])
10代表V的长度,[4,6] 表示非零元素的下标,[2,4]表示非零元素的值。
通过稀疏模型将文本向量化,比如某文本内容稀疏向量化之后:
{
"indices": [0, 100, 40, 50, 20],
"values": [0.5, 0.9, 0.3, 0.7, 0.6]
}向量检索版将稀疏向量下标和值用独立的两个多值字段表示,两个字段个数需要相等,位置一一对应。
其中indices表示稀疏向量下标(向量数组中有值的位置下标);
values表示稀疏向量。
在数据写入和查询时要求下标值按从小到大排序,值做相应的调整,最终表示为:
{
"indices": [0, 20, 40, 50, 100],
"values": [0.5, 0.6, 0.3, 0.7, 0.9]
}您可以通过以下脚本生成稀疏向量:(稠密向量需要通过其他向量模型生成)
ha3_vector_sparse_encoder20240308
也可以直接下载已经生成好的测试数据:
其中:pk(主键)、content(文本内容)、dense_vector(1536维的稠密向量)、subscript(稀疏向量下标) 、sparse_vector(稀疏向量)。
查询权重
混合查询时,相同文档的最终分数是将稠密向量的距离和稀疏向量的距离加和,如果需要给稀疏向量和稠密向量不同的权重,可以做如下处理:
{
"vector": [v * weight for v in dense_vector],
"sparseData": {
"indices": sparse_data["indices"],
"values": [v * (1 - weight) for v in sparse_data["values"]]
}
}购买OS向量检索版实例
购买实例可参考购买OpenSearch向量检索版实例。
配置实例
新购买的实例在其详情页中显示状态为“待配置”,系统将自动部署一个与所购查询节点和数据节点的个数及规格一致的引擎,之后需要依次配置表基础信息、数据同步、字段配置以及索引结构,等待索引重建完成即可正常搜索。
1. 表基础信息
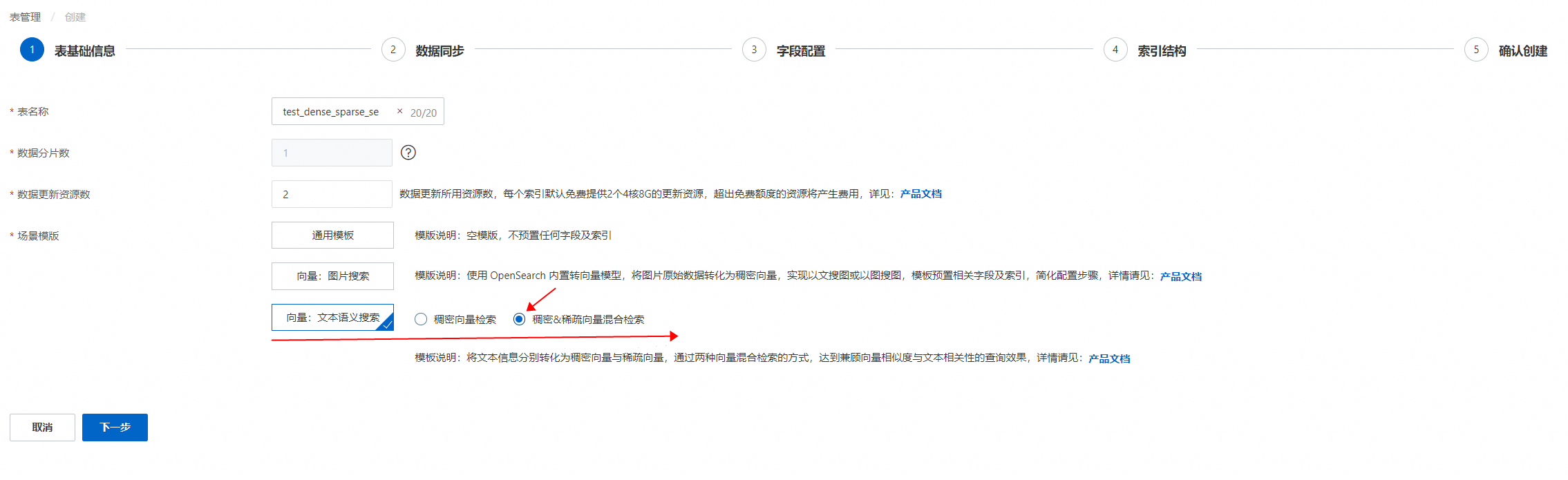
表管理点击“表添加",输入表名称,设置数据分片数和数据更新资源数,场景模板选择:向量:文本语义搜索,并选择稠密&稀疏向量混合检索:
配置说明:
表名称:可自定义。
数据分片数:分片数设置时,请填写不超过256的正整数, 用于提升全量构建速度、单次查询性能。(部分存量实例,仍需各索引表分片数保持一致;或至少一个索引表分片数为1,其余索引表分片数一致)
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版计费概述
2. 数据同步
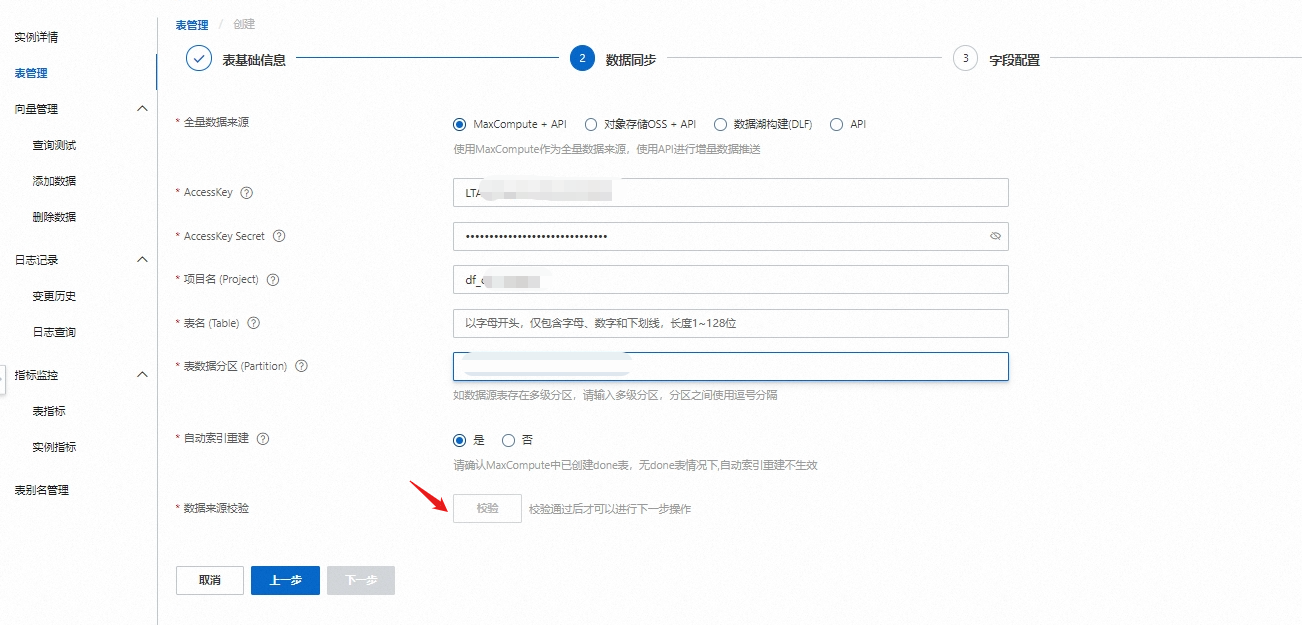
选择全量数据来源(目前支持的数据源有MaxCompute+API、对象存储OSS+API、数据湖构建(DLF)和API数据源),本文以MaxCompute+API为例,依次设置AccessKey、AccessKey Secret、Project、Table、Partition,按需选择是否开启自动索引重建,设置完成后在数据来源校验点击校验,通过后才可以进行下一步操作。
3. 字段配置
稠密&稀疏向量混合检索场景需要配置如下字段:主键(id)、稠密向量(dense_vector)、稀疏向量(sparse_vector_values)、稀疏向量下标数组(sparse_vector_indices):
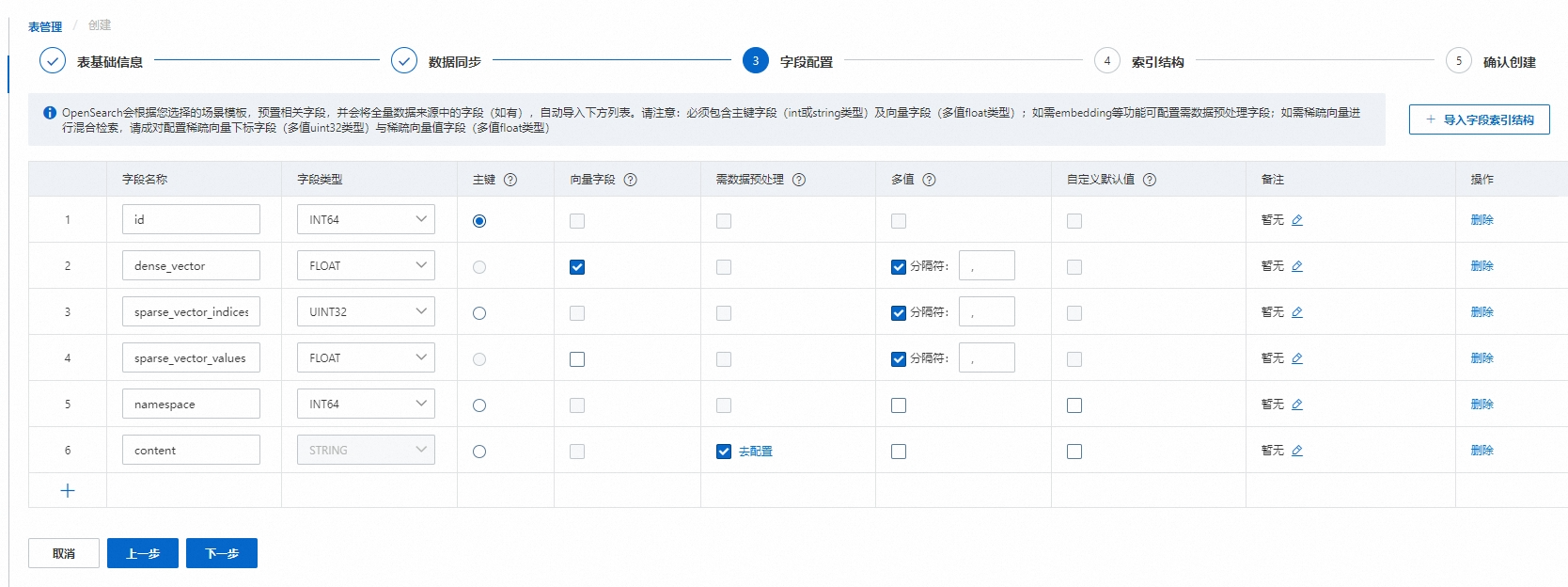
字段配置说明:
必选字段:主键字段和向量字段,主键字段为INT或STRING类型并且需要勾选主键按钮,向量字段为float类型并且需要勾选向量字段按钮;
向量字段为必选字段,可多选,该字段为向量数据,校验字段类型为多值FLOAT。
稀疏向量进行混合检索,请成对配置稀疏向量下标字段(多值UINT32类型)与稀疏向量值字段(多值FLOAT类型)。
使用向量检索,在定义字段时有位置要求,需要按照主键字段、命名空间字段(非必要)、向量字段的顺序创建。(如上图所示)
数据预处理:可对STRING类型的字段做数据预处理,经过处理后自动产出的字段可参与索引构建和查询。详细配置请参考调用AI搜索开放平台模型服务。
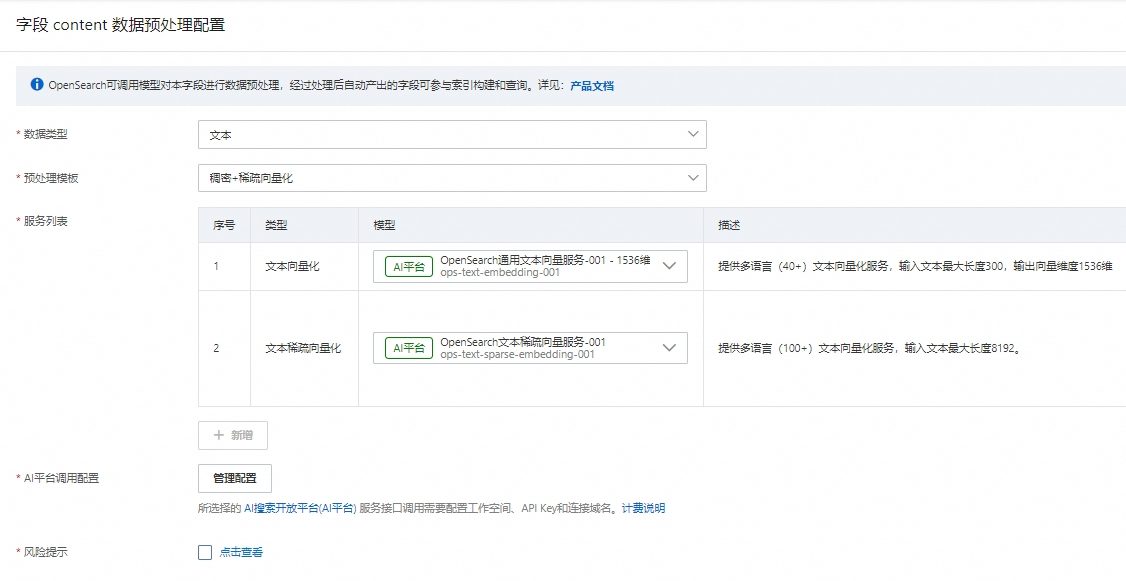
4. 索引结构
配置混合索引,混合索引选择“开启”,包含字段中配置主键、向量字段、稀疏向量下标、稀疏向量值:
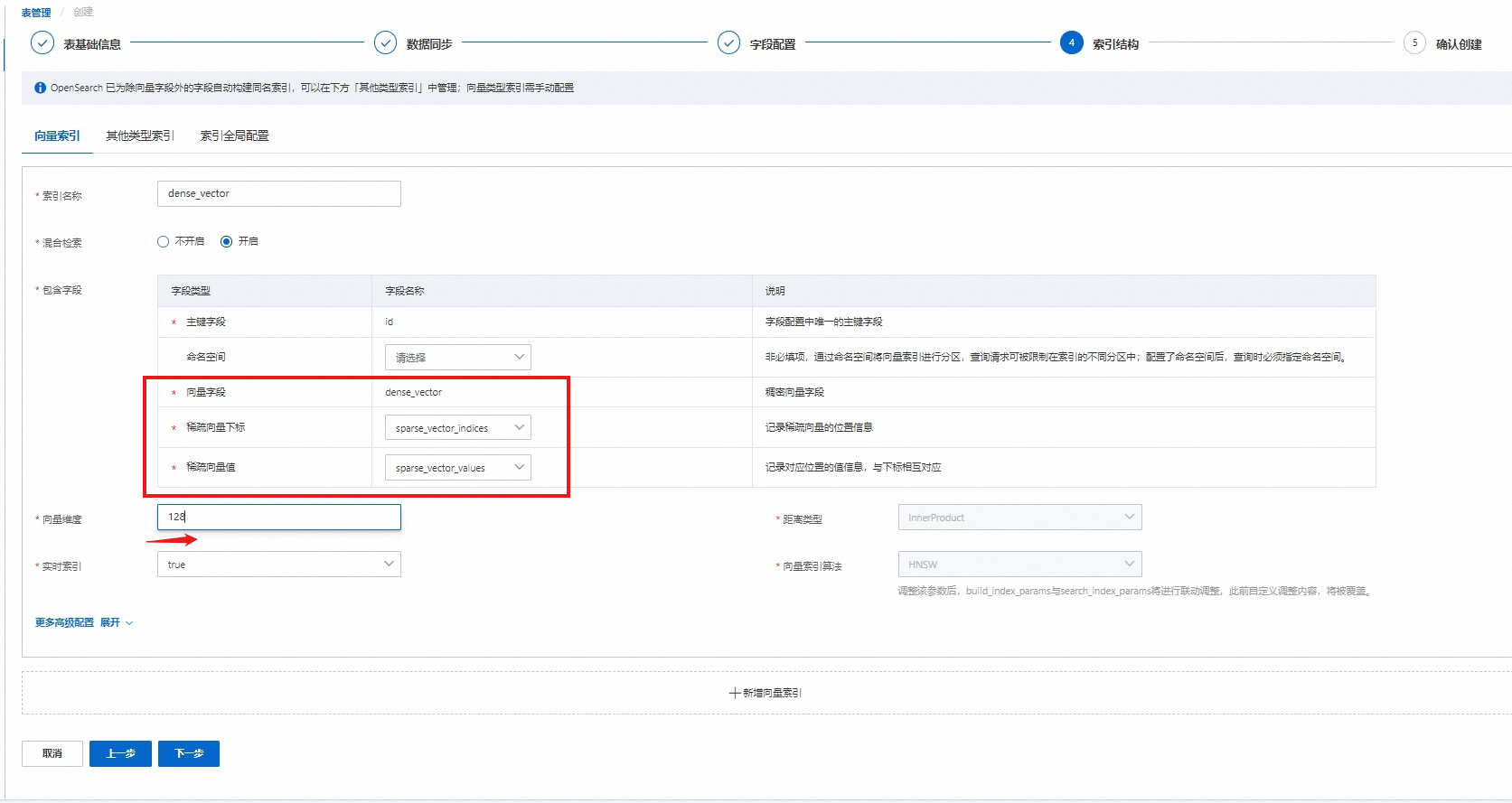
配置说明:
索引名称:必填,可自定义。
混合检索:选择开启.
混合检索开启时:需要再配置稀疏向量下标、稀疏向量值。
向量维度:配置稠密向量维度。
开启混合检索,默认距离类型为InnerProduct,向量索引算法为HNSW,不支持修改。
高级配置,向量索引需要单独配置参数,详情可参考向量索引通用配置。
若使用本文中的测试数据,请将向量维度设置为1536
5. 确认创建
索引配置完成后,点击确认创建。
6. 变更历史
实例管理-变更历史-数据源变更,可以看到创建表及新增索引及索引重建的所有FSM,全部完成之后引擎搭建完成,可以开始查询测试:
7. 查询测试
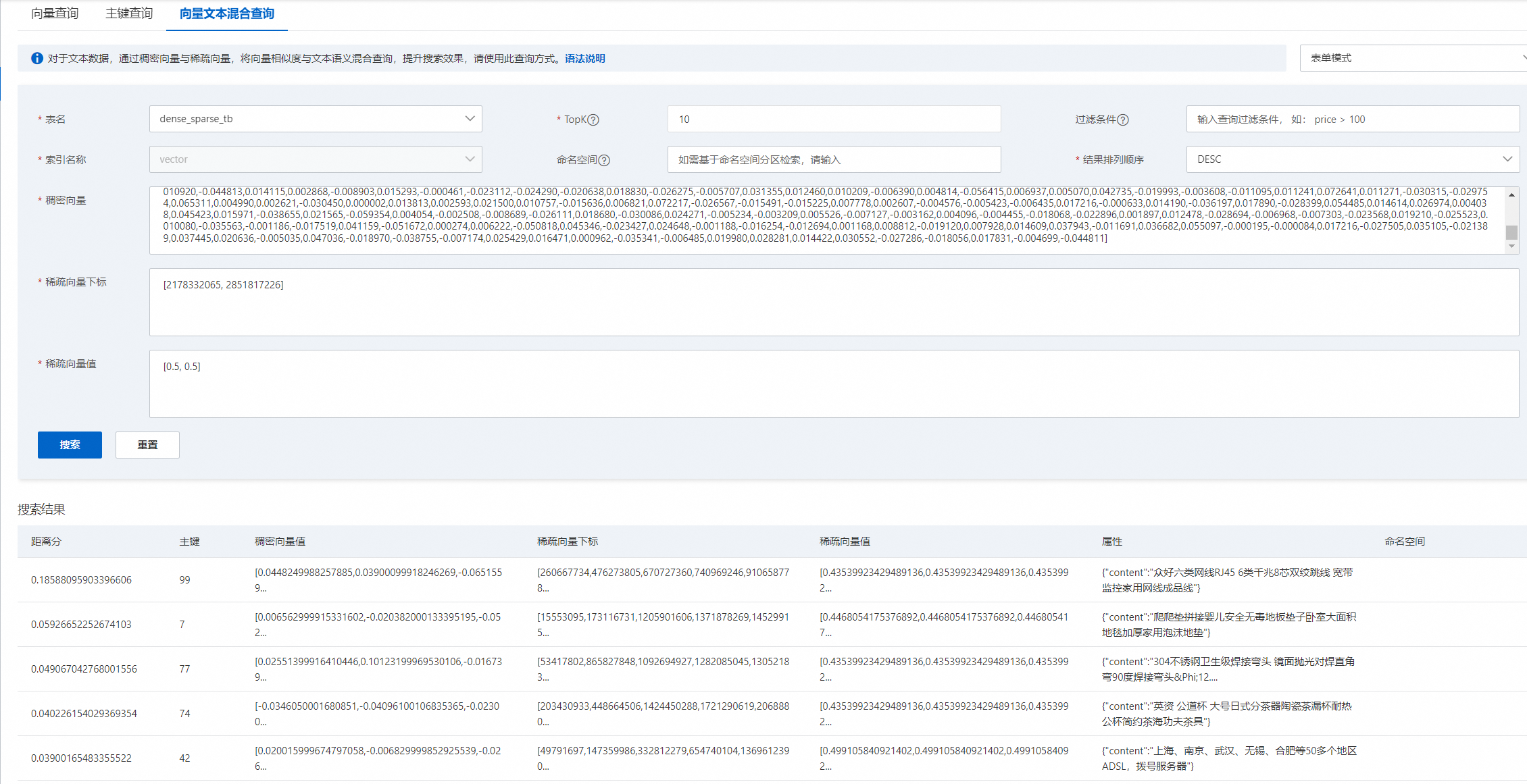
{
"tableName": "dense_sparse_tb",
"indexName": "vector",
"vector": [
0.1,
0.2,
0.3,
0.4,
0.5
],
"sparseData": {
"indices": [
0,
2
],
"values": [
1.2,
2.4
]
},
"topK": 2,
"order": "DESC"
}tableName:表名
indexName:本例中为vector
vector:稠密向量
sparseData:稀疏向量
indices:稀疏向量下标
values:稀疏向量值
topK:取topK个结果
order:排序策略,DESC为倒序
效果演示: