
本文将介绍如何使用AI搜索开放平台模块服务,为OpenSearch向量检索版提供RAG能力,并结合DeepSeek快速构建RAG方案。
技术原理
检索增强生成(RAG)是一种结合检索和生成技术的人工智能方法,旨在提升生成内容的相关性、准确性和多样性。RAG在处理生成任务时,会先从外部数据或知识库中检索与输入最相关的片段,然后将这些片段与原始输入一起输入到大语言模型(LLM)中,引导模型生成更精确和丰富的回答。这种方法使模型在生成响应时,不仅能依赖内部参数和训练数据,还能利用外部最新或特定领域的信息,从而提升回答的准确性。
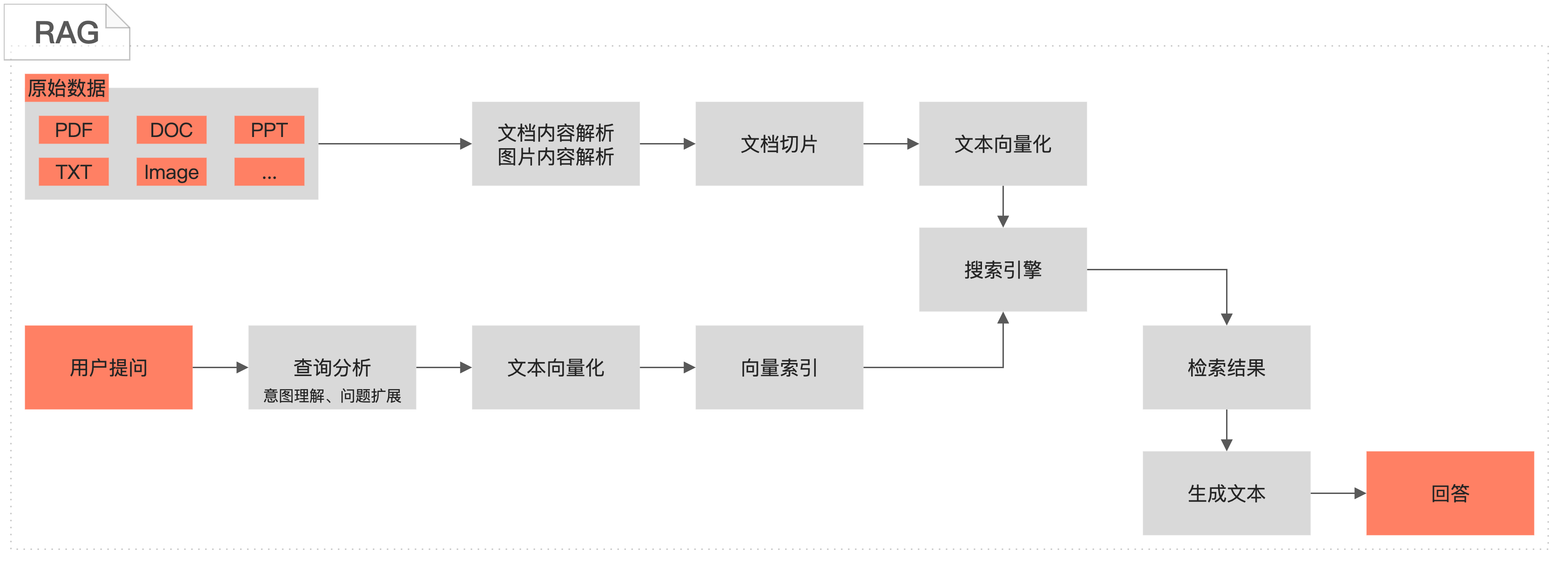
应用场景
-
智能客服:通过从企业知识库中检索相关信息,自动生成精准的回复。
-
对话式搜索:结合用户输入和外部知识库,提供更智能、更自然的交互体验。
-
知识图谱增强:利用外部知识库扩展模型的知识范围,提升问答的深度和广度。
-
个性化推荐:根据用户历史行为和偏好,生成个性化的推荐内容。
方案介绍
产品介绍
-
OpenSearch-向量检索版:OpenSearch-向量检索版是阿里巴巴自主研发的大规模分布式向量检索引擎,支持多种向量检索算法,高精度下性能表现优异,能完成大规模高性价比的索引构建和检索,同时,索引支持水平拓展与合并,支持索引流式构建、即增即查、数据实时动态更新。
-
AI搜索开放平台:AI搜索开放平台围绕智能搜索及RAG场景,将AI搜索链路中用到的算法服务以组件化形式提供,内置文档解析、文档切片、文本向量化、查询分析、召回、排序、效果评估以及LLM模型服务,开发者根据自身情况灵活选择组件服务进行搜索业务开发。
-
DeepSeek:是一款热门的推理模型,能够在少量标注数据的情况下显著提升推理能力,它在数学、代码、自然语言推理等复杂任务上表现出色。
方案步骤
-
服务开通
-
向量检索版实例创建
-
AI搜索开发平台服务开通
-
-
RAG开发链路搭建和测试
-
完成AI搜索开放平台服务选型和代码下载
-
本地环境适配和测试RAG开发链路
-
执行文档处理脚本
-
通过AI搜索开放平台的服务,对业务数据进行处理(包括文档解析、文档切片、向量化)。
-
将处理后的业务数据写入OpenSearch向量检索版存储引擎。
-
-
执行在线问答脚本
-
文本向量化模型对输入的Query进行Query向量化。
-
向量形式的query输入向量检索版,进行文档召回,并对所有召回结果进行去重。
-
将召回去重的结果进行排序打分。
-
通过调用DeepSeek模型服务,对召回结果进行推理总结,返回结果。
-
-
-
前提准备
1.向量检索版实例创建
-
购买“OpenSearch向量检索版实例”。
-
配置向量检索版实例可参考混合查询最佳实践进行向量检索版实例的配置。
-
向量检索版实例是部署在VPC环境中,因此用户在本地或者公网环境是无法直接通过API域名访问VPC环境中的向量检索版实例的,因此系统通过配置IP白名单的方式支持用户在本地或公网环境访问向量检索版实例,详情参见公网白名单配置。
-
公网白名单配置完毕后,预计需要等待1分钟左右就可以生效。
2.AI搜索开放平台服务开通
-
开通“AI搜索开放平台服务”。
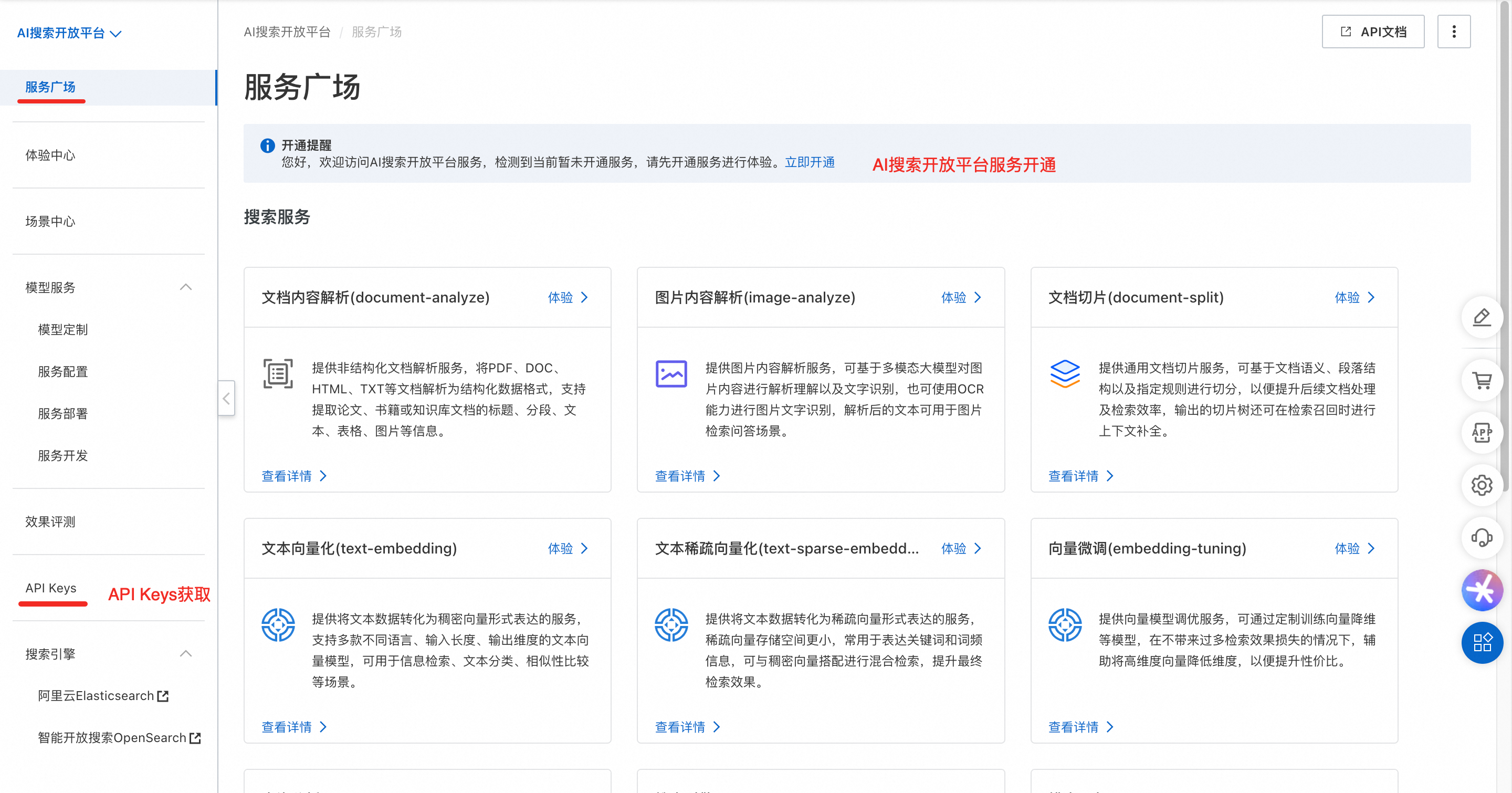
-
目前AI搜索开放平台功能,仅支持在上海区域开通。
-
AI搜索开放平台支持通过公网和VPC地址调用服务,且可通过VPC实现跨地域调用服务,目前支持上海、杭州、深圳、北京、张家口、青岛地域的用户,通过VPC地址调用AI搜索开放平台的服务。
搭建步骤
1.服务选型和代码下载
根据知识库和业务需要,选择RAG链路中需要使用的算法服务以及开发框架。
-
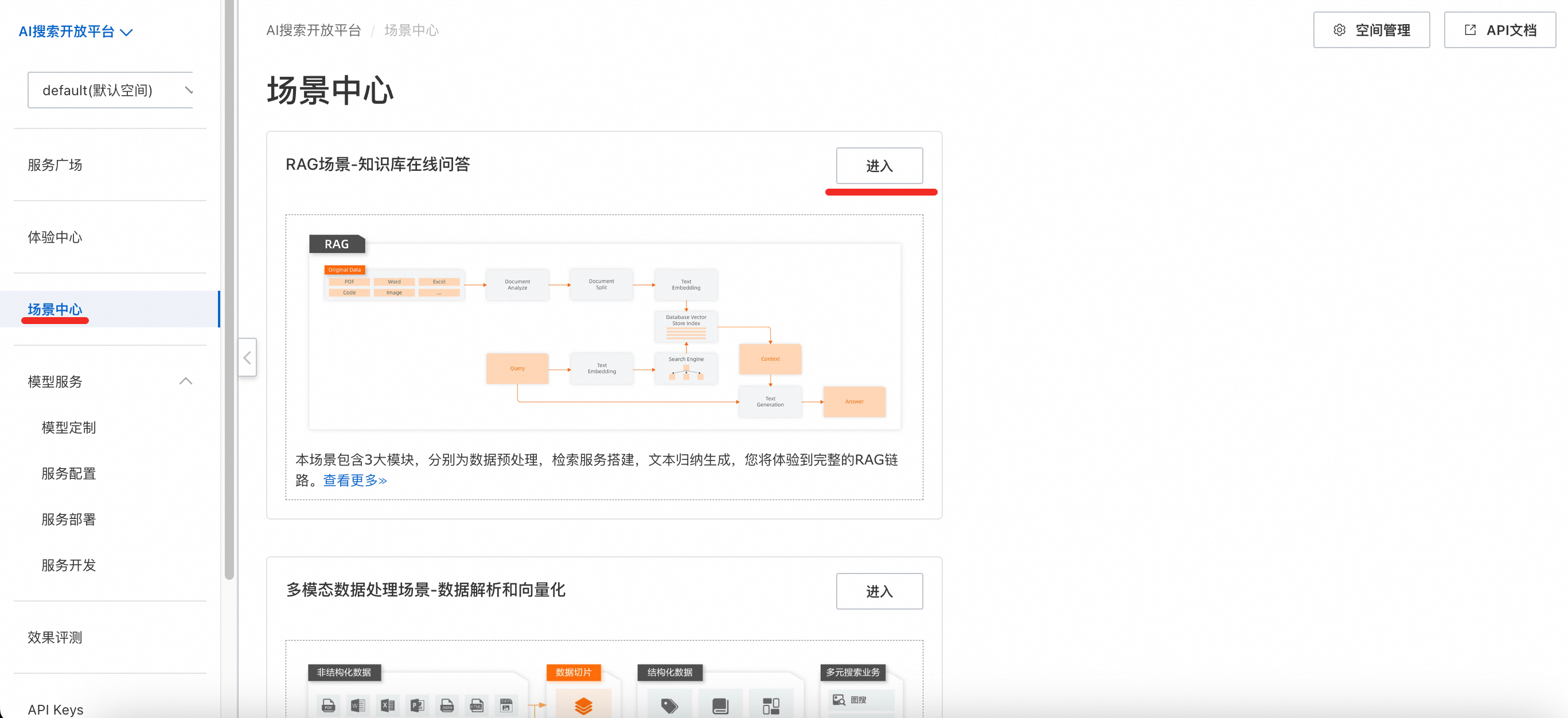
登录AI搜索开放平台控制台。
-
在左侧导航栏选择场景中心,选择RAG场景-知识库在线问答,在右侧点击进入。
-
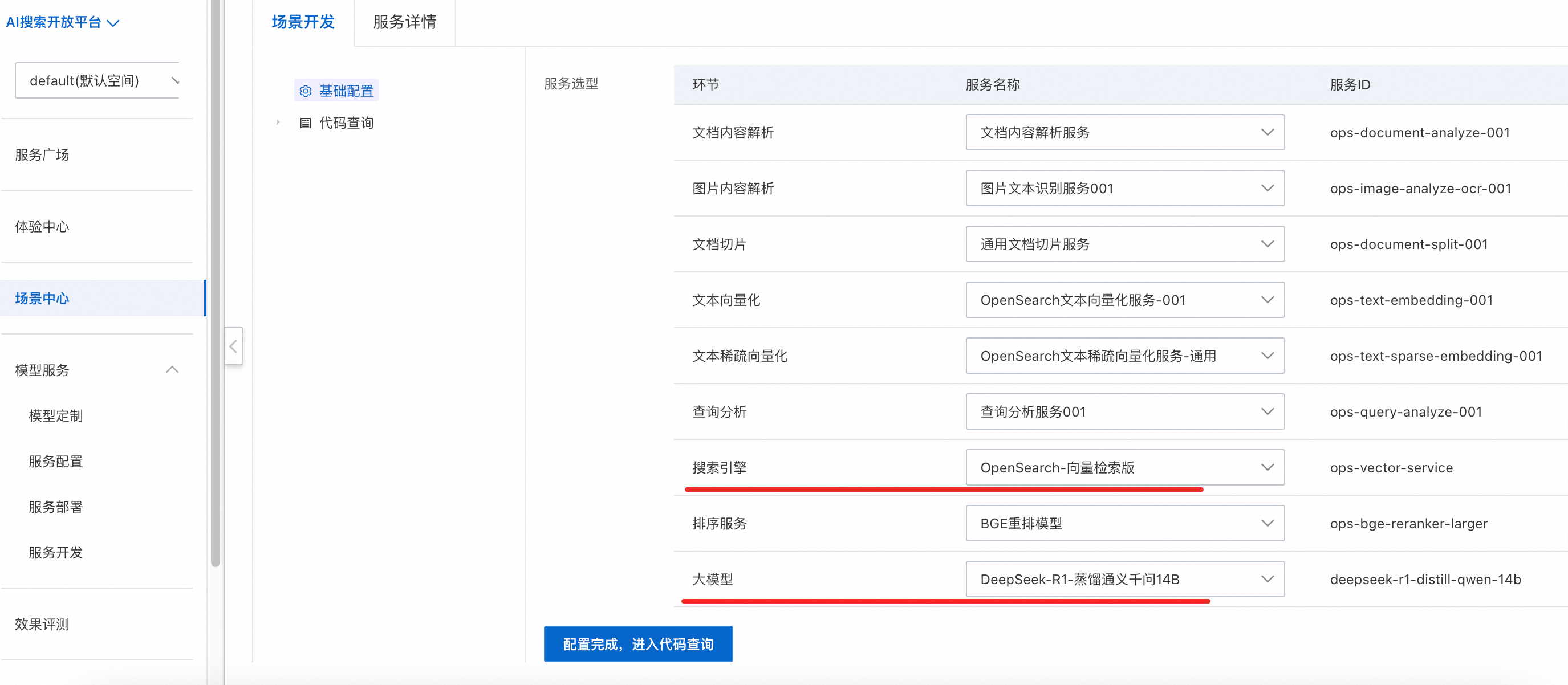
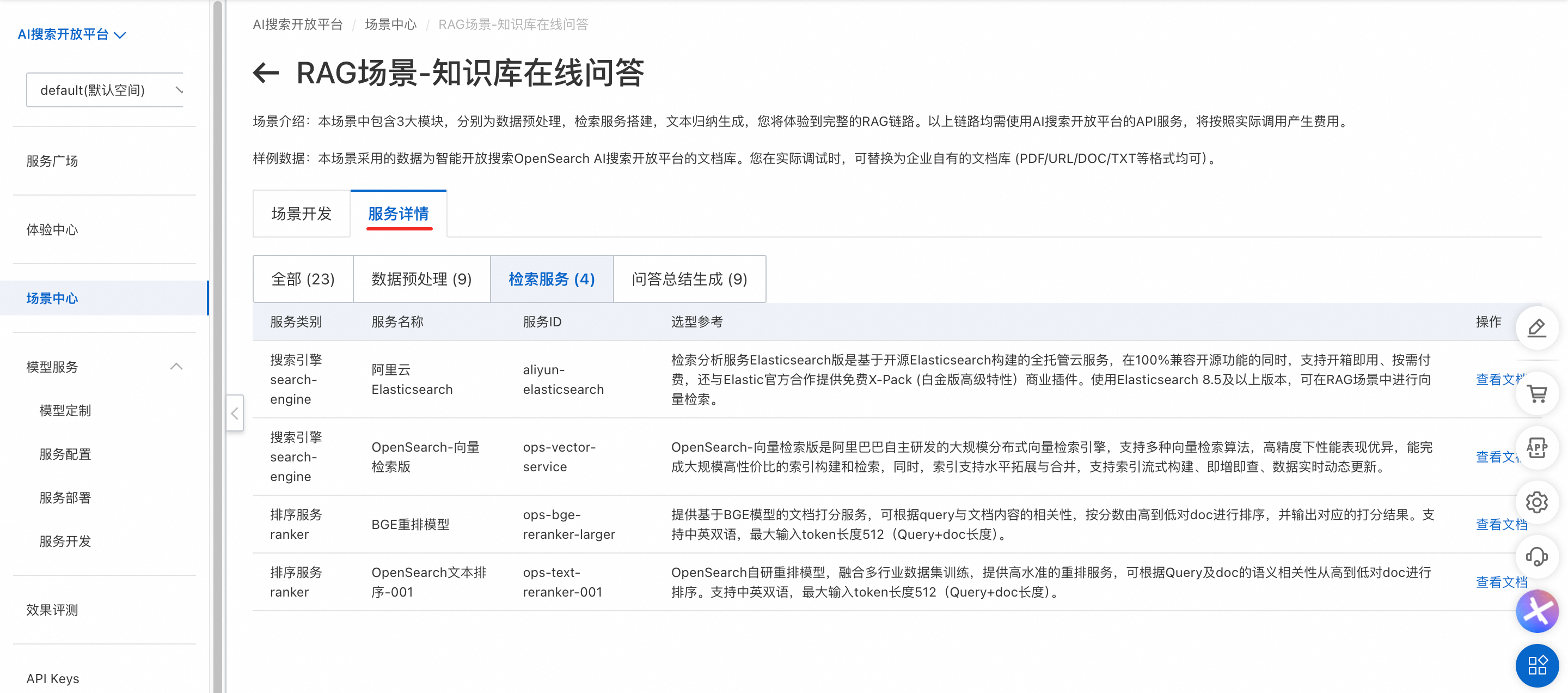
在场景开发页面,可以根据服务信息结合业务特点,在下拉列表中选择所需服务。其中搜索引擎选择OpenSearch-向量检索版,大模型以DeepSeek-R1-蒸馏千问14B为例。
-
服务详情页面可查看服务详细信息。
-
大模型:AI搜索开放平台提供多种⼤语⾔模型服务,包含DeepSeek全系模型(含R1/V3及7B/14B蒸馏版本)、千问系列QwQ、千问-Turbo、千问-Plus、千问-Max⼤模型,满足不同场景的需求。
-
完成服务选型后,单击配置完成,进入代码查询,就可以得到完整的脚本代码。
-
按照应用调用RAG链路时的运行流程,代码分为文档处理流程和在线问答流程两部分。

-
先选好开发架构,再分别点击代码查询下的文档处理流程和在线问答流程,进行复制代码或下载文件,将代码保存到本地。
-
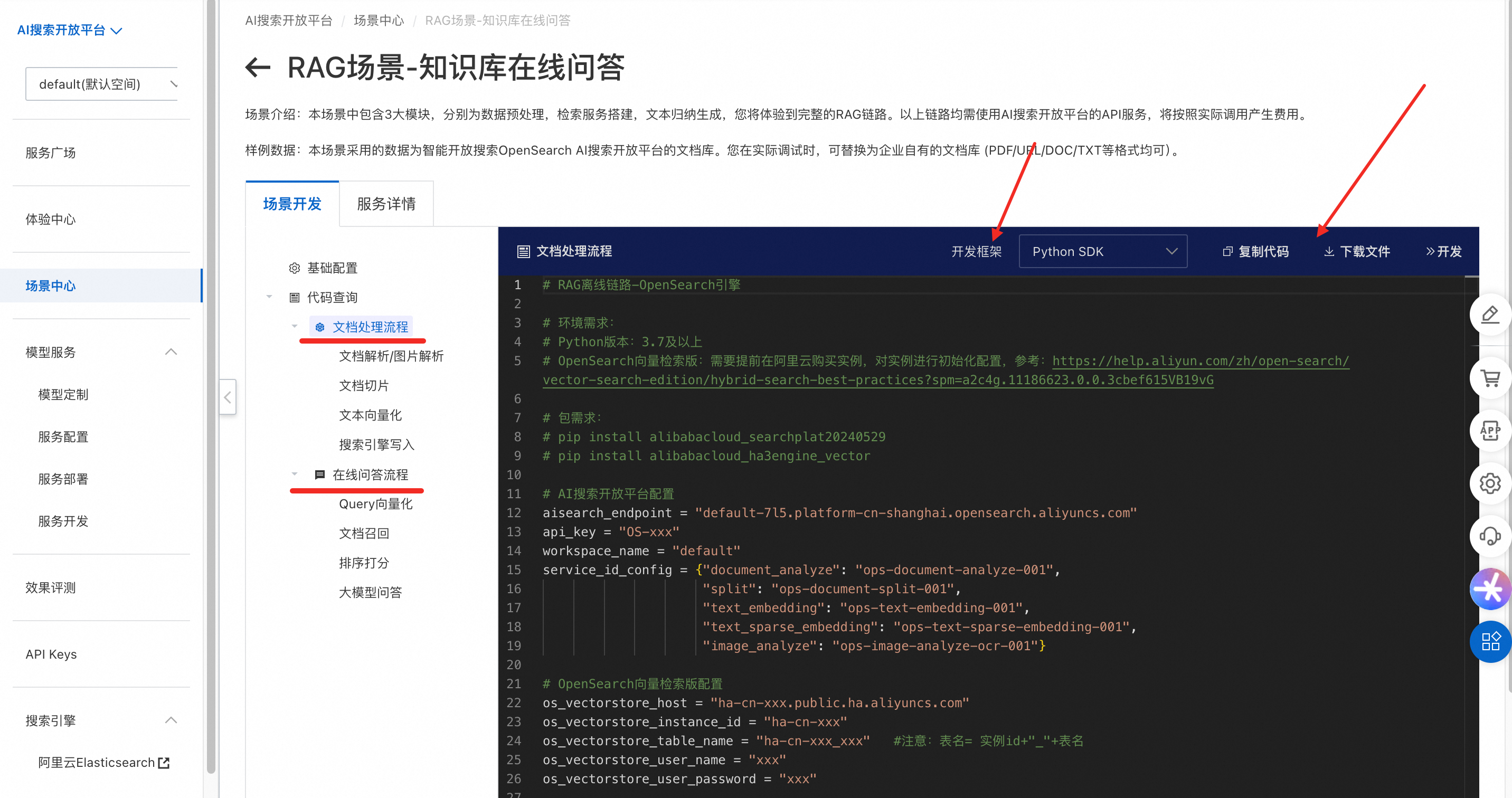
AI搜索开放平台提供四种类型的开发框架,本文以Python SDK方式为例。
-
Java SDK。
-
Python SDK。
-
如果业务已经使用LangChain开发框架,在开发框架中选择LangChain。
-
如果业务已经使用LlamaIndex开发框架,在开发框架中选择LlamaIndex。
2.本地环境适配和测试RAG开发链路
将「文档处理流程」和「在线问答流程」代码下载到本地文件后,即可以在本地的Python环境中执行脚本,进行效果测试。
2.1.环境准备
-
Python版本需要3.7及以上。
-
配置Python开发环境,安装依赖项。
# pip install alibabacloud_searchplat20240529
# pip install alibabacloud_ha3engine_vector2.2.配置参数
需要分别对「文档处理流程」和「在线问答流程」中的实例信息进行补充。
-
AI搜索开放平台配置
# AI搜索开放平台配置
api_key = "OS-xxx"
aisearch_endpoint = "default-7l5.platform-cn-shanghai.opensearch.aliyuncs.com"
workspace_name = "default"
service_id_config = {
"rank": "ops-bge-reranker-larger",
"text_embedding": "ops-text-embedding-001",
"text_sparse_embedding": "ops-text-sparse-embedding-001",
"llm": "deepseek-r1",
"query_analyze": "ops-query-analyze-001"
}|
参数 |
说明 |
|
api_key |
API调用密钥,获取方式请参见管理API Key |
|
aisearch_endpoint |
API调用地址,获取方式请参见获取服务接入地址。
|
|
workspace_name |
工作空间名称,如果你没有新建过工作空间,那就是默认的default,无需修改;如果使用的是新创建的工作空间,此处填入新工作空间的名称 |
|
service_id_config |
为服务选型页面选择的服务ID
|
-
OpenSearch向量检索版配置
# OpenSearch向量检索版配置
os_vectorstore_host = "ha-cn-xxx.public.ha.aliyuncs.com"
os_vectorstore_instance_id = "ha-cn-xxx"
os_vectorstore_table_name = "ha-cn-xxx_xxx"
os_vectorstore_user_name = "xxx"
os_vectorstore_user_password = "xxx"|
参数 |
说明 |
|
os_vectorstore_host |
向量检索版的API域名,获取方式请参见实例管理 |
|
os_vectorstore_instance_id |
向量检索版的实例ID,获取方式请参见实例管理 |
|
os_vectorstore_table_name |
向量检索版的表名 |
|
os_vectorstore_user_name |
向量检索版的用户名 |
|
os_vectorstore_user_password |
向量检索版的密码 |
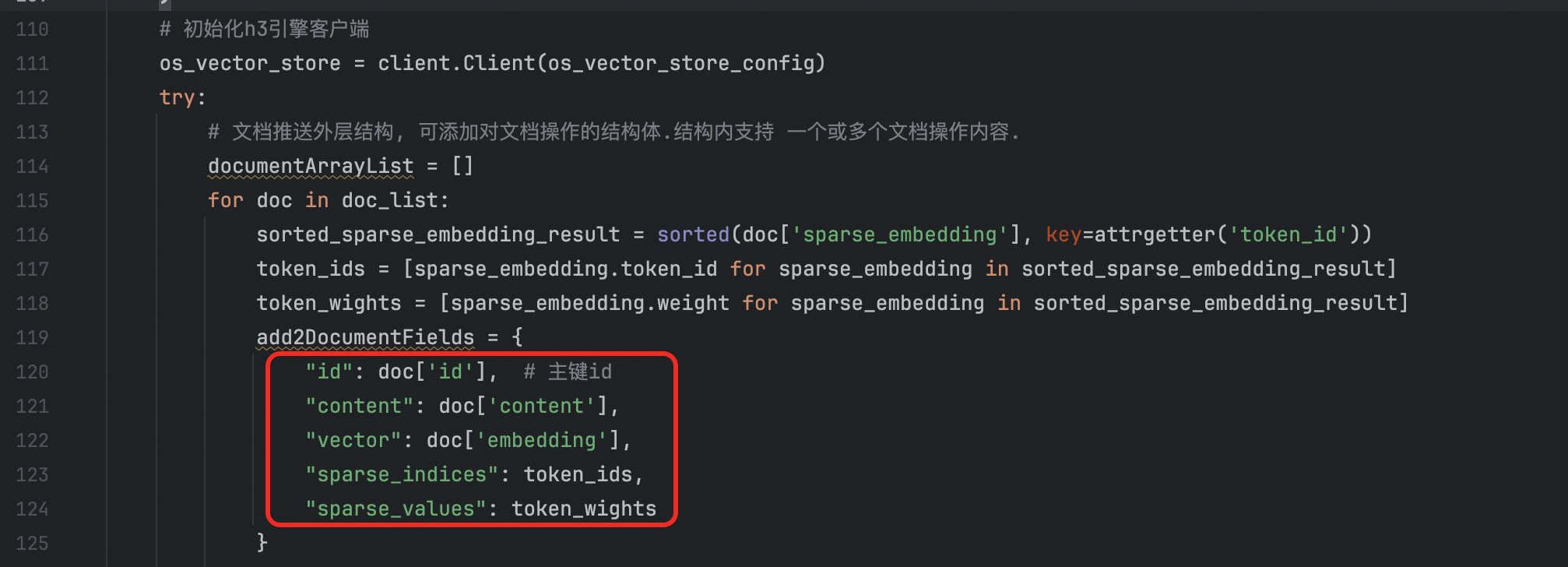
在「文档处理流程」代码中,需要将add2DocumentFields部分里的文档字段进行设置,注意这里字段需要和向量检索版中的配置的字段保持一致。
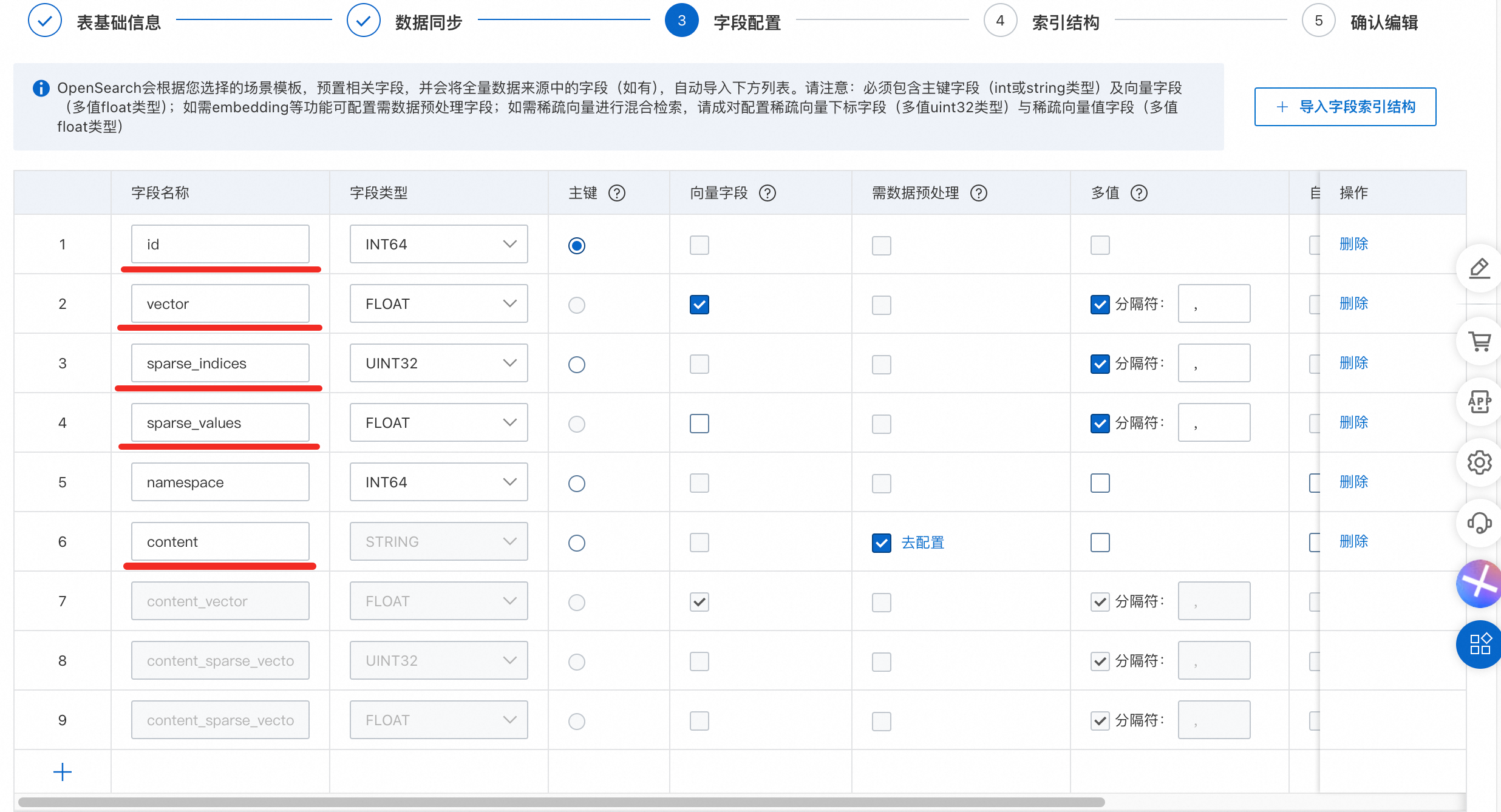
2.3.效果测试
-
文档处理
执行文档处理流程的脚本,包括文档解析、文档切片、向量化和将向量写入搜索引擎等任务。注意模板代码里用到的是示例数据(opensearch产品说明文档),如果希望处理自己的知识库,那么需要把document_url的链接换成自己文档链接。
# 输入文档url,示例文档为opensearch产品说明文档
document_url = "https://help.aliyun.com/zh/open-search/search-platform/product-overview/introduction-to-search-platform?spm=a2c4g.11186623.0.0.7ab93526WDzQ8z"运行代码后,如果出现“text-embedding done”,就说明文档处理中的写入数据执行成功。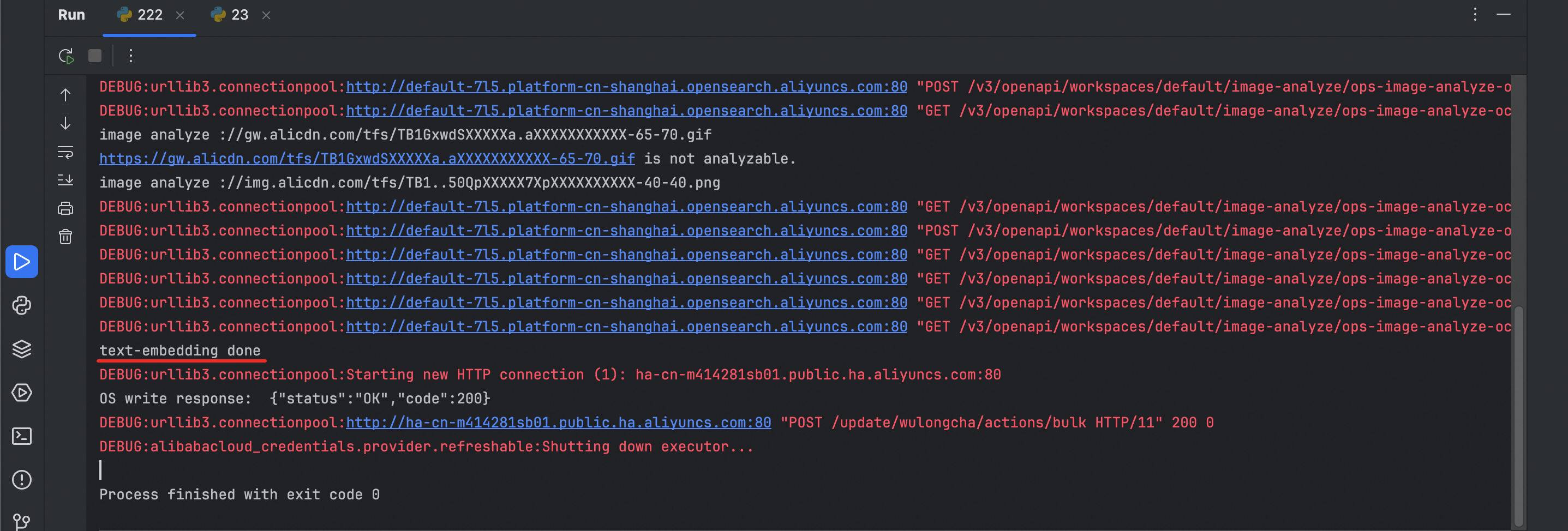
-
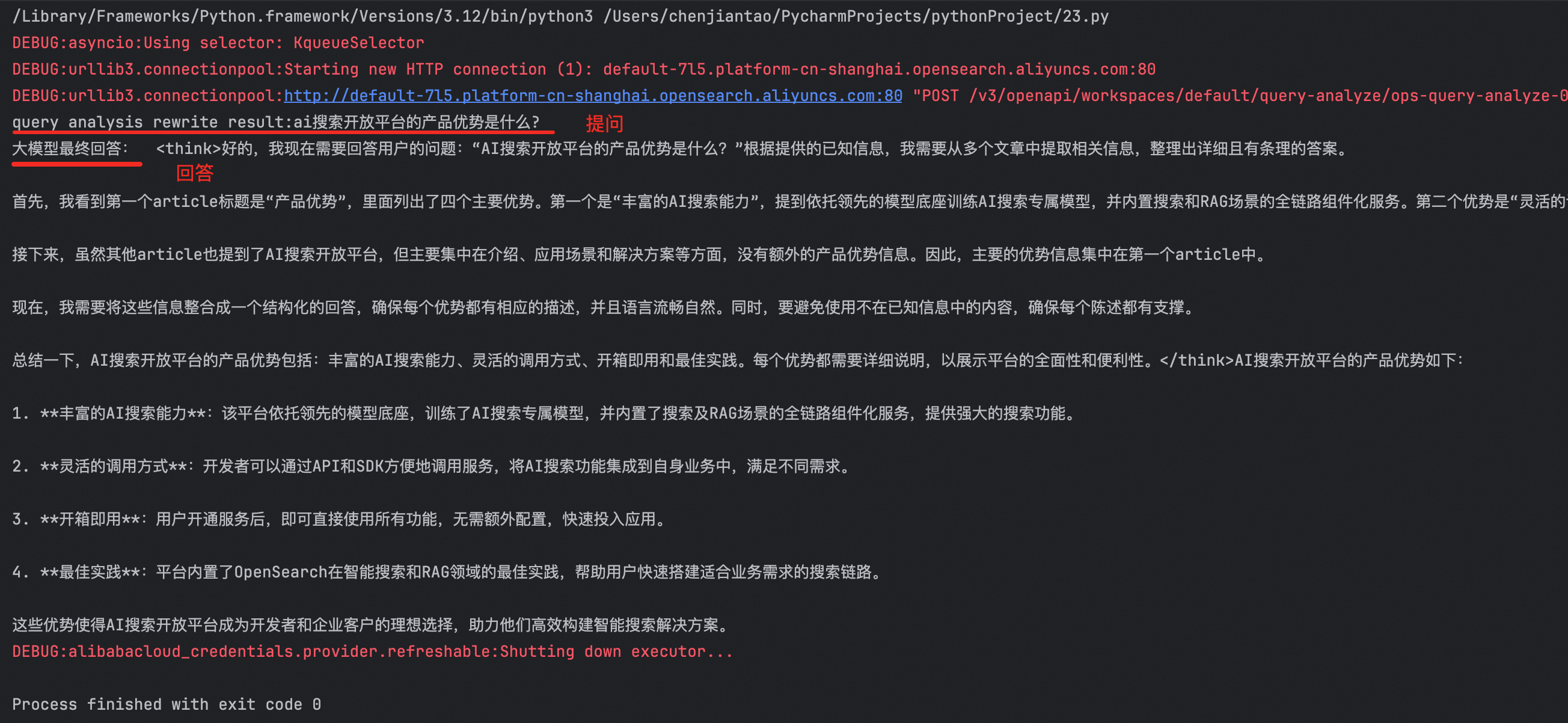
在线问答
执行在线问答脚本,向系统提问示例文档(opensearch产品说明文档)的内容,“AI搜索开放平台的产品优势是什么?”,大模型开始进行推理并完成回答。
-
如果执行过程中提示“调用get_text_generation_async方法时发生了超时错误”,可以在生成AI搜索开放平台client中找到protocol,将超时时间配置长一些。参考示例:“protocol="http",read_timeout=20000,connect_timeout=20000”
-
对召回文档进行序打分,示例脚本中设置的是top_k=8,可以根据具体情况修改该参数。

