大语言模型的知识缺少企业私有或实时的数据,通过检索增强生成RAG(Retrieval-Augmented Generation)技术可以检索私有知识库,并以上下文的方式提供给大语言模型,从而增强大语言模型回答的准确性和相关性。本文将详细介绍如何在LangStudio中开发和部署RAG应用。
背景信息
在现代信息检索领域,RAG模型结合了信息检索和生成式人工智能的优势,能够在特定应用场景中提供更为精准和相关的答案。例如在金融、医疗等专业领域,用户通常需要精确且相关的信息来支持决策。传统的生成模型虽然在自然语言理解和生成方面表现出色,但在专业知识的准确性上可能存在不足。RAG模型通过将检索与生成技术相结合,有效提升了回答的准确性和上下文相关性。本文以人工智能平台PAI为基础产品,为您介绍面向金融、医疗场景的大模型RAG检索增强解决方案。
前提条件
本文创建的向量数据库连接基于Milvus数据库,因此需要您先完成Milvus数据库的创建,详情请参见创建Milvus实例、实例管理。
已将RAG知识库语料上传至OSS中。本文针对金融、医疗场景提供以下示例语料:
1. 部署LLM和Embedding模型
本文以快速开始 > ModelGallery中部署的模型服务为例,后续创建连接时也会基于此处的模型服务进行创建。
前往快速开始 > ModelGallery,分别按场景选择大语言模型及Embedding分类,并部署指定的模型。本文以通义千问2.5-7B-Instruct和bge-large-zh-v1.5 通用向量模型为例进行部署。请务必选择使用指令微调的大语言模型(名称中包含“Chat”或是“Instruct”的模型),Base模型无法正确遵循用户指令回答问题。
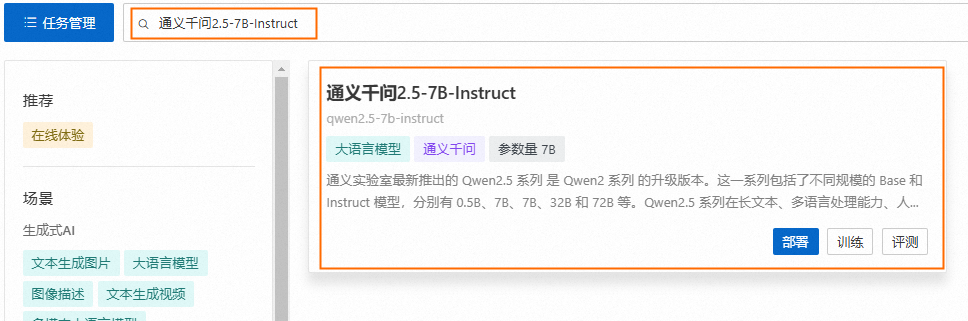
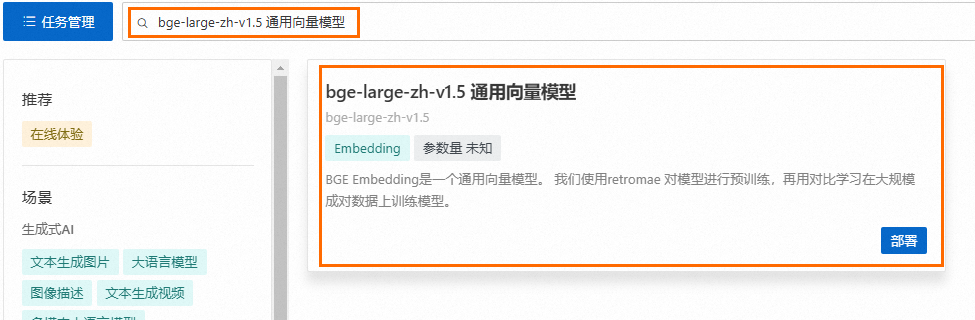
更多部署详情,请参见模型部署及训练。
前往任务管理,单击已部署的服务名称,在服务详情页签下单击查看调用信息,分别获取前面部署的LLM和Embedding模型服务的VPC访问地址和Token,供后续创建连接时使用。
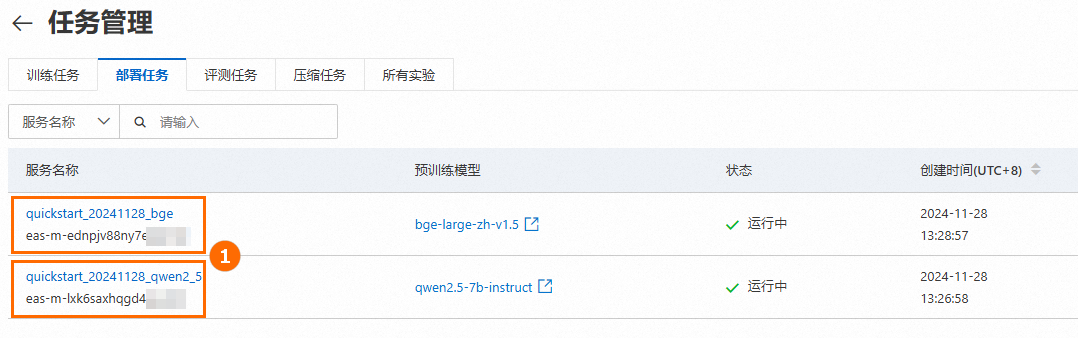
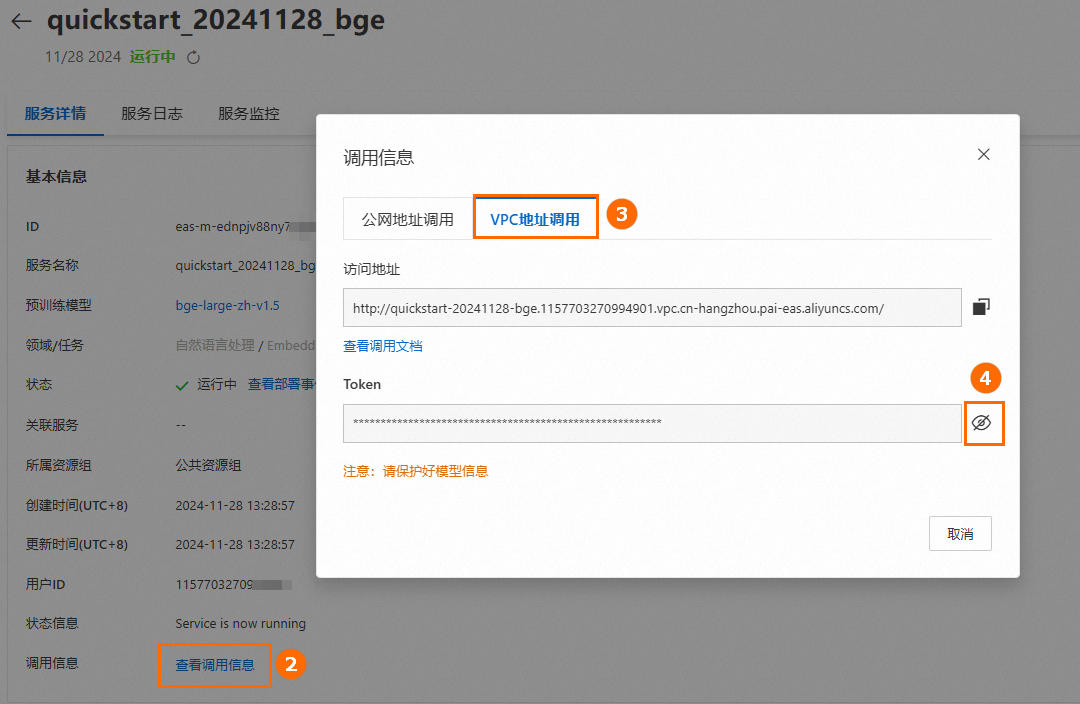
2. 创建连接
本文创建的LLM和Embedding模型服务连接基于快速开始 > ModelGallery中部署的模型服务。更多其他类型的连接及详细说明,请参见连接管理。
2.1 创建LLM服务连接
进入LangStudio,选择工作空间后,在连接管理页签下单击新建连接,进入应用流创建页面。
创建通用LLM模型服务连接。其中base_url和api_key分别对应1. 部署LLM和Embedding模型中LLM的VPC访问地址和Token。
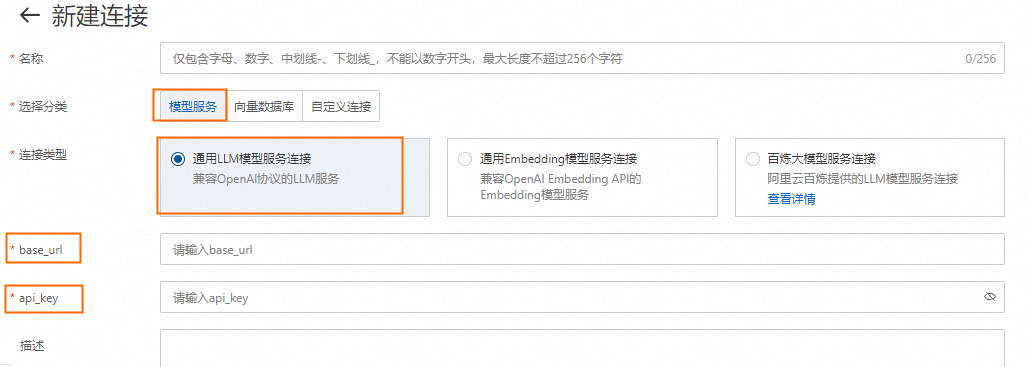
2.2 创建Embedding模型服务连接
同2.1 创建LLM服务连接,创建通用Embedding模型服务连接。其中base_url和api_key分别对应1. 部署LLM和Embedding模型中Embedding模型的VPC访问地址和Token。
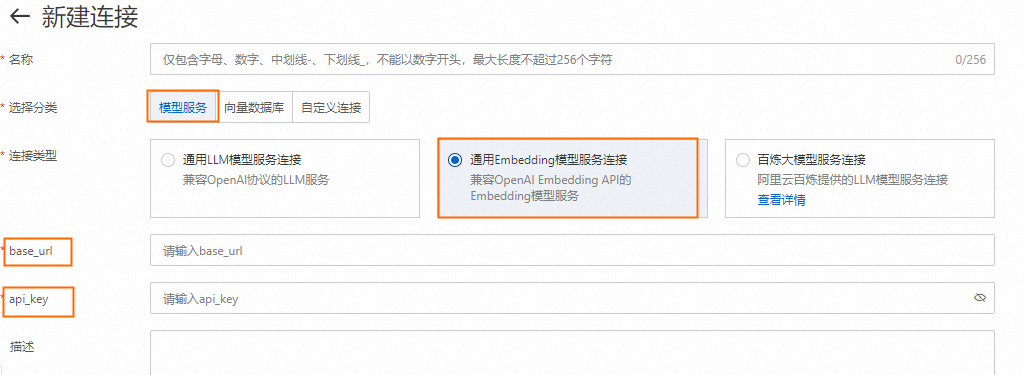
2.3 创建向量数据库连接
同2.1 创建LLM服务连接,创建Milvus数据库连接。
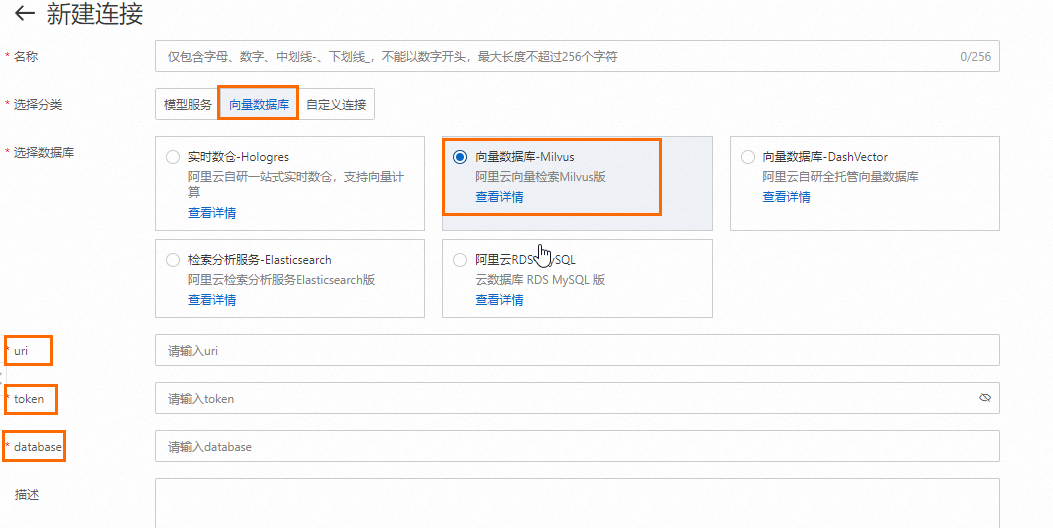
关键参数说明:
uri:Milvus实例的访问地址,即
http://<Milvus内网访问地址>,Milvus内网访问地址如下: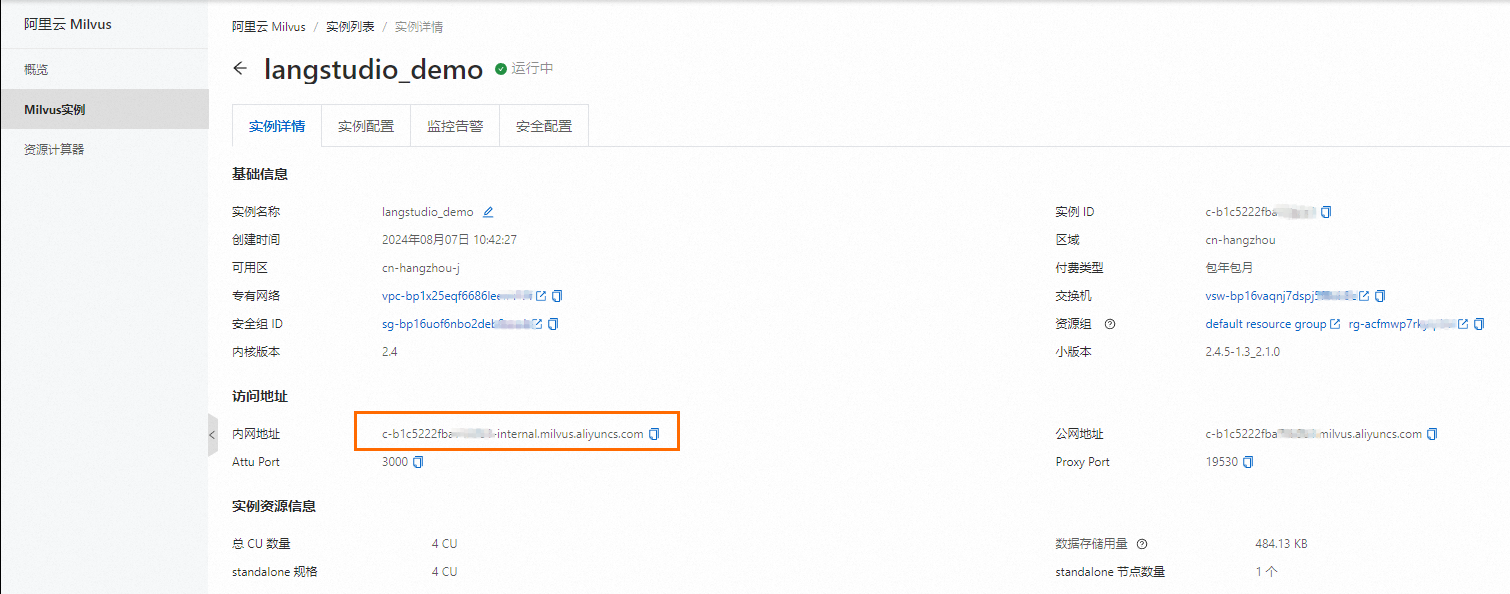
则uri为
http://c-b1c5222fba****-internal.milvus.aliyuncs.com。token:登录Milvus实例的用户名和密码,即
<yourUsername>:<yourPassword>。database:数据库名称,本文使用默认数据库
default。
3. 创建离线知识库
通过PAI-Designer预置的RAG离线知识库构建工作流模板,将语料经过解析、分块、向量化后存储到向量数据库,从而构建知识库。
进入PAI-Designer,选择工作空间后,在预置模板 > LLM 大语言模型页签下创建并进入RAG离线知识库构建工作流。
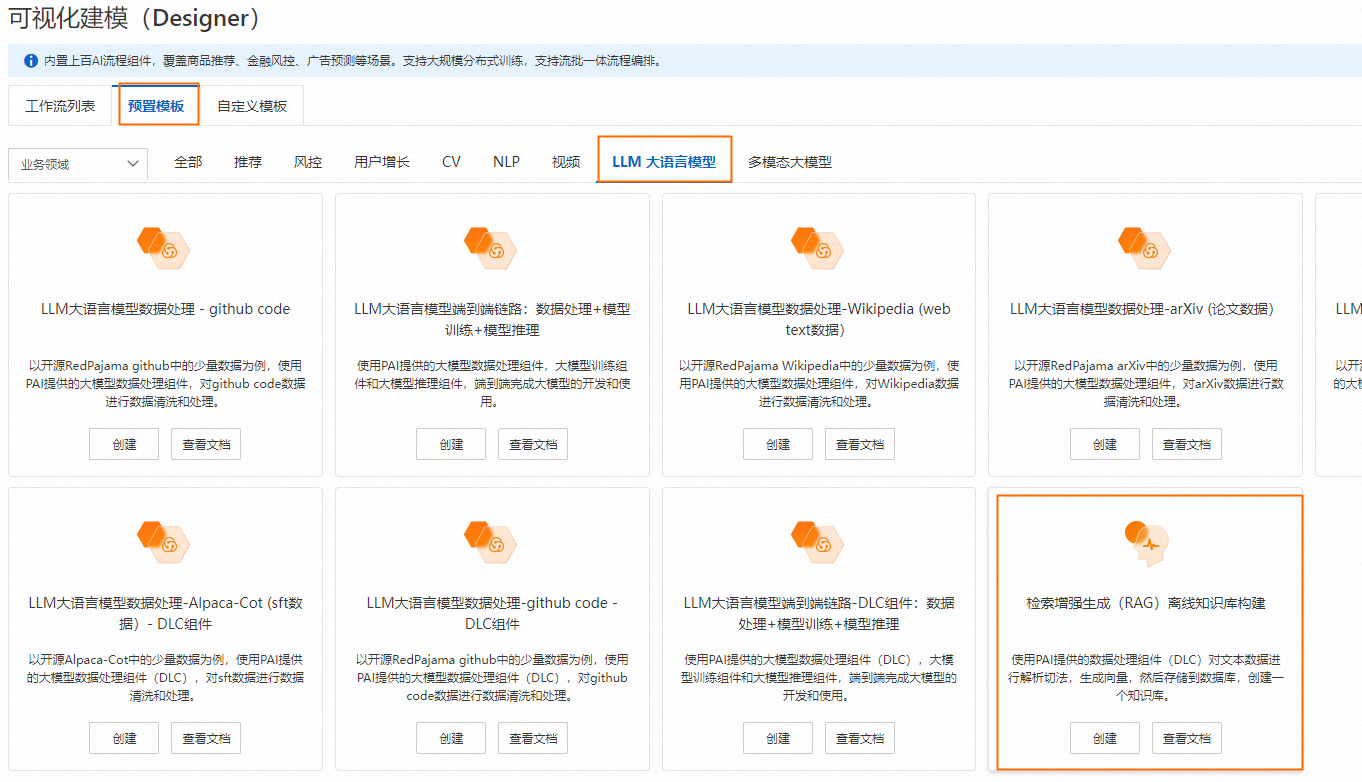
配置工作流,关键组件说明:
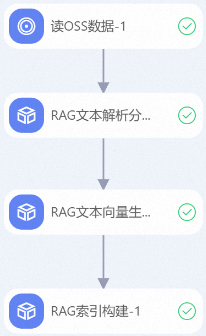
工作流中的其余配置保持默认或根据实际需求进行配置,关键组件配置如下:
读OSS数据
OSS数据路径:配置前提条件中RAG知识库语料的OSS路径。
RAG文本解析分块
块大小:本文部署的Embedding模型bge-large-zh-v1.5最大输入为512,需要将文本分块大小调整为512或者更小。
RAG文本向量生成
Embedding模型连接名称:配置2.2 创建Embedding模型服务连接中创建的连接名称。
RAG索引构建
向量数据库连接:配置2.3 创建向量数据库连接 中创建的连接。
集合/表名称:配置前提条件中创建Milvus数据库的Collection。
执行调优 > 专有网络配置:配置Milvus实例所在的专有网络。
运行工作流。
4. 创建并运行RAG应用流
进入LangStudio,选择工作空间后,在应用流页签下单击新建应用流,模板类型选择RAG,创建RAG应用流。
启动运行时:单击右上角启动运行时并进行配置。注:在进行Python节点解析或查看更多工具时,需要保证运行时已启动。
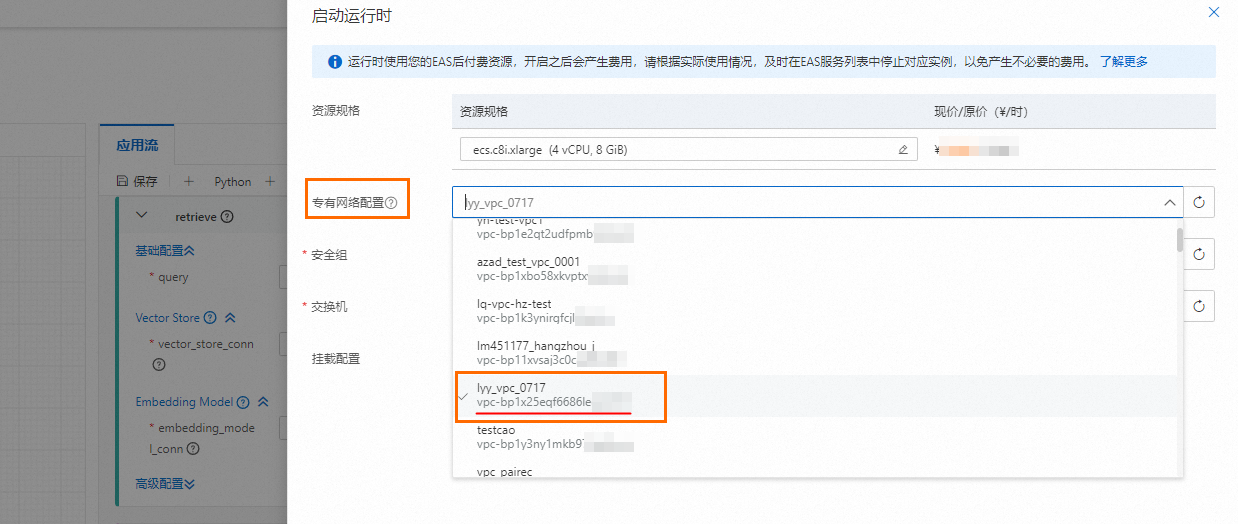
关键参数说明:
专有网络配置:选择前提条件中创建Milvus实例时的专有网络。

开发应用流。应用流中的其余配置保持默认或根据实际需求进行配置,关键节点配置如下:
rewrite_question:重写用户问题,将用户的问题重写为更具体、准确的表述。
connection:选择2.1 创建LLM服务连接中创建的连接。
model:输入default。如果connection选择的是百炼大模型服务连接,则model需在下拉列表中选择对应的模型名称,百炼模型名称可在百炼-模型广场中查看。
retrieve:在知识库中检索与用户问题相关的文本。
vector_store_conn:选择2.3 创建向量数据库连接中创建的连接。
index_name:输入前提条件中创建Milvus数据库的Collection。
embedding_model_conn:选择2.2 创建Embedding模型服务连接中创建的连接。
embedding_model_name:置空。如果embedding_model_conn选择的是百炼大模型服务连接,则embedding_model_name需在下拉列表中选择对应的模型名称,百炼模型名称可在百炼-模型广场中查看。
threshold_filter:根据向量索引查找组件返回的相似度分数过滤分数低于阈值的文档。
generate_answer:使用过滤后的文档作为上下文,与用户问题一起发送给大语言模型,生成回答。
connection:选择2.1 创建LLM服务连接中创建的连接。为了简化流程,本文在generate_answer阶段采用和rewrite_question阶段相同的连接。在生产阶段,您可以根据实际需求创建并选择不同的连接。
model:输入default。如果connection选择的是百炼大模型服务连接,则model需在下拉列表中选择对应的模型名称,百炼模型名称可在百炼-模型广场中查看。
调试/运行:单击右上角对话, 开始执行应用流。
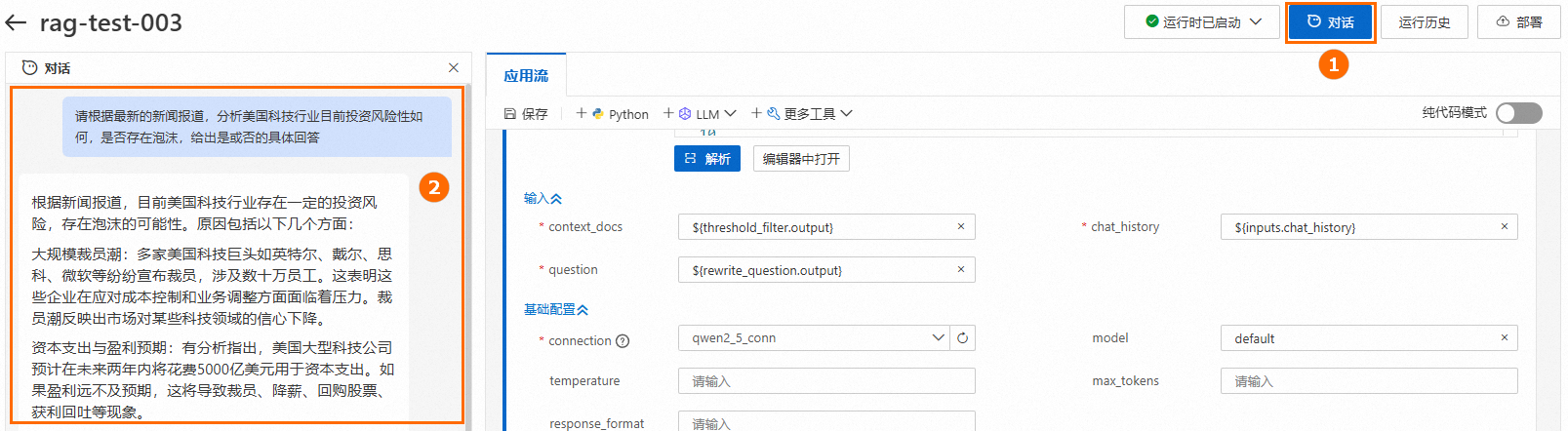
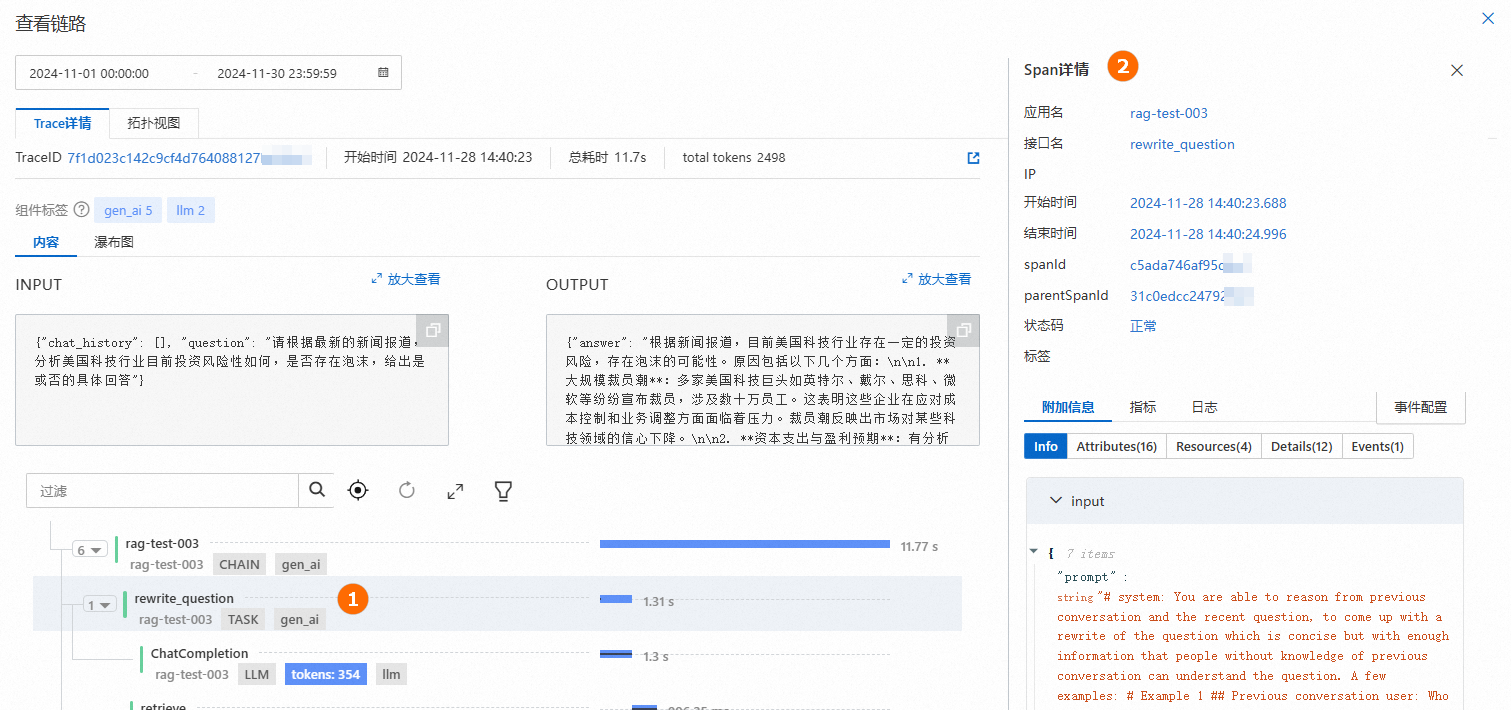
查看链路:单击生成答案下的查看链路,查看Trace详情或拓扑视图。
5. 部署应用流
在应用流开发页面,单击右上角部署,部署参数其余配置保持默认或根据实际需求进行配置,关键参数配置如下:
资源部署信息 > 实例数:配置服务实例数。本文部署仅供测试使用,因此实例数配置为1。在生产阶段,建议配置多个服务实例,以降低单点故障的风险。
专有网络配置 > VPC:配置Milvus实例所在的专有网络。
更多部署详情,请参见应用流部署。
6. 调用服务
部署成功后,跳转到PAI-EAS,在在线调试页签下配置并发送请求。请求参数中的Key与应用流中输入节点中的"Chat 输入"字段一致,本文使用默认字段question。
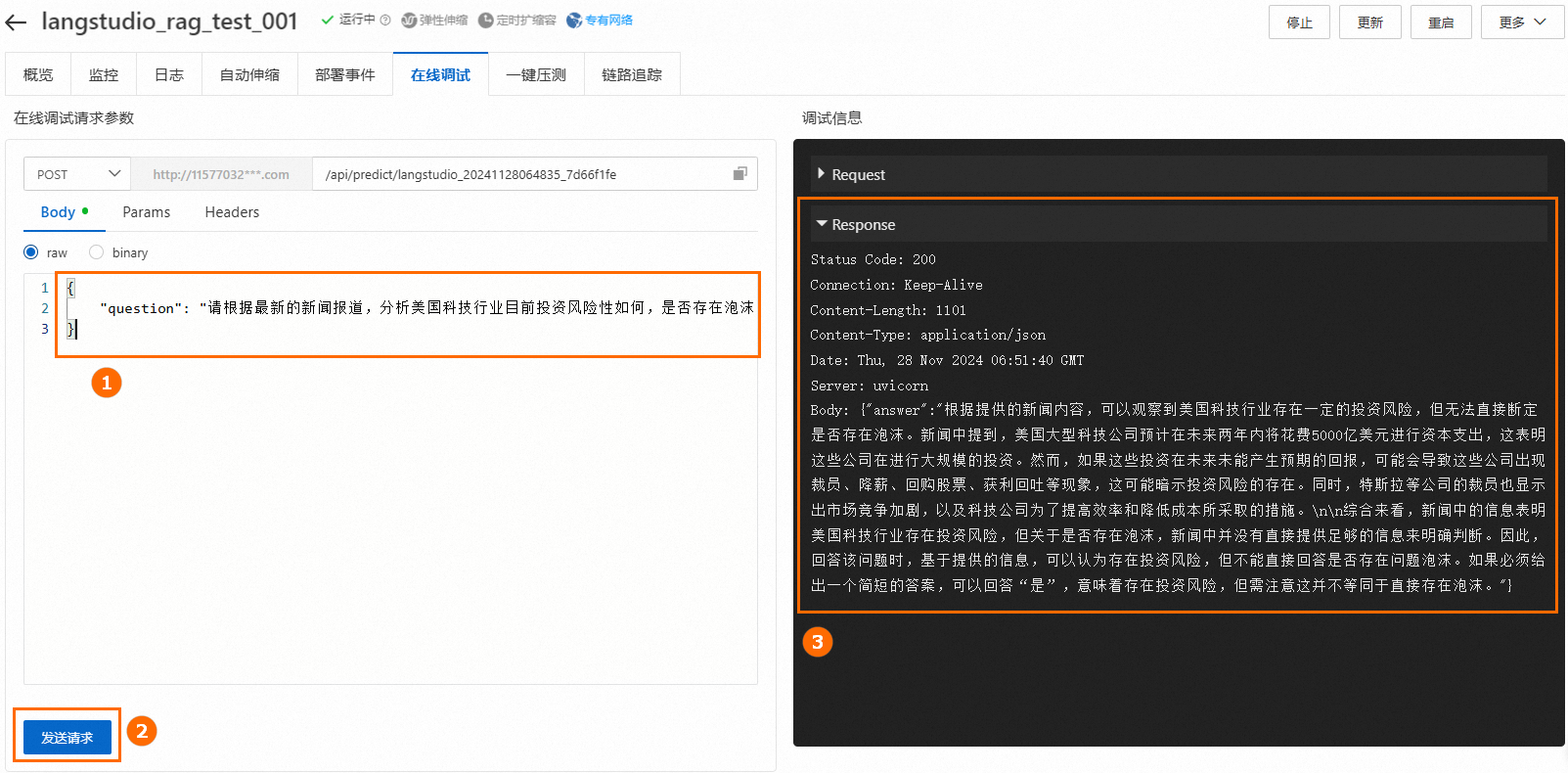
更多调用方式(如API调用)及详细说明,请参见调用服务。
附录:案例对比
在以下案例中,将对比金融和医疗领域中使用与不使用RAG技术来解决特定任务的效果。红色部分表示大模型回答存在事实性错误或不够具体精确,而绿色部分则展示了使用RAG技术后得到的正确回复。
金融领域
任务一:投资风险分析
问题:请根据最新的新闻报道,分析美国科技行业目前投资风险性如何,是否存在泡沫,给出是或否的具体回答。
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|


任务二:行业趋势分析
问题:请根据最新的新闻报道,给出房地产相关行业是否乐观的判断。
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|


任务三:贸易情况分析
问题:我国近10个月来货物贸易进出口情况如何?
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|


医疗领域
任务一:疾病治疗建议
问题:患者女,40岁,常年患有全身性红斑狼疮。请根据相关医疗知识,给出个性化的治疗建议。
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|


任务二:疾病辅助诊断
问题:患者男,30岁,近日发现右眼视力严重受损,视力模糊并且出现复视,并且有肢体无力、共济失调现象。请根据相关医疗知识,判断患者可能患有的疾病,并且推荐医院相关科室进行治疗。
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|


任务三:疾病预警
问题:孕妇子痫前症的发病病因有哪些。
通义千问2.5-7B-Instruct回复
| 通义千问2.5-7B-Instruct + RAG回复
|

