
当您希望在业务流程中集成AI能力(如文本摘要、智能问答、商品推荐)时,通常面临着复杂的AI基础设施搭建、高昂的算力成本以及数据跨域流动的安全风险。为了解决这些痛点,PolarDB推出了AI模型算子(Model as Operator)能力,它允许您通过简单的SQL语句或直接调用模型的访问地址进行推理。其核心价值在于,数据无需离开您的VPC,即可在数据库内部完成低延迟、高吞吐的AI计算,简化了AI应用的开发和维护,同时保障了数据的安全与合规。
功能简介
核心架构
PolarDB的AI模型算子本质上是一个部署在您集群内的模型推理服务网关。它作为PolarDB内核与底层AI算力之间的桥梁,通过统一的访问地址(私网/公网/PrivateLink)向您提供服务。
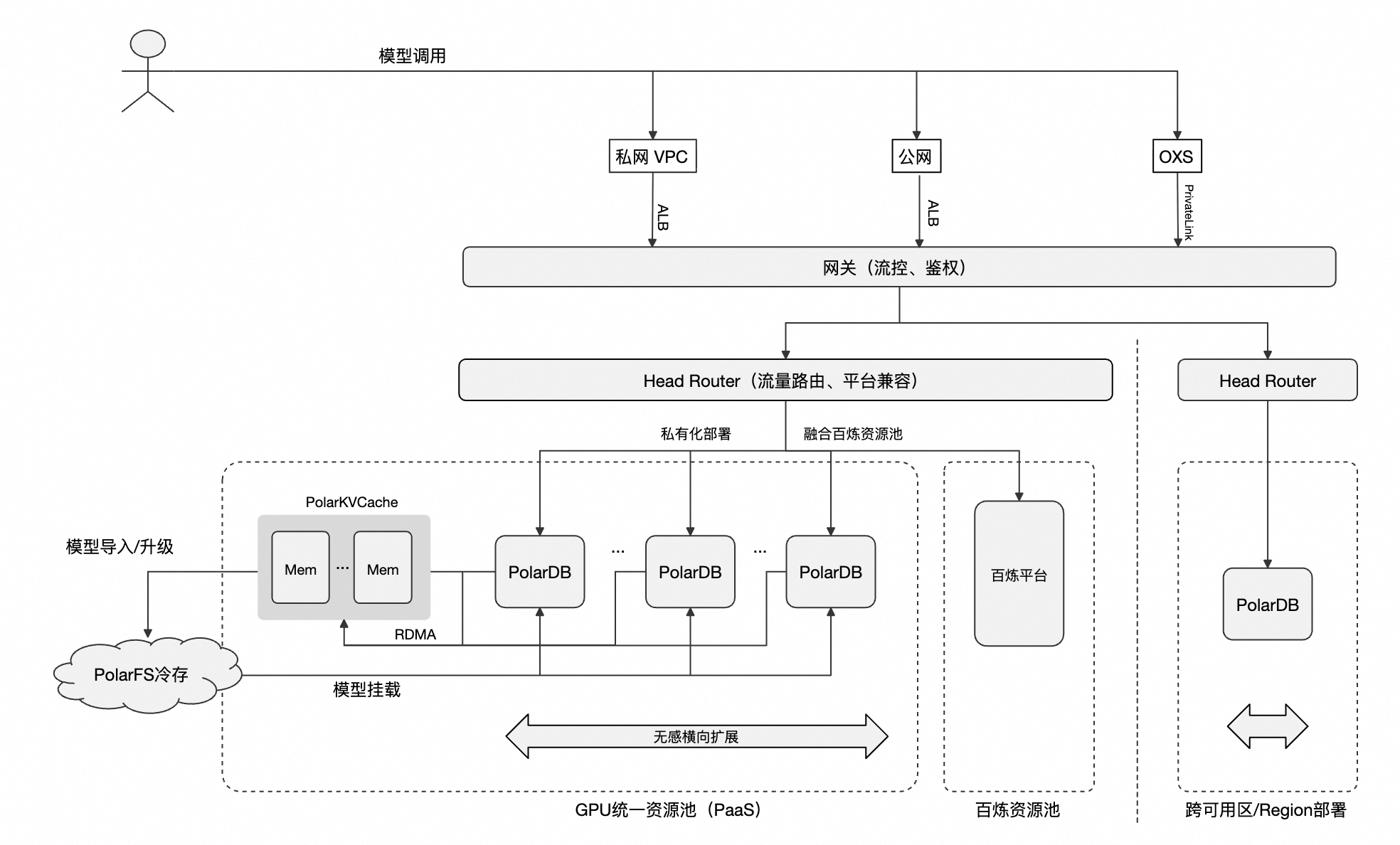
其核心数据流如下:
模型调用:可通过SQL函数调用或直接调用模型的访问地址。
方式一:采用SQL函数的方式进行模型注册与调用。
模型注册:通过
AI_CreateModel函数,在PolarDB中注册一个模型。注册信息包括模型的访问地址(model_url)和提供方(如阿里云大模型服务平台百炼或自定义服务)。SQL调用:业务应用执行
AI_CallModel函数,将需要推理的数据(如一段文本)作为参数传入。
方式二:直接调用提供方(如阿里云大模型服务平台百炼或自定义服务)的模型访问地址,模型输入参数应与提供方的规范保持一致。
服务代理:将请求转发给部署AI模型算子的PolarDB集群。
模型推理:AI模型算子根据注册信息,向后端的AI模型服务(如阿里云大模型服务平台百炼)发起调用,执行推理计算。
结果返回:AI模型算子获取推理结果,并将其返回给PolarDB,最终以SQL查询结果的形式呈现给您。
部署模式
AI模型算子支持专属资源+阿里云大模型服务平台百炼混池的混合部署架构。该架构的核心优势在于通过内置网关,在两个资源池之间进行流量分配。
特性 | 专属资源 | 阿里云大模型服务平台百炼混池 | 混合部署架构优势 |
资源隔离 | 物理隔离,独享GPU算力,性能稳定无干扰。 | 逻辑隔离,共享大规模算力资源池。 | 通过内置网关,将需要物理隔离和性能稳定性的核心请求定向至专属资源,其余请求利用混池的逻辑隔离,实现性能与成本的最佳平衡。 |
数据隐私 | 最高。模型和数据均在您VPC内处理。 | 较高。数据仍在您VPC内,但模型服务由阿里云大模型服务平台百炼托管。 | 无论流量走向何方,数据始终在您的VPC内。对于有数据不出VPC最严格合规要求的流量,网关可确保其始终在专属资源内处理,提供最高级别的安全保障。 |
成本 | 相对较高,按预留资源付费,适合作为稳定容量基石。 | 成本较低,按实际用量付费,适合承载绝大部分常规流量。 | 将主体流量引导至按量付费的阿里云大模型服务平台百炼混池,大幅降低基础成本。仅在必要时(如处理Corner Case)动用专属资源,避免了为全部流量预留昂贵专属算力的浪费,实现成本优化。 |
弹性 | 支持手动扩缩容,保障核心业务的确定性容量。 | 支持智能弹性伸缩,自动应对流量洪峰。 | 充分利用阿里云大模型服务平台百炼混池的智能弹性能力应对业务洪峰,同时专属资源作为稳定容量的基石和处理特定请求的快速通道。二者结合,既能从容应对流量波动,又能保证核心业务的绝对稳定。 |
核心性能
高吞吐:在PolarSearch集群中对接Qwen-Embedding模型时,通过AI模型算子能力,每分钟请求数(QPM)可达26,000以上。
低延迟:基于三层解耦内存池的PolarKVCache技术,大模型推理的首Token时延(TTFT)可降低7倍,整体吞吐量提升60%。
优势
开箱即用
您可以在数据库内直接调用主流的开源模型或您自己的定制模型,无需复杂的环境配置,即刻为您的数据应用注入AI能力。数据不出域
数据始终保留在您自己的VPC(私有网络)内,并且模型可部署于指定地域。这确保了计算过程的物理隔离,完全满足数据安全、隐私保护的合规要求。弹性伸缩 & 无感流控
系统能根据实时负载自动、平滑地伸缩资源,从容应对业务的波峰波谷。这既能保障服务的持续稳定,又能最大化资源利用率,降低成本。高性能
基于三层解耦内存池的PolarKVCache技术,大幅提升了模型推理效率,实现首Token时延(TTFT)可降低7倍,整体吞吐能力提升60%,确保交互的流畅体验。监控体系
提供覆盖模型从调用到返回的全链路监控。您可以清晰观测服务状态,并通过自动化的异常告警,第一时间发现并定位问题,保障业务稳定运行。生态融合
服务与PolarDB、PolarSearch及IMCI等功能原生集成。让AI能力无缝融入您现有的数据分析与应用工作流,无需在多个系统间切换,简化开发。灵活计费
提供多种计费模式:包年包月、按量付费与按Token计费。您可以根据业务的稳定或波动情况,自由选择最经济的成本方案。
应用场景
在数据库内进行向量检索与智能问答
在构建基于大语言模型的智能问答、知识库或推荐系统时,通常需要将业务数据(如产品文档、历史对话)转换为向量并存储。使用AI模型算子,您可以直接在数据库内调用Embedding模型(如Qwen3-Embedding-8B),将文本数据实时或批量转换为向量。结合PolarDB的向量检索能力,可以在一个SQL查询中完成用户问题向量化->相似向量匹配->返回相关业务数据的完整流程,无需将数据导出到外部向量数据库,简化了技术架构并降低了数据同步的延迟。
对海量数据进行自动化标注与清洗
对于存储在数据库中的海量非结构化数据,如用户评论、商品描述等,手动进行情感分析、标签提取或数据分类成本高昂且效率低下。您可以利用AI模型算子,编写一个SQL函数或存储过程,批量将这些数据发送给大语言模型(LLM)进行处理。例如,调用模型判断用户评论的情感倾向(正面/负面/中性)或提取关键信息,并将结果直接写回数据表的新字段中,实现数据的自动化富化和质量提升。
构建满足数据安全合规的AI应用
对于金融、医疗、政务等对数据安全和隐私有严格要求的行业,数据通常不允许离开客户的私有网络环境。AI模型算子的专属资源部署模式是理想的解决方案。它将AI模型服务直接部署在您的VPC内,确保模型调用和数据处理的全过程都在安全边界内完成,满足数据不出域的合规要求。这使得您可以在保障数据安全的前提下,利用AI能力进行风险预测、合规审计或敏感信息识别等高级分析。
适用范围
集群形态:集中式PolarDB PostgreSQL版集群,暂不支持PolarDB PostgreSQL分布式版集群。
数据库引擎:PostgreSQL 16。
地域:华东1(杭州)、华东2(上海)、华北2(北京)、华南1(深圳)、华北6(乌兰察布)、中国香港、新加坡以及德国(法兰克福)。
费用说明
AI模型的计费方式默认根据您选择的GPU节点规格和购买时长进行计算。此外,系统也支持按Token计费。如您有相关需求,请提交工单与我们联系,以便为您转换计费方式。
创建AI模型实例
您可以通过以下两种方式进行创建:
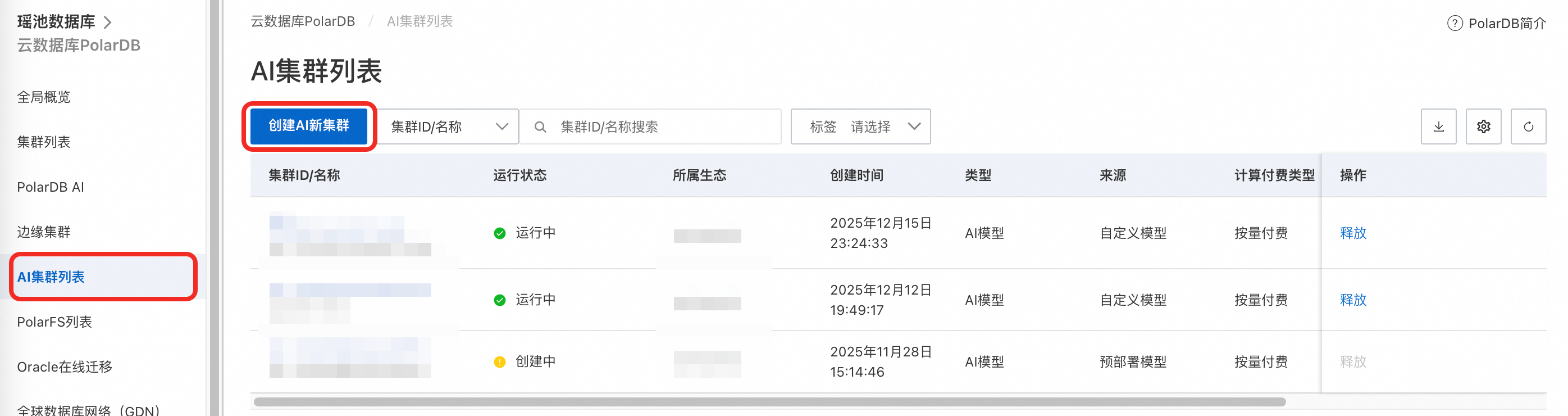
前往PolarDB控制台,单击左侧导航栏的AI集群列表,并单击创建AI新集群。
前往PolarDB控制台,在左侧导航栏单击集群列表,找到符合适用范围的目标集群并进入集群详情页。单击左侧导航栏中的,并单击新建AI模型。
在模型购买页面中,请根据您的需求选择适合的配置:
配置项
说明
付费类型
包年包月:预付费模式。在创建应用时,您需选择固定规格的资源,并预先支付应用的费用。购买周期越长,所享受的折扣也越大。该模式一般适用于业务需求长期稳定的场景。
按量付费:后付费模式。在创建应用时,您需选择固定规格的资源,但无需提前支付应用的费用。该模式根据您实际使用的时长进行计费,一般适用于业务需求灵活的场景。
引擎
固定为PolarDB。
地域
选择应用所在的地理位置。
说明应用购买完成后,不支持更改地域。
应用需与PolarDB PostgreSQL版集群位于同一地域。因此,请选择与PolarDB PostgreSQL版集群相同的地域。
建议将应用与需要连接的ECS创建在同一地域,否则它们将无法通过内网(私网)实现互通,只能通过外网(公网)进行通信,这将无法充分发挥最佳性能。
架构
选择AI节点。
生态
选择PostgreSQL。
源 PolarDB 集群
选择需要创建模型的PolarDB集群。
扩展
您可以根据实际业务需求,选择是否预部署指定模型。
预部署模型
自动部署开源LLM模型。部署成功后,将提供可调用的模型服务。
模型列表:支持多种开源模型,您可以根据实际业务需求进行选择。例如,
Qwen3-VL-30B-A3B-Instruct、Qwen3-14B或DeepSeek-R1-Distill-Qwen-32B等。部署方式:固定一键部署。
推理引擎:可选择SGLang或VLLM。
是否开启KVCache加速:选择是否开启KVCache加速。取值范围:10~100000,默认100,单位GB。详细价格信息,请以购买页为准。
自定义模型
若您已有LLM模型,则可选择直接部署自有模型。
部署方式:固定一键部署。
推理引擎:可选择SGLang或VLLM。
自定义模型:请填写模型所在的OSS Bucket、路径以及模型名称。
自有模型参数:设置自有模型的部署相关参数。
格式:以
--开头。示例:
--gpu-memory-utilization:0.85。--served-model-name:Qwen3-0.6B-xxx。
自有模型最大访问限制:您可以根据实际业务需求进行配置。取值范围:1~99999,默认100。
说明付费类型需选择按量付费。
地域需选择与OSS Bucket地域保持一致。
在部署自有模型之前,需要先为PolarDB授权访问OSS Bucket的只读(包含ListObject操作)权限。建议设置一个专门用于托管自有模型的OSS Bucket,并授予PolarDB对该Bucket的整体只读权限。
实例规格类型
选择为GPU规格。
GPU资源
选择对应的GPU规格。
说明在扩展选择自定义模型时,规格可随意选择,实际上并不生效。
开启周期分时
选择是否在固定的时间段自动启动资源,在其他时间段自动停止资源。
网络类型
固定为专有网络。
VPC网络
自动填写为源PolarDB集群的专有网络,无需手动填写。
可用区和交换机
配置VPC网络的交换机,建议选择与PolarDB PostgreSQL版集群的主可用区相同的交换机,以发挥最佳网络性能。
如果已有的交换机无法满足您的要求,您可以自行创建交换机。
安全组
配置应用的安全组。
购买数量
选择需要购买的应用数量。
说明每个PolarDB PostgreSQL版集群仅支持购买一个相同类型的AI应用。
仅付费类型为包年包月时,支持配置。
购买时长
选择应用的购买时长。
说明仅付费类型为包年包月时,支持配置。
自动续费
配置是否开启自动续费。为避免因忘记续费而导致业务中断,建议您开启自动续费。
说明仅付费类型为包年包月时,支持配置。
购买成功后,请返回相应的AI模型列表页面,以查看新创建的模型。如果选择预部署模型,请耐心等待系统完成相应模型的部署。
管理AI模型实例
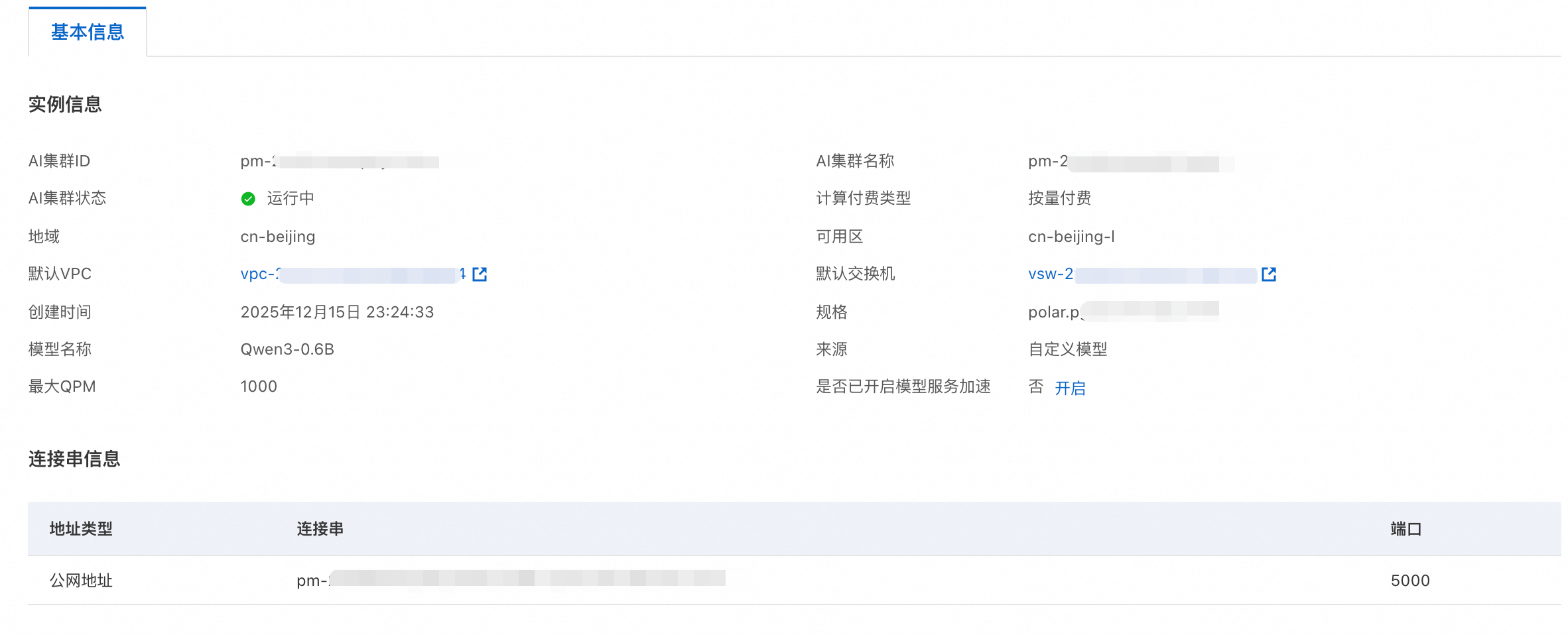
查看模型信息:进入AI模型列表页面,单击模型实例名称,您可以查看模型实例的基本信息与连接串信息。
查看模型实例监控信息:进入AI模型列表页面,单击操作列的查看云监控。您可以查看模型实例的请求数、负载率、Token消耗等信息。
模型开发
SQL函数调用:您可以根据模型管理中的SQL函数进行AI_CreateModel - 创建模型、AI_SetModelToken - 设置模型API-Key、AI_CallModel - 调用模型、AI_AlterModel - 更新模型以及AI_DropModel - 删除模型等操作。
直接调用模型的访问地址:您可以直接调用提供方(如阿里云大模型服务平台百炼或自定义服务)的模型访问地址,模型输入参数应与提供方的规范保持一致。