
Dify是一款开源的大语言模型(LLM)应用开发平台。它将后端即服务(Backend as Service)与LLMOps理念相结合,使开发者能够迅速构建生产级的生成式AI应用。本文将介绍如何基于RDS PostgreSQL与Dify平台构建智能问答应用。
本方案依赖于RDS PostgreSQL实现。您可以加入RDS PostgreSQL插件交流钉钉群(103525002795),进行咨询、交流和反馈,获取更多关于插件的信息。
步骤一:创建RDS PostgreSQL实例
步骤二:部署Dify
创建ECS实例,详情请参见自定义购买ECS实例。
CPU版ECS实例,支持添加在线AI大模型。
GPU版ECS实例,支持添加在线及ECS本地的AI大模型。
重要本文以Alibaba Cloud Linux 3为例。
如果您购买的是GPU版的ECS实例,您需要在配置镜像时,安装对应的GPU驱动。使用GPU版的ECS实例,您可以使用Ollama将大模型部署在ECS上。
在ECS中,安装Docker。详情请参见安装Docker。
(可选)如果购买的是GPU版的ECS实例,需要执行如下命令,安装container-toolkit组件。
执行如下命令,获取Dify源码。
git clone https://github.com/langgenius/dify.git您可以通过
branch参数指定版本分支,以安装特定版本。例如,安装v1.0.0版时,可以使用如下命令。Dify的分支版本请参见dify。git clone https://github.com/langgenius/dify.git --branch 1.0.0说明如果未安装Git命令,请执行
sudo yum install git -y进行安装。配置环境变量,将RDS PostgreSQL作为默认数据库和向量库。
设置RDS PostgreSQL为默认数据库。
export DB_USERNAME=testdbuser export DB_PASSWORD=dbPassword export DB_HOST=pgm-****.pg.rds.aliyuncs.com export DB_PORT=5432 export DB_DATABASE=testdb01请根据实际情况替换代码中的参数值。
参数
说明
DB_USERNAME
RDS PostgreSQL实例的高权限账号。
DB_PASSWORD
RDS PostgreSQL实例的高权限账号的密码。
DB_HOST
RDS PostgreSQL实例的外网连接地址。
DB_PORT
RDS PostgreSQL实例的外网端口,默认为5432。
DB_DATABASE
RDS PostgreSQL实例中的数据库名称。
设置RDS PostgreSQL作为默认向量库。
export VECTOR_STORE=pgvector export PGVECTOR_HOST=pgm-****.pg.rds.aliyuncs.com export PGVECTOR_PORT=5432 export PGVECTOR_USER=testdbuser export PGVECTOR_PASSWORD=dbPassword export PGVECTOR_DATABASE=testdb01请根据实际情况替换代码中的参数值。
参数
说明
VECTOR_STORE
使用vector插件。
PGVECTOR_USERNAME
RDS PostgreSQL实例的高权限账号。
PGVECTOR_PASSWORD
RDS PostgreSQL实例的高权限账号的密码。
PGVECTOR_HOST
RDS PostgreSQL实例的外网连接地址。
PGVECTOR_PORT
RDS PostgreSQL实例的外网端口,默认为5432。
PGVECTOR_DATABASE
RDS PostgreSQL实例中的数据库名称。
您也可以通过
.env文件配置RDS PostgreSQL为默认数据库和向量库。(可选)若您希望在ECS中避免运行默认的数据库和Weaviate容器,以节省流量和存储空间,请编辑
.env和docker-compose.yaml文件,以禁用默认的数据库和Weaviate容器。执行如下命令,启动Dify镜像。
cd /root/dify/docker docker compose -f docker-compose.yaml up -d
步骤三:访问Dify服务
在浏览器中访问
http://<ECS公网IP地址>/install,以访问Dify服务。说明如果访问失败,请多次刷新页面,Dify正在初始化存储表结构及相关信息。
请根据页面提示设置管理员账户(即邮箱地址、用户名和密码),以注册Dify平台来使用服务。
步骤四:添加并配置AI模型
本文以通义千问为例。
登录Dify平台。
在右上角,单击用户名称 > 设置。
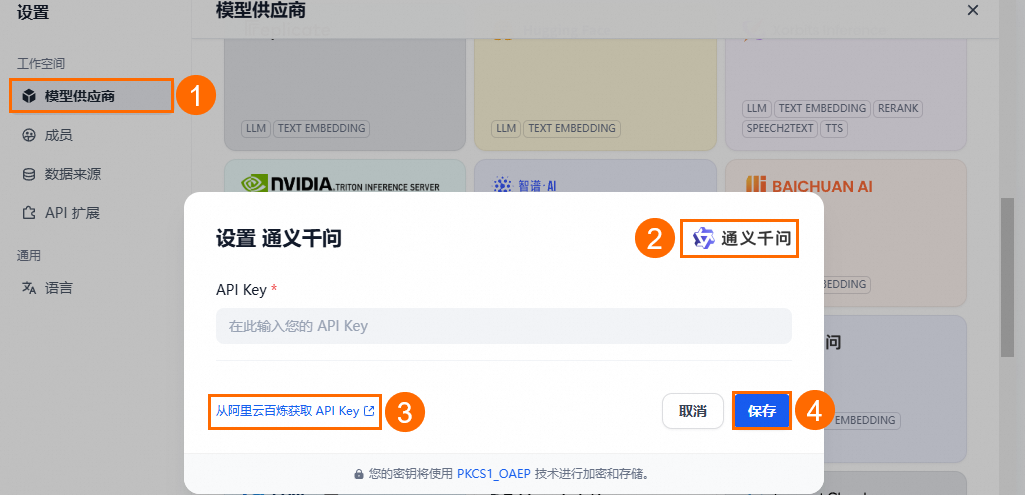
在设置页面,选择模型供应商 > 通义千问 > (设置)。
在通义千问的设置页面,单击链接获取阿里云百炼的API Key。
输入获取到的API Key后,单击保存。
如果您购买的是GPU版本的是ECS,您可以将通义千问的LLM服务部署在ECS上。
步骤五:创建知识库
通过专属知识库,可使智能问答应用更加精准和专业地回答相关问题。
前提条件
已准备好专属知识库的语料文件。当前已支持TXT、MARKDOWN、MDX、PDF、HTML、XLSX、XLS、DOCX、CSV、MD和HTM等格式,每个文件不超过15 MB。
操作步骤
依次单击知识库 > 创建知识库 > 导入已有文本 > 选择文件 > 下一步,将准备好的文件上传至知识库。

单击下一步后,您可根据页面引导,进行文本分段与清洗。
此处的配置参数保持默认即可。知识库将自动为上传的文档进行清洗、分段并建立索引,以便后续智能问答应用在回答时检索参考。
通过RDS PostgreSQL验证知识库并确认索引
配置知识库完成后,需在RDS PostgreSQL数据库中对知识库内容进行验证,并对每个知识库表的索引进行确认。
连接Dify使用的RDS PostgreSQL数据库,连接RDS PostgreSQL实例。
执行如下命令,查看知识库对应的ID。
SELECT * FROM datasets;将目标ID中的
-替换为_,加上前缀embedding_vector_index_和后缀_nod后,即为存储该知识库的表名称。例如,执行如下命令,即可查看目标知识库在RDS PostgreSQL中存储的数据。SELECT * FROM embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod;确认知识库索引。
Dify平台在创建知识库时,会默认为每一个知识库创建HNSW索引,以加速使用pgvector插件进行的向量相似度查询。系统默认使用如下的SQL语句进行向量相似度查询。
SELECT meta, text, embedding <=> $1 AS distance FROM embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod ORDER BY distance LIMIT $2;使用以下语句检查知识库表的索引及其默认参数是否符合召回率要求。HNSW索引
m、ef_construction与召回率之间的关系,请参见pgvector性能测试(基于HNSW索引)。SELECT * FROM pg_indexes WHERE tablename = 'embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod';如未自动创建索引,或索引的默认参数不符合召回率要求,请执行以下命令以手动创建索引。
(可选)删除已有索引。
DROP INDEX IF EXISTS embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod;创建索引。
CREATE INDEX ON embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod USING hnsw (embedding vector_cosine_ops); WITH (m = '16', ef_construction = '100');
说明embedding_vector_index_6b169753_****_****_be66_9bddc44a4848_nod为索引表名称,在实际应用中,请根据需要替换该表名称。
步骤六:创建智能问答应用
本文以应用模板中的Question Classifier + Knowledge + Chatbot模板为例。
单击工作室 > 从应用模板创建 。

查找Question Classifier + Knowledge + Chatbot,并单击使用该模板。
配置应用名称和图标后,单击创建。
在工作室页面,单击新创建的应用卡,进入到应用编排页面。
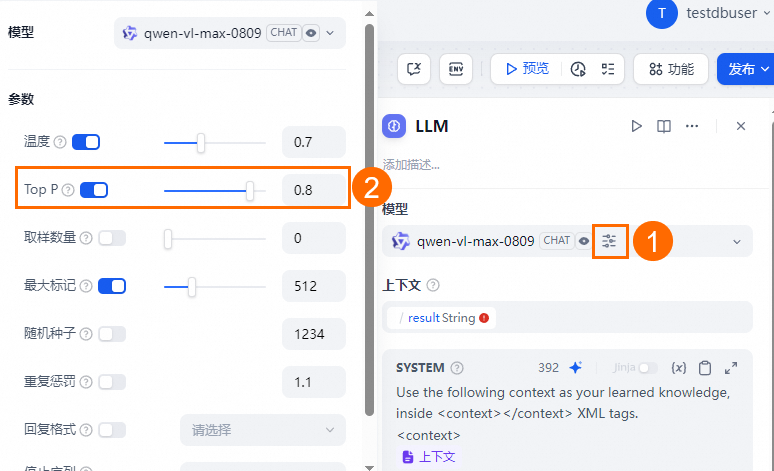
配置应用工作流,删除Answer模块,保留一个Knowledge Retrieval模块,并将Question Classifier和LLM模块的AI模型修改为通义千问。

配置通义千问大模型时,需要将Top P的值设置为小于1的数值。
编辑Question Classifier模块,根据实际情况修改问题分类。例如,此前创建的知识库是关于PostgreSQL的内容,以PostgreSQL知识问答为例,可以设定:
当问题和PostgreSQL相关时,采用知识库+通义千问大模型进行归纳总结。
当问题和PostgreSQL无关时,采用通义千问大模型进行回答。

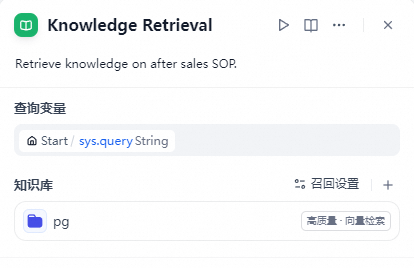
编辑Knowledge Retrieval模块,添加此前创建的与PostgreSQL相关的知识库。
单击右上角的预览,进行问答演示。演示正常后,单击右上角的发布,即可发布应用。