
Salesforce on Alibaba Cloud 的AI产品能力已经进一步迭代:
由CXG AI Connector 提供百炼大模型能力,CXG RAG 在 Salesforce Prompt Builder 提示生成器中为提示词补充准确、及时且相关的非结构化知识数据,从而帮助我们管理准确的企业内部知识,提升大语言模型生成结果的业务专业度和相关性。
CXG RAG 的产品优势
洞察非结构化数据
仅需点击操作即可轻松从Salesforce Data Library 中提取关键信息
在 Prompts 中应用最新且相关的业务信息
结合 Prompt Builder, 您可以实时从知识库中检索关联信息,结合上下文生成 Prompt,从而显著提升 LLM 的响应准确
赋能员工的现有工作流
业务人员可通过 RAG 和 AI Actions,向客户提供更相关、更个性化的回复,显著提升客户满意度和忠诚度
CXG RAG 的工作流程

RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术,其效果由三个核心阶段决定:
1.建立索引:在Data Library 中管理我们的企业知识,对文档内容进行解析、切片与向量化。
文档解析:这里需要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk)
文本向量化:将文档中的文本内容转化为数值向量,此过程叫做embedding,并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。这就是建立索引的过程。
2.检索召回:根据用户查询(Prompt),从向量存储中匹配并召回相关的知识片段。
随着用户输入请求,RAG 需要计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置,最大值为20)作为回答当前问题的知识。在这个过程中需要用到2个实时模型:
实时请求Embedding:在用户发起请求时,实时将用户查询 (Query) 通过模型进行向量化,用于后续的文档向量检索。
实时请求ReRank: ReRank模型用于语义检索场景,可以给定查询 (Query) 和一系列候选文本(Documents),会根据与查询的语义相关性从高到低对候选文本进行排序,从而简单、有效地提升文本检索的效果。
3.生成答案:知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
产品能力概览
无缝集成Prompt Builder :将Prompt Builder 与CXG RAG 产品能力结合起来,让AI更“理解”我们的业务知识。
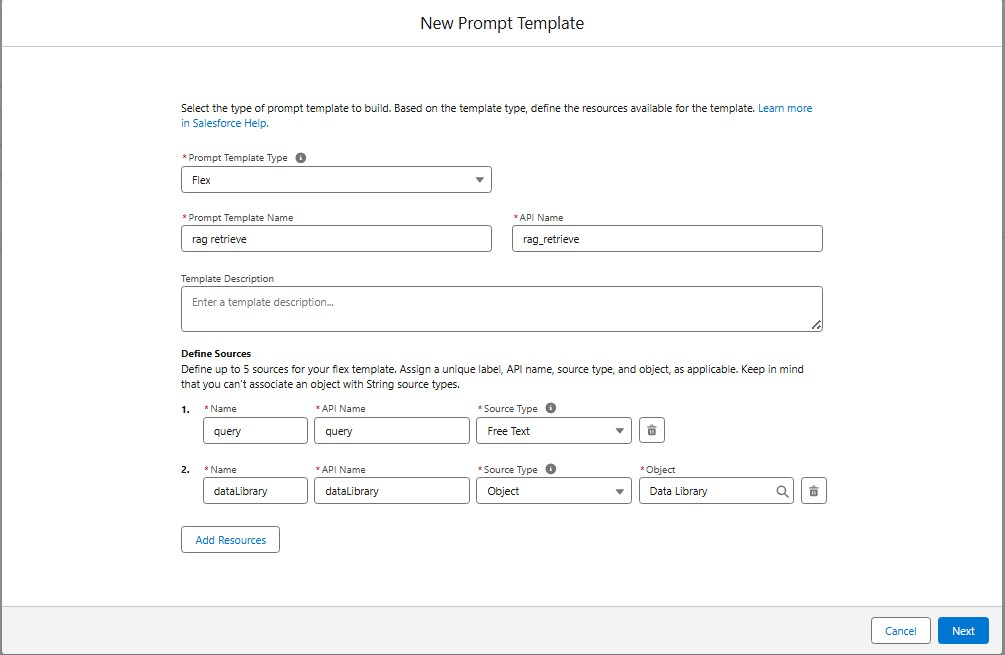
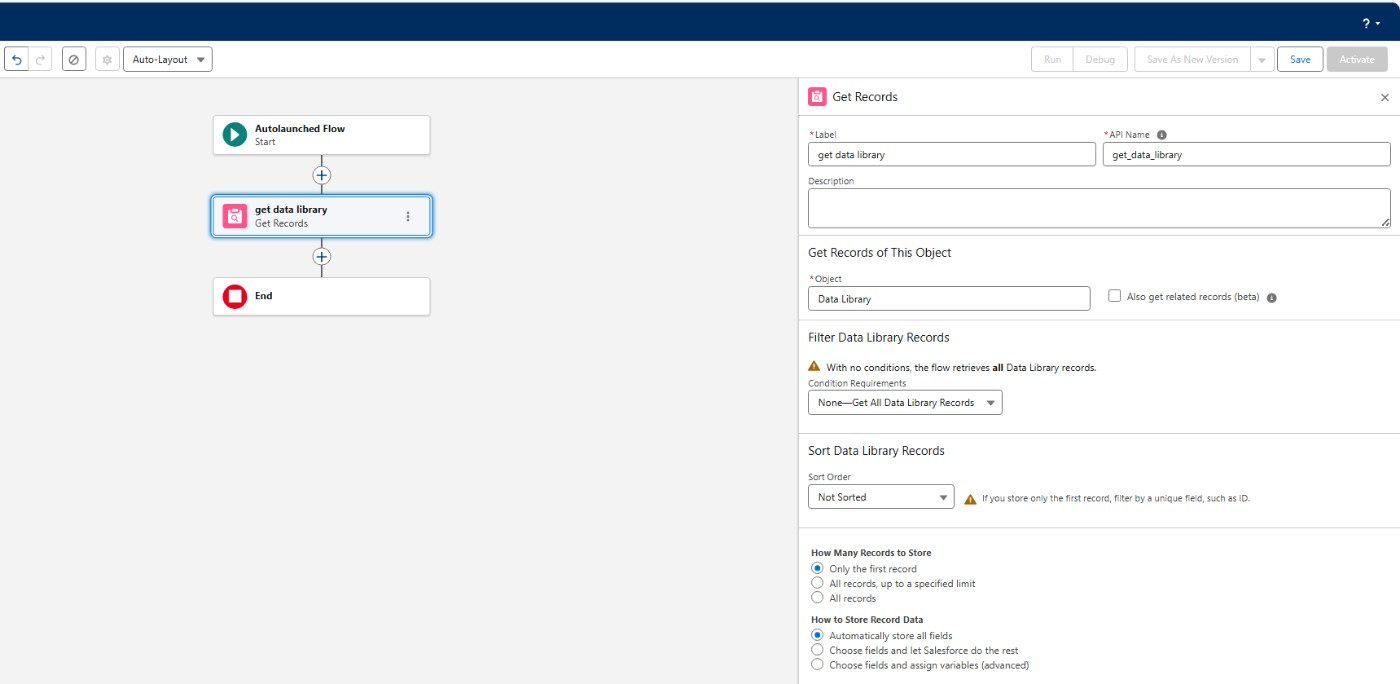
和工作流程深度融合:在 Flow 中直接调用 CXG AI 提升效率,同时利用 RAG 确保流程服务的业务精准度。
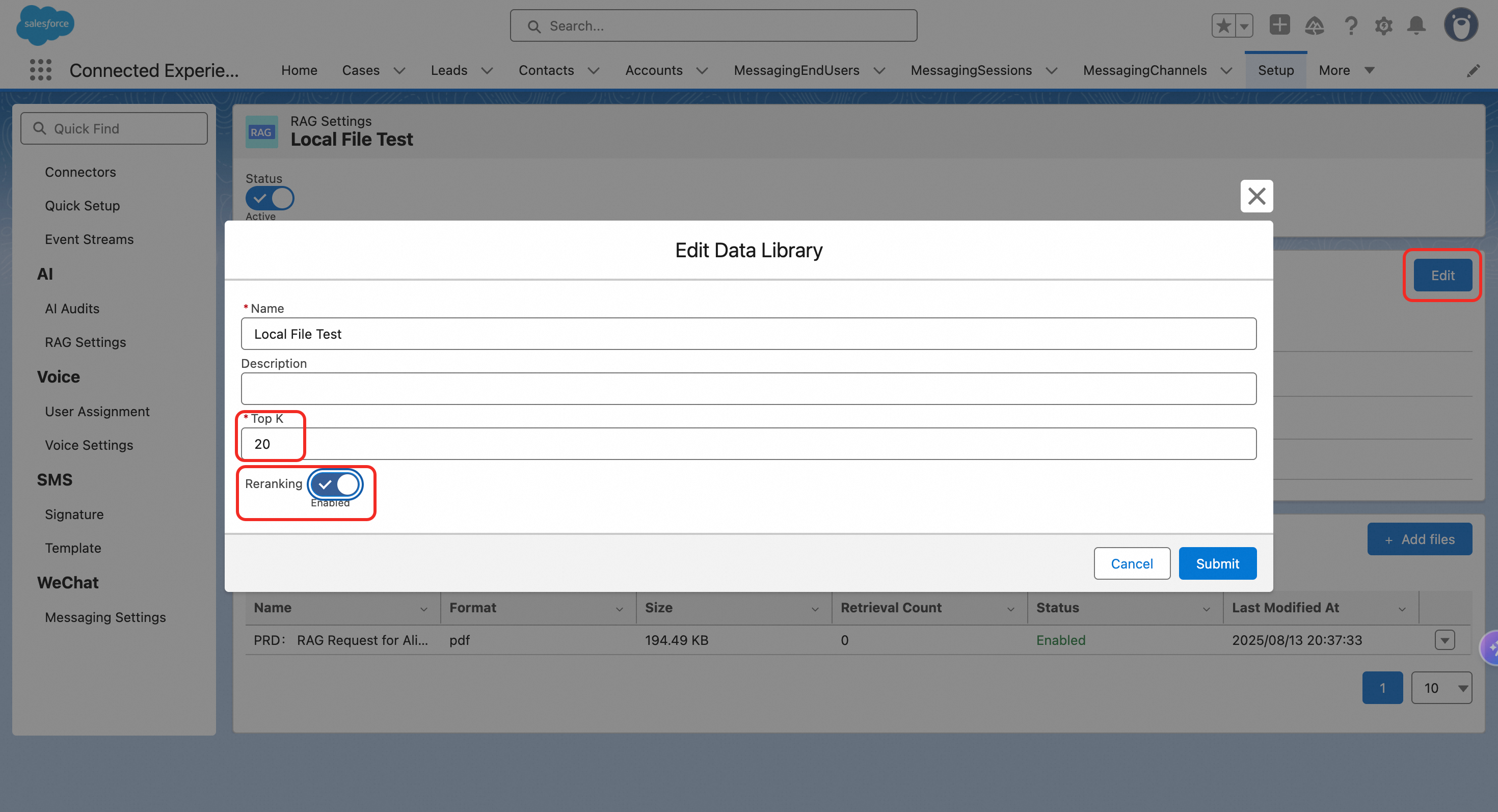
灵活调整CXG RAG效果:通过编辑知识库内容、调整 Top K(最大值20) 及启用重排序(ReRank)模型,可灵活优化 CXG RAG 效果
安全保障

物理数据隔离
RAG 服务支持组织级数据隔离,从而降低数据泄露风险。
端到端加密
RAG 服务全程加密,静态数据使用 AES256 加密,传输中的数据通过 TLS 1.2 协议进行保护。
最小权限原则
Salesforce 对用户身份进行强验证并进行相关访问控制。基于Salesforce 共享设置,RAG 服务支持按知识库层级设置权限控制。
RAG 的效果保障
采用“智能切分”策略——基于语义相关性进行切分,有助于保留语义完整性。
选择适合您知识库的文本切片长度并非易事,因为这必须考虑多种因素:
文件的类型:例如,对于专业类文献,增加长度通常有助于保留更多上下文信息;而对于社交类帖子,缩短长度则能更准确地捕捉语义。
提示词的复杂度:一般来说,如果用户的提示词较为复杂且具体,则可能需要增加长度;反之,缩短长度会更为合适。
当前您在创建知识库时,我们为您默认了智能切分作为切分方式,应用这一策略时,知识库会:
首先利用系统内置的分句标识符将文件划分为若干段落。
基于划分的段落,根据语义相关性自适应地选择切片点进行切分(语义切分),而非根据固定长度进行切分。
在上述过程中,知识库将努力确保文件各部分的语义完整性,尽量避免不必要的划分和切分。此策略将应用于该知识库中的所有文件(包括后续导入的文件)。
优化提示词提升RAG辅助效果
如果返回的结果没有按照要求,或者不够全面,您可以:优化提示词模板。通过调整提示词来影响大模型的行为(例如怎样利用检索到的知识等),间接提升 RAG 的效果。
如果希望反馈不同效果的RAG结果,您可以调整参数提升RAG辅助效果:
调整Top K(召回片段数):召回片段数即多路召回策略中的K值。如果文本切片数量超过K,系统最终会选取相似度分数最高的 K 个文本切片提供给大模型。也正因为此,不合适的K值也可能会导致 RAG 漏掉正确的文本切片,从而影响大模型生成完整的回答。
开启ReRank模型:可以给定查询 (Query) 和一系列候选文本(Documents),会根据与查询的语义相关性从高到低对候选文本进行排序,从而简单、有效地提升文本检索的效果。