本文汇总了使用FTP客户端连接云虚拟主机以及上传网站文件后出现的常见问题。
权限问题:
连接问题:
Linux操作系统云虚拟主机的目录用途是什么?
Linux操作系统云虚拟主机的常见目录说明如下表所示:
| 目录名称 | 含义 | 权限 |
| / | FTP的根目录。 | 只读权限 |
| /awstats | 日志分析统计报告存放目录,该目录目前是一个空目录。 | 只读权限 |
| /ftplogs | FTP访问日志的存放位置。 | 只读权限 |
| /htdocs | 网站的根目录,您需要将网站程序或者网页文件上传到该目录。 | 读写权限 |
| /myfolder | 此目录中的内容不会被Web用户看到,可以临时存放一些不愿公开的内容。例如,站点备份和数据库备份。 | 读写权限 |
| /php_upload_tmp | 系统程序php上传缓存文件的目录,例如session等信息。 | 读写权限 |
| /wwwlogs | www访问日志的存放位置。 | 只读权限 |
通过Web方式上传文件的大小限制是多少?
轻云服务器和独享云虚拟主机
网站程序语言
Windows操作系统
Linux操作系统
ASP
10 MB
不涉及
ASP.NET
30 MB
不涉及
PHP
2 MB
200 MB
共享云虚拟主机
网站程序语言
Windows操作系统
Linux操作系统
ASP
2 MB
不涉及
ASP.NET
30 MB
不涉及
PHP
2 MB
200 MB
为什么通过FTP客户端无法修改Windows操作系统云虚拟主机的文件权限?
Windows操作系统云虚拟主机默认已经为IIS进程用户分配对应的完全控制权,不支持您通过FTP客户端修改文件权限。
云虚拟主机的开放端口主要有哪些?
云虚拟主机支持对外开放的端口有21端口、80端口以及443端口。各端口说明如下所示:
端口 | 服务 | 说明 |
21 | FTP | FTP服务所开放的端口,用于上传和下载文件。 |
80 | HTTP | 用于HTTP服务提供对外访问功能的端口。例如IIS、Apache、Nginx等服务。 |
443 | HTTPS | 用于HTTPS服务提供网页浏览的端口,HTTPS是一种能提供加密和通过安全端口传输的一种协议。 |
FTP无法连接云虚拟主机时如何排查?
当您通过FTP方式无法连接云虚拟主机时,可以从以下几个方面排查:
检查FTP连接方式。
建议您使用更安全、功能更完善的FTP客户端连接云虚拟主机,例如FileZilla或者CuteFTP。具体操作,请参见通过FileZilla管理网站程序文件和通过CuteFTP管理网站程序文件。
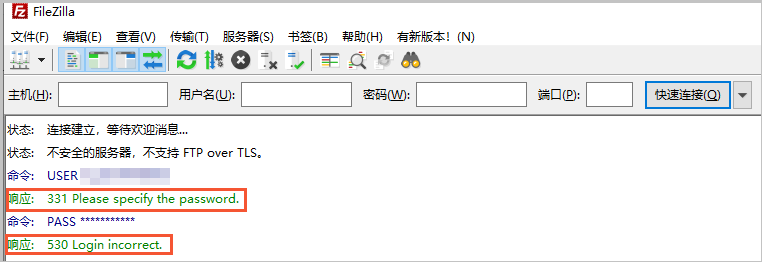
检查FTP客户端报错信息。
报错信息为331 Please specify the password或者530 Login incorrect,说明FTP登录密码不正确,请重新输入密码。
 说明
说明如果您忘记密码,请在主机管理控制台重置密码。具体操作,请参见重置主机管理控制台密码和FTP密码。
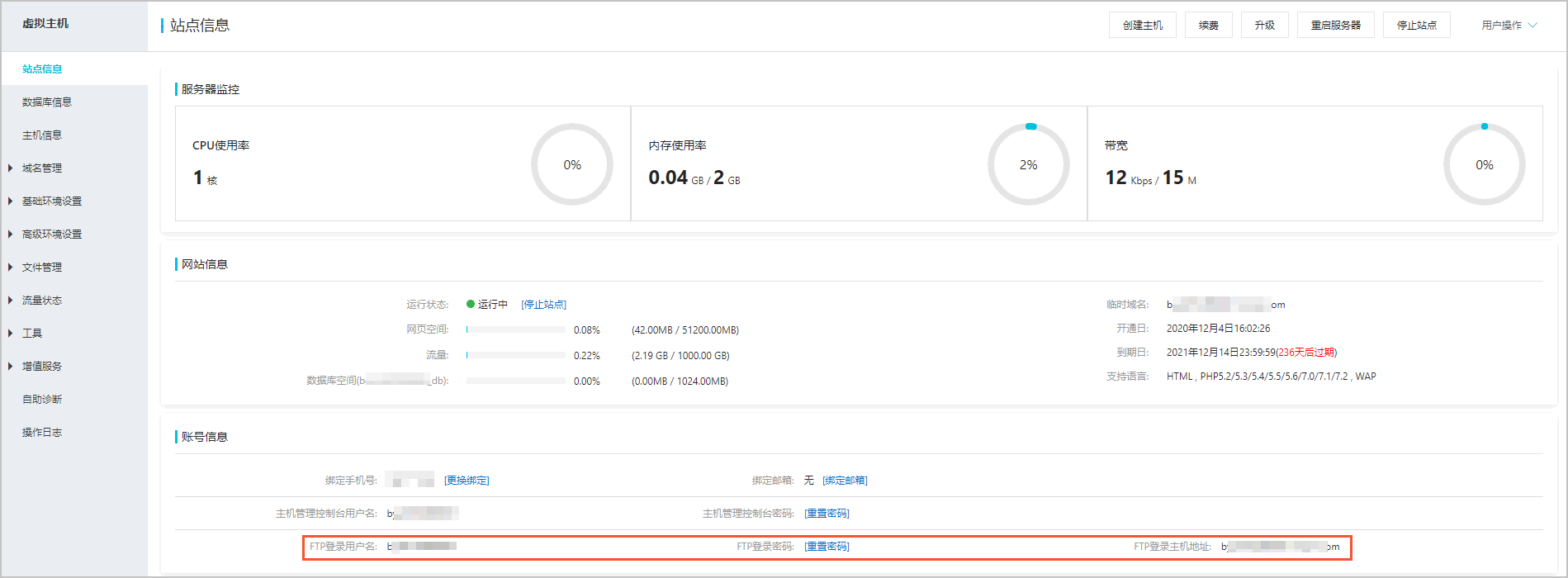
检查FTP登录信息。
您可以在主机管理控制台的站点信息页面获取FTP登录信息,然后查看在FTP客户端中输入的信息是否正确。
检查网络状况。
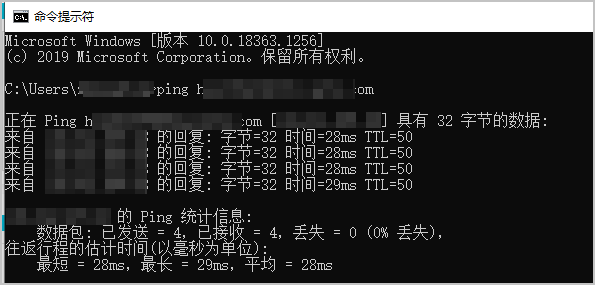
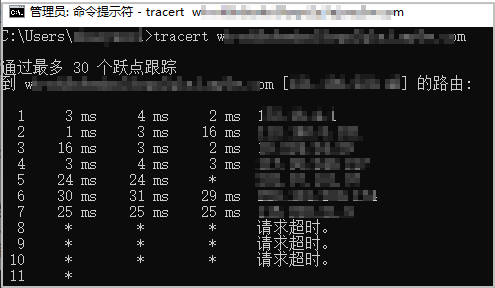
通过Ping命令,检查网络是否能够正确连接至云虚拟主机FTP地址。
回显如下图所示时,表示网络状况正常,可以连接到FTP地址。
如果执行Ping命令后,无法显示如上图所示时,表示网络状态异常,请通过tracert命令,进行路由跟踪检测,判断网络异常的故障位置。
执行tracert命令:
tracert 云虚拟主机FTP地址回显如下图所示时,表示网络状况异常,根据数据包在网络上的停止位置,判断故障位置。
 说明
说明如果您的网络异常情况自己仍无法解决,请您提交工单联系阿里云技术支持。
FTP客户端连接云虚拟主机时有哪些常见报错?
报错信息 | 可能原因 | 解决方案 |
530 Login incorrect |
|
|
USER anonymous | 设置FTP连接时,设置的登录类型为匿名。 | 在FTP连接设置中,将登录类型修改为正常。 |
426 Data connection closed, transfer aborted | 网络或本地主机的防火墙对端口做了限制。 |
|
AUTH TLS | FTP客户端要求云虚拟主机对FTP进行了会话加密的方式。 | FTP连接设置时,在协议区域中选择FTP-文件传输协议,在加密区域中选择只使用明文FTP(不安全)。 |
EAI_NONAME - 未提供,或不知道节点名或服务名 | FTP登录主机地址错误,例如主机地址输入错误、多空格等原因。 | 确认FTP登录主机地址准确无误。 |
更多常见报错问题,请参见使用FTP连接主机提示Connection refused报错、使用FileZilla连接站点时出现乱码和使用FileZilla连接云虚拟主机报错。
为什么FTP传输速度慢?
FTP传输涉及FTP客户端和FTP服务器,因此传输速度慢可能有如下原因:
在中国内地访问其他国家和地区地域下的云虚拟主机,受到国际链路拥塞影响。
FTP服务器端资源消耗过多,系统运行慢。
FTP服务器端网络收到DDoS攻击,导致网络不稳定。
FTP客户端网络带宽低,导致网络不稳定。
传输中的文件太大,长时间占用FTP服务器资源。
传输文件数量多,某些文件传输失败。
您可以参考以下方法排查和解决问题:
退款其他国家和地区地域下的云虚拟主机,再重新购买中国内地的云虚拟主机。
重启FTP客户端。
使用其他FTP客户端软件上传文件。
检查您的网络状况,根据排查结果具体分析解决。
将文件压缩后再上传至云虚拟主机。
为什么使用IE作为客户端无法连接FTP服务器?
可能原因:客户端没有公网IP时,默认只能通过PASV方式连接FTP服务器,因此采用IE作为客户端(默认使用PORT方式)连接FTP服务器,会导致连接失败。
解决方法:
如果IE浏览器版本为6.0及以上,具体操作如下:
打开IE浏览器。
在右上角菜单栏中,选择。
在Internet选项页面,单击高级。
在高级页签下的设置区域,选中使用被动FTP(用于防火墙和DSL调制解调器的兼容)。
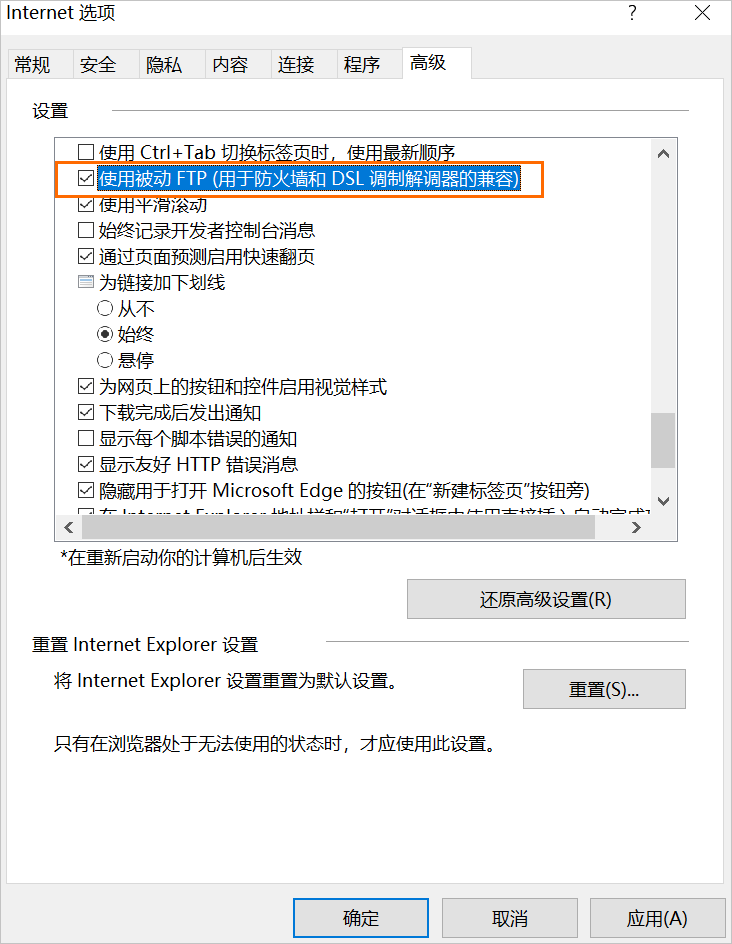
单击确定。
如果IE浏览器版本为6.0以下,或者使用IE连接FTP服务器时无法看到连接信息,出错原因也无法快速定位。推荐您使用FileZilla或CuteFTP等其他FTP客户端软件来连接FTP服务器。
共享云虚拟主机上的网站被DDoS攻击后收到关停邮件时如何处理?
使用共享虚拟主机时,收到类似如下格式的关停通知邮件时,建议按照本文解决方案处理。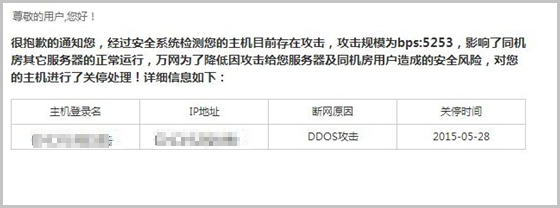
如果网站存在违法违规信息,阿里云对违法违规信息的网站域名也会进行访问屏蔽,导致网站被关停。您需要查看具体的违法违规信息,并对违法违规信息进行整改处理,最后申请解除访问屏蔽。具体操作,请参见域名存在违法违规信息如何处理。
解决方法:
场景描述 | 解决方法 |
共享云虚拟主机上的网站共享同一个IP,即同一个IP下存在多个网站。如果其中一个网站被攻击,则会导致同IP下所有网站被暂时关停。 说明 系统关停时间在30分钟到24小时之间。 | 您无需进行操作,耐心等待系统自动解封后继续使用。 系统会根据攻击类型自动对应不同的解封时间并自动解封网站,同时安全系统仍然会继续检测,如果攻击仍然存在或者解封之后又遭到DDoS攻击,系统会再次按照同样的规则进行处理。 |
DDoS攻击基本是针对共享IP的4层攻击,目前无法精确定位到哪一个绑定在IP中的网站被攻击,导致同IP下所有网站被同时关停。 | 为了避免由于绑定在同一个IP的其他域名被攻击,您可以考虑使用独立IP的独享云虚拟主机,独享云虚拟主机的安全策略相对共享云虚拟主机安全性较高。具体操作,请参见升级云虚拟主机。 |
在共享云虚拟主机断网关停期间,会导致FTP工具无法正常使用,您无法通过FTP工具直接下载备份数据。 | 如果需要备份网站程序,建议您使用共享主机IP的相邻IP连接FTP工具来下载备份数据。 例如,被攻击关停的云虚拟主机IP为127.0.0.1,连接FTP工具时可使用127.0.0.2进行连接(登录名和密码不变)。 |
网站被黑或被网信办通告如何处理?
可能原因:一般是因为网站程序内部存在漏洞,导致网站首页被篡改,网站被黑客攻击。
解决方法:
登录云虚拟主机管理控制台进行网站的数据备份,具体操作,请参见备份和恢复数据。
查看网站访问日志分析漏洞原因并进行整改,查看访问日志的具体操作,请参见下载或删除网站日志。
例如,在程序中发现存在挂马的代码,直接删除或将源程序重新上传至云虚拟主机,您也可以咨询程序开发人员直接定位并解决该问题。
如果问题反复出现,建议您接入阿里云的Web应用防火墙(Web Application Firewall,简称WAF)产品,WAF产品为您的网站或App业务提供一站式安全防护。更多信息,请参见什么是Web应用防火墙和使用教程。
说明WAF的所有版本都支持独享云虚拟主机,直接开通WAF进行配置即可。
共享云虚拟主机由于使用的是共享IP,源站由多个用户共同使用,不建议单独配置WAF。建议您将共享云虚拟主机升级为独享云虚拟主机,具体操作,请参见升级云虚拟主机。
如何通过Robots协议屏蔽搜索引擎抓取网站内容?
Robots协议(也称为爬虫协议、机器人协议等)的全称是网络爬虫排除标准(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。避免出现网站被爬虫访问,导致耗费大量流量和宽带的问题。关于Robots协议的更多信息,请您自行查阅了解。
robots.txt文件的参数配置说明
如果有些网站页面访问消耗性能比较高,不希望被搜索引擎抓取,您可以在站点根目录下存放robots.txt文件,屏蔽搜索引擎或者设置搜索引擎可以抓取文件的范围以及规则。robots.txt文件的参数配置说明如下:
Robots协议不是强制协议,通过robots.txt文件能够保护您的一些文件不暴露在搜索引擎之下,从而有效地控制爬虫的抓取路径。但是,部分搜索引擎或者伪装成搜索引擎的爬虫不会遵守该协议,对于不遵守该协议的情况,以下处理方法无效。
参数 | 说明 |
| 搜索引擎的种类。其中, 说明 关于搜索引擎和User-Agent的对应关系,更多信息,请参见搜索引擎和User-agent的对应关系。 |
| 禁止爬取admin目录下面的目录。 |
| 禁止爬取require目录下面的目录。 |
| 禁止爬取ABC目录下面的目录。 |
| 禁止访问/cgi-bin/目录下的所有以 |
| 禁止访问网站中所有包含问号(?)的网址。 |
| 禁止抓取网页所有 |
| 禁止爬取ab目录下面的 |
| 允许爬取cgi-bin目录下面的目录。 |
| 允许爬取tmp整个目录。 |
| 仅允许访问以 |
| 允许抓取网页和 |
| 网站地图,告诉爬虫这个页面是网站地图。 |
常见搜索引擎和User-agent的对应关系
搜索引擎 | User-Agent(搜索引擎种类) |
Baidu | Baiduspider |
Googlebot | |
Yahoo Web Pages | Googlebot |
Netscape | Googlebot |
AltaVista | Scooter |
Infoseek | Infoseek |
Hotbot | Slurp |
AOL Search | Slurp |
Goto | Slurp |
MSN | Slurp |
Iwon | Slurp |
LooksmartWebPages | Slurp |
Excite | ArchitextSpider |
WebCrawler | ArchitextSpider |
Lycos | Lycos |
NorthernLight | Gulliver |
Fast | Fast |
DirectHit | Grabber |
操作示例
本部分以下面场景为例,为您展示通过Robots协议屏蔽搜索引擎抓取网站内容的方法,操作示例如下所示。
示例一:执行以下命令,禁止所有搜索引擎访问网站的任何资源。
User-agent: * Disallow: /示例二:执行以下命令,允许所有搜索引擎访问任何资源。
User-agent: * Allow: /说明您也可以建一个
/robots.txt空文件,将Allow的值设置为/robots.txt。示例三:执行以下命令,禁止某个搜索引擎(例如Google)访问网站。
User-agent: Googlebot Disallow: /示例四:执行以下命令,允许某个搜索引擎(例如Baidu)访问网站。
User-agent: Baiduspider allow: /示例五:执行以下命令,禁止所有搜索引擎访问特定目录。
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /data/示例六:执行以下命令,允许访问特定目录中的部分URL,实现
a目录下只有b.htm允许访问。User-agent: * Allow: /a/b.htm Disallow: /a/
如何防止黑客攻击云虚拟主机上的网站?
如果网站程序内部存在漏洞,网站很容易受到黑客的攻击,即网站存在安全风险。建议您提前采取措施防止黑客攻击云虚拟主机上的网站,常用解决方案如下所示:
遵循密码(包括会员密码、FTP密码、邮箱密码、数据库密码、后台管理密码等)设置的安全原则。
安全密码必须是8~30个字符,其中必须包括大写字母、小写字母和数字。如果有特殊字符相对更安全,例如
d9C&v6Q0形式的密码比较安全。建议每隔几个月定时更换一次密码,保证密码的安全性。
注意及时清空您的临时文件、上网拨号的时候不选择保存密码、在浏览网页输入密码时不选择让浏览器记住您的密码等。
建议不要使用无组件上传方式。因为该方式很容易导致网站被黑客上传木马,对网站进行恶意破坏。
建议在后台管理入口环节添加验证码,避免黑客通过程序方式暴力破解。
Access数据库后缀不要使用
.mdb,建议使用.asp或.asa,避免被黑客下载。数据库名称建议以
#开头命名,存放的目录名称也建议设置复杂一些,避免黑客猜测到存放的目录名称。
如何提高网站安全性?
建议从以下几点提高网站安全性:
请妥善保管好网站后台管理系统的用户名和密码。
如果暂时不需要使用云虚拟主机上的FTP功能,建议及时关闭该功能。具体操作,请参见开启和关闭FTP功能。
定时更换主机控制台密码、FTP登录密码以及数据库密码。
云虚拟主机的网页空间显示已满如何处理?
可能原因:网站访问量日渐增长、网站应用程序或者网页文件过大,导致网页空间已满,从而影响了网站的正常运行。
解决方法:您可以参考以下方法解决问题。
清理网站中不必要的网站文件。例如,不重要的数据、图片或者帖子等。
增加云虚拟主机的网页空间。针对共享云虚拟主机,您可以额外购买网页空间,具体操作,请参见增加共享云虚拟主机的网页空间。
升级云虚拟主机。如果云虚拟主机支持升级功能,您可以通过升级云虚拟主机来增加网页空间,具体操作,请参见升级云虚拟主机。
如何将网站切换为仅使用静态文件模式?
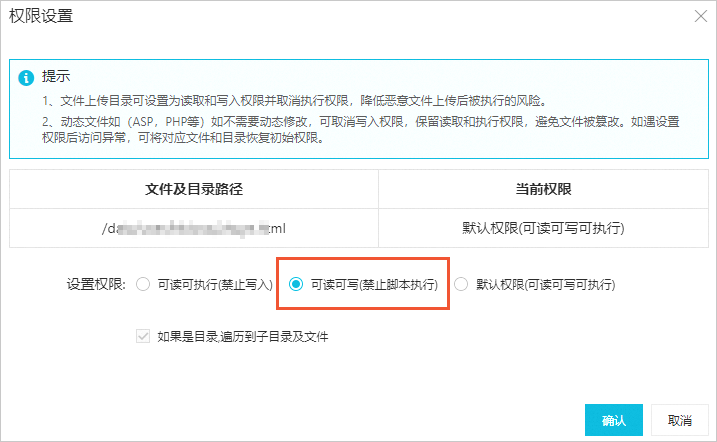
由于云虚拟主机中的PHP环境无法直接关闭,如果搭建在云虚拟主机上的网站仅需要使用纯静态文件(即没有PHP等需要在云虚拟主机中执行的动态程序),则您可以设置权限将网站切换为仅使用静态文件的模式。
在设置权限前,请确保网站的动态文件已全部转化为静态文件(例如HTML、CSS或图片等)。