MaxCompute支持您在项目中创建OSS(Object Storage Service)外部表,与存储服务OSS上的目录建立映射关系,您可以通过OSS外部表访问OSS目录下的数据文件中的非结构化数据,或将MaxCompute项目中的数据写入OSS目录。本文为您介绍创建、读取和写入OSS外部表的语法,以及参数信息。
前提条件
已具备访问OSS的权限。阿里云账号(主账号)、RAM用户或RAMRole身份可以访问OSS外部表,授权信息请参见OSS的STS模式授权。
(可选)已准备好OSS存储空间(Bucket)、OSS目录及OSS数据文件。具体操作请参见创建存储空间、管理目录和简单上传。
MaxCompute已支持在OSS侧自动创建目录,对于携带外部表及UDF的SQL语句,您可以通过一条SQL语句执行读写外部表及UDF的操作。原手动创建目录方式仍然支持。
已创建MaxCompute项目。具体操作请参见创建MaxCompute项目。
由于MaxCompute只在部分地域部署,跨地域的数据连通性可能存在问题,因此建议Bucket与MaxCompute项目所在地域保持一致。
已具备在MaxCompute项目中创建表(CreateTable)的权限。表操作的权限信息请参见MaxCompute权限。
注意事项
OSS外部表只是记录与OSS目录的映射关系。当删除OSS外部表时,不会删除映射的OSS目录下的数据文件。
OSS数据文件类型为归档文件时,需要先解冻文件。
请使用OSS经典网络域名。对于公网的网络域名,MaxCompute不保证网络连通性。
使用限制
OSS外部表不支持cluster属性。
单个文件大小不能超过3 GB,如果文件过大,建议拆分。
操作入口
MaxCompute支持通过以下平台创建OSS外部表、对外部表执行读取和写入操作。
方式 | 平台 |
基于MaxCompute SQL的方式 | |
可视化方式 |
创建OSS外部表
OSS外部表分为分区表和非分区表,具体类型需要根据数据文件在OSS中的存储路径选择。当数据文件以分区路径方式存储时,需要创建分区表,否则创建非分区表。
注意事项
对于不同格式的数据文件,创建OSS外部表语句在个别参数设置上会不同,请根据创建OSS外部表语法及参数说明创建符合业务需求的外部表,否则读取OSS数据或将数据写入OSS操作时会执行失败。
语法说明
场景:通过内置文本数据解析器创建外部表
语法格式
数据文件格式
示例
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name> ( <col_name> <data_type>, ... ) [comment <table_comment>] [partitioned BY (<col_name> <data_type>, ...)] stored BY '<StorageHandler>' WITH serdeproperties ( ['<property_name>'='<property_value>',...] ) location '<oss_location>';支持读取或写入OSS的数据文件格式:
CSV
TSV
以GZIP、SNAPPY或LZO方式压缩的CSV、TSV
场景:通过内置开源数据解析器创建外部表
语法格式
数据文件格式
示例
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name> ( <col_name> <data_type>, ... ) [comment <table_comment>] [partitioned BY (<col_name> <data_type>, ...)] [row format serde '<serde_class>' [WITH serdeproperties ( ['<property_name>'='<property_value>',...]) ] ] stored AS <file_format> location '<oss_location>' [USING '<resource_name>'] [tblproperties ('<tbproperty_name>'='<tbproperty_value>',...)];支持读取或写入OSS的数据文件格式:
PARQUET
TEXTFILE
ORC
RCFILE
AVRO
JSON
SEQUENCEFILE
Hudi(仅支持读取DLF生成的Hudi数据)
以ZSTD、SNAPPY或GZIP方式压缩的PARQUET
以SNAPPY、ZLIB方式压缩的ORC
以GZIP、SNAPPY、LZO方式压缩的TEXTFILE
场景:通过自定义解析器创建外部表
语法格式
数据文件格式
示例
CREATE EXTERNAL TABLE [IF NOT EXISTS] <mc_oss_extable_name> ( <col_name> <date_type>, ... ) [comment <table_comment>] [partitioned BY (<col_name> <data_type>, ...)] stored BY '<StorageHandler>' WITH serdeproperties ( ['<property_name>'='<property_value>',...] ) location '<oss_location>' USING '<jar_name>';支持读取或写入OSS的数据文件格式:除上述格式外的数据文件。
参数说明
以下为各类格式外表的公共参数说明,您可以在对应格式的文档中查看并使用其独有参数。
基础语法参数说明
参数名称
是否必填
说明
mc_oss_extable_name
是
待创建的OSS外部表的名称。
表名大小写不敏感,在查询外部表时,无需区分大小写,且不支持强制转换大小写。
col_name
是
OSS外部表的列名称。
在读取OSS数据场景,创建的OSS外部表结构必须与OSS数据文件结构保持一致,否则无法成功读取OSS数据。
data_type
是
OSS外部表的列数据类型。
在读取OSS的数据场景,OSS外部表各列数据类型必须与OSS数据文件各列数据类型保持一致,否则无法成功读取OSS数据。
table_comment
否
表注释内容。注释内容为长度不超过1024字节的有效字符串,否则报错。
partitioned by (col_name data_type, ...)
否
当OSS中的数据文件是以分区路径方式存储时,需要携带该参数,创建分区表。
col_name:分区列名称。
data_type:分区列数据类型。
'<(tb)property_name>'='<(tb)property_value>'
是
OSS外部表扩展属性,参数详解见各格式文档独有参数。
oss_location
是
数据文件所在OSS路径。默认读取该路径下的所有数据文件。
格式为
oss://<oss_endpoint>/<Bucket名称>/<OSS目录名称>/。oss_endpoint:
OSS访问域名信息。需要使用OSS提供的经典网络域名,即带
-internal的endpoint。例如
oss://oss-cn-beijing-internal.aliyuncs.com/xxx。更多OSS经典网络域名信息,请参见OSS地域和访问域名。
建议数据文件存放的OSS地域与MaxCompute项目所在地域保持一致。如果跨地域,数据连通性可能存在问题。
不写endpoint。系统会默认补充一个当前Project所在地域的endpoint。
不推荐这种方式,如果文件存储跨地域,可能存在数据连通性问题。
Bucket名称:OSS存储空间名称。
例如
oss://oss-cn-beijing-internal.aliyuncs.com/your_bucket/path/。更多查看存储空间名称信息,请参见列举存储空间。
目录名称:OSS目录名称。目录后不需要指定文件名。
例如
oss://oss-cn-beijing-internal.aliyuncs.com/oss-mc-test/Demo1/。错误示例:
-- 不支持HTTP连接。 http://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 不支持HTTPS连接。 https://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/ -- 连接地址错误。 oss://oss-cn-shanghai-internal.aliyuncs.com/Demo1 -- 不需要指定文件名。 oss://oss-cn-shanghai-internal.aliyuncs.com/oss-mc-test/Demo1/vehicle.csv权限规范(RamRole):
显示指定(推荐):创建自定义角色并绑定权限策略,使用该自定义角色的ARN信息,创建详情请参见STS模式授权。
使用Default(不推荐):使用
aliyunodpsdefaultrole角色的ARN信息。
WITH serdeproperties属性
property_name
使用场景
property_value
默认值
odps.properties.rolearn
使用STS模式授权时,请添加该属性。
指定RAM中Role(具有访问OSS权限)的ARN信息。您可以通过RAM控制台中的角色详情进行获取。示例如下
acs:ram::xxxxxx:role/aliyunodpsdefaultrole。当MaxCompute和OSS的Owner是同一个账号时:
若建表语句中不写
odps.properties.rolearn,默认使用aliyunodpsdefaultrole角色的ARN信息。若您想用自定义角色的ARN信息,需要提前创建自定义角色,创建详情请参见OSS的STS模式授权(方式二)。
当MaxCompute和OSS的Owner不是同一个账号时,您需要填写自定义角色的ARN信息,创建详情请参见OSS的STS模式授权(方式三)。
补全OSS外部表分区数据语法
创建的OSS外部表为分区表时,需要额外执行引入分区数据的操作,具体如下。
方式一(推荐):自动解析OSS目录结构,识别分区,为OSS外部表添加分区信息。
该方式适用于一次性补全全部缺失的历史分区的场景。MaxCompute会根据您创建OSS外部表时指定的分区目录,自动补全OSS外部表的分区,而不用逐个按照分区列名和名称增加。
MSCK REPAIR TABLE <mc_oss_extable_name> ADD PARTITIONS [ WITH properties (key:VALUE, key: VALUE ...)];该方式不适用于处理增量数据的补充,尤其是在OSS目录中包含大量分区(如超过1000个)的情况下。当新增的分区远少于已有分区时,频繁使用
msck命令会导致对OSS目录大量的重复扫描和元数据更新情况,从而降低命令执行的效率。对于需要更新增量分区的场景,建议采用方式二。方式二:手动执行命令为OSS外部表添加分区信息。
该方式适用于历史分区已经创建完成,需要频繁地周期性追加分区的场景。在执行数据写入任务之前创建好分区,即使OSS上有新数据写入,也不需要刷新对应分区,外部表即可读取OSS目录上的最新数据。
ALTER TABLE <mc_oss_extable_name> ADD PARTITION (<col_name>=<col_value>)[ ADD PARTITION (<col_name>=<col_value>)...][location URL];col_name和col_value的值需要与分区数据文件所在目录名称对齐。
假设,分区数据文件所在的OSS目录结构如下图,col_name对应
direction,col_value对应N、NE、S、SW、W。一个add partition对应一个子目录,多个OSS子目录需要使用多个add partition。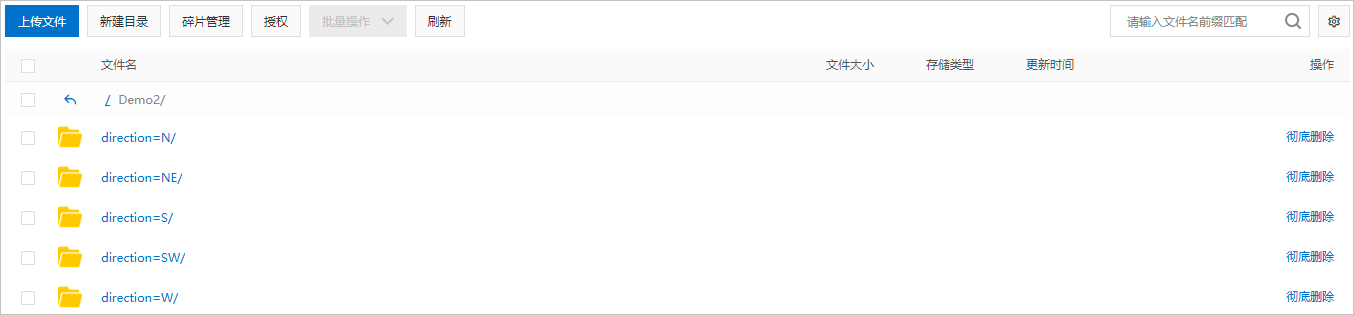
读取OSS数据
注意事项
创建好OSS外部表后,才可以通过外部表读取OSS数据。MaxCompute支持的OSS数据文件类型及创建OSS外部表语法,请参见语法说明。
SQL语句中涉及到复杂数据类型时,需要在SQL语句前添加
set odps.sql.type.system.odps2=true;命令,然后一起提交执行。数据类型相关信息请参见数据类型版本说明。对于映射开源数据的OSS外部表,需要在Session级别设置
set odps.sql.hive.compatible=true;后再读取OSS数据,否则会报错。OSS对外提供的带宽资源有限,若短时间内数据读写流量超过实例带宽上限,会直接影响OSS外表的数据读写速度。关于OSS带宽详情,请参见使用限制及性能指标。
语法说明
<select_statement> FROM <from_statement>;select_statement:
SELECT子句,从源表中查询需要插入目标表的数据。from_statement:
FROM子句,数据来源,如外表名称。
非分区数据
创建OSS外部表(非分区表)后,读取OSS数据方式如下:
方式一(推荐):将OSS的开源格式数据导入MaxCompute内部表,然后再读取OSS数据。
该方式适用于需要对数据进行反复计算或对计算性能要求高的场景。通过在MaxCompute项目中创建与OSS外部表Schema相同的内部表,将OSS数据导入该内部表后执行复杂查询,可充分利用MaxCompute针对内部存储的优化机制,提升计算性能。命令示例如下:
CREATE TABLE <table_internal> LIKE <mc_oss_extable_name>; INSERT OVERWRITE TABLE <table_internal> SELECT * FROM <mc_oss_extable_name>;方式二:与MaxCompute内部表的操作一致,直接读取OSS数据。
该方式适用于对计算性能要求不高的场景。与读取内部表不同的是,每次读取数据都是直接从OSS读取对应的数据。
分区数据
创建OSS外部表后,MaxCompute会全量扫描OSS目录下的所有数据,包括子目录下的数据文件。当数据量较大时,对全量目录扫描会产生不必要的I/O消耗以及数据处理时间。解决该问题有如下两种方式。
方式一(推荐):在OSS上将数据以标准分区路径或自定义分区路径方式存储。
创建OSS外部表时,需要在建表语句中指定分区及oss_location信息。推荐使用标准分区路径存储OSS数据。
方式二:规划多个数据存放路径。
创建多个OSS外部表读取各个路径下的数据,即每个OSS外部表指向OSS数据的一个子集。该方式操作繁琐,数据管理效果不佳,不推荐使用。
标准分区路径格式
oss://<oss_endpoint>/<Bucket名称>/<目录名称>/<partitionKey1=value1>/<partitionKey2=value2>/...示例:某公司会将每天产生的Log文件以CSV格式存放在OSS上,并通过MaxCompute以天为周期处理数据。则存储OSS数据的标准分区路径应设置如下。
oss://oss-odps-test/log_data/year=2016/month=06/day=01/logfile
oss://oss-odps-test/log_data/year=2016/month=06/day=02/logfile
oss://oss-odps-test/log_data/year=2016/month=07/day=10/logfile
oss://oss-odps-test/log_data/year=2016/month=08/day=08/logfile
...自定义分区路径格式
自定义分区路径格式:只有分区列值,没有分区列名。示例如下:
oss://oss-odps-test/log_data_customized/2016/06/01/logfile
oss://oss-odps-test/log_data_customized/2016/06/02/logfile
oss://oss-odps-test/log_data_customized/2016/07/10/logfile
oss://oss-odps-test/log_data_customized/2016/08/08/logfile
...OSS的数据已按照分区方式存储,但其路径并非标准分区路径格式,MaxCompute支持将不同的子目录绑定至不同的分区,从而访问子目录数据。
实现方案:创建OSS外部表后,通过alter table ... add partition ... location ...命令指定子目录,将不同的子目录绑定到不同的分区,命令示例如下。
ALTER TABLE log_table_external ADD PARTITION (year = '2016', month = '06', day = '01')
location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/bucket名称/oss-odps-test/log_data_customized/2016/06/01/';
ALTER TABLE log_table_external ADD PARTITION (year = '2016', month = '06', day = '02')
location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/bucket名称/oss-odps-test/log_data_customized/2016/06/02/';
ALTER TABLE log_table_external ADD PARTITION (year = '2016', month = '07', day = '10')
location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/bucket名称/oss-odps-test/log_data_customized/2016/07/10/';
ALTER TABLE log_table_external ADD PARTITION (year = '2016', month = '08', day = '08')
location 'oss://oss-cn-hangzhou-internal.aliyuncs.com/bucket名称/oss-odps-test/log_data_customized/2016/08/08/';查询优化
动态统计信息收集
由于数据存储在外部数据湖且缺乏预先统计信息,查询优化器采用保守策略,查询效率低。动态统计信息收集功能支持Optimizer在Query执行中临时统计表的Stats来发现小表,并主动采用Hash Join、优化Join Order、减少Shuffle和缩短执行的Pipeline等方法,实现查询优化。
SET odps.meta.exttable.stats.onlinecollect=true; SELECT * FROM <tablename>;外表Split优化
通过设置split size参数调整单个并发处理的数据大小,从而优化查询效率。其中split size的设置有如下影响。
表数据量非常大,每次读取的数据太少,会导致split数太多,并行度多大,Instance大多数时间在排队等资源。
表数据量非常小,每次读取的数据太多,会导致split数太少,并发不够,大部分资源都空闲。
SET odps.stage.mapper.split.size=<value>; SELECT * FROM <tablename>;
将数据写入OSS
与读取OSS数据类似,MaxCompute支持将内部表数据或处理外部表得到的数据写入OSS。
通过内置文本或开源数据解析器将数据写入OSS:CSV/TSV外部表、CSV/TSV外部表、CSV/TSV外部表、通过内置开源数据解析器将数据写入OSS。
通过自定义解析器将数据写入OSS:示例:通过自定义解析器创建OSS外部表。
通过OSS分片上传功能将数据写入OSS:通过OSS分片上传功能将数据写入OSS。
语法说明
INSERT {INTO|OVERWRITE} TABLE <table_name> PARTITION (<ptcol_name>[, <ptcol_name> ...])
<select_statement> FROM <from_statement>;参数名 | 是否必填 | 描述 |
table_name | 是 | 要写入的外表名称。 |
select_statement | 是 |
|
from_statement | 是 |
|
如果需要向动态分区中插入数据,请参考插入或覆写动态分区数据(DYNAMIC PARTITION)。
注意事项
如果
INSERT OVERWRITE ... SELECT ... FROM ...;操作在源数据表from_tablename上分配了1000个Mapper,则最后将产生1000个TSV或CSV文件。可以通过MaxCompute提供的配置控制生成文件的数量。
Outputer在Mapper里:通过
odps.stage.mapper.split.size控制Mapper的并发数,从而调整生成的文件数量。Outputer在Reduce或Joiner里:分别通过
odps.stage.reducer.num和odps.stage.joiner.num来调整生成的文件数量。
通过OSS分片上传功能将数据写入OSS
当需要将数据以开源格式写入OSS时,可以通过基于开源数据解析器创建的OSS外部表及OSS的分片上传功能,执行INSERT操作将数据写入OSS。
开启OSS分片上传功能设置如下:
场景 | 命令 |
在Project级别设置 | 整个Project生效。 |
在Session级别设置 | 只对当前任务生效。 |
属性odps.sql.unstructured.oss.commit.mode默认取值为false,不同取值时的实现原理如下:
取值 | 原理 |
false | MaxCompute写入到OSS外部表的数据,会存储在LOCATION目录下的.odps文件夹中。.odps文件夹中维护了一个.meta文件,用于保证MaxCompute数据的一致性。.odps的内容只有MaxCompute能正确处理,在其他数据处理引擎中可能无法正确解析,从而报错。 |
true | MaxCompute使用分片上传功能,兼容其他数据处理引擎。以 |
导出文件管理
参数说明
当需要为写入OSS的数据文件添加前缀、后缀或者扩展名时,可以通过如下参数设置。
property_name | 使用场景 | 说明 | property_value | 默认值 |
odps.external.data.output.prefix (兼容odps.external.data.prefix) | 当需要添加输出文件的自定义前缀名时,请添加该属性。 |
| 符合条件的字符组合,例如'mc_' | 无 |
odps.external.data.enable.extension | 当需要显示输出文件的扩展名时,请添加该属性。 | True表示显示输出文件的扩展名,反之不显示扩展名。 |
| False |
odps.external.data.output.suffix | 当需要添加输出文件的自定义后缀名时,请添加该属性。 | 仅包含数字,字母,下划线(a-z, A-Z, 0-9, _)。 | 符合条件的字符组合,例如'_hangzhou' | 无 |
odps.external.data.output.explicit.extension | 当需要添加输出文件的自定义扩展名时,请添加该属性。 |
| 符合条件的字符组合,例如"jsonl" | 无 |
使用示例
为写入OSS的文件自定义前缀为
test06_,DDL如下所示:CREATE EXTERNAL TABLE <mc_oss_extable_name> ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongitude DOUBLE, recordTime STRING, direction STRING ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/***/' TBLPROPERTIES ( -- 设置自定义前缀。 'odps.external.data.output.prefix'='test06_') ; -- 向外表写入数据。 INSERT INTO <mc_oss_extable_name> VALUES (1,32,76,1,63.32106,-92.08174,'9/14/2014 0:10','NW');写入后生成的文件如下图所示:

为写入OSS的文件自定义后缀为
_beijing,DDL如下所示:CREATE EXTERNAL TABLE <mc_oss_extable_name> ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongitude DOUBLE, recordTime STRING, direction STRING ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/***/' TBLPROPERTIES ( -- 设置自定义后缀。 'odps.external.data.output.suffix'='_beijing') ; -- 向外表写入数据。 INSERT INTO <mc_oss_extable_name> VALUES (1,32,76,1,63.32106,-92.08174,'9/14/2014 0:10','NW');写入后生成的文件如下图所示:

为写入OSS的文件自动生成扩展名,DDL如下所示:
CREATE EXTERNAL TABLE <mc_oss_extable_name> ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongitude DOUBLE, recordTime STRING, direction STRING ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/***/' TBLPROPERTIES ( -- 自动生成扩展名。 'odps.external.data.enable.extension'='true') ; -- 向外表写入数据。 INSERT INTO <mc_oss_extable_name> VALUES (1,32,76,1,63.32106,-92.08174,'9/14/2014 0:10','NW');写入后生成的文件如下图所示:
为写入OSS的文件自定义扩展名
jsonl,DDL如下所示:CREATE EXTERNAL TABLE <mc_oss_extable_name> ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongitude DOUBLE, recordTime STRING, direction STRING ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/***/' TBLPROPERTIES ( -- 自定义扩展名。 'odps.external.data.output.explicit.extension'='jsonl') ; -- 向外表写入数据。 INSERT INTO <mc_oss_extable_name> VALUES (1,32,76,1,63.32106,-92.08174,'9/14/2014 0:10','NW');写入后生成的文件如下图所示:

为写入OSS的文件设置前缀为
mc_,后缀为_beijing,扩展名为jsonl,DDL如下所示:CREATE EXTERNAL TABLE <mc_oss_extable_name> ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongitude DOUBLE, recordTime STRING, direction STRING ) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-beijing-internal.aliyuncs.com/***/' TBLPROPERTIES ( -- 自定义前缀。 'odps.external.data.output.prefix'='mc_', -- 自定义后缀。 'odps.external.data.output.suffix'='_beijing', -- 自定义扩展名。 'odps.external.data.output.explicit.extension'='jsonl') ; -- 向外表写入数据。 INSERT INTO <mc_oss_extable_name> VALUES (1,32,76,1,63.32106,-92.08174,'9/14/2014 0:10','NW');写入后生成的文件如下图所示:

以动态分区形式写出大文件
业务场景
需要以分区的形式将上游表的计算结果导出到OSS上,并写出为大文件(如4G)时。
通过配置odps.adaptive.shuffle.desired.partition.size参数(单位MB),可以控制下游每个Reducer读取的数据量及输出文件的大小。但是由于输出大文件会导致并行度降低,进而延长整体执行时间。
参数说明
-- 必须开启动态分区能力。
set odps.sql.reshuffle.dynamicpt=true;
-- 设置期望每个reducer消费的数据,假设希望每个文件是4G。
set odps.adaptive.shuffle.desired.partition.size=4096; 使用示例
向OSS写出大小约4G的json文件。
准备测试数据。公共数据集的表
bigdata_public_dataset.tpcds_1t.web_sales,约30G(以压缩的形式存储在MaxCompute上,导出后存储会增大)。创建JSON外部表。
-- 示例表名:json_ext_web_sales CREATE EXTERNAL TABLE json_ext_web_sales( c_int INT , c_string STRING ) PARTITIONED BY (pt STRING) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::<uid>:role/aliyunodpsdefaultrole' ) STORED AS textfile LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/oss-mc-test/demo-test/';未设置任何参数,将测试表以动态分区的形式写入JSON外部表。
-- 打开三层语法开关。 set odps.namespace.schema=true; -- 向JSON外表以动态分区的形式写入。 INSERT OVERWRITE json_ext_web_sales PARTITION(pt) SELECT CAST(ws_item_sk AS INT) AS c_int, CAST(ws_bill_customer_sk AS string) AS c_string , COALESCE(CONCAT(ws_bill_addr_sk %2, '_', ws_promo_sk %3),'null_pt') AS pt FROM bigdata_public_dataset.tpcds_1t.web_sales;OSS上存储的文件如下图所示:

加上输出大文件的参数
odps.adaptive.shuffle.desired.partition.size,将测试表以动态分区的形式写入JSON外部表。-- 打开三层语法开关。 set odps.namespace.schema=true; -- 必须开启动态分区能力。 set odps.sql.reshuffle.dynamicpt=true; -- 设置期望每个reducer消费的数据,假设希望每个文件是4G。 set odps.adaptive.shuffle.desired.partition.size=4096; -- 向JSON外表以动态分区的形式写入。 INSERT OVERWRITE json_ext_web_sales PARTITION(pt) SELECT CAST(ws_item_sk AS INT) AS c_int, CAST(ws_bill_customer_sk AS string) AS c_string , COALESCE(CONCAT(ws_bill_addr_sk %2, '_', ws_promo_sk %3),'null_pt') AS pt FROM bigdata_public_dataset.tpcds_1t.web_sales;OSS上存储的文件如下图所示:
从OSS导入或导出到OSS
附录:准备示例数据
准备OSS目录
提供的示例数据信息如下:
oss_endpoint:
oss-cn-hangzhou-internal.aliyuncs.com,即华东1(杭州)。Bucket名称:
oss-mc-test。目录名称:
Demo1/、Demo2/、Demo3/和SampleData/。
非分区表数据
Demo1/目录下上传的文件为vehicle.csv,文件中包含的数据信息如下。Demo1/目录用于和通过内置文本数据解析器创建的非分区表建立映射关系。1,1,51,1,46.81006,-92.08174,9/14/2014 0:00,S 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00,NE 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00,W 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00,S 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00,S 1,7,53,1,46.81006,-92.08174,9/15/2014 0:00,N 1,8,63,1,46.81006,-92.08174,9/15/2014 0:00,SW 1,9,4,1,46.81006,-92.08174,9/15/2014 0:00,NE 1,10,31,1,46.81006,-92.08174,9/15/2014 0:00,N分区表数据
Demo2/目录下包含五个子目录direction=N/、direction=NE/、direction=S/、direction=SW/和direction=W/,分别上传的文件为vehicle1.csv、vehicle2.csv、vehicle3.csv、vehicle4.csv和vehicle5.csv,文件中包含的数据信息如下。Demo2/目录用于和通过内置文本数据解析器创建的分区表建立映射关系。--vehicle1.csv 1,7,53,1,46.81006,-92.08174,9/15/2014 0:00 1,10,31,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle2.csv 1,2,13,1,46.81006,-92.08174,9/14/2014 0:00 1,3,48,1,46.81006,-92.08174,9/14/2014 0:00 1,9,4,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle3.csv 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00 1,5,47,1,46.81006,-92.08174,9/14/2014 0:00 1,6,9,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle4.csv 1,8,63,1,46.81006,-92.08174,9/15/2014 0:00 --vehicle5.csv 1,4,30,1,46.81006,-92.08174,9/14/2014 0:00压缩数据
Demo3/目录下上传的文件为vehicle.csv.gz,压缩包内文件为vehicle.csv,与Demo1/目录下的文件内容相同,用于和携带压缩属性的OSS外部表建立映射关系。自定义解析器数据
SampleData/目录下上传的文件为vehicle6.csv,文件中包含的数据信息如下。SampleData/目录用于和通过开源数据解析器创建的OSS外部表建立映射关系。1|1|51|1|46.81006|-92.08174|9/14/2014 0:00|S 1|2|13|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|3|48|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|4|30|1|46.81006|-92.08174|9/14/2014 0:00|W 1|5|47|1|46.81006|-92.08174|9/14/2014 0:00|S 1|6|9|1|46.81006|-92.08174|9/14/2014 0:00|S 1|7|53|1|46.81006|-92.08174|9/14/2014 0:00|N 1|8|63|1|46.81006|-92.08174|9/14/2014 0:00|SW 1|9|4|1|46.81006|-92.08174|9/14/2014 0:00|NE 1|10|31|1|46.81006|-92.08174|9/14/2014 0:00|N
常见问题
通过外部表处理OSS数据时,报错Inline data exceeds the maximun allowed size,如何解决?
问题现象
处理OSS数据时,报错
Inline data exceeds the maximum allowed size。产生原因
OSS Store对于每一个小文件有一个大小限制,如果超过3 GB则报错。
解决措施
针对该问题,您可以通过调整以下两个属性进行处理。其原理是通过属性值调整执行计划,控制每个Reducer写入外部表OSS的数据大小,使得OSS Store文件不超过3 GB的限制。
set odps.sql.mapper.split.size=256; #调整每个Mapper读取数据的大小,单位是MB。 set odps.stage.reducer.num=100; #调整Reduce阶段的Worker数量。
在MaxCompute上访问OSS外部表,编写UDF本地测试通过,上传后报错内存溢出,如何解决?
问题现象
在MaxCompute上访问OSS外部表,编写UDF本地测试通过,上传后返回如下报错。
FAILED: ODPS-0123131:User defined function exception - Traceback: java.lang.OutOfMemoryError: Java heap space设置如下参数后运行时间增加但依然报错。
set odps.stage.mapper.mem = 2048; set odps.stage.mapper.jvm.mem = 4096;产生原因
外部表的对象文件太多,内存占用过大且未设置分区。
解决措施
使用小数据量查询。
将对象文件进行分区,以减少内存占用。
如何通过OSS外部表将多个小文件输出为一个文件?
通过Logview日志,查看SQL的执行计划中最后一个是Reducer还是Joiner。
如果是Reducer,则执行语句
set odps.stage.reducer.num=1;如果是Joiner,则执行语句
set odps.stage.joiner.num=1;
读取OSS外部表时报错Couldn't connect to server,如何解决?
问题现象
读取OSS外部表的数据时,报错
ODPS-0123131:User defined function exception - common/io/oss/oss_client.cpp(95): OSSRequestException: req_id: , http status code: -998, error code: HttpIoError, message: Couldn't connect to server。产生原因
原因一:创建OSS外部表时,oss_location地址中的
oss_endpoint使用了公网地址,未使用内网地址。原因二:创建OSS外部表时,oss_location地址中的
oss_endpoint使用了其他Region的地址。
解决措施
对于原因一:
您需要核查OSS外部表的建表语句中oss_location参数的
oss_endpoint是否为内网地址,如果是公网地址则需要修改为内网地址,具体参数信息请参见参数说明。例如,用户在印度尼西亚(雅加达)地域,使用了
oss://oss-ap-southeast-5.aliyuncs.com/<bucket>/....地址创建外部表,应该改为对应的内网地址oss://oss-ap-southeast-5-internal.aliyuncs.com/<bucket>/....。对于原因二:
您需要核查OSS外部表的建表语句中,oss_location参数的
oss_endpoint是否为要访问的Region的Endpoint,更多OSS经典网络域名信息,请参见OSS地域和访问域名。
创建OSS外部表时报错Network is unreachable (connect failed) ,如何解决?
问题现象
创建OSS外部表时,报错
ODPS-0130071:[1,1] Semantic analysis exception - external table checking failure, error message: Cannot connect to the endpoint 'oss-cn-beijing.aliyuncs.com': Connect to bucket.oss-cn-beijing.aliyuncs.com:80 [bucket.oss-cn-beijing.aliyuncs.com] failed: Network is unreachable (connect failed)。产生原因
创建OSS外部表时,oss_location地址中的
oss_endpoint使用了公网地址,未使用内网地址。解决措施
你需要核查OSS外部表的建表语句中,oss_location参数的
oss_endpoint是否为内网地址。如果是公网地址,则需要修改为内网地址,具体参数信息请参见参数说明。例如,用户在华北2(北京)地域,使用了
oss://oss-cn-beijing.aliyuncs.com/<bucket>/....地址创建外部表,应该改为对应的内网地址oss://oss-cn-beijing-internal.aliyuncs.com/<bucket>/....。
基于OSS外部表执行SQL作业时,运行慢,如何解决?
OSS外部表中的GZ压缩文件读取慢
问题现象
用户创建了一个OSS外部表,数据源为OSS中的GZ压缩文件,大小为200 GB。在读取数据过程中执行缓慢。
产生原因
由于Map端执行计算的Mapper数量过少,所以SQL处理慢。
解决措施
对于结构化数据,您可以设置以下参数调整单个Mapper读取数据量的大小,加速SQL执行。
set odps.sql.mapper.split.size=256; #调整每个Mapper读取Table数据的大小,单位是MB。对于非结构化数据,您需要查看OSS外部表路径下的OSS文件是否只有1个。如果只有1个,由于压缩方式下的非结构化数据不支持拆分,所以只能生产1个Mapper,导致处理速度较慢。建议您在OSS对应的外部表路径下,将OSS大文件拆分为小文件,从而增加读取外部表生成的Mapper数量,提升读取速度。
使用SDK搜索MaxCompute外部表数据速度慢
问题现象
使用SDK搜索MaxCompute外部表数据速度慢。
解决措施
外部表仅支持全量搜索,所以较慢,建议您改用MaxCompute内部表。
通过OSS分片上传功能将数据写入OSS场景下,旧数据被删除,但是新数据未写入,如何解决?
问题现象
insert overwrite操作场景,在极端情况下如果作业运行失败会出现与预期不一致的问题,表现为旧数据被删除,但是新数据并没有写入。产生原因
新写入的数据因为极低概率的硬件故障或元数据更新失败等原因没有成功写入目标表,且OSS的删除操作不支持回滚,导致被删除的旧数据无法恢复。
解决措施
如果基于旧数据再覆写OSS外部表,例如
insert overwrite table T select * from table T;,需要提前做好OSS数据备份,作业运行失败时,再基于备份的旧数据覆写OSS外部表。如果
insert overwrite作业可以重复提交,当作业运行失败时重新提交作业即可。
相关文档
支持的不同格式的OSS外部表:
通过自定义解析器创建OSS外部表并读取写入OSS数据:自定义解析器。
将OSS文件解析为包含Schema的数据集,支持列筛选与加工:特色功能:Schemaless Query。