Delta Table支持增量写入和存储,关键考虑是支持增量查询和计算优化,为此,设计了新的SQL增量查询语法来支持近实时增量处理链路。
增量查询的处理过程
增量查询Delta Table 的处理过程如下图所示。
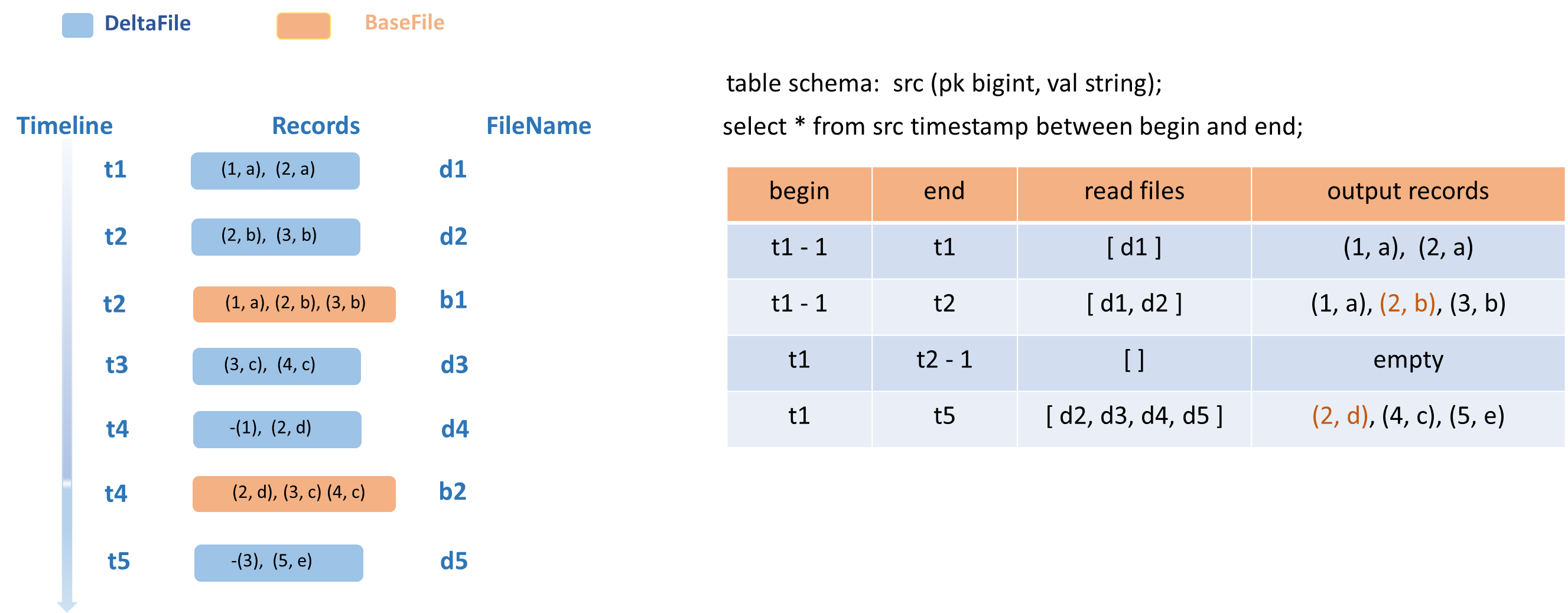
当输入一个SQL语句后,引擎侧会解析用户指定的版本范围查询出来所有符合时间范围内的DeltaFile,进行合并输出。
Clustering和Compaction操作会产生新的数据文件,但不会增加新的逻辑数据行。这些操作只是将原有的记录进行了优化和重组,新生成数据文件中的记录不应被视为新增数据而重复输出。为此,增量查询专门进行了设计优化,以剔除掉这些记录,确保其更符合用户的使用场景。因此,增量查询将只读取指定时间区间内的所有DeltaFile,而不会读取任何BaseFile,并根据指定的策略进行Merge输出。
上图以创建一张事务表(src)为例:
Schema包含pk列和val列。
左边图展示了数据变化过程,t1-t5代表了事务的时间版本,分别执行了5次数据写入的事务,生成了5个DeltaFile。
在t2和t4时刻分别执行了COMPACTION操作,生成了两个BaseFile: b1和b2。
在具体的查询示例中,例如,begin是t1-1,end是t1,只需读取t1时间段对应的DeltaFile:d1进行输出; 如果end是t2,会读取两个DeltaFiles:d1和d2;如果begin是t1,end是t2-1,即查询的时间范围为(t1, t2),这个时间段是没有任何增量数据插入的,会返回空行。
文档内容是否对您有帮助?