
用户对于搜索引擎最关注的两方面一是召回,即满足条件的doc全部可以被召回;二是排序,即在满足条件的文档中将相关度最高的文档优先召回。其中,二往往是需要根据用户的实际业务需求进行调整,因此就需要用户对OpenSearch在排序方面提供的能力有一定的了解,本文将详细介绍OpenSearch在排序方面的能力,并且列举一些常见场景如何通过OpenSearch的排序能力实现。
sort子句与排序策略的关系
简单来说sort子句在OpenSearch中代表全局排序,而排序策略可以理解为sort子句中的一个层级的排序,排序策略是通过系统内置的函数结合表达式形成一种复杂的文档算分逻辑来实现用户复杂的业务场景,但最终参与排序的还是排序策略中表达式算出的最终得分。举个例子,某个业务希望通过文档的新旧程度进行排序,同时新旧程度相同的文档,可以根据文档的相似程度进行二级排序,此时实现用户上述需求,就需要通过sort子句同时结合排序策略,假设用户业务表中有一个字段为create_time,同时检索的字段为name,则可以在sort子句中加入:
sort=-create_time;-RANK同时在基础排序设置static_bm25() 函数,在业务排序中设置text_relevance(name)函数即可。(排序策略的配置步骤参考排序策略配置)。
这里的RANK就表示获取排序策略的得分,而“-” 表示倒序,“+”表示正序。
系统默认在不配置sort子句的情况下用-RANK作为排序条件,而如果配置了sort子句,在需要排序策略分排序的时候需要显示的写入-RANK,否则系统将不会自动引入排序策略分作为排序条件。
为了更形象的表达sort子句和排序策略的关系,这里以一个案例的方式说明:
假设OpenSearch有一个应用,应用结构为:
字段 | 类型 | 索引 |
id | int | 关键字 |
name | text | 中文通用 |
age | int | 关键字 |
为name设置了一个基础排序,表达式内容如下:

为name设置了一个业务排序,表达式内容如下:

同时在检索时,配置sort子句为:
sort=age;-RANK打开排序明细查看算分详情:
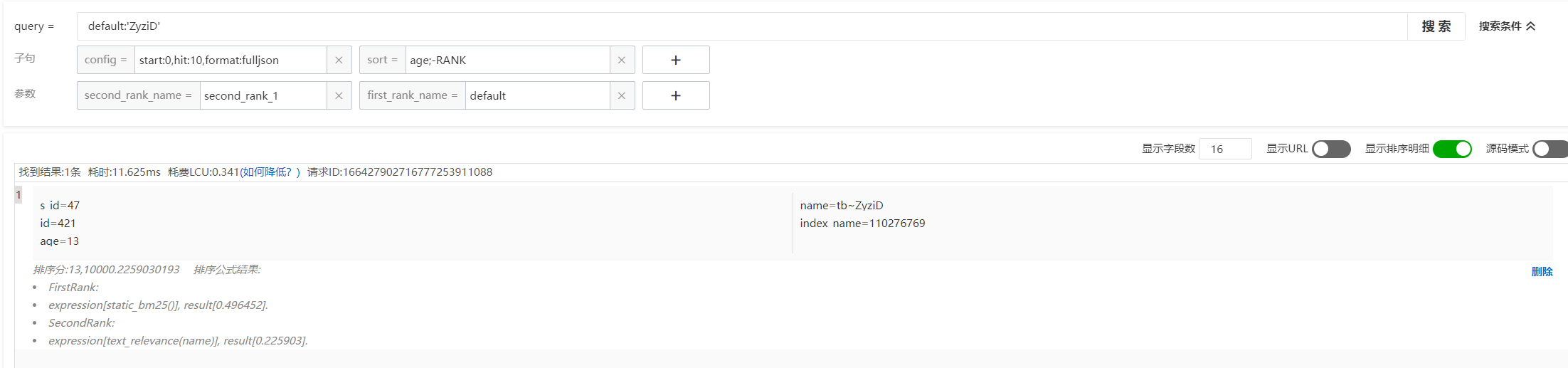
首先可以看到排序分为13,10000.2259030193,因为sort子句设置的是age;-RANK,因此13表示文档字段age的值,而10000.2259030193表示排序策略的最终得分,OpenSearch会先根据age的值进行正序排序,age值相同的文档再根据排序策略的最终得分倒序排序。
再看排序公式:
FirstRank:
expression[static_bm25()], result[0.496452].
SecondRank:
expression[text_relevance(name)], result[0.225903].FirstRank表示基础排序得分,SecondRank表示业务排序得分,最终的排序分为10000.2259030193,为什么最终排序策略得分为10000.2259030193而不是[0.496452+0.225903] 在下一节会详细说明。
由上述现象,可以得出结论:在OpenSearch中sort子句类似于SQL中order by的功能,可以直接通过文档中的属性字段进行排序,也支持复杂的排序策略进行算分,而排序策略又有着特有的函数支持和算分规则,最终根据sort子句的“+”,“-”,以及排序字段控制文档排序方式以及文档得分。
排序策略说明
排序策略打分原理
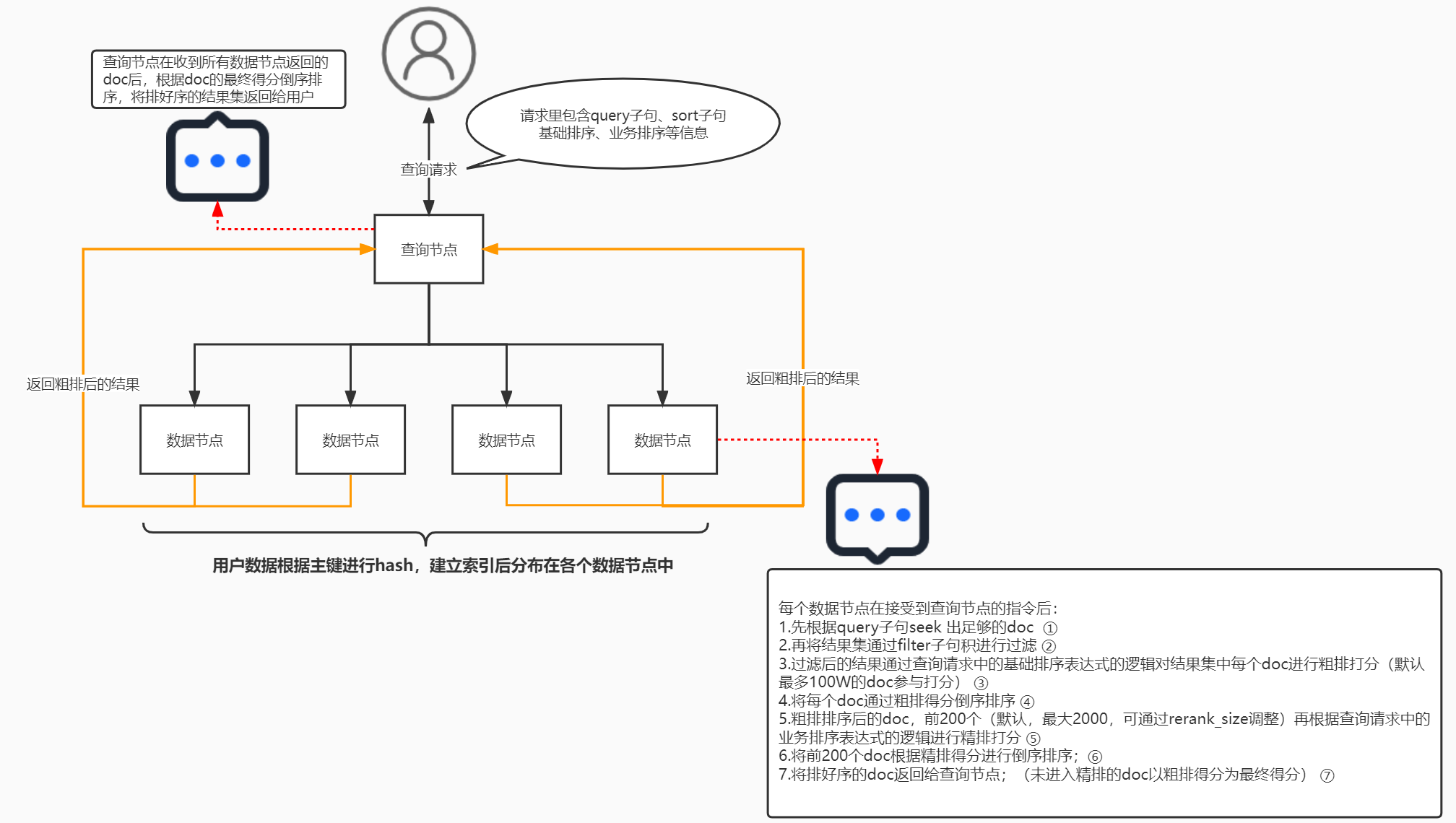
对于排序策略的算分分为两个阶段:基础排序和业务排序,通过query召回并通过filter过滤后的文档,首先进入基础排序,根据基础排序表达式海选出文档得分较高的文档,然后取出TOP N个结果再按照业务排序表达式进行精细算分,最终返回排序策略的最终得分。算分规则如下:
若只配置了基础排序,则文档得分为(10000+基础排序表达式计算的结果),总分最大为20000,超过20000结果仍为20000。
若只配置了业务排序,则文档得分为(10000+业务排序表达式计算的结果),总分无上限。
若同时配置了基础排序和业务排序,那么进入业务排序的文档最终得分为(10000+业务排序表达式计算的结果),其余文档最终得分为(10000+基础排序表达式计算的结果,总分最大为20000,超过20000结果仍为20000)。
再结合上一节排序算分为:
FirstRank:
expression[static_bm25()], result[0.496452].
SecondRank:
expression[text_relevance(name)], result[0.225903].最终得分为10000.2259030193。
通过上述原理,可理解为该命中的doc,在基础排序阶段在召回100W的doc中,参与了基础排序,通过static_bm25函数算分为0.496452,同时该文档的基础排序分正好使该文档排在了所有命中文档的前200内,参与了业务排序,在文档从基础排序进入业务排序时文档分会默认加10000分,同时舍弃基础排序的得分,以业务排序得分+10000分为最终的排序策略得分,由于该文档在业务排序中通过text_relevance函数算分为0.225903,所以该文档的最终排序策略得分为10000.2259030193。
业务排序函数用法
注意:以下内置函数中引用到的应用结构中的字段均需要设置为属性字段,否则会报错Invalid formula。
函数 | 描述 | 案例 |
i in (value1, value2, …, valuen) | 如果i的值在集合[value1, value2, …,valuen]中出现,则该表达式值为1,否则为0。 | 字段age=5 age in (1,2,3,4,5) # 结果为1 age in (6,7,8,9) # 结果为0 |
if(cond, then_value, else_value) | 如果cond的值非0,则该if表达式的实际值为then_value,否则为else_value。 如if( 2,3, 5)的值为3,if( 0,3,5)的值为5。 | 字段a=1 if(a==1,5,10) #结果为5 if(1,5,10) #结果为5 if(a==2,5,10) #结果为10 if(0,5,10) #结果为10 |
random() | 返回[0,1]间的一个随机值。 | - |
now() | 返回当前时间,自Epoch ( 00:00:00 UTC,January 1,1970)开始计算,单位是秒。 | - |
若排序策略的表达式仍无法满足复杂场景的算分逻辑,可以通过cava插件,编写脚本进行复杂场景的算分,关于cava插件的使用以及原理此处不再赘述,有兴趣的用户可以参考排序插件开发-Cava语言
常用场景的排序策略配置
1. 比如想根据age>10 的 +10分,age>40的+20分,根据weight>60的+30,最后根据最后得分排序。
实现1:
#业务排序表达式设置为:默认是匹配到只加1分
(age>10)*10+(age>40)*20+(weight>60)*30实现2:
#精排表达式设置为:
if(age>10,10,0) + if(age>40,20,0) +if(weight>60,30,0)2. 比如,xxx公司,xxx杭州分公司,那么“xxx公司”要排在“xxx杭州分公司”的前面。
实现:
#可以在业务排序(精排表达式)是里配置field_match_ratioc函数
field_match_ratio(title)3. 比如搜索 all:'dim_itm_tb',那么“dim_itm_tb”想在“dim_itm_tb_dst_itm_relation_dd”前面。
实现:
#可以在业务排序(精排表达式)是里配置field_match_ratioc函数:
field_match_ratio(detail) 4. 如何实现query = item:"iphone 8" OR item: 'iphone 8' 类似这种查询呢
实现:
#可以在业务排序(精排表达式)是里配置query_min_slide_window函数:
query_min_slide_window(title)5. 我设置了一个精排 text_relevance,搜索关键词是 "民国",但是不知道为什么 "民国趣闻-民国", "中国民族史-民国" 等要比 "民国" 排序要考前。(需要让“民国”排在最前面)
实现:
#可以在业务排序(精排表达式)是里配置query_min_slide_window函数:
query_min_slide_window(title)6. 搜索关键字在字段内容重复出现,会导致static_bm25()函数重复算分,如果规避这种情况?
实现:
#在业务排序里配置query_match_ratio
query_match_ratio(title) 7. 如何把搜索存在关键词堆积的文档给排到后面去?
实现:
#使用query_term_match_count,定义重复多少次为结果堆积。
if(field_term_match_count(title)>3,1,10)8.如何配置字符串不为空时增加一定的分数?
实现:
可以先在源库中增加标记字段(mark),如过被判断字段为空就标记成0,不为空就标记成1。然后在精排表达式中使用if函数进行判断。
精排表达式设置为:当mark=1时排序分加500
if(mark==1,500,0)