
本文介绍如何使用OpenSearch智能问答版为OpenSearch召回引擎版提供RAG能力。
假设用户已经购买了召回引擎版实例,则只需购买智能问答版实例,这两个实例的具体作用如下:
召回引擎版实例负责:
存储用户文档数据,向量数据
召回用户文档数据,向量数据
智能问答版实例负责:
对用户文档进行切片和向量化 (非必须)
对用户原始query进行向量化 (非必须)
对召回结果进行推理和总结
具体操作流程如下图所示:
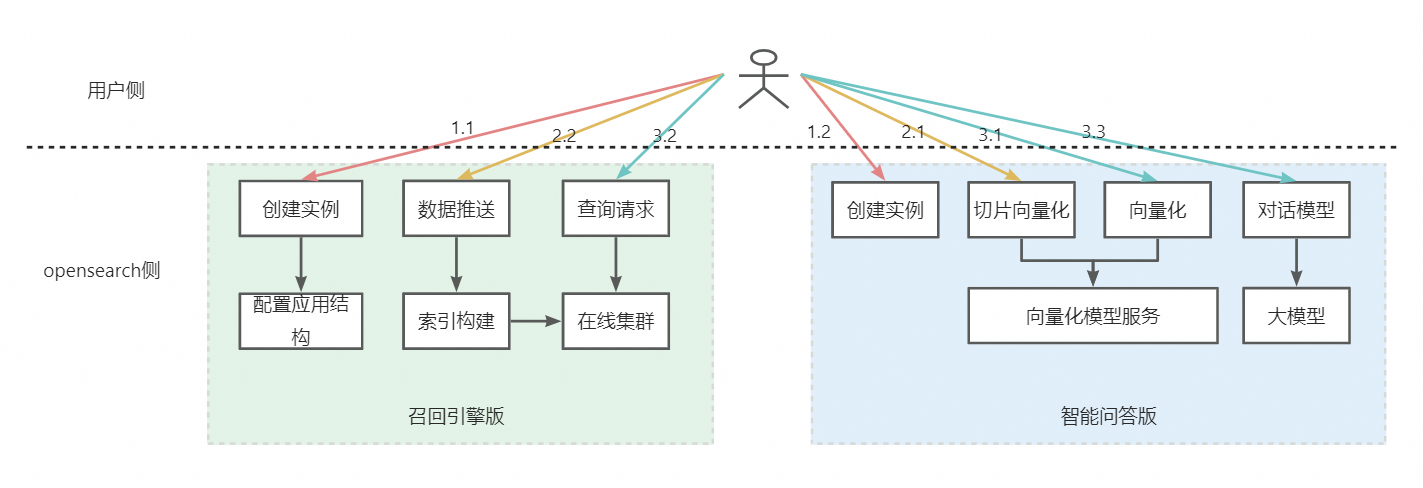
1. 创建和配置实例
1.1. 创建和配置召回引擎版实例
1.1.1. 购买OpenSearch召回引擎版实例
如果用户已经有了召回引擎版实例,则无需再购买新实例。
购买新实例可参考购买OpenSearch召回引擎版实例。
1.1.2. 配置OpenSearch召回引擎版实例
如果用户不想修改现有召回引擎版实例的查询和召回逻辑,则无需对现有实例配置进行修改,只需调用智能问答版的问答接口,对现有召回结果进行推理和总结即可(直接参见3.3章节)。
如果用户想要对现有实例中的数据内容做切片向量化,则需要修改已有配置。
在实例列表页,点击配置,进入实例配置流程,如下图所示:

1.1.2.1. 表基础信息&&数据源配置
配置表基础信息:需要自定义表名称,设置分片数,设置数据更新资源数:

数据更新资源数默认有2个免费资源,数据量超过2,按n-2 计费,n是单表的数据更新资源总数
数据同步:配置全量数据源,选择API数据源

点击确定后,数据源会保存至列表页,点击下一步,进入索引结构配置页面。
1.1.2.2. 索引结构配置
为了保存用户切片数据、向量数据,用户表结构中必须包含以下字段:
文档主键,如下图中的doc_id;
文档切片后内容字段,如下图中的split_content;
文档切分后内容向量化值,如下图中的split_content_embedding。该字段需要设置为多值float类型的向量字段,并以","分割。
除上述必须字段外,客户可以自定义添加其他业务字段,并使用这些字段做查询,排序,过滤等,来满足客户的业务需求。如下图所示:

索引配置说明:
主键ID需要配置主键索引:PRIMARYKEY64
content和split_content需要配置PACK索引或者TEXT索引
split_content_embedding需要配置CUSTOMIZED,向量索引维度为1536维,其他参数默认即可
索引配置,如下图所示:

配置完成后,点击确认创建:
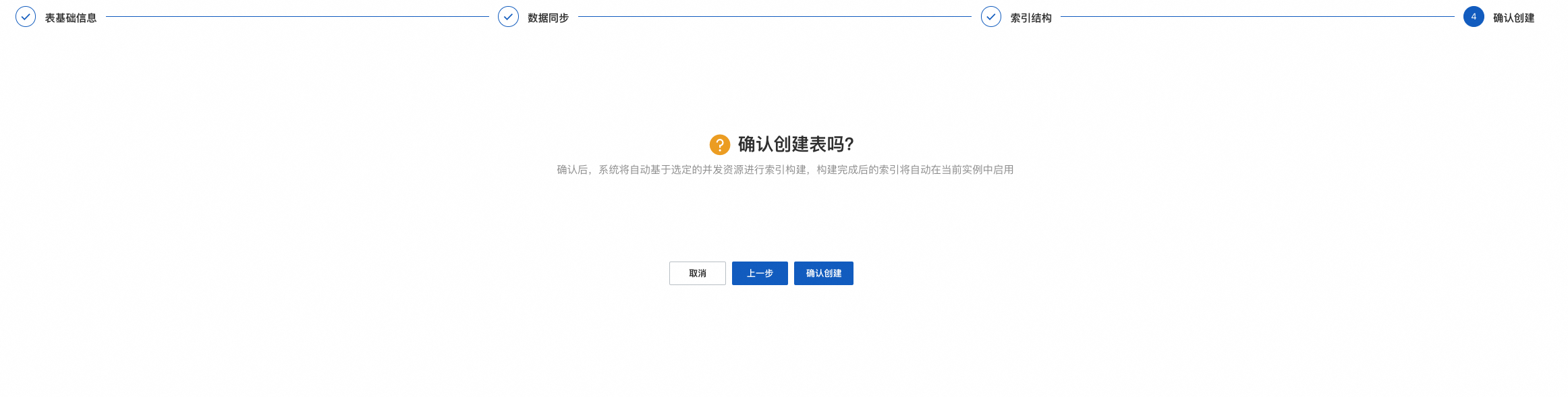
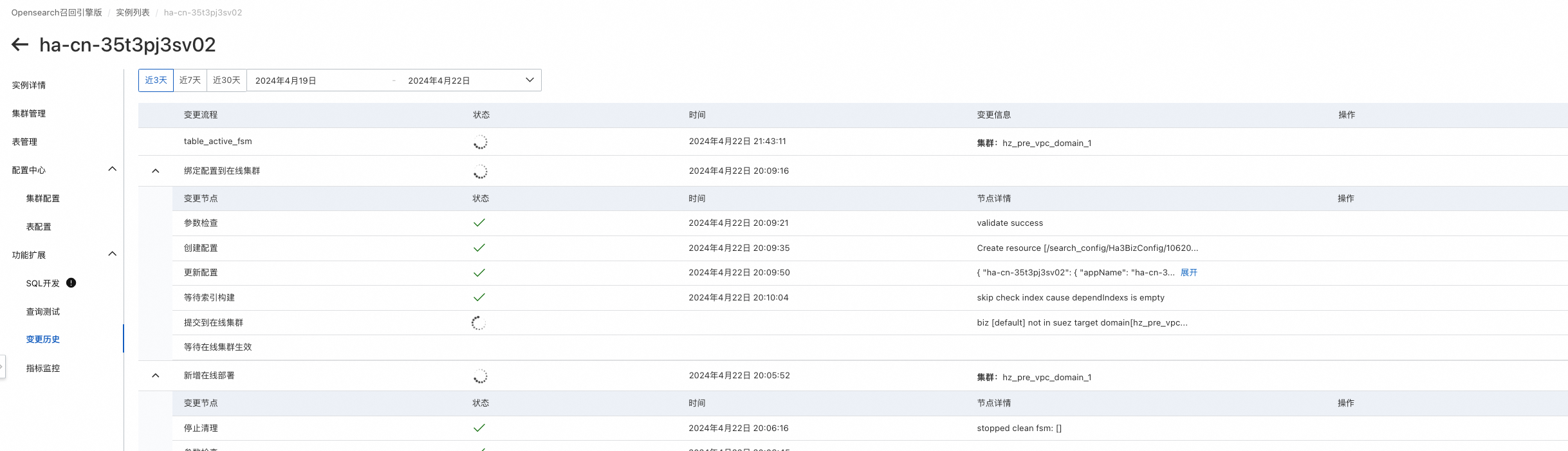
可在功能扩展>变更历史中查看创建进度,进度完成后即可进行查询测试:
1.2. 创建和配置智能问答版实例
1.2.1. 1.2.1. 购买和配置OpenSearch智能问答版实例
购买实例可参考通过控制台实现企业知识库问答。
智能问答版实例无需特殊配置,实例购买完成即可使用。
2. 数据入库
2.1. 对文档内容进行切片和向量化
在用户原始文档内容比较大的情况下,无法直接用原始文档直接调用智能问答版对话接口进行推理总结。
这就需要调用智能问答版实例相关endpoint和api,对用户原始文档内容进行切片和向量化。
请参考本文末尾的JAVA SDK Demo,或者参考文章:
2.2. 将切片和向量化之后的文档推送到召回引擎版实例
在2.1返回结果中:
chunk_id为切分后的文档ID。需要和原始文档ID拼接起来,组成新的文档主键:doc_id
chunk为切分后文档内容,对应split_content;
embedding为切分后文档内容向量化值,对应split_content_embedding;
需要将上述结果推送到召回引擎版实例。
调用召回引擎版实例相关endpoint和API,请参考本文末尾的JAVA SDK Demo,或者参考文章:
3. 查询问答
3.1. query向量化
将用户原始查询内容进行向量化。
调用智能问答版实例相关endpoint和API,请参考本文末尾的JAVA SDK Demo,或者参考文章:
3.2. 召回向量化结果数据
使用query的向量化的结果,去召回引擎版进行召回
处理query的向量化召回外,用户可以使用其他表字段进行召回,还可以对召回结果进行排序,过滤等
调用召回引擎版实例相关endpoint和API,请参考本文末尾的JAVA SDK Demo,或者参考文章:
3.3. 大模型推理总结
基于召回引擎版召回的结果,调用智能问答版的大模型问答接口,进行推理总结。
请参考本文末尾的JAVA SDK Demo,或者参考文章:
4. JAVA SDK Demo
使用Java SDK完成数据推送和智能问答的demo如下:
添加Maven依赖:
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>aliyun-sdk-ha3engine</artifactId>
<version>1.3.6</version>
</dependency>
<dependency>
<groupId>com.aliyun.opensearch</groupId>
<artifactId>aliyun-sdk-opensearch</artifactId>
<version>4.0.0</version>
</dependency>JAVA Demo:
import com.aliyun.ha3engine.Client;
import com.aliyun.ha3engine.models.*;
import com.aliyun.ha3engine.vector.models.QueryRequest;
import com.aliyun.opensearch.OpenSearchClient;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchResult;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import java.util.*;
public class RetrievalWithLLMDemo {
/**
* 智能问答版实例应用名称
*/
private static String llmAppName = "xxxx";
/**
* 智能问答版实例访问地址
*/
private static String llmHost = "http://opensearch-cn-shanghai.aliyuncs.com";
/**
* 智能问答版实例访问key
*/
private static String llmAccessKey = "xxx";
/**
* 智能问答版实例访问密钥
*/
private static String llmAccessSecret = "xxx";
/**
* 召回实例API域名
*/
private static String retrievalEndpoint = "ha-cn-xxx.public.ha.aliyuncs.com";
/**
* 召回引擎版实例名称
*/
private static String retrievalInstanceId = "ha-cn-xxx";
/**
* 召回引擎版文档数据表名称
*/
private static String retrievalTableName = "ha-cn-xxx";
/**
* 召回引擎版文档推送的文档主键字段.
*/
private static String retrievalPkField = "doc_id";
/**
* 召回引擎版用户名
*/
private static String retrievalUserName = "xxx";
/**
* 召回引擎版密码
*/
private static String retrievalPassword = "xxx";
public static void main(String[] args) throws Exception {
//创建访问智能问答版实例的对象
//创建并构造OpenSearch对象
OpenSearch openSearch = new OpenSearch(llmAccessKey, llmAccessSecret, llmHost);
//创建OpenSearchClient对象,并以OpenSearch对象作为构造参数
OpenSearchClient llmClient = new OpenSearchClient(openSearch);
//创建访问召回引擎版实例的对象
Config config = new Config();
config.setEndpoint(retrievalEndpoint);
config.setInstanceId(retrievalInstanceId);
config.setAccessUserName(retrievalUserName);
config.setAccessPassWord(retrievalPassword);
Client retrievalClient = new Client(config);
//对content进行切分和向量化
Map<String, String> splitParams = new HashMap<String, String>() {{
put("format", "full_json");
put("_POST_BODY", "{\"content\":\"OpenSearch是基于阿里巴巴自主研发的大规模分布式搜索引擎搭建的一站式商用智能搜索平台,目前为包括淘宝、天猫、菜鸟在内的阿里集团核心搜索业务提供中台服务支持。" +
"经过多年的行业搜索经验沉淀、双11大促流量冲击,智能开放搜索OpenSearch打磨出一套高性能、高时效、高可用、强稳定搜索全家桶服务,包括LLM智能问答版、行业算法版、高性能检索版、召回引擎版、召回引擎版五类商品版本,以满足各行各业的搜索需求。" +
"OpenSearch以平台服务化的形式,将专业搜索技术简单化、低门槛化和低成本化,让搜索不再成为客户的业务瓶颈,以低成本实现产品搜索功能并快速迭代\",\"use_embedding\":true}");
}};
String splitPath = String.format("/apps/%s/actions/knowledge-split", llmAppName);
OpenSearchResult openSearchResult = llmClient.callAndDecodeResult(splitPath, splitParams, "POST");
System.out.println("split result:" + openSearchResult.getResult());
JsonArray array = JsonParser.parseString(openSearchResult.getResult()).getAsJsonArray();
// 文档推送外层结构, 可添加对文档操作的结构体. 结构内支持一个或多个文档操作内容.
ArrayList<Map<String, ?>> documents = new ArrayList<>();
//假设用户原始文档主键为1
String doc_raw_id="001";
for(JsonElement element:array){
JsonObject object = element.getAsJsonObject();
// 添加文档
Map<String, Object> add2Document = new HashMap<>();
Map<String, Object> add2DocumentFields = new HashMap<>();
// 插入文档内容信息, keyValue 成对匹配.
// field_pk 字段需与 pkField 字段配置一致.
add2DocumentFields.put("doc_id", doc_raw_id+"_"+object.get("chunk_id").getAsString());
add2DocumentFields.put("doc_raw_id", doc_raw_id);
List<Float> vectors = new ArrayList();
for(String str: object.get("embedding").getAsString().split(",")){
vectors.add(Float.parseFloat(str));
}
add2DocumentFields.put("split_content_embedding", vectors);
add2DocumentFields.put("split_content", object.get("chunk"));
// 将文档内容添如 add2Document 结构.
add2Document.put("fields", add2DocumentFields);
// 新增对应的文档命令: add
add2Document.put("cmd", "add");
documents.add(add2Document);
}
System.out.println("push docs:"+documents.toString());
// 推送数据到召回引擎版
PushDocumentsRequestModel request = new PushDocumentsRequestModel();
request.setBody(documents);
PushDocumentsResponseModel response = retrievalClient.pushDocuments(retrievalTableName, retrievalPkField, request);
String responseBody = response.getBody();
System.out.println("push result:" + responseBody);
//对用户原始query进行向量化
Map<String, String> embeddingParams = new HashMap<String, String>() {
{
put("format", "full_json");
put("_POST_BODY", "{\"content\":\"OpenSearch是什么\",\"query\":true}");
}};
String embeddingPath = String.format("/apps/%s/actions/knowledge-embedding", llmAppName);
openSearchResult = llmClient.callAndDecodeResult(embeddingPath, embeddingParams, "POST");
System.out.println("query embedding:"+openSearchResult.getResult());
String embedding = openSearchResult.getResult();
SearchRequestModel haQueryRequestModel = new SearchRequestModel();
SearchQuery haRawQuery = new SearchQuery();
haRawQuery.setQuery("query=split_content_embedding:'"+embedding+"'&&config=start:0,hit:5,format:json&&cluster=general");
haQueryRequestModel.setQuery(haRawQuery);
// 仅支持GET和POST请求方式,默认为GET,查询query长度超过30K请使用POST请求
haQueryRequestModel.setMethod("POST");
SearchResponseModel searchResponse = retrievalClient.Search(haQueryRequestModel);
System.out.println("搜索结果:" + searchResponse.getBody());
JsonObject recallResult = JsonParser.parseString(searchResponse.getBody()).getAsJsonObject().get("result").getAsJsonObject();
long hits = recallResult.get("totalHits").getAsLong();
List<String> list = new ArrayList<>();
if(hits <=0){
System.out.println("未能召回结果");
return ;
}else{
JsonArray items = recallResult.get("items").getAsJsonArray();
for(JsonElement element:items) {
JsonObject object = element.getAsJsonObject();
String splitContent = object.get("fields").getAsJsonObject().get("split_content").getAsString();
list.add(splitContent);
}
}
//调用智能问答版实例进行推理总结
StringBuffer sb =new StringBuffer();
sb.append("{ \"question\" : \"什么是opensearch\" ,");
sb.append(" \"type\" : \"text\",");
sb.append(" \"content\" : [");
for(String str:list){
sb.append("\"");
sb.append(str);
sb.append("\"");
sb.append(",");
}
sb.deleteCharAt(sb.lastIndexOf(","));
sb.append("]}");
Map<String, String> llmParams = new HashMap<String, String>() {{
put("format", "full_json");
put("_POST_BODY", sb.toString());
}};
System.out.println("llm request params:"+llmParams);
String llmPath = String.format("/apps/%s/actions/knowledge-llm", llmAppName);
openSearchResult = llmClient.callAndDecodeResult(llmPath, llmParams, "POST");
System.out.println("llm result:"+openSearchResult.getResult());
}
}