
本文介绍如何调用AI搜索开放平台模型进行数据预处理。此方案适用所有需要将原始图片或文本进行处理并实现文本搜图、图搜图及语义搜索的场景。
链路示意
下面以某个从事装卸搬运和仓储业为主的企业案例为例,只有各仓库工人拍摄的货品照片(货品外包装图片,图片中含有货品品牌型号等文本信息)和货品ID,需要以图搜图来快速查询相似货品,即可参照示意图中的链路快速搭建图搜服务。
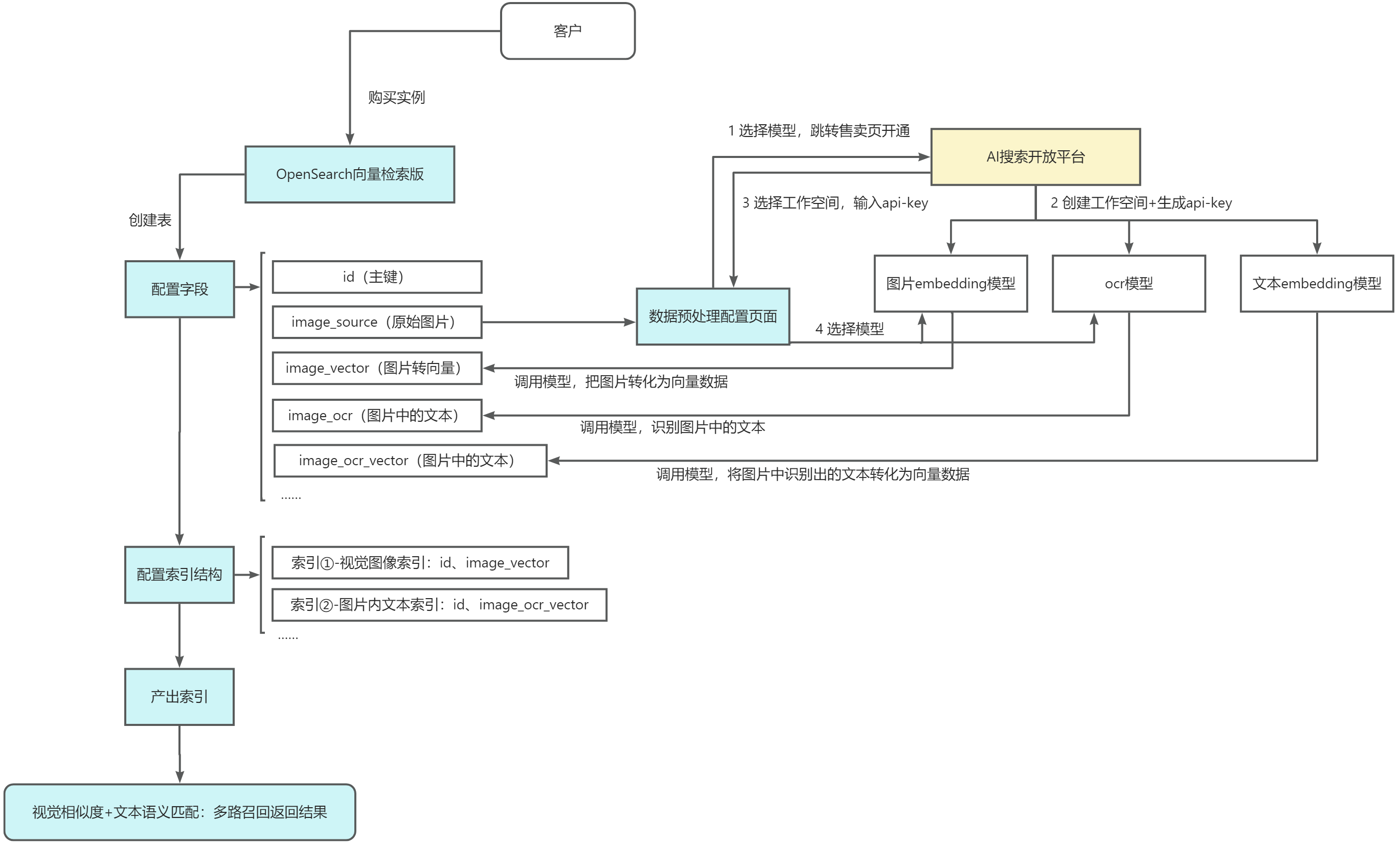
购买实例
购买实例可参考购买OpenSearch向量检索版实例。
配置实例
新购买的实例在其详情页中显示状态为“待配置”,并且会自动部署一个与购买的查询节点和数据节点的个数及规格一致的空实例。之后,需要为该实例配置表信息、数据同步、字段配置及索引结构,最终等待索引重建完成即可正常搜索。

1. 表基础信息
表管理点击“添加表",输入表名称,设置数据分片数和数据更新资源数,选择场景模板后(本文以向量:图片搜索为例)点击下一步:
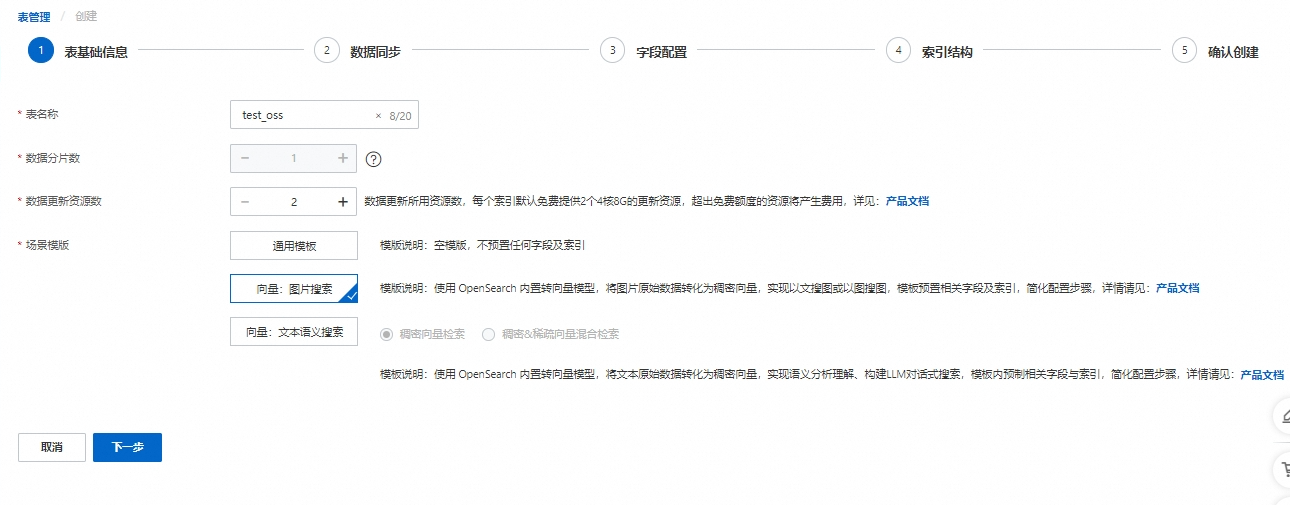
配置说明:
表名称:可自定义
数据分片数:分片数设置时,请填写不超过256的正整数, 用于提升全量构建速度、单次查询性能。(部分存量实例,仍需各索引表分片数保持一致;或至少一个索引表分片数为1,其余索引表分片数一致)
数据更新资源数:数据更新所用资源数,每个索引默认免费提供2个4核8G的更新资源,超出免费额度的资源将产生费用,详情可参考向量检索版计费概述
场景模板:可选择通用模板、向量:图片搜索及向量:文本语义搜索。
2.数据同步
选择全量数据来源(目前支持的数据源有MaxCompute+API、对象存储OSS+API、数据湖构建(DLF)和API),本文以对象存储OSS+API为例,配置完参数校验通过后,点击下一步。
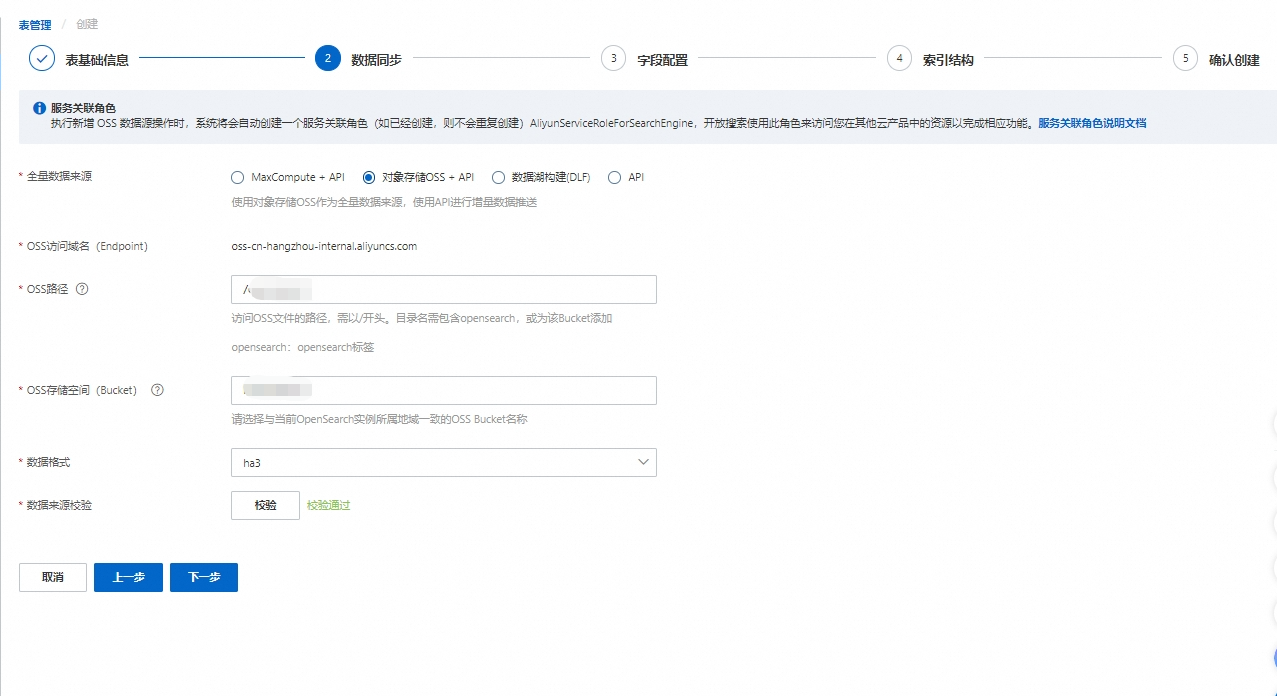
3.字段配置
向量检索版会根据您选择的场景模板,预置相关字段,并将全量数据来源中的字段,自动导入下方列表,字段配置、需数据预处理-去配置 都设置完成后,点击 下一步 。
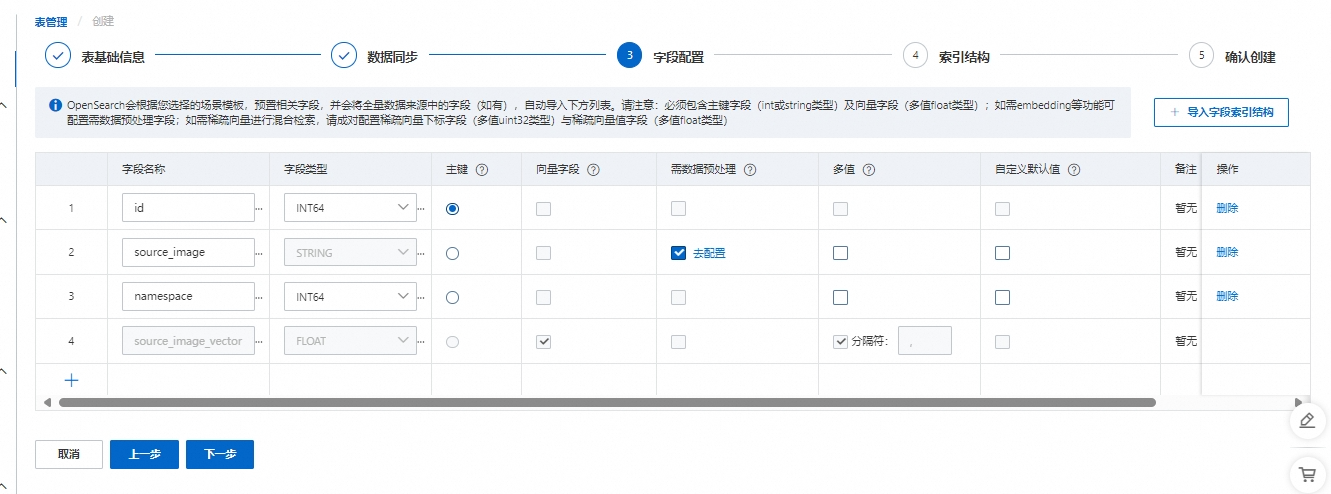
字段含义:
id(主键)
source_image(源图片)
namespace(命名空间)
source_image_vector(源图片向量)
配置说明:
必选字段有:主键字段和向量字段,主键字段为int或string类型并且需要勾选主键按钮,向量字段为float类型并且需要勾选向量字段按钮。
向量字段默认为多值的float类型,多值分隔符默认使用分割符英文逗号进行切分,也可以输入自定义多值分隔符。
当数据中缺少字段或字段为空时,系统将自动补充默认值,数字类型默认补0,STRING类型默认补空字符串,支持自定义默认值。
需数据预处理 - 去配置:点击去配置,进入字段 source_image 数据预处理配置界面。
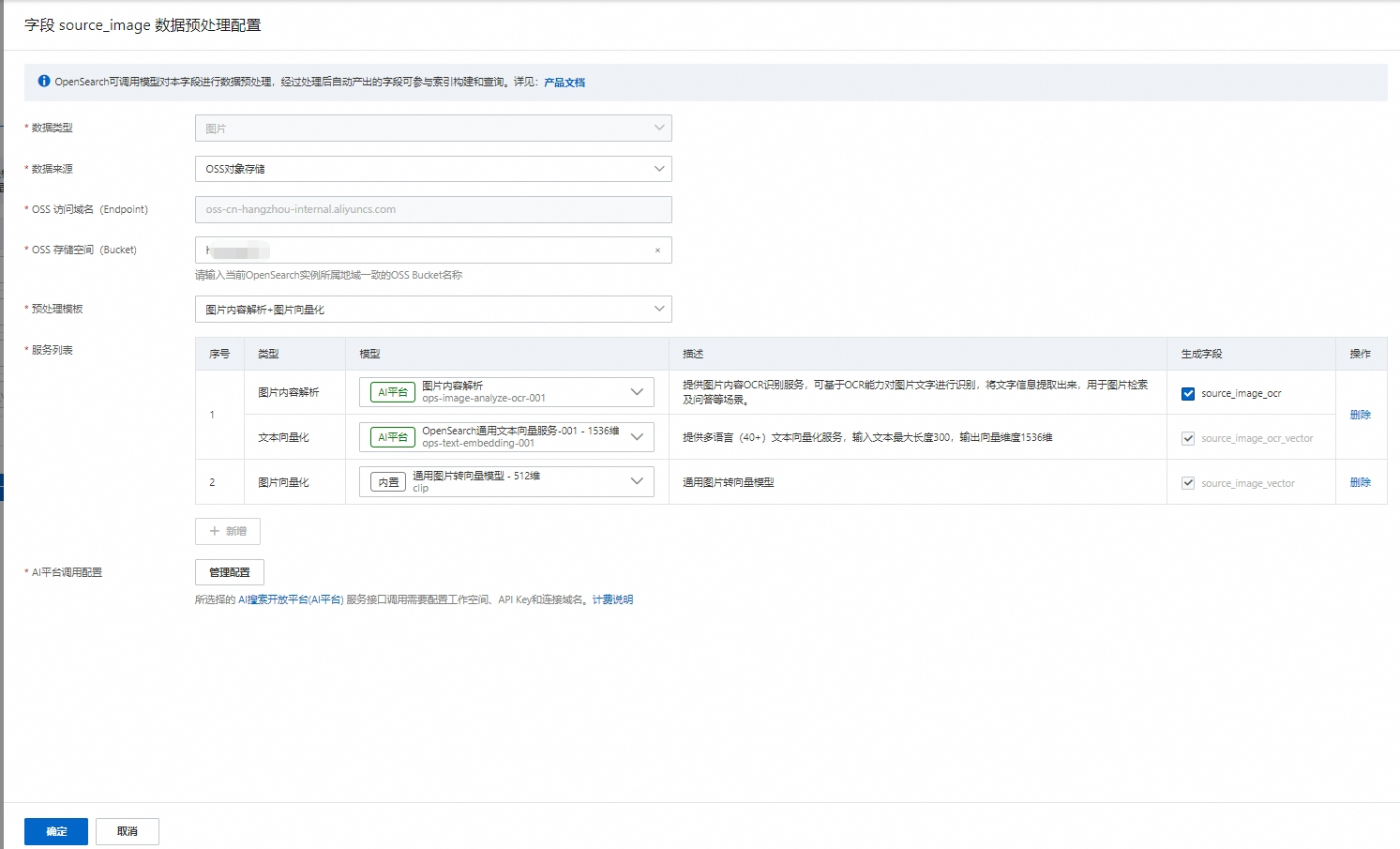
数据来源:有OSS对象存储和Base64编码的两种数据类型选项,本次选择OSS对象存储方式。
OSS对象存储:需要填写OSS路径,其实就是将图片存放在OSS的文件夹里面,从OSS直接导入。
Base64编码:相当于需要先将图片进行一次编码,然后存储在数据库中,或者直接用API方式进行传输。
预处理模板:会根据要进行预处理的数据类型(文本或图片)而展示不同模板,由于本次预处理的是图片类型的数据,所以此时预处理模板展示的分别是(1.图片向量化、2.OCR图片文字识别、3.OCR图片文字识别+图片向量化)3种模板,本次演示选择 图片向量化 预处理模板。
服务列表:
选定预处理模板后,自动出现模板下的服务列表,展示该模板下所用到的模型种类。
可选的模型有三个来源:
内置模型:模型种类与数量较少,可免费调用。
AI搜索开放平台:如果选择的预处理模板是(OCR图片文字识别、OCR图片文字识别+图片向量化)模板,则会出现AI搜索开放平台模型选项。
自定义模型:用户可根据自身需求自定义模型,在模型列表>自定义模型中进行新增模型操作。
生成字段:
embedding处理类的服务,默认必须生成字段。
ocr服务可选是否生成字段。
同一字段,同类服务目前只支持处理一次。
4.索引结构
配置完成后点击下一步。
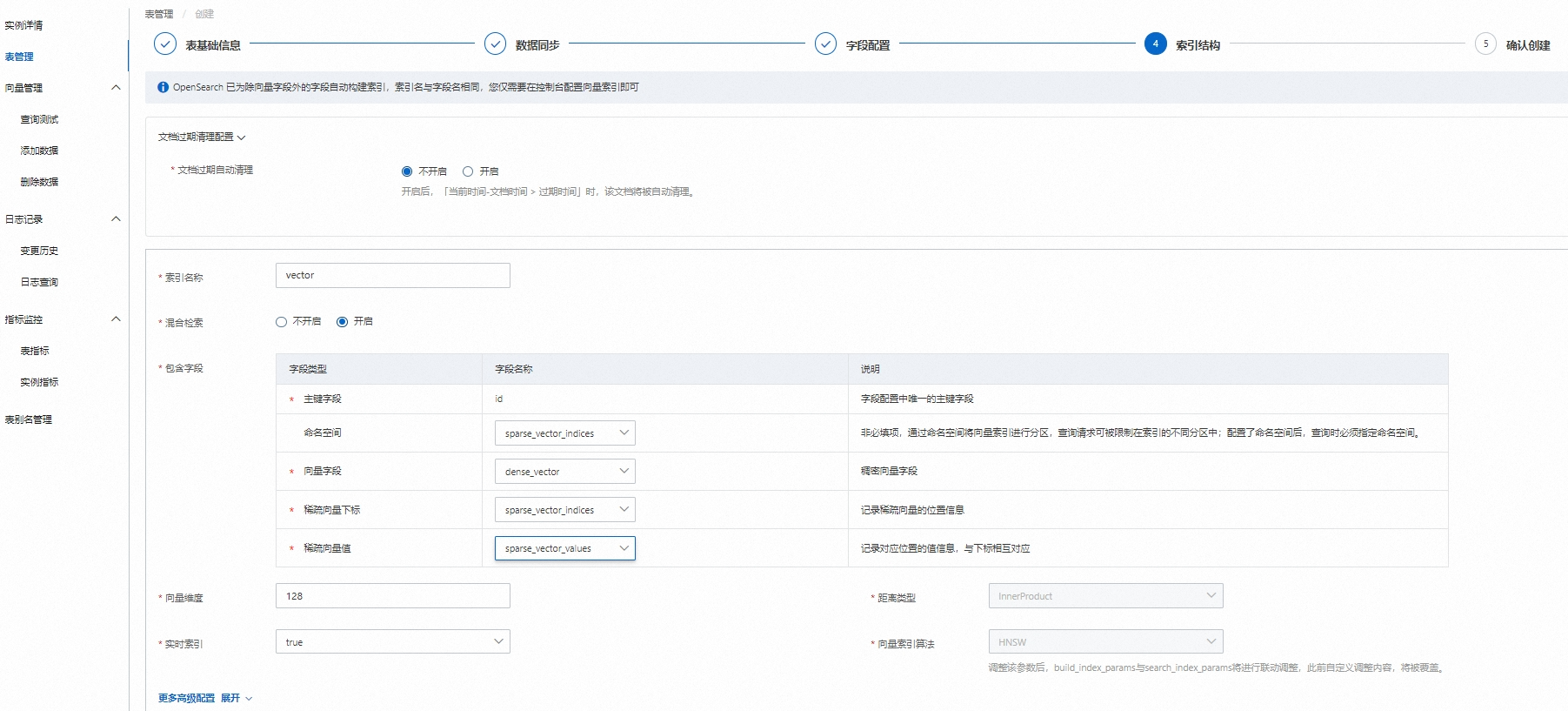
配置说明:
包含字段:主键字段、向量字段必须填写,命名空间字段非必填,可以为空。
向量维度、实时索引、距离类型、向量索引算法可以根据业务情况填写。
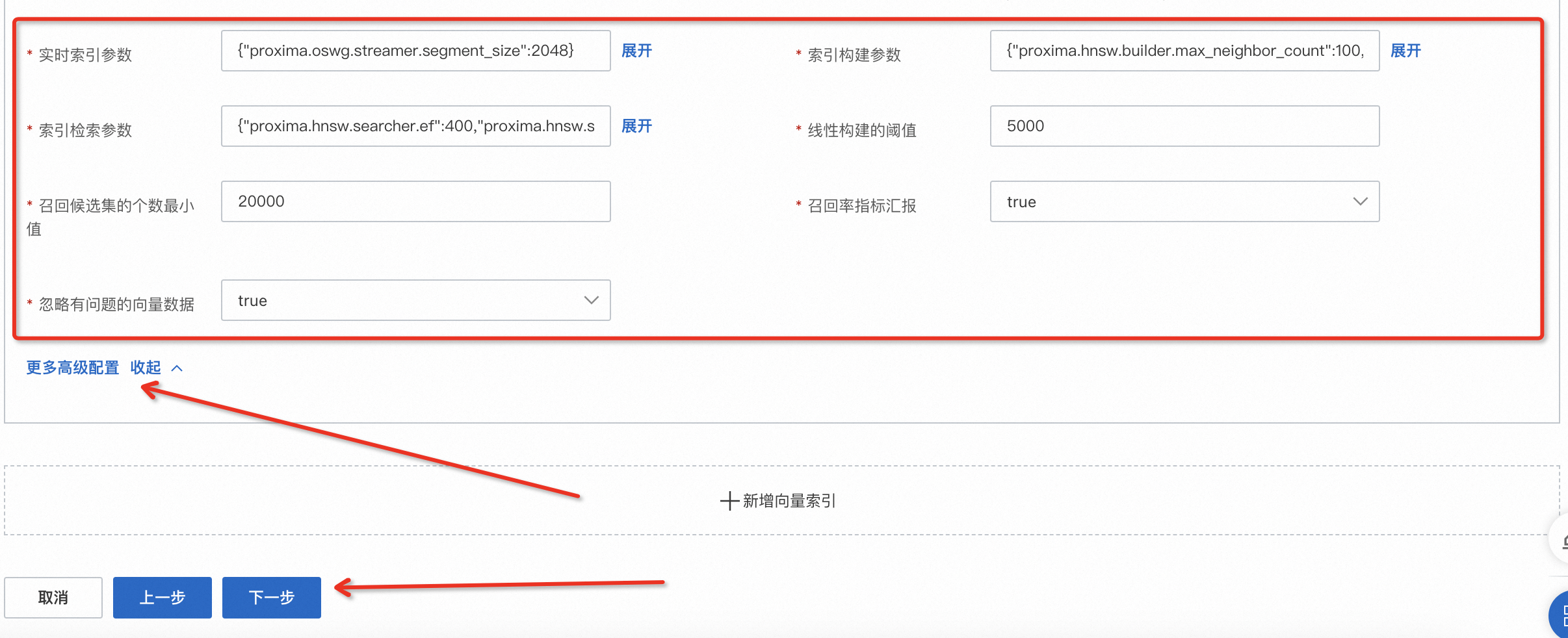
更多高级配置:可直接使用默认参数或根据业务情况调整,详情可参考向量索引通用配置,索引结构页设置完毕后,点击下一步,进入确认创建页。
5.确认创建
配置完成后,点击确认创建,返回到 实例列表 页,待实例状态为“ 正常 ”后,就可以从 操作栏 - 查询测试 进行后续的搜索和测试。