
准备工作
推荐进入VPC环境进行测试
下载gist-960-euclidean数据集,可任选一种方法下载
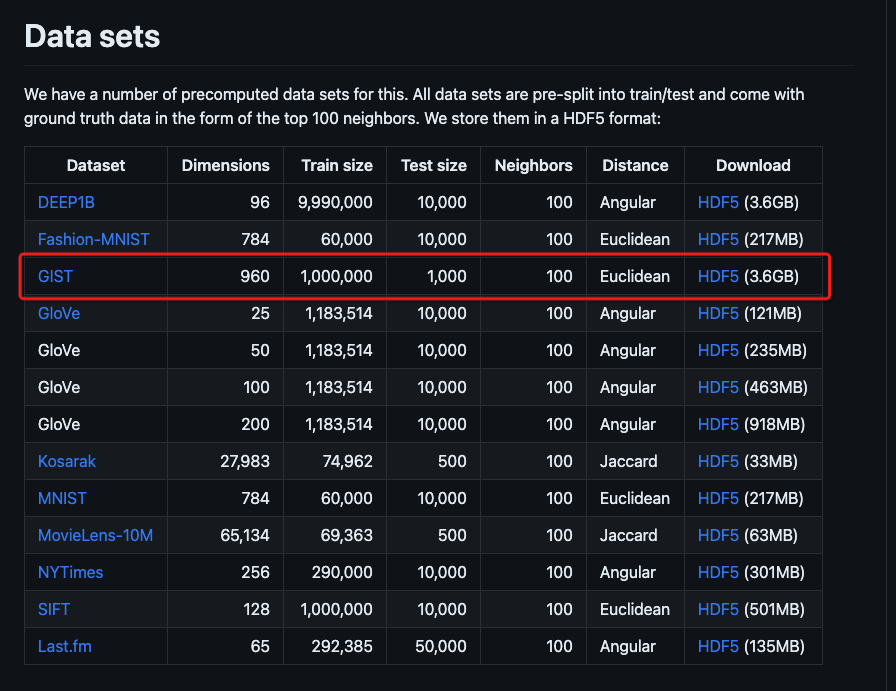
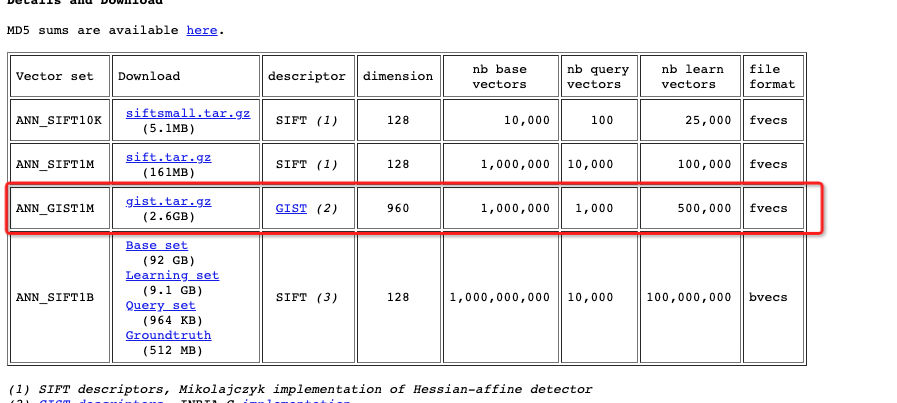
解压后使用目录中的gist_base.fvecs。
python3及相关库
h5py
json
numpy
sklearn
alibabacloud_ha3engine_vector生成数据
使用
prepare_data.py脚本,脚本支持hdf5/fvecs/bvecs/ivecs格式的向量数据,以hdf5格式作为例子
python3 prepare_data.py -i ./gist-960-euclidean.hdf5 脚本执行完成后,当前目录下会产生一个
data/子目录生成文件名为
gist-960-euclidean.hdf5.data检查生成的数据行数是否完整
wc -l data/gist-960-euclidean.hdf5.data
1000000 gist-960-euclidean.hdf5.data购买OpenSearch向量检索版实例
购买实例请参考购买OpenSearch向量检索版实例
添加表
详情可参考:
推送数据
使用
push_data.py脚本推送数据参数
文件路径
-i:指定推送的文件路径表名
-t:table_name用户名
-u:user_name密码
-p:password实例ID
-e:instance_id
python3 push_data.py -i data/gist-960-euclidean.hdf5.data -t gist -u ${user_name} -p ${password} -e ${instance_id}生成query
使用
prepare_query.py脚本从原始数据中随机生成query
python3 prepare_query.py -i gist-960-euclidean.hdf5 -c 10000 -t gist脚本会在
data/文件夹下生成query.dataquery文件
使用wrk进行压测
wrk是一个开源的HTTP请求压测工具:https://github.com/wg/wrk
从github下载wrk压测工具
git clone https://github.com/wg/wrk.git使用
search.lua进行测试复制到脚本目录下
cp search.lua wrk/scripts/计算签名并更改脚本的
request方法中的header["Authorization"]信息
-- wrk 运行阶段,随机选取query,构造具体发送的请求
request = function ()
local query = query_table[count]
count = (count + 1)%query_count
local headers = {}
headers["Authorization"] = "Basic xxxx" -- 签名信息
headers["Content-Type"] = "application/json"
return wrk.format("POST", nil, headers, query)
end开始压测
-c连接数(并发数)-t发送请求的线程数-d指定压测时间-s指定脚本--latency打印详细压测结果
./wrk -c24 -d100s -t8 -s scripts/search.lua http://ha-cn-xxxxxx.ha.aliyuncs.com/vector-service/query --latency查看指标
查看召回率、查询耗时等指标
请参考指标监控授权
脚本下载
性能测试数据
以下是向量检索版使用八代机,对ANN_GIST1M 960维数据集的测试情况。
产品 | OpenSearch(使用gist自带的1000条query压测,ef也根据自带groundtruth调整) | |
测试集 ANN_GIST1M 960维(http://corpus-texmex.irisa.fr/) | ||
产品版本 | OpenSearch-向量检索版 2024.11 vector_service_1.4.0_test_202411081507 | OpenSearch-向量检索版 2024.11 vector_service_1.3.0_202410081048 |
机器规格 | 16core 64G ecs.g8i.4xlarge 八代机 | |
测试工具 | wrk(https://github.com/wg/wrk) 压测参数: 线程:10 连接数:30 | wrk(https://github.com/wg/wrk) 压测参数: 线程:10 连接数:40 |
参数配置 | m:100 ef_construction:500 | |
向量算法 | HNSW | QGRAPH(HNSW+量化) |
top10 recall@95 | 查询参数: ef=60 | 查询参数: ef=40:recall@94 ef=80:recall@95 |
QPS: 4486.06 Latency(avg):6.7ms CPU负载:95.8% | recall 94 ef=40 QPS: 4957.48 Latency(avg):7.6ms CPU负载:93% recall 95 ef=80 QPS: 3700.74 Latency(avg):8.19ms CPU负载:92% | |
top10 recall@99 | 查询参数: ef=170 | recall最高95.8,达不到99 |
QPS: 2868.77 Latency(avg):10.44ms CPU负载:94% | ||
top10 recall@99.5 | 查询参数: ef=300 线程:10 连接数:20 | |
QPS: 2050.66 Latency(avg):9.73ms CPU负载:95% | ||