
列存索引的目标是提供一个最简便的方案,以加速业务中复杂耗时的SQL语句。您可以参考快速入门中的内容,以配置集群的HTAP负载处理能力。此外,您可以参考进阶使用中的内容对列存索引进行定制以满足特定的业务需求。
快速入门
1. 添加列存索引只读节点
登录PolarDB控制台,在左侧导航栏单击集群列表,选择集群所在地域,找到目标集群。单击操作栏中的增删节点,添加列存索引只读节点。
2. 配置行列分流方案
您可以根据业务需求选择行列自动分流或手动分流两种方式,来使用列存索引。
行列自动分流:如果您的业务中,OLTP类型业务与OLAP类型业务是基于同一个应用程序访问数据库,则可以通过将两类业务的读请求根据预估执行代价(扫描行数)进行自动分流,从而分别路由至列存索引只读节点或只读行存节点。
行列手动分流:如果您的业务中,OLTP类型业务与OLAP类型业务是基于不同应用程序访问数据库,则可以为这些应用程序分别配置不同的集群地址。随后,将列存索引只读节点和只读行存节点分别配置到不同集群地址(Endpoint)的服务节点中,从而实现行存和列存的分流。
行列自动分流
前往集群详情页面,在数据库连接区域,修改集群地址的行存/列存自动引流选项为开启。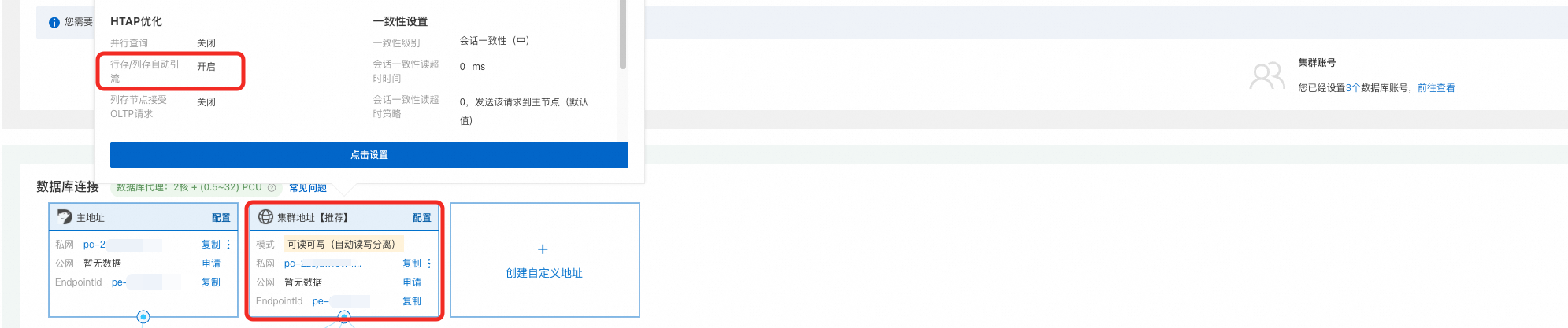
调整行存/列存自动引流选项仅对新连接生效。请在完成调整后,重新连接集群。
若您是使用DMS连接集群,由于DMS默认使用主地址连接集群,因此您需要手动修改为使用集群地址连接PolarDB集群。
行列自动分流的默认预估执行代价(扫描行数)为50000,您可以根据实际业务需求对该参数进行调整。
行列手动分流
前往集群详情页面,在数据库连接区域,新建一个自定义地址,服务节点应仅包含列存索引只读节点。
3. 添加列存索引
您可以根据业务需求选择手动添加或自动添加两种方式,来为您的业务表添加列存索引。
查询SQL语句中所涉及的所有列均需被列存索引完全覆盖,才能使用列存索引实现查询加速。
手动添加
列存索引为您提供全面的DDL语句,以支持您为业务表添加或删除列存索引。您可以根据实际需求进行选择:
DDL语法 | 示例 |
| |
| |
|
添加列存索引时,您可以保留原有注释。例如:
ALTER TABLE <table_name> COMMENT 'COLUMNAR=1 <原有注释>';。默认情况下,库表级(批量)增加列存索引时,表注释会修改为
'COLUMNAR=1 <原有注释>'。
自动添加
列存索引提供的自动无感提速(AutoIndex)功能,能够根据您的慢SQL自动创建列存索引,从而显著提升慢SQL的执行速度,无需您深入理解每一条慢SQL进行调优。随着应用负载的变化,自动列存索引提速功能会持续监控并调整列存索引策略,以确保PolarDB集群维持在最佳性能状态。
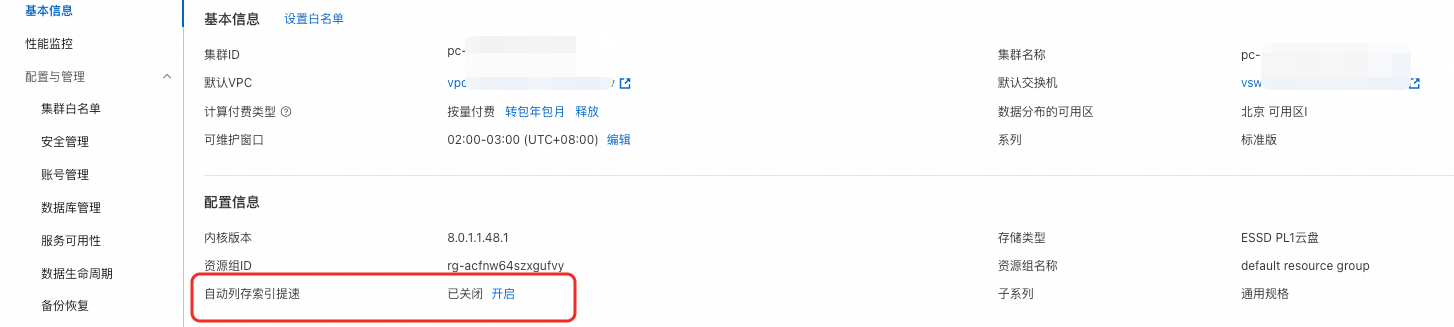
您只需在PolarDB集群详情页面,开启自动列存索引提速功能即可体验该功能带来的效果:
(可选)4. 查询列存索引构建进度
手动添加列存索引后,需要查看列存索引构建的执行进度,等待列存索引构建完成,即可体验列存索引的查询加速效果。
SELECT * FROM INFORMATION_SCHEMA.IMCI_ASYNC_DDL_STATS;示例如下:通过查看STATUS状态是否为Safe to read,可以确认列存索引是否已构建完成。
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| SCHEMA_NAME | TABLE_NAME | CREATED_AT | STARTED_AT | FINISHED_AT | STATUS | APPROXIMATE_ROWS | SCANNED_ROWS | SCAN_SECOND | SORT_ROUNDS | SORT_SECOND | BUILD_ROWS | BUILD_SECOND | AVG_SPEED | SPEED_LAST_SECOND | ESTIMATE_SECOND |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
| tpch | lineitem | 2024-10-21 13:44:02 | 2024-10-21 13:44:02 | 2024-10-21 13:50:11 | Safe to read | 590446240 | 600037902(100%) | 369 | 0 | 0 | 0(0%) | 0 | 1625058 | 0 | 0 |
+-------------+------------+---------------------+---------------------+---------------------+--------------+------------------+-----------------+-------------+-------------+-------------+------------+--------------+-----------+-------------------+-----------------+
1 row in set, 1 warning (0.00 sec)(可选)5. 检查SQL语句是否使用列存索引
列存执行计划以横向树的形式输出,该格式与行存执行计划的输出格式存在明显区别。您可以通过使用Explain查看SQL的执行计划,来判断某条SQL语句是否可以使用列存索引加速功能。示例如下:
列存执行计划(横向树形式)
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| ID | Operator | Name | E-Rows | E-Cost | Extra Info |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
| 1 | Select Statement | | | | IMCI Execution Plan (max_dop = 4, max_query_mem = 858993459) |
| 2 | └─Sort | | | | Sort Key: revenue DESC,o_orderdate ASC |
| 3 | └─Hash Groupby | | | | Group Key: (lineitem.L_ORDERKEY, orders.O_ORDERDATE, orders.O_SHIPPRIORITY) |
| 4 | └─Hash Join | | | | Join Cond: orders.O_ORDERKEY = lineitem.L_ORDERKEY |
| 5 | ├─Hash Join | | | | Join Cond: customer.C_CUSTKEY = orders.O_CUSTKEY |
| 6 | │ ├─Table Scan | customer | | | Cond: (C_MKTSEGMENT = "BUILDING") |
| 7 | │ └─Table Scan | orders | | | Cond: (O_ORDERDATE < 03/24/1995) |
| 8 | └─Table Scan | lineitem | | | Cond: (L_SHIPDATE > 03/24/1995) |
+----+----------------------------+----------+--------+--------+-----------------------------------------------------------------------------+
8 rows in set (0.01 sec)行存执行计划
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
| 1 | SIMPLE | customer | NULL | ALL | PRIMARY | NULL | NULL | NULL | 147630 | 10.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | NULL | ref | PRIMARY,ORDERS_FK1 | ORDERS_FK1 | 4 | tpch100g.customer.C_CUSTKEY | 14 | 33.33 | Using where |
| 1 | SIMPLE | lineitem | NULL | ref | PRIMARY | PRIMARY | 4 | tpch100g.orders.O_ORDERKEY | 4 | 33.33 | Using where |
+----+-------------+----------+------------+------+--------------------+------------+---------+-----------------------------+--------+----------+----------------------------------------------+
3 rows in set, 1 warning (0.00 sec)辅助工具
在使用列存索引查询复杂SQL语句时,您需要检查SQL语句中是否存在未被索引覆盖的列。如果发现有未被列存索引覆盖的列,您可以针对该SQL语句获取创建列存索引的DDL语句,或者针对某个业务批量获取创建列存索引的DDL语句。执行获取的DDL语句后,确保SQL语句中的所有列均被列存索引覆盖,才可使用列存索引进行查询加速。
PolarDB集群内置的存储过程如下:
检查SQL语句中是否存在未被索引覆盖的列存储过程:
dbms_imci.check_columnar_index('<query_string>');。获取创建列存索引的DDL语句存储过程:
dbms_imci.columnar_advise('<query_string>');和dbms_imci.columnar_advise_by_columns('<query_string>');。批量获取创建列存索引的DDL语句存储过程:
dbms_imci.columnar_advise_begin();、dbms_imci.columnar_advise_show();和dbms_imci.columnar_advise_end();。
常见问题
更多信息,请参考列存索引常见问题。
进阶使用
您可以参考以下内容来优化列存索引的使用。
进阶功能 | 说明 |
列存索引数据组织的基本单位为行组(Row Group)。在每个行组中,不同的列会各自打包形成列数据块,这些列数据块按照行存原始数据的主键顺序并行构建,整体上呈现无序状态。您可以通过设置排序键来修改列数据块的排列顺序,以提高查询性能。 | |
ETL(Extract Transform Load)功能可以让您在读写(RW)节点上使用列存索引,读写(RW)节点上的SQL语句中的 | |
加速访问OSS外表。列存索引的并行扫描功能可以充分利用对象存储OSS的高带宽,并通过并行计算或向量计算来提升CPU的使用效率,最终获得极高的分析速度,并支持离线和实时数据的聚合分析。 | |
Serverless功能可以根据业务负载进行自动扩缩容。在高峰时段自动升配,有效应对业务负载的突增。在低谷时段自动降配,有效降低使用成本。 | |
Hybrid Plan是指在同一条查询语句中同时使用列式索引和行式索引的查询方式。Hybrid Plan能够显著提高宽表查询的速度。在执行计划中,对于适合使用列式索引的部分,将通过列存索引进行执行并获取中间结果,该中间结果仅包含主键信息。最后,通过主键结合InnoDB主索引来查询需要的所有列信息并进行输出。 | |
对于海量数据的复杂查询,单个列存索引只读节点已无法满足性能需求。您可以使用多机并行的方式进行查询加速。 |
深入了解
如果您对列存索引的原理感兴趣,您可以参考以下文档以深入了解列存索引: