阿里云Elasticsearch为运行中的集群提供了多项基础监控指标(例如集群状态、集群查询QPS、节点CPU使用率、节点磁盘使用率等)和高级监控报警指标(例如Cluster、Index、Note Resource等),用来监测集群的运行状况。您可以根据这些指标,实时了解集群的运行状况,及时处理潜在风险,保障集群稳定运行。本文介绍如何查看集群监控详情,以及各监控指标含义、异常原因和异常处理建议。
监控差异说明
阿里云Elasticsearch集群监控可能与Kibana或第三方监控存在如下差异:
采样周期差异性:采集周期和Kibana或第三方监控存在差异,采集到的数据不同,因此会存在差异。
查询算法差异性:例如,阿里云Elasticsearch集群监控和Kibana监控采集数据时都会受集群稳定性的影响,集群监控QPS指标会因集群的抖动会出现监控突增、负值或无监控等状况,而Kibana监控可能显示为空。
说明如果集群监控提供的指标比Kibana监控多,在实际使用时,建议将集群监控和Kibana监控结合起来分析集群监控详情。
采集接口差异性:Kibana监控指标依赖于Elasticsearch API,而集群监控部分节点级别的指标(例如CPU使用率、load_1m、磁盘使用率等),调用的是阿里云Elasticsearch底层系统接口,因此监控中除了Elasticsearch进程外还包含了系统级别资源的占用情况。
查看集群监控详情
- 登录阿里云Elasticsearch控制台。
- 在左侧导航栏,单击Elasticsearch实例。
- 进入目标实例。
- 在顶部菜单栏处,选择资源组和地域。
- 在Elasticsearch实例中单击目标实例ID。
在左侧导航栏,选择。
查看监控详情。
查看高级监控报警详情
单击高级监控报警页签,选择监控时段,查看该时段内的监控详情。
 说明
说明高级监控报警功能目前仅支持杭州、北京、上海、深圳、青岛、张家口、美国东部、美国西部、日本、印度、印度尼西亚、中国香港等地域,具体以控制台为准。详细信息请参见高级监控报警概述。
阿里云Elasticsearch实例的版本不同,支持的高级监控指标也不同,具体以控制台为准。
ES实例的高级监控报警页面默认仅展示该实例指标数据在Top 20内的节点监控,不建议您在该页面过滤或切换大盘,请单击页面右上角更多监控,跳转至高级监控控制台获取更多监控指标及相关信息。
查看基础监控详情
查看基础监控页签,选择资源类型和监控时段,查看该类别的资源在对应时段内的监控详情。
您也可以单击自定义,选择开始时间和结束时间,单击确定,查看自定义时间段内的监控详情。
说明Elasticsearch实例的监控报警默认为开启状态,因此您可以在集群监控页面查看历史监控数据。目前只保留30天内的监控信息,并且提供分钟粒度的数据。
集群的主要监控指标包含(实际以控制台为准):
集群状态(value)
指标含义
集群状态指标展示了集群的健康度,数值为0.00时表示正常。此监控指标必须配置,配置方法请参见配置集群报警。指标各数值的含义如下。
数值 | 颜色 | 状态 | 说明 |
2.00 | 红色 | 不是所有的主分片都可用。 | 表示该集群中某个或某几个索引的主分片丢失(unassigned)。 |
1.00 | 黄色 | 所有主分片可用,但不是所有副本分片都可用。 | 表示该集群中某个或某几个索引的副本分片丢失(unassigned)。 |
0.00 | 绿色 | 所有主分片和副本分片都可用。 | 表示该集群中的所有索引都很健康,不存在丢失(unassigned)的分片。 |
表中的颜色是指在实例的基本信息页面所看到的集群状态的颜色。
指标异常原因
监控期间,当指标数值不为0.00时,表示集群状态异常,常见原因如下:
节点的CPU或HeapMemory使用率过高,甚至达到100%。
节点的磁盘使用率过高,例如超过85%,甚至达到100%。
节点的load_1m负载过高。
集群中索引的健康度出现过非健康(非绿色)状态。
异常处理建议
在Kibana控制台的Monitoring页面查看监控信息,或者查看实例的日志,获取问题的具体信息,并排查解决(例如索引占用内存太大,可删除一些索引)。
对于磁盘使用率过高导致集群异常的情况,建议参见集群磁盘使用率过高和read_only问题的排查与处理方法排查解决。
对于1核2 GB规格的实例,遇到实例状态不正常的问题时,建议先按照1:4(CPU:Mem)的规格升配集群,增大实例规格。升配后,如果状态依然异常,建议参见以上两种方案排查解决。
慢查询耗时分布
指标含义
慢查询耗时分布指标展示了集群在每500ms内,慢查询的数量分布。
例如:获取2021.10.15~2021.10.16区间内慢查询分布,0ms≤search_time_ms(慢查询耗时)<500ms,此区间分布了10000条慢查询日志;500ms≤search_time_ms(慢查询耗时)<1000ms,此区间分布了20000条慢查询日志。耗时分布时间按照500ms间隔进行累加。
指标异常原因
监控期间,当区间慢查询耗时,查询数量增大时,服务异常,常见原因如下:
指标异常原因 | 说明 |
QPS | 查询QPS或写入QPS流量突增或波动较大,集群压力大,相对单条查询耗时久。 |
有agg查询或者有脚本查询 | 聚合查询场景,需要耗用大量的计算资源做数据聚合,尤其是内存,在使用时请注意。 |
term查询数值字段 | 大批量的数值型byte、short、integer、long字段做term查询时,在构造docid集合的bitset很耗时,会影响查询速度。如果该数值字段没有range和agg聚合需求,建议改为keyword类型字段。 |
模糊匹配 | 通配符和正则表达式、模糊查询,需要遍历倒排索引中的词条列表来找到所有的匹配词条,进而逐个词条地收集对应的文档ID。尤其在未压测的前提下,大批量的查询,会耗用大量的计算资源,建议使用前结合场景压测,选择合适的量级。 |
存在个别慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较小或不明显,可在阿里云Elasticsearch控制台中的查询日志页面,单击searching慢日志查看分析。 |
集群中存在大量索引或总分片数量非常多 | 由于Elasticsearch会监控集群中的索引并写入日志,因此当总索引或总分片数量过多时,容易引起CPU或HeapMemory使用率过高,或load_1m负载过高,影响整个集群查询速度。 |
在集群上执行过Merge操作 | Merge操作会消耗CPU资源,对应节点的Segment Count会突降,可在Kibana控制台中节点的Overview页面查看。 |
执行过gc操作 | gc操作会尝试释放内存(例如full gc),消耗CPU资源,可能会导致CPU使用率突增,影响查询速度。 |
执行过定时任务 | 数据备份或其他自定义任务,需要占用大量的IO资源,影响查询速度。 |
集群写入QPS(Count/Second)
如果写入QPS流量突增,可能引起CPU使用率、HeapMemory使用率或load_1m负载过高,影响集群服务,请尽量避免这种情况。
指标含义
集群写入QPS指标展示了集群每秒写入文档的数量。具体说明如下:
如果1秒内,客户端向集群发送了1个只包含单个文档的写入请求,则对应1个写入QPS。如果1秒内发送了多个写入请求,则累加统计。
如果1秒内,通过_bulk API在一个写入请求中批量写入了多个文档,则写入QPS参考该请求中批量推送的总文档个数。如果1秒内发送了多个_bulk API批量写入请求,则累加统计。
集群查询QPS(Count/Second)
如果查询QPS流量突增,可能引起CPU使用率、HeapMemory使用率或load_1m负载过高,影响集群服务,请尽量避免这种情况。
指标含义
集群查询QPS指标展示了集群每秒执行的查询QPS数量,查询QPS数量与待查询索引的主分片个数有关。
例如:待查询索引有5个主分片,则一次查询请求对应5个QPS。
index bulk写入tps
指标含义
index bulk写入tps指标展示了索引每秒bulk的请求量。
指标异常原因
监控期间,该指标可能存在没数据,常见原因如下:
集群压力大,影响集群监控数据的正常采集。
监控数据未成功推送。
index查询QPS
指标含义
index查询QPS指标展示了索引每秒执行的查询QPS数量,查询QPS数量与待查询索引的主分片个数有关。
例如:待查询索引有5个主分片,则一次查询请求对应5个QPS。
指标异常原因
监控期间,该指标可能存在没数据,常见原因如下:
集群压力大,影响集群监控数据的正常采集。
监控数据未成功推送。
索引查询QPS流量突增,可能就是该索引引起了集群CPU使用率、HeapMemory使用率或load_1m负载过高,影响整个集群服务,可以针对该索引进行优化。
节点CPU使用率(%)
指标含义
节点CPU使用率指标展示了集群中各节点的CPU使用率百分比。当CPU使用率较高或接近100%时,会影响集群服务。
指标异常原因
监控期间,当指标数值突增或波动较大时,服务异常,常见原因如下:
指标异常原因 | 说明 |
QPS | 查询QPS或写入QPS流量突增或波动较大。 |
存在个别慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较小或不明显,可在阿里云Elasticsearch控制台中的日志查询页面,单击searching慢日志查看分析。 |
集群中存在大量索引或总分片数量非常多 | 由于Elasticsearch会监控集群中的索引并写入日志,因此当总索引或总分片数量过多时,容易引起CPU或HeapMemory使用率过高,或load_1m负载过高。 |
在集群上执行过Merge操作 | Merge操作会消耗CPU资源,对应节点的Segment Count会突降,可在Kibana控制台中节点的Overview页面查看。 |
执行过gc操作 | gc操作会尝试释放内存(例如full gc),消耗CPU资源。可能会导致CPU使用率突增。 |
执行过定时任务 | 数据备份或其他自定义任务。 |
节点CPU使用率不仅包含了阿里云Elasticsearch系统级别的资源的占用情况,也包含了Elasticsearchs任务的资源占用情况。
节点HeapMemory使用率(%)
指标含义
节点HeapMemory使用率指标展示了集群中各节点的HeapMemory使用率百分比。当HeapMemory使用率较高或存在较大的内存对象时,会影响集群服务,也会自动触发gc操作。
指标异常原因
监控期间,当指标数值突增或波动较大时,服务异常,常见原因如下:
指标异常原因 | 说明 |
QPS | 查询QPS或写入QPS流量突增或波动较大。 |
存在个别慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较小或不明显,可在阿里云Elasticsearch控制台中的日志查询页面,单击searching慢日志查看分析。 |
存在大量慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较大或很明显,可在阿里云Elasticsearch控制台中的日志查询页面,单击indexing慢日志查看分析。 |
集群中存在大量索引或总分片数量非常多 | 由于Elasticsearch会监控集群中的索引并写入日志,因此当总索引或总分片数量过多时,容易引起CPU或HeapMemory使用率过高,或load_1m负载过高。 |
在集群上执行过Merge操作 | Merge操作会消耗CPU资源,对应节点的Segment Count会突降,可在Kibana控制台中节点的Overview页面查看。 |
执行过gc操作 | gc操作会尝试释放内存(例如full gc),消耗CPU资源。可能会导致HeapMemory使用率突降。 |
执行过定时任务 | 数据备份或其他自定义任务。 |
节点load_1m(value)
指标含义
节点load_1m指标展示了集群中各节点在1分钟内的负载情况,表示各节点的系统繁忙程度。该指标的正常数值,应该低于对应节点规格的CPU核数。以单核的Elasticsearch节点为例,指标各数值的含义如下。
节点load_1m | 说明 |
<1 | 没有等待的进程。 |
=1 | 系统无额外的资源运行更多的进程。 |
>1 | 进程拥堵,等待资源。 |
节点load_1m指标不仅包含了阿里云Elasticsearch系统级别的资源的占用情况,也包含了Elasticsearch任务的资源占用情况。
节点load_1m指标出现波动可能是正常情况,建议您重点关注节点CPU使用率指标进行分析。
指标异常原因
监控期间,当指标数值超过节点规格的CPU核数时,服务异常,常见原因如下:
节点的CPU或HeapMemory使用率过高,甚至达到100%。
查询QPS或写入QPS流量突增或上涨较大。
存在耗时较大的慢查询。
可在阿里云Elasticsearch控制台中的日志查询页面,打开对应日志查看分析。
节点load_1m不仅包含了阿里云Elasticsearch系统级别的资源的占用情况,也包含了Elasticsearchs任务的资源占用情况。
节点磁盘使用率(%)
指标含义
节点磁盘使用率指标展示了集群中各节点的磁盘使用率百分比。建议将磁盘使用率报警阈值控制在75%以下,不要超过85%。否则默认数据节点的磁盘使用率可能会出现以下情况,影响集群服务。
节点磁盘使用率 | 说明 |
>85% | 新的shard无法分配。 |
>90% | 集群会尝试将节点中的shard,迁移到其他磁盘使用率较低的数据节点中。 |
>95% | Elasticsearch会为集群中的每个索引强制设置 |
强烈建议您配置该监控指标,以便在发生报警时,及时扩容磁盘和节点或清理索引数据等,避免影响集群服务。
节点磁盘使用率不仅包含了阿里云Elasticsearch系统级别的资源的占用情况,也包含了Elasticsearchs任务的资源占用情况。
old区使用
指标含义
old区使用指标展示了集群中各节点堆内存old区的使用大小。当old区占用较高或存在较大的内存对象,会影响集群服务,会自动触发gc操作,大对象回收可能会出现gc耗时较长或full gc。
指标异常原因
监控期间,当指标数值突增或波动较大时,服务异常,常见原因如下:
指标异常原因 | 说明 |
QPS | 查询QPS或写入QPS流量突增或波动较大。 |
有agg查询或者有脚本查询 | 聚合查询场景,需要耗用大量的计算资源做数据聚合,尤其是内存,在使用时请注意。 |
term查询数值字段 | 大批量的数值型byte、short、integer、long字段做term查询时,在构造docid集合的bitset很费时,会影响查询速度。如果该数值字段没有range和agg聚合需求,建议改为keyword类型字段。 |
模糊匹配 | 通配符和正则表达式、模糊查询,需要遍历倒排索引中的词条列表来找到所有的匹配词条,进而逐个词条地收集对应的文档ID。尤其在未压测的前提下,大批量的查询,会耗用大量的计算资源,建议使用前结合场景压测,选择合适的量级。 |
存在个别慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较小或不明显,可在阿里云Elasticsearch控制台中的查询日志页面,单击searching慢日志查看分析。 |
存在大量慢查询或慢写入请求 | 此情况下,查询和写入QPS流量波动较小或不明显,可在阿里云Elasticsearch控制台中的查询日志页面,单击indexing慢日志查看分析。 |
集群中存在大量索引或总分片数量非常多 | 由于Elasticsearch会监控集群中的索引并写入日志,因此当总索引或总分片数量过多时,容易引起CPU或HeapMemory使用率过高,或load_1m负载过高。 |
在集群上执行过Merge操作 | Merge操作会消耗CPU资源,对应节点的Segment Count会突降,可在Kibana控制台中节点的Overview页面查看。 |
执行过gc操作 | gc操作会尝试释放内存(例如full gc),消耗CPU资源,可能会导致HeapMemory使用率突降。 |
执行过定时任务 | 数据备份或其他自定义任务。 |
old gc频次
指标含义
old gc频次指标表示集群中各个节点old区gc回收数量,当old区占用较高或存在较大的内存对象,会影响集群服务,会自动触发gc操作,大对象回收可能会出现gc耗时较长或full gc。
基础监控指标full gc通过日志获取,高级监控中内存指标依赖ES引擎采集,两者获取方式及应用存在差异,建议结合所有指标综合判断集群性能。
指标异常原因
请参见old区使用的指标异常原因。
old gc耗时
指标含义
old gc耗时指标表示集群中各个节点old区gc回收平均耗时,当old区占用较高或存在较大的内存对象,会自动触发gc操作,大对象回收可能会出现gc耗时较长或full gc。
指标异常原因
请参见old区使用的指标异常原因。
fielddata内存使用
指标含义
fielddata内存使用指标表示集群中fielddata内存占用情况,监控曲线越高,说明堆内存存在大量的fielddata数据缓存,过大的fielddata内存占用会触发fielddata内存熔断,影响集群稳定性。
指标异常原因
监控期间,当指标占用大量的堆内存时,可能会出现服务异常,常见原因如下:
查询中存在大量对字符串(text)字段做排序或者聚合的操作,该类查询fielddata默认不会被回收,建议使用数值型字段类型。
查询QPS或写入QPS流量突增或波动较大,fielddata数据频繁的进行缓存。
集群中存在大量索引或总分片数量非常多。由于Elasticsearch会监控集群中的索引并写入日志,因此当总索引或总分片个数过多时,容易引起CPU或HeapMemory使用率过高,或load_1m负载过高。
FullGc次数(count)
当系统出现频繁full gc时,会影响集群服务。
指标含义
FullGc次数指标展示了集群中1分钟内的gc总次数。
指标异常原因
监控期间,当指标数值不为0时,服务异常,常见原因如下:
HeapMemory使用率较高。
存在较大的内存对象。
Exception次数(count)
指标含义
Exception次数指标展示了集群的主日志中,一分钟内出现的警告级别日志的总个数。
指标异常原因
监控期间,当指标数值不为0时,服务异常,常见原因如下:
查询请求可能存在异常。
写入请求可能存在异常。
Elasticsearch执行任务时,遇到异常。
执行过gc操作。
异常处理建议
可在阿里云Elasticsearch控制台中的日志查询页面,单击主日志。在主日志页面,根据时间点查看详细异常信息,并分析异常原因。
如果主日志中有gc记录,也会在Exception次数监控指标中统计展示。
快照状态(value)
指标含义
快照状态指标展示了Elasticsearch控制台中,自动备份功能的快照状态。当指标数值为-1或0时,表示服务正常。指标各数值的含义如下。
快照状态 | 说明 |
0 | 有快照。 |
-1 | 没有快照。 |
1 | 正在进行快照。 |
2 | 快照任务失败。 |
指标异常原因
指标数值为2时,服务异常,常见原因如下:
节点磁盘使用率很高或接近100%。
集群不健康。
节点网络流入包(count)
节点网络流入包指标展示了集群中各节点网络流入流量包的数量。监控周期:1分钟。
节点网络流出包(count)
节点网络流出包指标展示了集群中各节点网络从流量包流出的数量。监控周期:1分钟。
数据流入率(KB/s)
数据流入率指标展示了集群中各节点每秒数据包的流入速率。监控周期:1分钟,单位:KB/s。
数据流出率(KB/s)
数据流出率指标展示了集群中各节点每秒数据包的流出速率。监控周期:1分钟,单位:KB/s。
节点TCP链接数(count)
指标含义
节点TCP链接数指标展示了集群中各节点收到的客户端每次发起TCP连接请求的数量。
指标异常原因
监控期间,当指标数值突增或波动较大时,服务异常,常见原因为:客户端发起TCP连接长时间未释放,导致节点TCP连接数量突增。建议客户端设置相关策略进行释放。
IOUtil(%)
指标含义
IOUtil指标展示了集群中各节点的IO使用率达到多少百分比。
指标异常原因
监控期间,当指标数值突增或波动较大时,服务异常,常见原因为:磁盘使用率过高,读取和写入数据的平均等待时间过长,导致IO使用率突增,甚至达到100%。建议您根据集群具体情况,并结合其他指标数据进行处理,例如进行集群升配等。
每秒完成的读请求数量(count)
每秒完成的读请求数量指标展示了集群中各节点每秒完成的读请求数量。
每秒钟读取的大小(MB/s)
每秒钟读取的大小指标展示了每秒从集群中各节点读取的数据量。
每秒完成的写请求数量(count)
每秒完成的写请求数量指标展示了集群中各节点每秒完成的写请求数量。
每秒钟写入的大小(MB/s)
每秒钟写入的大小指标展示了每秒向集群中各节点写入的数据量。
常见问题
Q:高级监控报警中的慢查询条数指标的含义是什么?
A:以下图为例,12表示当前过滤的时间段内,最后一个时刻的慢日志的条数;254表示当前过滤的时间段内慢日志的条数总和。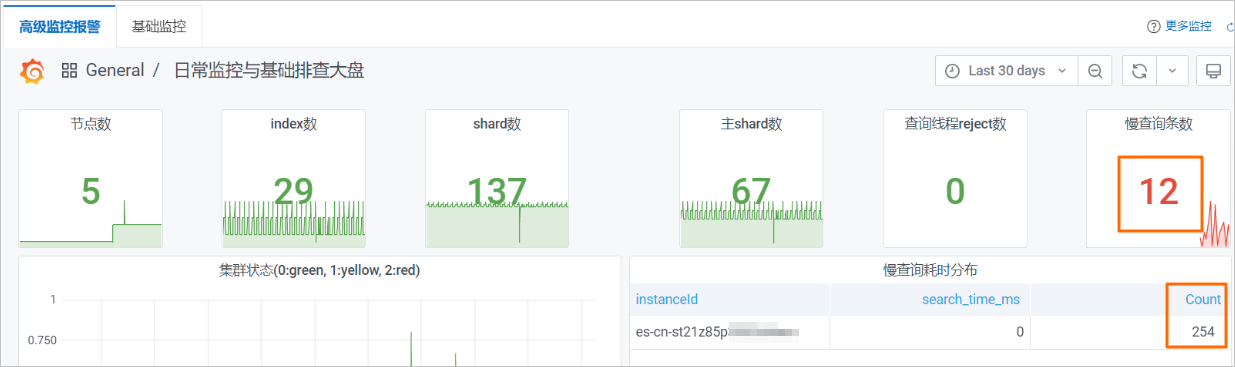
- 本页导读 (1)