Sync data from an OceanBase database to Kafka
This topic describes how to use Data Transmission Service (DTS) to sync data from an OceanBase database to Kafka.
Background information
Kafka is a widely used high-performance distributed stream computing platform. DTS supports real-time data synchronization between both tenant types of OceanBase databases and self-managed Kafka data sources. This extends message processing capabilities and is widely used in scenarios such as building real-time data warehouses, data queries, and report offloading.
Prerequisites
DTS must have the required cloud resource access permissions. For more information, see Grant permissions to a DTS migration role.
Create a database user for the data sync task in the source OceanBase database and grant the required permissions to the user. For more information, see Create a database user.
Limits
Data synchronization is supported only for physical tables. Other objects are not supported.
DTS supports Kafka versions V0.9, V1.0, and V2.x.
If you rename a table at the source during data synchronization, and the new name is not included in the sync objects, the data from that table is not synced to the destination Kafka instance.
The names of the tables and columns to be synced cannot contain Chinese characters.
DTS supports migrating only objects whose database, table, and column names contain ASCII characters. These names cannot contain special characters such as line breaks, spaces, or .|"'`()=;/&\.
DTS does not support using a secondary OceanBase database as the source.
Notes
In a data sync task with an OceanBase database as the source and DDL synchronization enabled, if a table is renamed at the source using the
RENAMEoperation, you must restart the task to prevent data loss during incremental synchronization.If your OceanBase database version is between V4.0.0 and V4.3.x (excluding V4.2.5 BP1) and you select incremental synchronization, you must configure the STORED property for generated columns. Otherwise, information about generated columns is not saved in the incremental logs, which may cause data anomalies during incremental synchronization.
When an updated row includes a LOB column:
If the LOB column is an updated column, do not rely on its value before the
UPDATEorDELETEoperation.Data types that use LOB columns for storage include JSON, GIS, XML, User Defined Type (UDT), and various TEXT types such as LONGTEXT and MEDIUMTEXT.
If the LOB column is not an updated column, its value is NULL both before and after the
UPDATEorDELETEoperation.
If the clocks are not synchronized between nodes, or between your computer and the server, the incremental sync latency may be inaccurate.
For example, if a clock is ahead of the standard time, the latency may become a negative value. If a clock is behind the standard time, it may cause latency issues.
When a task is unexpectedly interrupted and resumes from a breakpoint, some duplicate data from the last minute may exist in the Kafka instance. Therefore, your downstream system must be able to remove duplicates.
When syncing data from an OceanBase database to Kafka, if a statement to create a unique index fails at the source, Kafka consumes both the create DDL statement and the delete DDL statement. If the create index DDL statement fails when it is passed to the downstream system, you can ignore the exception.
If you configure only Incremental Synchronization when you create the data sync task, DTS requires that the local incremental logs of the source database be retained for more than 48 hours.
If you configure Full Synchronization + Incremental Synchronization when you create a data synchronization task, DTS requires the local incremental logs of the source database to be retained for at least 7 days. Otherwise, DTS may be unable to retrieve the incremental logs, which can cause the data synchronization task to fail or lead to data inconsistency between the source and destination.
Supported source and destination instance types
In the following table, the MySQL tenant of an OceanBase database is referred to as OB_MySQL, and the Oracle tenant is referred to as OB_Oracle.
Source | Destination |
OB_MySQL (OceanBase cluster instance) | Kafka (Alibaba Cloud Kafka instance) |
OB_MySQL (OceanBase cluster instance) | Kafka (Self-managed Kafka instance in a VPC) |
OB_MySQL (OceanBase cluster instance) | Kafka (Kafka instance on the Internet) |
OB_MySQL (Serverless instance) | Kafka (Alibaba Cloud Kafka instance) |
OB_MySQL (Serverless instance) | Kafka (Self-managed Kafka instance in a VPC) |
OB_MySQL (Serverless instance) | Kafka (Kafka instance on the Internet) |
OB_Oracle (OceanBase cluster instance) | Kafka (Alibaba Cloud Kafka instance) |
OB_Oracle (OceanBase cluster instance) | Kafka (Self-managed Kafka instance in a VPC) |
OB_Oracle (OceanBase cluster instance) | Kafka (Kafka instance on the Internet) |
Supported DDL synchronization scope
Create table
CREATE TABLEImportantThe created table must be within the scope of the sync objects. Currently, you can only perform a
CREATE TABLEoperation after aDROP TABLEoperation has been performed on a synced table.Alter table
ALTER TABLEDrop table
DROP TABLETruncate table
TRUNCATE TABLENoteIn a delayed deletion scenario, two identical
TRUNCATE TABLEDDL statements may exist in the same transaction. In this case, the downstream consumer must process them idempotently.Delete data from a specified partition
ALTER TABLE…TRUNCATE PARTITIONCreate index
CREATE INDEXDrop index
DROP INDEXAdd a comment to a table
COMMENT ON TABLERename table
RENAME TABLEImportantThe new table name must be within the scope of the sync objects.
Procedure
Log on to the OceanBase Management Console and purchase a data sync task.
For more information, see Purchase a data sync task.
In the Data Transmission Service console, navigate to the Data Synchronization page, find the new sync task, and click Configure.

If you want to reuse the configurations of an existing task, click Reuse Configuration. For more information, see Reuse and clear the configurations of a data sync task.
On the Select Source and Target page, set the parameters.
Parameter
Description
Sync Task Name
We recommend using a combination of letters, numbers, and Chinese characters. The name cannot contain spaces and must not exceed 64 characters.
Source
If you have already created an OceanBase data source, select it from the drop-down list. If you have not, click Create Data Source in the drop-down list and create a new one in the dialog box on the right. For more information about the parameters, see Create an OceanBase data source.
ImportantThe source type does not support OceanBase databases whose Instance Type is OceanBase Tenant Instance.
Destination
If you have created a Kafka data source, select it from the drop-down list. If not, click Create Data Source in the drop-down list to create one in the dialog box that appears on the right. For details about the parameters, see Create a Kafka data source.
Tag (Optional)
Click the text box and select the target tag from the drop-down list. You can also click Manage Tags to create, modify, and delete tags. For more information, see Manage data synchronization tasks using tags.
Click Next. On the Select Synchronization Type page, select a synchronization type for the task.
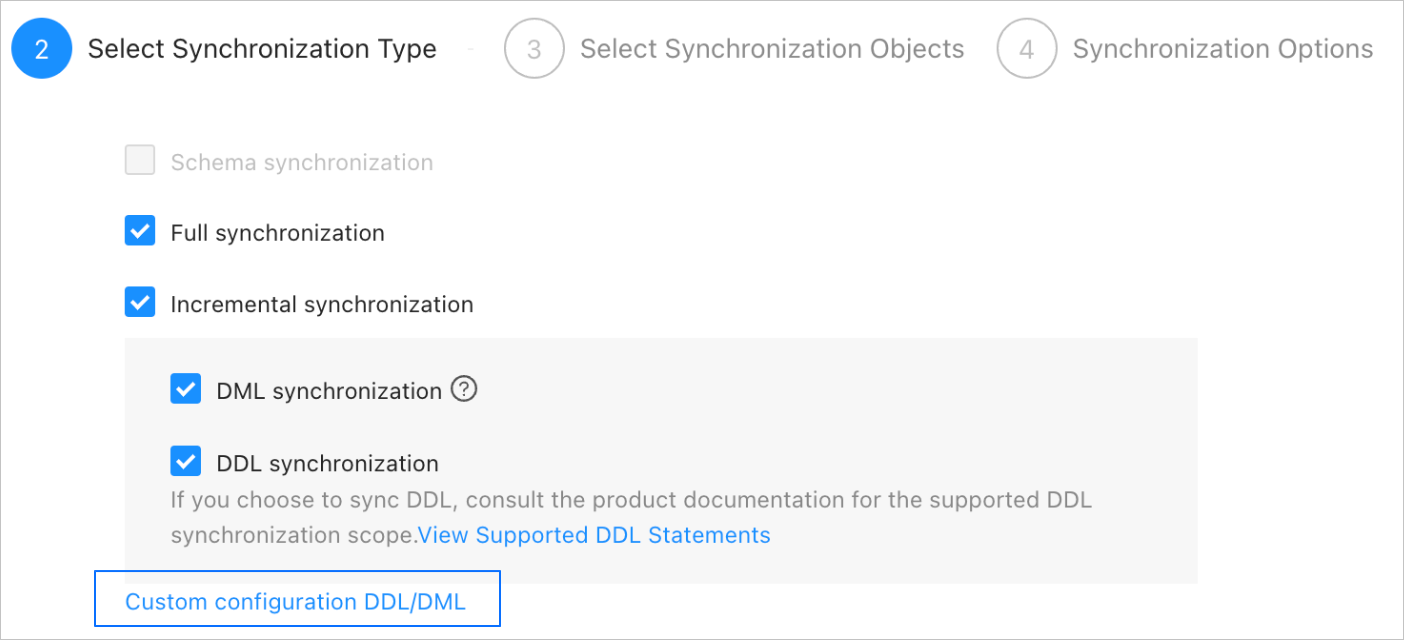
There are two synchronization types: Full Synchronization and Incremental Synchronization. Incremental Synchronization supports DML Synchronization (such as
INSERT,DELETE, andUPDATE) and DDL Synchronization. You can customize the configuration based on your requirements. For more information, see Customize DDL and DML.Click Next. On the Select Synchronization Objects page, select the objects to synchronize.
You can select objects for synchronization using two methods: Specify Objects and Matching Rules. This topic describes the procedure for selecting objects using the Specify Objects method. For more information about how to configure matching rules for database-to-message queue synchronization, see Configure and Modify Matching Rules.
NoteIf you select DDL Synchronization in the Select Synchronization Type step, we recommend that you select objects using matching rules. This ensures that new objects that match the rules are also synchronized. If you select objects individually, new or renamed objects will not be synchronized.
When you sync data from an OceanBase database to Kafka, you can sync multiple tables to multiple topics.
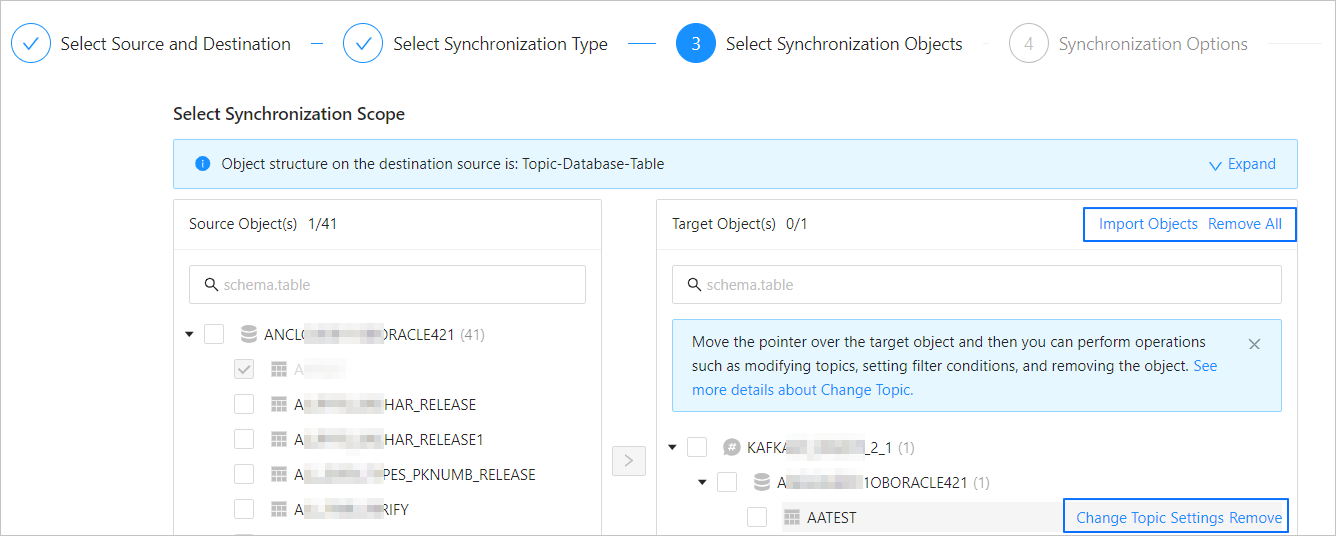
In the Select Sync Objects area, select Specify Objects.
In the selection area on the left, select the objects to sync.
Click >.
In the Map Object To Topic dialog box, from the Existing Topic drop-down list, search for and select the Topic to sync.
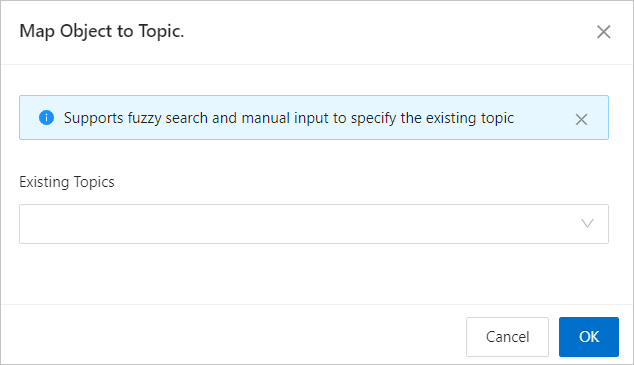
Click OK.
DTS lets you import objects from a text file and perform operations on the destination objects, such as changing the topic, setting row filters, and removing single or all objects. The structure of the destination objects is Topic > Database > Table.
NoteWhen you select synchronization objects using the Matching Rules method, the renaming capability is overwritten by the matching rule syntax. In the Actions section, you can only set filter conditions, select sharding columns, and specify the columns for synchronization. For more information, see Configure and modify matching rules.
Operation
Description
Import Objects
In the list on the right side of the selection area, click Import Objects in the upper-right corner.
In the dialog box that appears, click OK.
ImportantImporting objects overwrites previous selections. Proceed with caution.
In the Import Sync Objects dialog box, import the objects to sync. You can import a CSV file to set row filtering conditions, filter columns, and set sharding columns. For more information, see Download and import sync object configurations.
Click Validate.
After the validation is successful, click OK.
Change Topic
DTS lets you change the topic for destination objects. For more information, see Change a topic.
Settings
DTS supports row filtering using a
WHEREclause, and lets you select sharding columns and columns to sync.In the Settings dialog box, you can perform the following operations.
In the Row Filter Condition area, enter a standard SQL
WHEREclause in the text box to configure row filtering. For more information, see Filter data using SQL conditions.In the Sharding Column drop-down list, select the target sharding column. You can select multiple fields as the sharding column. This parameter is optional.
When selecting sharding columns, if there are no special requirements, you can simply select the primary key. If the primary key causes a load imbalance, select a field that is unique and relatively balanced as the sharding column to avoid potential performance issues. The main functions of sharding columns are as follows:
Load balancing: If concurrent writes are possible at the destination, the sharding column is used to determine the specific thread for sending a message.
Ordering: Because concurrent writes can cause out-of-order issues, DTS ensures that messages with the same sharding column value are received in order. Ordering here refers to the order of changes (the execution order of DML operations on a column).
In the Select Columns area, select the columns to sync. For more information, see Column Filtering.
Remove/Remove All
DTS lets you remove one or more objects that have been temporarily selected for the destination during data mapping.
Remove a single sync object
In the list on the right side of the selection area, hover over the target object and click the Remove button that appears.
Remove all sync objects
In the list on the right side of the selection area, click Remove All in the upper-right corner. In the dialog box, click OK to remove all synchronization objects.
Click Next and configure the parameters on the Sync Options page.
Full synchronization
The following parameters are displayed only if you select Full Synchronization on the Choose Synchronization Types page.

Parameter
Description
Read Concurrency
This parameter specifies the number of concurrent threads for reading data from the source during full synchronization. The maximum value is 512. A high concurrency may put excessive pressure on the source and affect your business.
Write Concurrency
This parameter specifies the number of concurrent threads for writing data to the destination during full synchronization. The maximum value is 512. A high concurrency may put excessive pressure on the destination and affect your business.
Full Synchronization Rate Limit
You can decide whether to enable the full synchronization rate limit as needed. If you enable it, set RPS (the maximum number of data rows that can be synchronized to the destination per second during full synchronization) and BPS (the maximum data volume that can be synchronized to the destination per second during full synchronization).
NoteThe RPS and BPS values set here are only for rate limiting. The actual performance of full synchronization is affected by factors such as the source, destination, and instance specifications.
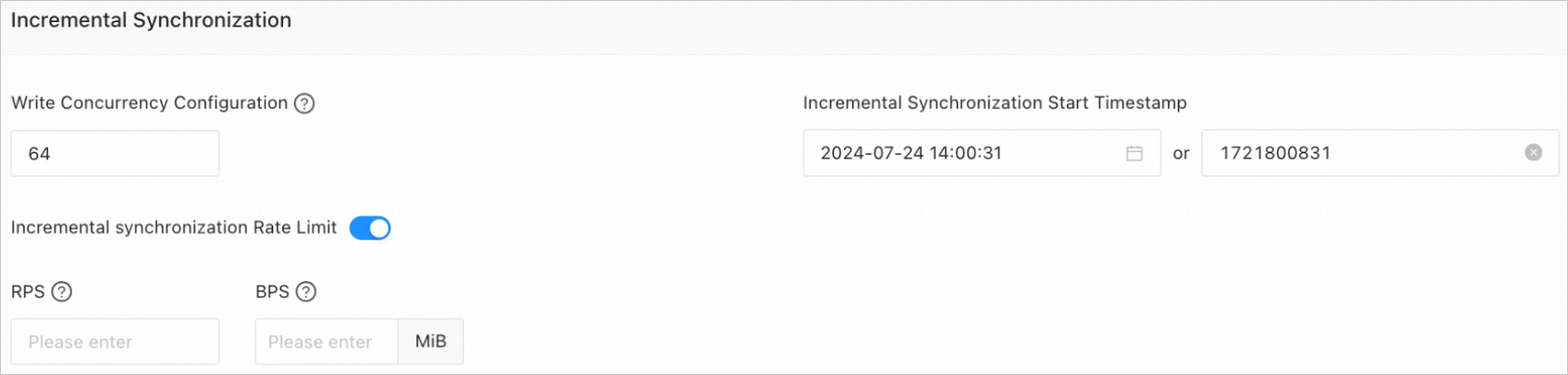
Incremental synchronization
The following parameters are displayed only if you select Incremental Synchronization on the Choose Synchronization Types page.

Parameter
Description
Write Concurrency
This parameter specifies the number of concurrent threads for writing data to the destination during incremental synchronization. The maximum value is 512. A high concurrency may put excessive pressure on the destination and affect your business.
Incremental Synchronization Rate Limit
You can decide whether to enable the incremental synchronization rate limit as needed. If you enable it, set RPS (the maximum number of data rows that can be synchronized to the destination per second during incremental synchronization) and BPS (the maximum data volume that can be synchronized to the destination per second during incremental synchronization).
NoteThe RPS and BPS values set here are only for rate limiting. The actual performance of incremental synchronization is affected by factors such as the source, destination, and instance specifications.
Incremental Synchronization Start Offset
If you select Full Synchronization when you select the synchronization type, you cannot change this parameter.
If you do not select Full Synchronization but select Incremental Synchronization when you select the synchronization type, specify a point in time after which you want to synchronize data. The default value is the current system time. For more information, see Set the start offset for incremental synchronization.
Advanced Options
Parameter
Description
Serialization Method
Specifies the message format for data synchronized to Kafka. The supported formats are Default, Canal, DataWorks (supports V2.0), SharePlex, DefaultExtendColumnType, Debezium, DebeziumFlatten, DebeziumSmt, and Avro. For more information, see Data formats.
ImportantCurrently, only OceanBase MySQL tenants support Debezium, DebeziumFlatten, DebeziumSmt, and Avro.
When you select DataWorks, DDL synchronization does not support
COMMENT ON TABLEorALTER TABLE…TRUNCATE PARTITION.
Partitioning Rule
The supported rules for synchronizing data from an OceanBase database to a Kafka Topic are Hash, Table, and One. For DDL statement delivery and examples in different scenarios, see the description below the table.
Hash means that data transmission uses a hash algorithm to select a Kafka topic partition based on the primary key value or the sharding column value.
Table: Ships all data from a single table to the same partition using the table name as the hash key.
One means that JSON messages are delivered to a single partition of the Topic to preserve the order.
Business System Identifier (Optional)
This parameter is displayed only when you set Serialization Method to DataWorks. It is used to identify the source business system of the data for subsequent custom processing. The business system identifier must be 1 to 20 characters in length.
The following table describes how DDL statements are delivered in different scenarios.
Partitioning Rule
DDL statement that involves multiple tables
(for example, RENAME TABLE)
DDL statement for which the related table cannot be identified
(for example, DROP INDEX)
DDL statement that involves a single table
Hash
The DDL statement is delivered to all partitions of the topics that contain the related tables.
For example, if a DDL statement involves tables A, B, and C, where A is in Topic 1, B is in Topic 2, and C is not in this task, the DDL statement is delivered to all partitions of Topic 1 and Topic 2.
The DDL statement is delivered to all partitions of all topics in the task.
For example, if a DDL statement cannot be identified by DTS and the current task has three topics, the DDL statement is delivered to all partitions of these three topics.
The DDL statement is delivered to all partitions of the topic to which the table belongs.
Table
The DDL statement is delivered to the partition corresponding to the hash value of the table name in the topics that contain the related tables.
For example, if a DDL statement involves tables A, B, and C, where A is in Topic 1, B is in Topic 2, and C is not in this task, the DDL statement is delivered to the partitions corresponding to the hash values of the related tables in Topic 1 and Topic 2.
The DDL statement is delivered to all partitions of all topics in the task.
For example, if a DDL statement cannot be identified by DTS and the current task has three topics, the DDL statement is delivered to all partitions of these three topics.
The statement is hashed based on the table name and delivered to a specific partition within the topic to which the table belongs.
One
The DDL statement is delivered to a fixed partition of the topics that contain the related tables.
For example, if a DDL statement involves tables A, B, and C, where A is in Topic 1, B is in Topic 2, and C is not in this task, the DDL statement is delivered to a fixed partition of Topic 1 and Topic 2.
The DDL statement is delivered to a fixed partition of all topics in the task.
For example, if a DDL statement cannot be identified by DTS and the current task has three topics, the DDL statement is delivered to a fixed partition of these three topics.
The DDL statement is delivered to a fixed partition of the topic to which the table belongs.
Click Precheck.
In the Precheck step, Data Transmission Service verifies the connectivity between the source and the destination. If the precheck fails:
You can troubleshoot and resolve the issues, and then run the precheck again.
You can also click Skip in the Actions column for a failed precheck item. A dialog box appears and explains the specific impact of skipping this operation. To confirm skipping the item, click OK in the dialog box.
After the precheck passes, click Start Task.
If you do not need to start the task right away, click Save. You can then start the task manually on the Sync Task List page or include it in a batch operation. For more information about batch operations, see Perform batch operations on data sync tasks.
DTS lets you modify the synchronization objects while a data sync task is running. For more information, see View and modify synchronization objects and their filter conditions. After the data sync task starts, it runs based on the selected synchronization types. For more information, see View synchronization details.
If a data sync task fails, typically due to network connection issues or a slow process startup, you can click Resume on the task list or the product page.