
ACK默认集成了阿里云可观测产品,提供多种可观测功能,帮您快速构建容器场景的运维体系。您可以通过本文推荐的基础功能快速搭建容器可观测体系,也可深入阅读各章节内容,构建覆盖ACK集群基础设施数据面(Data Plane)、控制面(Control Plane)及业务系统(Application)的完整监控体系,进而提升整体稳定性。
可观测性介绍
为了保障系统在其环境发生变化时仍能持续稳定地运行并满足需求,我们需要通过可观测性来及时观测和响应故障、预防或(手动、自动)恢复故障,并具备相应的扩展能力。可观测性提供能够反映集群资源的实体状态、事件的实时数据,例如指标Metrics、日志Logging、调用链路Tracing等,帮助保障稳定性、故障快速排查、系统性能调优等。从容器场景来看,可观测性可以分为4个层次:基础设施层、操作系统层、容器或集群层以及应用层。
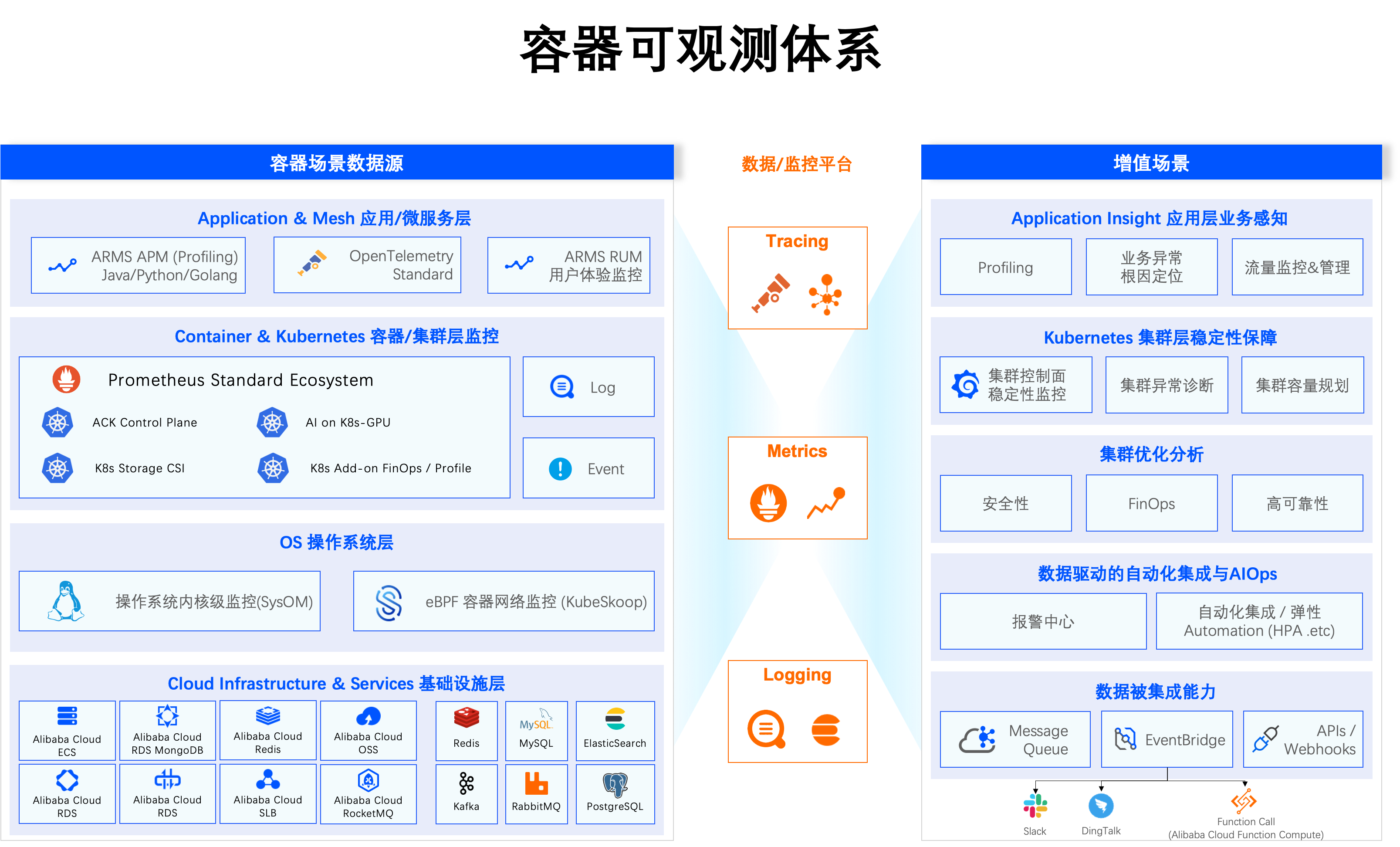
从可观测性的角度,维护容器集群的稳定性可以分为以下3个层面。
-
集群基础设施控制面(Control Plane)
-
集群的kube-apiserver 、etcd、kube-scheduler、kube-controller-manager、cloud-controller-manager组件的健康状态与承载能力。
-
集群控制面组件提供服务相关的关键资源,如 kube-apiserver的SLB带宽、连接数等。
-
-
集群基础设施数据面(Data Plane)
-
集群节点的健康状况,如节点的异常状态、资源异常、节点GPU坏卡、节点内存水位高等。
-
集群用户侧组件的稳定性,例如容器存储组件或功能、容器网络组件或功能等。
-
-
部署在集群中的用户业务系统(Application)
-
应用程序健康状况,例如用户业务的Pod和应用程序健康状况。常见异常状态包括Pod的内存不足导致的Pod或进程退出(OOM Kills)、Pod未就绪等。
-
推荐启用的功能列表
本小节介绍ACK提供的开箱即用的可观测功能,以便快速构建容器场景的运维体系。
通用稳定性场景
-
在ACK集群中部署ack-node-problem-detector组件,以开启事件监控功能。关于支持的集群检查项,请参见NPD中GPU坏卡事件、NPD支持的问题检查插件。
-
在ACK集群中部署Prometheus,包括接入与配置阿里云Prometheus监控(推荐)和开源Prometheus监控,实时监控集群和容器的健康状况。部署阿里云Prometheus后,您可以实现以下资源的监控:
-
ACK托管集群控制面组件监控
-
基础容器资源监控,包括Node、Workload、Pod。
-
-
启用事件监控和Prometheus监控后,建议进一步配置联系人、联系人组为负责集群或应用的人员,配置对应的报警规则并订阅对应的通知对象联系人组。
-
开启ECS节点云监控插件,获得ECS宿主机层基础指标监控,如进程监控、网络监控等。
-
将Pod日志接入至阿里云日志服务SLS。如果业务应用没有实现日志文件的拆分,推荐直接使用Pod的
stdout日志,请参见采集ACK集群容器日志。 -
对集群中使用Ingress进行业务应用的流量路由,开启Ingress日志明细监控大盘,请参见Nginx Ingress访问日志分析与监控。
-
对操作系统层资源进行监控,开启SysOM容器场景操作系统内核级监控功能,请参见SysOM内核层容器监控。
-
为集群中部署的重要业务开启APM应用性能监控功能,按实际应用的开发语言与环境选择对应合适的APM方案,请参见Java应用监控、Python应用监控、Golang应用监控、什么是可观测链路 OpenTelemetry 版以及对应的接入指南。
-
对于部署在容器服务中的Web应用、移动端及小程序等终端,如需实现用户体验行为监控,建议启用阿里云应用实时监控服务(ARMS)中的用户体验监控(RUM)功能,该方案支持从页面加载性能到API请求失败率的全链路追踪。
服务网格ServiceMesh场景
服务网格ServiceMesh场景下,推荐启用以下能力。
-
监控ServiceMesh数据面AccessLog日志以监控所有访问请求,请参见使用日志服务采集数据面集群AccessLog。
-
通过Prometheus监控ServiceMesh数据面的指标请参见集成可观测监控Prometheus版实现网格监控。
-
开启网络拓扑监控功能,观测并评估微服务间调用流量、时延是否符合预期,通过ServiceMesh数据面的Prometheus监控指标作为数据源,查看相关服务与配置的可视化界面,请参见开启网格拓扑提高可观测性。
-
通过定义衡量服务质量SLO等级,以观测调用的错误与延时行为,请参见SLO管理。
-
在应用代码中接入OpenTelemetry协议,并开启在ASM中实现分布式跟踪功能。
多云混合云ACK ONE场景
使用ACK One注册集群或ACK One多集群舰队构建的多云混合云场景下,推荐启用以下能力。
-
ACK One注册集群提供和ACK一致的可观测能力体验,包括将日志服务接入注册集群、将事件中心接入注册集群、将报警配置功能接入注册集群、将应用实时监控服务ARMS接入注册集群、将阿里云Prometheus接入注册集群,请参见具体文档搭建网络环境并实现监控能力。
-
为ACK One 多集群舰队开启全局监控,获得统一的监控能力。此外,还可以启用统一报警管理,保证已下发的报警规则在各个关联集群中的一致性,详情请参见多集群统一报警管理,以及支持单个子集群的多集群报警差异化配置。
-
当用户使用ACK One GitOps时,监控舰队集群的核心组件的稳定性和GitOps对全托管的Argo CD的运行和性能情况,请参见舰队监控 。并推荐开启GitOps控制面日志与审计日志,配置GitOps ArgoCD告警,请参见配置ACK One ArgoCD告警。
下文将从集群基础设施控制面(Control Plane)、集群基础设施数据面(Data Plane)、用户业务系统(Application)的稳定性体系层面分别介绍推荐的可观测具体最佳实践解决方案。
一、集群基础设施控制面(Control Plane)

Kubernetes集群控制面负责集群的API层、调度、Kubernetes资源管理、云资源管理、元数据存储等控制面功能,控制面的主要组件包括kube-apiserver、kube-scheduler、kube-controller-manager、cloud-controller-manager和etcd。
ACK托管集群的控制面由阿里云完全托管并提供SLA保障(请参见阿里云容器服务Kubernetes版服务等级协议)。为提升控制面的可观测性,帮助您更好地管理、配置和调优集群,您可以参见以下功能实时监控和观测集群控制面的负载健康状况并默认配置相关告警,从而预防异常问题的发生,保障业务的持续稳定运行。
开启控制面组件监控
ACK扩展增强了kube-apiserver组件提供的Kubernetes的RESTful API接口,使得外部客户端、集群内的其他组件(如标准的Prometheus采集)可以与ACK集群交互,从而获取集群Control Plane组件的Prometheus指标。
-
如您使用阿里云Prometheus,您可以在ACK托管集群Pro版中使用开箱即用的集群控制面监控大盘,请参见查看集群控制面组件监控大盘。
-
如您使用自建Prometheus方案,可参见通过自建Prometheus采集控制面组件指标并配置告警进行数据接入。
监控集群控制面组件日志
ACK集群支持将集群控制面组件日志收集到您账号的SLS Project中,请参见采集ACK托管集群控制面组件日志。
开启容器服务报警功能
ACK提供默认报警规则,覆盖大部分需要高优先级关注的容器场景异常,您也可自行调整报警规则。
阿里云 Prometheus、阿里云日志服务SLS以及此ACK集群相关的其他云资源的云监控的数据进行报警规则判断并通知异常,请参见容器服务报警管理。
若您使用自建Prometheus方案,可参见使用Prometheus配置报警规则的最佳实践配置报警。
二、集群基础设施数据面(Data Plane)
集群节点
ACK通过集群节点来提供业务部署资源环境。保障容器场景的稳定性时,您还需要关注每个节点的异常状态、资源负载情况等。虽然Kubernetes提供调度、抢占与驱逐等机制,在一定情况下能容忍部分节点的异常,以保证整体系统可靠性,但从稳定性角度来看,还需要更多对节点异常进行预防、观测和响应恢复的手段。
使用ack-node-problem-detector组件与事件监控
ack-node-problem-detector组件是ACK提供的用于事件监控功能的组件,兼容社区Node-Problem-Detector组件,支持在集群数据面进行节点环境异常巡检,并对ACK的节点环境、操作系统、容器引擎进行了适配增强。
ack-node-problem-detector组件提供以下功能:
-
通过组件中的node-problem-detector DaemonSet对集群节点环境、操作系统兼容性、容器引擎等进行了适配增强。
-
增强了节点巡检项功能,NPD支持的问题检查插件以插件形式提供,巡检频率时效性为1分钟内,满足大多数日常节点运维场景。
-
默认持久化事件监控数据至90天,且组件中包含kube-eventer Deployment,负责将所有集群中的Kubernetes Event上传至阿里云SLS的事件中心。默认情况下,集群内Kubernetes Event存储在etcd中,且只能查询最近1小时内事件数据。ack-node-problem-detector组件提供的持久化方式可以支持生产业务系统对历史事件的查询。
当ack-node-problem-detector组件发现节点异常状态时,您可以通过kubectl describe node ${NodeName}命令查看该节点异常Condition,或者在节点页面的节点列表查看节点异常状态。
同时,您还可以在开启了ACK事件监控功能后,使用容器服务报警管理功能,例如订阅某关键业务Pod的启动失败事件、Service的Endpoint不可用等事件。SLS监控服务还支持发送事件报警。
开启集群节点ECS进程级监控
ACK集群的每个节点的宿主机(Host)通常对应一台阿里云ECS实例,推荐为ECS实例开启阿里云云监控服务提供的进程监控功能。
云监控ECS监控提供两方面能力:
-
进程级监控能力:回溯节点历史时间点Top5的进程对内存、CPU、打开文件数等关键资源的消耗。
-
ECS宿主机的操作系统层监控能力:监控宿主机CPU、内存、网络、磁盘水位、inode数、宿主机网络流量、网络同时连接数等宿主机层面的基础资源指标。
为节点池开启云监控进程监控后,仅针对节点池中后续新增的节点生效。
开启容器服务报警管理,订阅节点异常事件、资源水位异常规则
容器服务报警管理支持集群事件监控,提供节点异常状态事件以及资源水位异常等报警配置。推荐开启并订阅其中多个与节点有关的报警规则集,例如集群节点异常报警规则集、集群资源异常报警规则集等。
节点操作系统Journal日志的监控与持久化
Systemd是Linux系统的一个初始化系统和服务管理器,负责启动系统后的所有服务。其中,Journal是Systemd的一个组成部分,用于收集和存储系统日志。在容器场景下,如需获取kubelet、操作系统层等涉及节点稳定性的关键指标日志,需通过Systemd Journal日志数据进行查询和分析。在对操作系统层、容器引擎层稳定性敏感的场景下(如业务进程使用特权容器模式、需频繁超卖节点资源等直接使用操作系统资源场景),推荐使用此方式收集操作系统层日志进行监控。请参见采集集群节点的Systemd Journal日志数据采集日志数据并将日志存储至SLS Project中。
GPU或AI训练场景
如果您在ACK集群中部署了AI训练任务、机器学习任务等,ACK提供节点GPU异常状态、GPU资源的实时指标监控等功能。推荐方案如下。
-
节点GPU坏卡巡检:推荐安装并升级ack-node-problem-detector组件版本至 1.2.20及以上。ACK支持巡检NPD中GPU坏卡事件,详情请参见NPD中GPU坏卡事件。
关于GPU异常的处理方案,请参见常见GPU故障类型与解决方案进行排查。
-
GPU资源监控:集群GPU监控提供Pod维度的GPU资源消耗情况。通过ACK的ack-gpu-exporter组件,您可以获得兼容Nvidia DCGM标准的GPU监控指标。ACK针对共享GPU和独占GPU两种场景提供Pod级别的GPU监控指标,详情请参见监控指标说明。
如需了解实现对集群GPU节点的全方位监控的详细步骤,请参见监控集群GPU资源最佳实践。
-
容器服务报警管理:开启事件监控功能,通过容器服务报警管理订阅节点GPU异常事件报警,并参见常见GPU故障类型与解决方案进行异常处理。
集群数据面系统组件(容器存储和容器网络)
容器存储
ACK集群中的容器存储方式包括节点的本地存储、Secret和ConfigMap,以及外部存储介质(例如NAS存储卷、CPFS存储卷、OSS存储卷等)。
ACK通过csi-plugin组件统一透出上述容器存储使用方式的监控指标,再通过阿里云Prometheus进行统一采集,以提供开箱即用的监控大盘,详情请参见容器存储可观测最佳实践文档。关于支持和不支持监控功能的容器存储方式,以及对应的监控方法,请参见容器存储监控概述。
容器网络
CoreDNS
CoreDNS组件是集群的DNS服务发现机制的关键组件。您需要关注集群数据面中CoreDNS组件的资源情况、CoreDNS解析异常返回码(rcode)等关键指标(如CoreDNS大盘中的 Responses (by rcode)指标)、DNS解析异常行为(NXDOMAIN、SERVFAIL、FormErr)等,以保障组件稳定性。推荐启用以下功能。
-
在ACK集群中使用阿里云Prometheus,使用开箱即用的CoreDNS监控大盘,请参见CoreDNS组件监控。自建Prometheus可以通过社区CoreDNS监控方式配置指标采集进行监控。
-
建议开启容器服务报警管理功能,并订阅如集群网络异常事件报警规则集,包括CoreDNS修改配置后若配置Load不成功等CoreDNS状态异常事件报警通知。集群容器副本异常报警规则集也覆盖CoreDNS的Pod状态、资源等问题。
-
查看CoreDNS日志来分析CoreDNS解析慢、访问高危请求域名等问题,请参见分析和监控CoreDNS日志。
Ingress
使用Ingress进行业务应用的对客流量路由时,您需要关注Ingress的流量情况和Ingress的明细调用情况,并在Ingress路由状态异常时进行报警。推荐启用以下功能。
-
在ACK集群中使用阿里云Prometheus以及阿里云容器服务的Ingress Controller,使用开箱即用的Ingress流量监控大盘。
-
通过SLS监控Ingress日志,请参见Nginx Ingress访问日志分析与监控。
-
使用ACK提供的Ingress链路追踪功能,将Nginx Ingress Controller组件的链路信息上报至可观测链路OpenTelemetry版,对链路信息进行实时聚合计算和持久化,形成链路明细、实时拓扑等监控数据,以便进行问题排查与诊断。例如,您可以参见通过AlbConfig开启Xtrace实现链路追踪观测ALB Ingress的链路追踪数据。
-
开启容器服务报警管理功能,并订阅如集群网络异常事件报警规则集,订阅Ingress路由的异常状态事件报警。
基础容器网络流量监控
ACK集群通过节点kubelet透出了社区标准的容器监控指标,包括基本的容器网络流量指标,可以满足大多数场景下的网络流量监控需求,包括容器Pod的出入流量、异常网络流量、网络包监控等。
但当应用Pod定义为HostNetwork模式时,Pod将会继承宿主机的进程网络行为,导致基础的容器监控指标无法准确反映Pod维度的网络流量。推荐启用以下功能。
-
使用阿里云Prometheus或者自建Prometheus方案监控kubelet监控指标,以获得基本的容器网络流量情况。使用阿里云Prometheus时,ACK提供开箱即用的基本网络流量监控能力,支持在Pod监控大盘中查看。
-
监控宿主机ECS的网络流量时,可参见查看实例监控信息在ECS控制台查看监控数据。
三、用户业务系统(Application)
ACK提供容器副本Pod监控、容器应用日志监控等手段,用于观测集群上部署的业务应用的稳定性。
应用容器副本Pod监控
集群上部署的业务应用以Pod的形式在集群中运行。Pod的状态和资源负载情况直接影响其上运行的应用性能。推荐启用以下功能。
-
通过Prometheus监控容器Pod状态、资源水位:通过阿里云Prometheus或自建Prometheus方案采集ACK集群通过节点kubelet透出的社区标准的容器监控指标,并结合kube-state-metrics组件(包含在阿里云Prometheus组件或ACK提供的社区prometheus-operator组件Helm Chart)透出的Kubernetes对象的状态数据,监控完整的Pod容器监控,包括Pod的CPU、Memory、存储、基础容器网络流量等监控数据。ACK集群结合阿里云Prometheus提供了开箱即用的Pod容器监控大盘。
-
通过事件监控监控容器Pod的异常状态:Pod状态发生变化时会产生事件。当Pod出现异常状态时,推荐开启事件监控监控异常信息。
您可以在控制台的事件中心页面查看时间监控,并将事件持久化至SLS事件中心,以查看历史90天的监控事件。您也可以根据Pod的事件监控大盘查看由Pod Event串联的整个Pod生命周期时间线,从而观察Pod的异常状态。
-
订阅应用工作负载和容器副本的异常状态事件报警:启用容器服务报警和管理和事件监控后,推荐同时开启并订阅其中多个与工作负载和容器副本Pod有关的报警规则集,包括集群应用工作负载报警规则集、集群容器副本异常报警规则集等。具体操作,请参见使用Prometheus配置报警规则的最佳实践。
-
自定义Prometheus报警规则,订阅资源报警:由于应用部署有多样性需求,如不同业务应用需要保持不同的水位、对不同的关键资源有特殊需求等,推荐按照实际业务应用的需求配置自定义的Prometheus指标报警。
您可以在控制台的Prometheus 监控页面右上角跳转至对应的集群Prometheus实例并创建报警规则,请参见创建Prometheus告警规则。您也可以通过Prometheus标准的PromQL自定义的报警规则,请参见容器副本异常,也可以参考其中关于工作负载异常、容器副本异常等内容的样例报警规则,修改PromQL以自定义Prometheus的报警规则。
容器应用日志监控
集群中的业务系统会产生业务日志,记录关键业务过程。监控这些业务日志有助于异常诊断排查和业务行为状态判断。
ACK提供Kubernetes日志功能,以便排查和诊断问题。ACK集群提供了无侵入的方式进行应用的日志管理,您可以参见采集ACK集群容器日志采集应用日志,并使用SLS提供的多种日志统计分析功能。
应用进程的细粒度内存资源监控
Kubernetes中,容器内存实时使用量(Pod Memory)通过Working Set Size工作内存(WSS)来表示,是Kubernetes调度机制判断容器副本内存资源分配的关键指标。WSS包含多个操作系统Kernel的内存成分(不包含Inactive(anno)),以及多个细致的操作系统层内存成分。当您的应用进程使用不同细分内存成分(如写入文件系统时产生的额外pagecache内存等)时,可能遇到内部内存“黑洞”问题,在生产系统中需要重点监控。
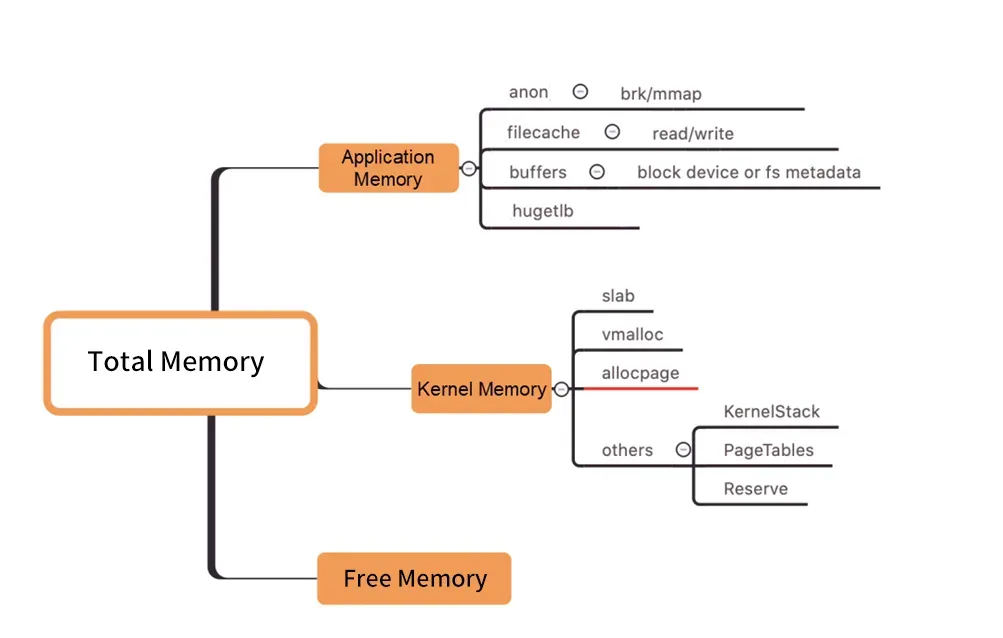
当您使用 Pod 内存的其他各成分不符合预期,都有可能最终造成 WorkingSet 工作负载升高,继而导致PodOOMKilling或者整个节点内存水位过高,出现节点驱逐等现象。例如,在容器环境中运行Java应用程序时,在某些通用配置下,Log4J和Logback等日志框架会默认使用NIO(New I/O)和mmap(内存映射文件)技术来处理日志输出,这可能导致额外的匿名内存使用。这种模式在处理大量日志时会频繁地进行内存的读写操作,并产生额外的匿名内存等,继而在容器环境中引发内存分配黑洞的问题。
为解决因容器引擎层的不透明性而导致的故障排查困难问题,ACK提供操作系统内核层的容器监控可观测能力,使得容器引擎层更为可视化,以便进行容器化迁移。您可以参见SysOM内核层容器监控在ACK集群中启用SysOM监控功能,并参见使用SysOM定位容器内存问题通过SysOM功能观测与收敛容器内存问题。
应用业务指标接入Prometheus监控,并绘制自定义业务大盘
如果您对业务应用逻辑有一定开发能力,推荐使用Prometheus Client监控应用来暴露业务应用本身的指标,并通过Prometheus监控系统配置采集接入,绘制统一的监控大盘。您可以对团队不同角色(如Infra团队、负责业务应用团队)绘制不同视角的监控大盘,以应对日常定性保障,或出现异常时快速处理恢复场景,提供低MTTR快速响应能力。
接入应用性能监控APM和Tracing能力
应用性能监控(Application Performance Monitoring,简称APM)是监控领域监控应用进程本身性能的通用解决方案。阿里云ARMS提供多种APM形态的产品能力,您可以根据开发语言选择对应方式。
-
Java应用的无侵入APM监控(无侵入式):您可以参见Java应用监控实现无侵入APM监控,即在不改动代码的情况下接入Java应用监控功能。接入后,您可以实现自动发现应用拓扑、自动生成3D拓扑、自动发现并监控接口、JVM资源监控、捕获异常事务和慢事务等监控功能,大幅提升线上问题诊断的效率。
-
Python应用的APM监控(侵入式,需调整容器镜像构建Dockerfile):对于部署在ACK集群中的Python应用(例如使用Django、Flask、FastAPI框架构建的Web应用或基于LlamaIndex、Langchain等开发的AI、LLM应用),可以安装ack-onepilot组件并调整Dockerfile,以实现应用性能监控,包括应用拓扑、链路追踪、接口调用分析、异常检测等功能以及针对大型模型交互过程中的细致跟踪记录,请参见Python应用监控。
-
Golang应用的APM监控(侵入式,需构建容器镜像时通过编译工具编译应用的Golang二进制文件):对于运行在ACK集群中的Golang应用,可以通过安装ack-onepilot组件,并在构建应用的容器镜像时通过编译工具instgo编译应用的Golang二进制文件。完成部署后,可以在ARMS中查看对应应用的应用拓扑、接口调用、数据库分析等监控数据,请参见Golang应用监控。
-
容器中应用通过OpenTelemetry协议接入(侵入式,需代码支持或接入OpenTelemetry协议):可观测链路 OpenTelemetry 版为分布式应用的开发者提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,以便快速分析和诊断分布式应用架构下的性能瓶颈,提高微服务时代的开发诊断效率。OpenTelemetry协议有多种数据接入方式,出于对稳定性和方案成熟度等方面的考虑,您可以参见接入指南,根据不同开发语言选择应用的OpenTelemetry接入方式。
前端Web行为监控RUM
当您在集群中的业务系统对外部用户暴露Web前端页面时,前端页面需要稳定和连续保障。ARMS提供的用户体验监控RUM功能专注于Web场景、App移动应用场景和小程序场景的监控,以用户体验为切入点,完整再现用户操作过程,从页面打开速度(测速)、请求服务调用(API)和故障分析(JS错误、网络错误等)、稳定性(JS错误、崩溃、ANR等)方面监测前端应用性能表现情况,并支持日志数据查询,帮助您快速跟踪定位故障原因。详情请参见接入应用选择接入方式。
基于服务网格ServiceMesh实现对服务行为的可观测
阿里云服务网格ASM提供一个全托管式的服务网格平台,兼容社区Istio开源服务网格,用于简化服务的治理,包括服务调用之间的流量路由与拆分管理、服务间通信的认证安全以及网格可观测能力,从而极大地减轻开发与运维的工作负担。
ASM在进行微服务治理时可以通过增强的可观测能力感知业务系统的稳定性保障,如Day0系统上线阶段的流量配置状态、Day1各微服务间流量的分布观测、通过定义SLO指标对Day2系统运行阶段的稳定性保障等。ASM提供了统一标准化的ServiceMesh可观测能力,为您提供一种收敛后的可观测数据生成与采集配置模式,以更好地支持云原生应用的可观测性。
-
监控ServiceMesh控制平面日志以确保流量路由配置正确:通过使用ASM网格诊断手动检测当前可能影响服务网格功能正常运行的异常项,通过告警处理建议实时观测流量路由策略配置是否正常运行,并通过配置实时异常日志报警即时处理异常情况。
-
监控ServiceMesh数据平面AccessLog日志以监控所有访问请求:ServiceMesh访问日志监控功能可供快捷查看日志,还可以对这些日志进行收集、检索或建立Dashboard,请参见使用日志服务采集数据面集群AccessLog。
-
通过Prometheus监控ServiceMesh数据平面的指标:将数据平面指标采集到阿里云Prometheus中后,可从网关状态、网格全局、网格服务级别、网格工作负载等多个维度实现全面监控,发现潜在的问题并及时调整和优化,请参见将监控指标采集到可观测监控Prometheus版、集成可观测监控Prometheus版实现网格监控。
-
通过网络拓扑监控观测并评估微服务间调用流量、时延是否符合预期:将数据平面的Prometheus监控指标作为数据源,可直观观测并评估微服务间调用流量、时延是否符合预期。详情请参见开启网格拓扑提高可观测性。
-
衡量服务质量SLO等级,以观测调用的错误与延时行为:SLO提供了一种通过定义具体量化监控指标的方式来描述、衡量和监控微服务应用程序的性能、质量和可靠性,可作为衡量服务水平质量以及持续改进的参考,详情请参见服务等级目标SLO概述。
-
启用分布式链路追踪,使用完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等能力:在应用代码中接入OpenTelemetry协议,并开启在ASM中实现分布式跟踪功能。
多云混合云场景的统一观测
分布式云容器平台ACK One是阿里云面向混合云、多集群、分布式计算、容灾等场景推出的企业级云原生平台。ACK One可以连接并管理您任何地域、任何基础设施上的Kubernetes集群,并提供一致的管理和社区兼容的API,支持对计算、网络、存储、安全、监控、日志、作业、应用、流量等进行统一运维管控。
主要的场景包括:
-
混合云:使用ACK One注册集群实现云下IDC自建Kubernetes集群接入云端构建混合云,并支持按需在云上伸缩计算资源和应用。
-
多云:使用ACK多集群舰队,纳管多个ACK集群或ACK注册集群,构建多云同城容灾、统一应用配置分发、多集群离线调度等。
针对多云混合云常见推荐启用的可观测能力如下。
-
为ACK One注册集群接入ACK可观测能力:ACK One注册集群提供和ACK一致的可观测能力体验,包括将日志服务接入注册集群、将事件中心接入注册集群、将报警配置功能接入注册集群、将应用实时监控服务ARMS接入注册集群、将阿里云Prometheus接入注册集群。但由于接入的网络环境、权限体系不同均需要额外的网络打通以及授权步骤。
-
ACK多集群舰队全局监控:随着业务的开展,企业需要构建多个Kubernetes集群来满足隔离、高可用、容灾等需求,但现有的监控系统往往针对单个Kubernetes集群。ACK One 多集群舰队提供全局监控功能,基于阿里云Prometheus全局聚合实例将多个集群的Prometheus监控指标聚合到一个统一的监控大盘,简化了多集群运维中的监控和问题诊断流程,避免频繁切换和手动对比各集群的监控指标。您可以在接入ACK多集群舰队后开启全局监控功能,并关联子集群至此多集群舰队中,请参见全局监控。
-
ACK多集群舰队统一报警管理:通过多集群统一报警管理能力,在Fleet实例中配置或修改报警规则。由Fleet实例将报警规则统一下发到指定的关联集群中,且保证已下发的报警规则在各个关联集群中的一致性。同时,Fleet实例可以对新关联的集群自动同步报警规则,请参见多集群统一报警管理、多集群报警差异化配置。
-
ACK One GitOps场景:在ACK One多集群舰队中提供了舰队的核心组件(APIServer、ETCD)监控和GitOps监控,监控舰队及全托管的Argo CD的运行和性能情况,请参见舰队监控 。还可以开启GitOps日志,请参见开启GitOps控制面日志与审计日志,配置GitOps ArgoCD告警,请参见配置ACK One ArgoCD告警。
监控Argo Workflows工作流中的应用
Argo Workflows是一个强大的云原生工作流引擎,广泛应用于批量数据处理、机器学习Pipeline、基础设施自动化以及CI/CD等场景。在ACK中使用Argo Workflows工作流部署应用或使用分布式工作流Argo集群部署工作流应用时,建议启用以下可观测能力,以确保应用的稳定性和可维护性。
-
使用日志服务持久化Argo Workflows中的应用日志:工作流完成时,通常需要配置工作流和Pod的回收策略,以清理相应的资源,避免集群控制面和工作流控制器资源的线性增长。然而,原生的集群在Pod清理后无法查看Pod或工作流日志,因此工作流集群集成了SLS,用来收集工作流运行过程中Pod产生的日志,并上报至SLS Project。您可以通过Argo CLI或Argo UI便捷地查看工作流的日志,请参见使用日志服务。
-
在工作流集群中使用Prometheus监控服务:工作流集群集成阿里云Prometheus,提供完善的可观测能力,以查看工作流运行状况和集群的健康状况,请参见使用Prometheus监控服务。
观测通过Knative框架部署的应用
Knative是一款基于Kubernetes的Serverless框架,支持基于请求的自动弹性、在没有流量时将实例数量自动缩容至零、版本管理与灰度发布等能力。在完全兼容社区Knative和Kubernetes API的基础上,ACK Knative进行了多维度的能力增强,例如通过保留实例降低冷启动时间、基于AHPA(Advanced Horizontal Pod Autoscaler)实现弹性预测等。您可以通过Knative的可观测能力实现服务监控、日志接入监控能力,详情请参见Knative可观测性。
-
在Knative上实现日志采集:如需采集Knative服务的容器文本日志,可以通过DaemonSet的方式,在每个节点上自动运行一个日志代理,以提升运维效率。ACK集群已兼容日志服务SLS,支持无侵入式采集日志,请参见在Knative上实现日志采集。
-
通过阿里云Prometheus查看Knative服务监控大盘:在Knative中部署业务应用后,可以将Knative服务的监控数据接入Prometheus,通过Grafana大盘实时查看Knative的Pod扩缩容趋势、响应延迟、请求并发数、CPU和内存资源用量等数据,详情请参见查看Knative服务监控大盘。