DataWorks全新推出Serverless资源组,它整合原独享调度资源组、独享数据集成资源组、独享数据服务资源组的核心功能。现在,您只需一个Serverless资源组,即可统一运行数据同步、周期性调度任务和API服务等所有核心操作,极大简化资源管理。该资源组提供两种收费模式以满足不同需求:
包年包月:提供稳定、可预期的独享计算资源,是生产环境的理想选择。
按量付费:提供按需使用、弹性伸缩的计算资源,兼具灵活性与成本效益。
当使用Serverless资源组时,只要节点任务发布至生产环境进行周期性调度,均会产生任务调度计费。
计费场景
DataWorks的Serverless资源组费用包括资源占用费用和任务调度费用。其中:
资源占用费用:DataWorks的部分任务在运行时,会消耗Serverless资源组的计算单元(CU)。系统根据消耗的CU总量进行计费,这部分费用即为资源占用费,以CU为计费单位。
其中,
1CU = 1核CPU + 4GiB内存。任务调度费用:将任务发布至生产环境进行周期性调度,此类任务依赖Serverless资源组,但仅计算任务调度费用,不计算资源占用费。任务调度费用以成功运行实例数(不包括空跑)为计费单位。
Serverless资源组支持的最大并发运行实例数上限为200,已满足旧版资源组所有规格的最大并发运行实例数,无需关注Serverless资源组CU规格。
Serverless资源组目前支持的任务类型和费用产生关系如下:

任务类型 | 任务类型说明 | 费用类型 |
数据集成 | 在数据集成或数据开发模块执行数据同步任务(例如,离线同步)。 | 资源占用费用 |
数据计算 |
重要 数据计算类任务请参见附录 1:任务类型和CU消耗情况。 | |
数据服务 | 调用数据服务中的生成API接口。 | |
个人开发环境 | 使用个人开发环境调试任务。 | |
大模型服务 | 部署和使用大模型服务。 | |
任务调度 | 周期性调度任务在生产环境中运行。 | 任务调度费用 |
注意事项
Serverless资源组按量计费方式,高峰期可能存在抢占资源情况,无法完全保障资源使用的时效性。
使用Serverless资源组,但包年包月资源组不支持转换为按量付费资源组。
新用户开通DataWorks时会默认购买按量付费Serverless资源组。不使用不计费,计费详情请参见按量付费资源组计费。
性能指标
Serverless资源组购买方式基于CU量进行计费,1CU = 1核CPU + 4GiB内存。使用Serverless资源组时,需要根据实际开发场景和对应的任务类型来规划资源组规格。
以下建议规格是基于一般情况提供的指导性配置。您可根据自身的具体业务需求和实际情况对资源进行调整,以确保任务能够高效且稳定地运行。
数据集成
离线同步
离线同步任务并发配置 | 建议规格 | 运行最低规格 |
<4 | 0.5 CU | 0.5 CU |
>=4 |
|
实时同步
同步任务类型 | 建议规格 | 运行最低规格 | |
MySQL实时同步 | 数据库数1个 | 2 CU | 运行一个实时同步任务最低规格:1 CU |
数据库数2~5个 | 2 CU | ||
数据库数6个以上 | 2 CU | ||
kafka实时同步 | 1 CU | ||
其它类型单表级别实时任务 | 1 CU | ||
整库实时同步 | - | 运行一个整库同步任务最低规格:2 CU | |
数据计算
每个数据计算型任务都有默认CU,请参见任务类型和CU消耗情况。
数据服务
最大每秒请求(QPS) | 最低规格 | 服务可用性(SLA) |
500 | 4 CU | 99.95% |
1000 | 8 CU | |
2000 | 16 CU |
个人开发环境
CPU类个人开发环境,提供2~100 CU不等的资源配额;GPU类个人开发环境,提供21~60 CU不等的资源配额。可根据任务类型进行大致判断:
轻量级任务(如简单SQL查询、Python脚本调试):建议选择较低的资源配额(如2 CU)。
中等复杂任务(如数据处理、Notebook分析):建议选择中等资源配额(如4 CU)。
深度学习任务(如TensorFlow、PyTorch模型训练):建议选择GPU类型资源,并根据模型规模选择合适的显存和CU数。
大模型服务
请根据GPU显存换算需要的CU抵扣。
0.6B、1.7B、4B、8B模型部署需要最低配置24GB显存。14B模型部署需要最低配置48GB显存。32B模型部署需要最低配置96GB显存。
任务调度
Serverless资源组支持的最大并发运行实例数上限为200,无需关注Serverless资源组CU规格。默认并发运行实例数为50,可在资源组详情页设置任务调度并发上限为200。
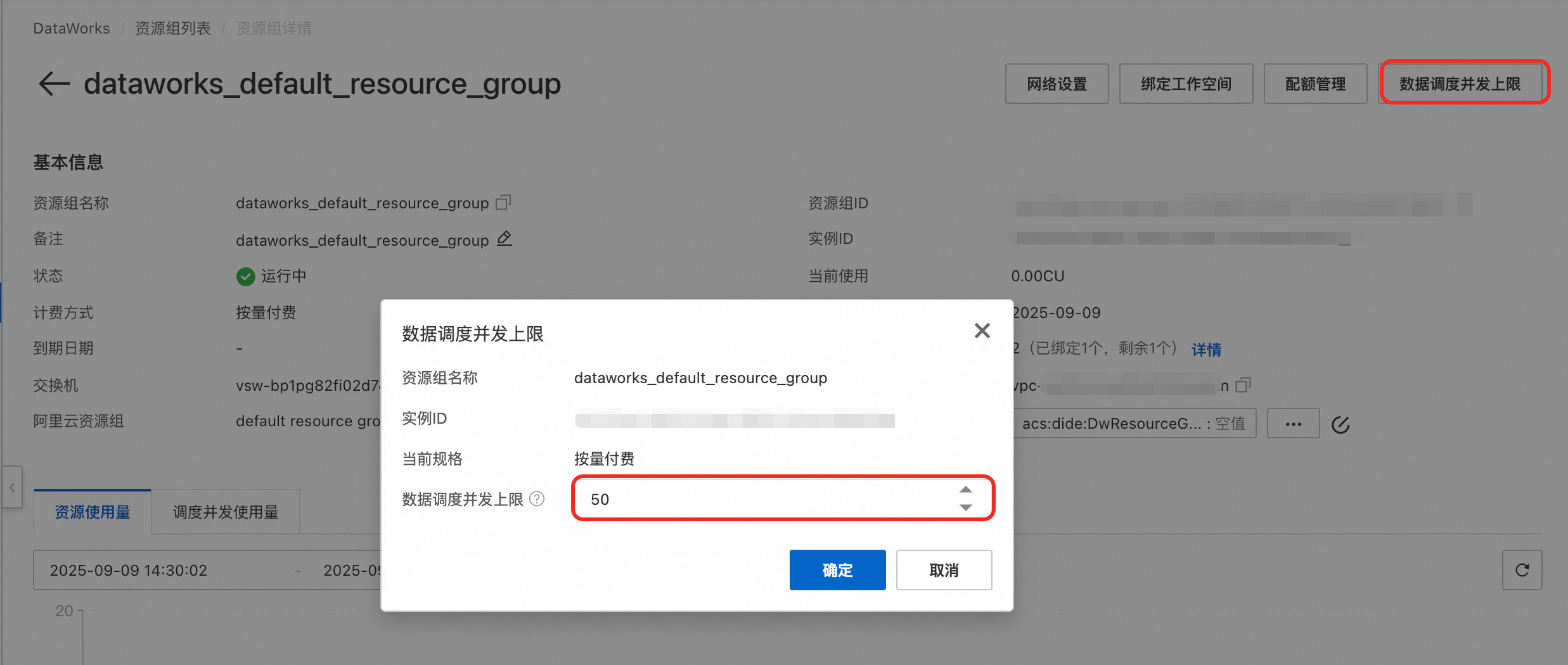
计费模式
Serverless资源组根据计费方式分为预付费的资源组(包年包月)和后付费的资源组(按量付费)。
Serverless资源组(包年包月):提前预估所需CU量及使用时长,并支付相应费用。除支付的包年包月费用外,使用Serverless资源组在DataWorks进行数据同步、数据计算,以及调试/调用数据服务API,DataWorks侧将不再收取其他资源占用费用。
Serverless资源组(按量付费):先使用产品相关功能,后续根据使用的CU总量统一支付相应费用。使用按量付费Serverless资源组运行部分任务(例如,离线同步任务、数据服务任务、数据开发任务)会产生相应资源占用费用。
不同计费方式的功能对比如下:
对比项 | Serverless资源组(按量付费) | Serverless资源组(包年包月) |
资源组总共可用的CU量 | 按照实际使用量计算。 | 购买时指定的CU量。 |
扩容、缩容、续费 | 不涉及 | 支持 |
配额管理 | 用于控制不同场景可使用的CU上限。数据计算、数据集成、数据服务均支持。 | |
设置任务调度并发上限 | 支持,最大支持200个任务实例并发执行。 | |
绑定的专有网络个数 |
| 取决于购买的CU量。
|
计费标准
包年包月资源组计费
统一按CU使用量收费,费用 = 月单价 * 月数 * 每月购买的CU量。
包年包月方式每月最低购买2CU,购买规格无上限,但可能受库存影响,如库存不足时,请关注购买页面提示。
购买后若规格不满足需求,您可随时执行扩容操作,参见使用Serverless资源组。
使用Serverless资源组运行任务时,不同类型任务要求的资源最低规格请参见性能指标。
地域 | 月单价(元/月/CU) |
华北3(张家口) | 180.3046 |
华北6(乌兰察布) | 214.5624 |
华东2(上海)、华东1(杭州)、华北2(北京)、华南1(深圳) | 240 |
英国(伦敦) | 329.5431 |
美国(弗吉尼亚) | 348.3241 |
马来西亚(吉隆坡) | 409.3401 |
中国香港、新加坡、德国(法兰克福)、印度尼西亚(雅加达) | 436.7817 |
美国(硅谷) | 469.9517 |
日本(东京) | 500.3647 |
按量付费资源组计费
统一按照CU时 * CU单价计费,费用 = CU时 * CU单价,按小时出账。
在资源组配额管理中,如果为数据服务当前配置1CU,则无论数据服务功能是否被使用,CU的消耗将持续,直至将数据服务当前配额的占用CU调整为0后才会停止。
地域 | 单价(元/CU时) | 示例 |
华北3(张家口) | 0.375635 | 示例:上海地域某数据同步任务配置了2CU,且该任务在0.5小时后运行成功,上海地域CU的单价为0.5元/CU时,则该任务消耗的CU时及费用如下:
|
华北6(乌兰察布) | 0.447005 | |
华东2(上海)、华东1(杭州)、华北2(北京)、华南1(深圳) | 0.5 | |
英国(伦敦) | 0.686548 | |
美国(弗吉尼亚) | 0.725675 | |
马来西亚(吉隆坡) | 0.852792 | |
德国(法兰克福)、印度尼西亚(雅加达)、中国香港、新加坡 | 0.909962 | |
美国(硅谷) | 0.979066 | |
日本(东京) | 1.042426 |
查看账单详情
在费用与成本控制台查看账单详情时,Serverless资源组的计费项和计费Code如下:
按量付费:计费项为
通用资源组CU时(按量付费)、计费Code为exresource_cu_hour_post。包年包月:计费项为
通用独享资源组包年包月(混合计费)、计费Code为cu_number。
具体操作请参见查看账单详情。
到期说明及续费
若Serverless包年包月资源组即将到期,您可对资源组进行续费。如果未续费,则资源组将会被停服或释放。续费详情,请参见到期说明及续费操作。
扩缩容费用说明
Serverless包年包月资源组支持在购买后根据实际需要进行扩缩容。扩缩容涉及费用变更,扩缩容前后费用计算逻辑,请参见资源升配。
后续步骤
您可购买资源组并选择在数据集成、数据开发、数据服务等任务中使用。购买资源组、绑定资源组至工作空间、连通资源组网络的相关操作,请参见使用Serverless资源组。
更多说明
附录 1:任务类型和CU消耗情况
DataWorks节点开发产生的任务分成数据计算型任务(计算CU消耗)和调度型任务(不计算CU消耗)。
任务类型判断
您可进入数据开发(Data Studio)相应节点的编辑页面,通过右侧导航栏的,查看当前任务的类型。
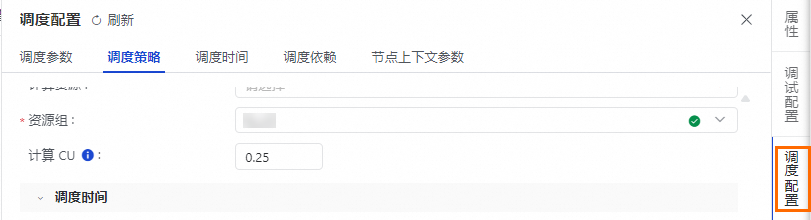
计算型任务:在调度策略区域,需指定任务运行所需的计算CU。
场景一:计算CU可自定义计算CU量。
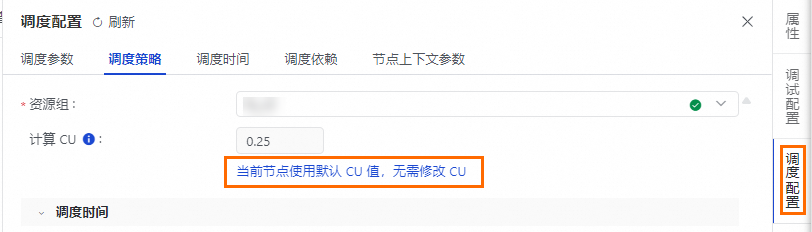
场景二:计算CU仅支持配置为默认的计算CU量。
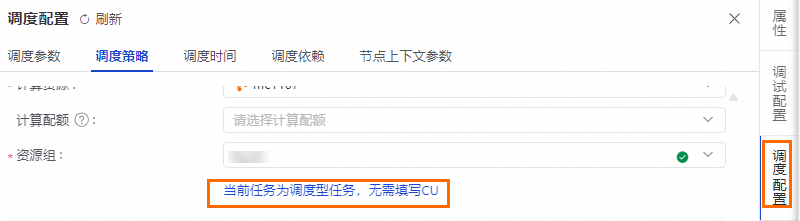
调度型任务:在调度策略区域,仅支持选择调度资源组,无需配置任务使用的CU量。
计算型任务CU配置列表
使用Serverless资源组运行数据计算任务会消耗CU,涉及的默认CU及运行CU介绍如下:
默认CU:每次运行任务时,平台根据任务类型分配的推荐CU量,低于该值可能无法保障任务的高效运行。
运行CU:运行任务实际配置的CU量,平台默认填充为默认CU的值,您可按需调整。配置原则如下:
最低配置为0.25CU,步长为0.25CU。若界面提示当前资源组的CU额度不足,可调整数据计算任务的CU配额。
为避免资源配置不足或过量,请参考默认CU及数据计算任务的CU配额合理配置。详情请参见给任务分配CU配额。
仅部分任务支持调整运行CU。例如:
Hologres SQL任务的运行CU无法调整,只能配置为0.25(即默认CU)。
PyODPS 2任务的运行CU默认为0.5,您可按需调整(例如,0.4、0.6等)。
节点类型 | 节点名称 | 默认CU(单位CU) | 运行CU是否可修改 |
Notebook | 0.5 | 支持 | |
MaxCompute | 0.5 | 支持 | |
0.5 | 支持 | ||
0.5 | 支持 | ||
0.25 | 支持 | ||
0.25 | 支持 | ||
Hologres | 0.25 | - | |
0.25 | - | ||
0.25 | 支持 | ||
0.25 | 支持 | ||
EMR | 0.25 | - | |
0.25 | - | ||
0.25 | 支持 | ||
0.25 | - | ||
0.25 | 支持 | ||
0.5 | 支持 | ||
0.5 | 支持 | ||
0.5 | 支持 | ||
0.25 | - | ||
0.25 | - | ||
Serverless Spark | 0.25 | - | |
0.25 | - | ||
0.25 | - | ||
Severless StarRocks | 0.25 | - | |
大模型 | 0.5 | - | |
ADB | 0.25 | 支持 | |
0.25 | 支持 | ||
0.25 | - | ||
0.25 | - | ||
CDH | 0.25 | - | |
0.5 | 支持 | ||
0.25 | - | ||
0.25 | - | ||
0.25 | - | ||
0.25 | - | ||
Lindorm | 0.25 | - | |
0.25 | - | ||
Click House | 0.25 | - | |
数据质量 | 0.25 | - | |
0.5 | 支持 | ||
通用 | 0.25 | 支持 | |
0.25 | 支持 | ||
0.25 | - | ||
0.5 | 支持 | ||
0.25 | 支持 | ||
0.25 | 支持 | ||
0.25 | - | ||
0.25 | - | ||
0.25 | - | ||
MySQL节点 | 0.25 | - | |
SQL Server | |||
Oracle节点 | |||
PostgreSQL节点 | |||
StarRocks节点 | |||
DRDS节点 | |||
PolarDB MySQL节点 | |||
PolarDB PostgreSQL节点 | |||
Doris节点 | |||
MariaDB节点 | |||
SelectDB节点 | |||
Redshift节点 | |||
Saphana节点 | |||
Vertica节点 | |||
DM(达梦)节点 | |||
KingbaseES(人大金仓)节点 | |||
OceanBase节点 | |||
DB2节点 | |||
GBase 8a 节点 | |||
算法 | 0.25 | - |
调度型任务配置列表
调度型任务不占用Serverless资源组的CU。
节点类型 | 节点名称 |
数据集成 | |
MaxCompute | |
Flink | |
通用 | |
算法 |
附录 2:任务运行几种收费模式

当您在DataWorks中运行一个节点任务时,其计算费用不一定由DataWorks收取。您需要明确该任务最终是在哪个计算引擎或资源上执行的。具体来说,存在以下三种情况:
当任务发布至生产环境进行周期性任务调度时,均产生任务调度费用。
执行方式 | 代表任务节点 | 计算资源提供方 | 费用构成 |
方式1:计算型任务下发至Serverless资源组执行 | PyODPS, Shell, 数据集成, 数据质量 | Serverless资源组 | 仅Serverless资源组费用 |
方式2:计算型任务通过Serverless资源组下发至三方引擎执行 | EMR Hive, Hologres SQL | Serverless资源组 + 三方引擎 | Serverless资源组费用 + 三方引擎费用 |
方式3:调度型任务通过调度中心下发至三方引擎执行。 | MaxCompute SQL, Flink SQL | 三方引擎 | 三方引擎费用 |
附录 3:部分模块费用细分说明
使用Serverless资源组在以下功能模块使用时,产生具体的Serverless资源组费用说明如下:
数据集成:当进行数据同步时,将在数据集成、数据开发和运维中心功能模块运行数据集成任务,进而消耗Serverless资源组产生数据集成类费用。周期性同步任务,还会产生任务实例调度费用。
数据开发:当使用数据开发(Data Studio)进行任务开发时,将在数据开发、数据质量、运维中心功能模块运行数据计算任务和调度任务,进而消耗Serverless资源组产生数据计算类费用和任务实例调度费用。当使用个人开发环境时,还会产生个人开发环境类费用。当使用大模型服务或者大模型节点时,还会产生大模型服务类费用。
数据分析:当使用数据分析进行SQL查询分析、查询结果下载时,将在数据分析功能模块运行数据计算任务,进而消耗Serverless资源组产生数据计算类费用。当使用数据洞察时,还会产生任务实例调度费用。
数据服务:当使用数据服务生成API时,通过资源组配额管理配置数据服务的占用CU,进而消耗Serverless资源组产生数据服务类费用。当使用数据推送时,还会产生任务实例调度费用。