
本文为您介绍如何通过PAI提供的文本类组件,快速构建文本分类模型。
背景信息
新闻分类是文本挖掘领域较为常见的场景。很多媒体或内容生产商对于新闻文本的分类通常采用手工标注的方式,消耗了大量的人力资源。PAI提供的智能文本挖掘算法可以实现新闻文本分类自动化(包括分词、词型转换、停用词过滤、主题挖掘及聚类等流程)。本工作流首先通过PLDA算法挖掘文章的主题,然后进行主题权重聚类,从而实现新闻自动分类。
本工作流数据为虚构数据,仅用于学习。
前提条件
已开通PAI(Designer)并创建了工作空间,详情请参见开通PAI并创建默认工作空间。
已将MaxCompute资源关联到工作空间,详情请参见管理工作空间。
基于文本分析算法实现新闻分类
进入PAI-Designer页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,进入Designer页面。
构建工作流。
在PAI-Designer页面,单击预置模板页签。
在模板列表的文本分析-新闻分类区域,单击创建。
在新建工作流对话框,配置参数(可以全部使用默认参数)。
其中:工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
单击确定。
您需要等待大约十秒钟,工作流可以创建成功。
在工作流列表,双击文本分析-新闻分类工作流,进入工作流。
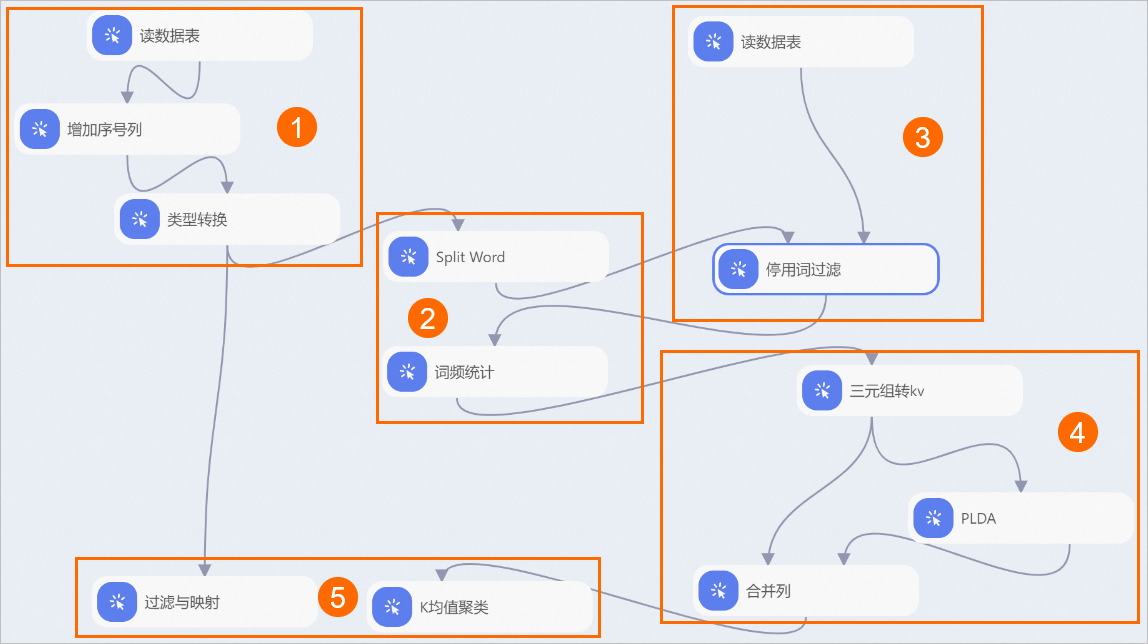
系统根据预置的模板,自动构建工作流,如下图所示。
区域
描述
区域
描述
①
增加序列号。本工作流的数据源以单个新闻为单元,需要增加ID列作为每篇新闻的唯一标识,便于算法计算。
②
分词及词频统计。首先使用分词组件对content字段(新闻内容)进行分词。然后对过滤停用词后的文本进行词频统计。
③
过滤停用词,通常过滤标点符号及对文章影响较小的助语等。
④
挖掘文本主题:
PLDA文本挖掘组件的输入必须为三元形式,因此使用三元组转kv组件将文本转换为三元形式(文本转换为数字)。
其中:
append_id:每篇新闻的唯一标识。
key_value:冒号前面的数字表示单词抽象成的数字标识,冒号后面的数字表示对应的单词出现频率。
使用PLDA组件训练模型。
PLDA算法(主题模型)可以定位每篇文章的主题词语。本工作流配置了50个主题,PLDA组件的第五个输出桩输出每篇文章对应每个主题的概率。
⑤
结果分析和评估。通过以上步骤已经将文本从主题维度转换成了向量,可以通过向量距离实现聚类,从而实现文本分类。
运行工作流并查看模型效果。
单击画布上方的运行。
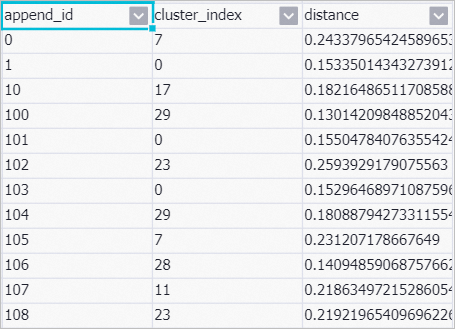
工作流运行结束后,右键单击画布中的K均值聚类,在快捷菜单,单击,即可查看分类结果。
 其中:
其中:cluster_index:表示每一类的名称。
append_id:每篇新闻的唯一标识。
右键单击画布中的过滤与映射,在快捷菜单,单击,即可查看append_id为115、292、248及166的新闻。
 本工作流的新闻分类结果不够理想(两篇体育类、一篇财经类及一篇科技类新闻分到了同一类中),主要原因如下:
本工作流的新闻分类结果不够理想(两篇体育类、一篇财经类及一篇科技类新闻分到了同一类中),主要原因如下:工作流数据量较小。
仅针对业务场景介绍文本分析算法的使用方法,未对数据集进行特征工程处理及细节调优。
因为本工作流模板已为过滤与映射配置了过滤条件,所以您可以直接查看append_id为115、292、248及166的新闻。如果需要查看其它新闻,则可以参见如下示例,将过滤与映射组件的过滤条件配置为相应的新闻ID。
append_id=292 or append_id=115 or append_id=248 or append_id=166 ;
- 本页导读 (1)
- 背景信息
- 前提条件
- 基于文本分析算法实现新闻分类
