
本文介绍如何使用Argo Workflows将OSS上的文件进行逐级合并以展示如何进行批量数据处理。这种处理方法常见于高精度地图处理、动画渲染等场景,使用Argo Workflows进行任务编排可以有效提升数据处理的并发度和处理速度。
前提条件
已完成组件的安装和阿里云Argo CLI的安装。详细步骤,请参见启用批量任务编排能力。
已完成OSS存储卷的配置。详细步骤,请参见使用存储卷。
步骤一:准备数据
使用以下示例内容,创建prepare-data.yaml。
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: aggregation-prepare-data- namespace: argo spec: entrypoint: main volumes: - name: workdir persistentVolumeClaim: claimName: pvc-oss templates: - name: main dag: tasks: - name: prepare-data template: create-file - name: create-file script: image: mirrors-ssl.aliyuncs.com/python:alpine command: - python source: | import os import sys import random os.makedirs("/mnt/vol/aggregation-demo/l1/", exist_ok=True) for i in range(32): with open('/mnt/vol/aggregation-demo/l1/' + str(i) + '.txt', 'w') as conbine_file: combined_content = random.choice('ABCDEFGHIJKLMNOPQRSTUVWXYZ') conbine_file.write(combined_content) volumeMounts: - name: workdir mountPath: /mnt/vol执行以下命令,提交工作流。
argo submit prepare-data.yaml任务运行完成后会在OSS上创建出
aggregation-demo/l1目录,并生成32个文件,每个文件内有单个随机字符。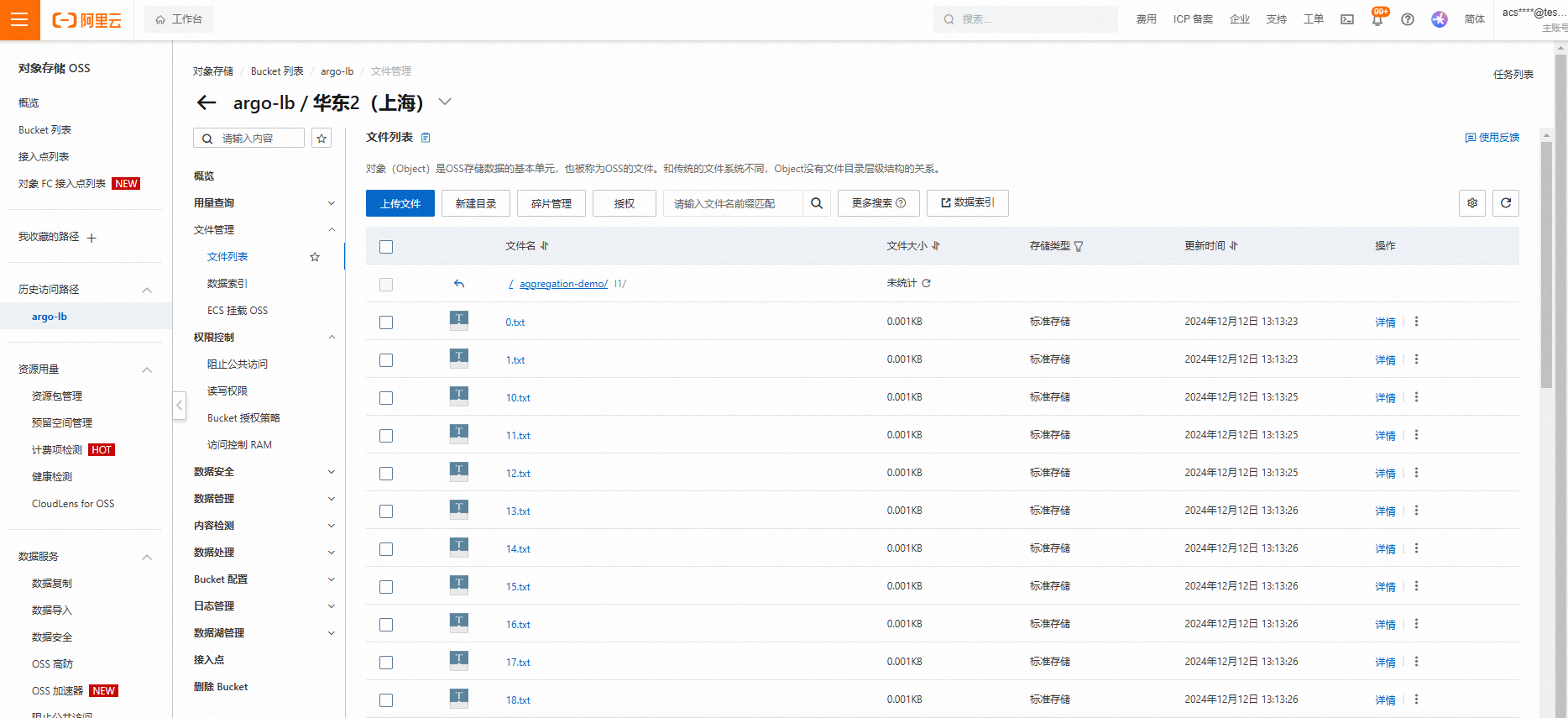
步骤二:处理批量数据
使用以下示例内容,通过YAML方式编辑数据处理作业,创建process-data.yaml。
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: process-data- # 数据处理工作流。 namespace: argo spec: entrypoint: main volumes: # 对象存储挂载。 - name: workdir persistentVolumeClaim: claimName: pvc-oss arguments: parameters: - name: numbers value: "16" templates: - name: main steps: - - name: process-data-l1 # 第一级处理,启动16个Pods,Merge 32 个files。 template: process-data arguments: parameters: - name: file_number value: "{{item}}" - name: level value: "1" withSequence: count: "{{workflow.parameters.numbers}}" - - name: process-data-l2 # 第二级处理,启动 8个Pods,Merge 16 个files, 上一步处理完后启动。 template: process-data arguments: parameters: - name: file_number value: "{{item}}" - name: level value: "2" withSequence: count: "{{=asInt(workflow.parameters.numbers)/2}}" - - name: merge-data # 最后一级处理,启动一个Pod,Merge 8 files, 上一步处理完后启动。 template: merge-data arguments: parameters: - name: number value: "{{=asInt(workflow.parameters.numbers)/2}}" - name: process-data # process-data 任务定义。 inputs: parameters: - name: file_number - name: level container: image: serverlessargo-registry.cn-hangzhou.cr.aliyuncs.com/argo-workflow-examples/python:3.11-amd # 注意开通vpc访问公网能力以便于拉取镜像 imagePullPolicy: Always command: [python3] # command args: ["process.py", "{{inputs.parameters.file_number}}", "{{inputs.parameters.level}}"]# 接收输入的参数,pod处理哪个file volumeMounts: - name: workdir mountPath: /mnt/vol - name: merge-data # merge-data 任务定义。 inputs: parameters: - name: number container: image: serverlessargo-registry.cn-hangzhou.cr.aliyuncs.com/argo-workflow-examples/python:3.11-amd imagePullPolicy: Always command: [python3] args: ["merge.py", "{{inputs.parameters.number}}"] # 接收输入的参数,处理多少个文件。 volumeMounts: - name: workdir mountPath: /mnt/vol执行以下命令,提交工作流。
argo submit process-data.yaml -n argo执行以下命令查看结果。
argo get @latest -n argo预期输出:
argo get @latest -n argo Name: process-data-8sn2q Namespace: argo ServiceAccount: unset (will run with the default ServiceAccount) Status: Succeeded Conditions: PodRunning False Completed True Created: Thu Dec 12 13:15:39 +0800 (4 minutes ago) Started: Thu Dec 12 13:15:39 +0800 (4 minutes ago) Finished: Thu Dec 12 13:16:40 +0800 (3 minutes ago) Duration: 1 minute 1 seconds Progress: 25/25 ResourcesDuration: 4s*(1 cpu),2m51s*(100Mi memory) Parameters: numbers: 16 STEP TEMPLATE PODNAME DURATION MESSAGE ✔ process-data-8sn2q main ├─┬─✔ process-data-l1(0:0) process-data process-data-8sn2q-process-data-3064646785 17s │ ├─✔ process-data-l1(1:1) process-data process-data-8sn2q-process-data-140728989 20s │ ├─✔ process-data-l1(2:2) process-data process-data-8sn2q-process-data-499182361 18s │ ├─✔ process-data-l1(3:3) process-data process-data-8sn2q-process-data-3152865965 20s │ ├─✔ process-data-l1(4:4) process-data process-data-8sn2q-process-data-1363784105 16s │ ├─✔ process-data-l1(5:5) process-data process-data-8sn2q-process-data-3270437485 20s │ ├─✔ process-data-l1(6:6) process-data process-data-8sn2q-process-data-1788045361 16s │ ├─✔ process-data-l1(7:7) process-data process-data-8sn2q-process-data-913839549 20s │ ├─✔ process-data-l1(8:8) process-data process-data-8sn2q-process-data-1562179905 16s │ ├─✔ process-data-l1(9:9) process-data process-data-8sn2q-process-data-573517021 20s │ ├─✔ process-data-l1(10:10) process-data process-data-8sn2q-process-data-3769586203 16s │ ├─✔ process-data-l1(11:11) process-data process-data-8sn2q-process-data-3700909073 20s │ ├─✔ process-data-l1(12:12) process-data process-data-8sn2q-process-data-2818003295 19s │ ├─✔ process-data-l1(13:13) process-data process-data-8sn2q-process-data-278901825 20s │ ├─✔ process-data-l1(14:14) process-data process-data-8sn2q-process-data-3986961347 16s │ └─✔ process-data-l1(15:15) process-data process-data-8sn2q-process-data-2905592609 19s ├─┬─✔ process-data-l2(0:0) process-data process-data-8sn2q-process-data-2056515729 9s │ ├─✔ process-data-l2(1:1) process-data process-data-8sn2q-process-data-2141620461 4s │ ├─✔ process-data-l2(2:2) process-data process-data-8sn2q-process-data-352538601 9s │ ├─✔ process-data-l2(3:3) process-data process-data-8sn2q-process-data-2144734909 6s │ ├─✔ process-data-l2(4:4) process-data process-data-8sn2q-process-data-2290907961 8s │ ├─✔ process-data-l2(5:5) process-data process-data-8sn2q-process-data-4197561341 5s │ ├─✔ process-data-l2(6:6) process-data process-data-8sn2q-process-data-1620613249 9s │ └─✔ process-data-l2(7:7) process-data process-data-8sn2q-process-data-3126908173 10s └───✔ merge-data merge-data process-data-8sn2q-merge-data-1171626309 7s在控制台查看结果。
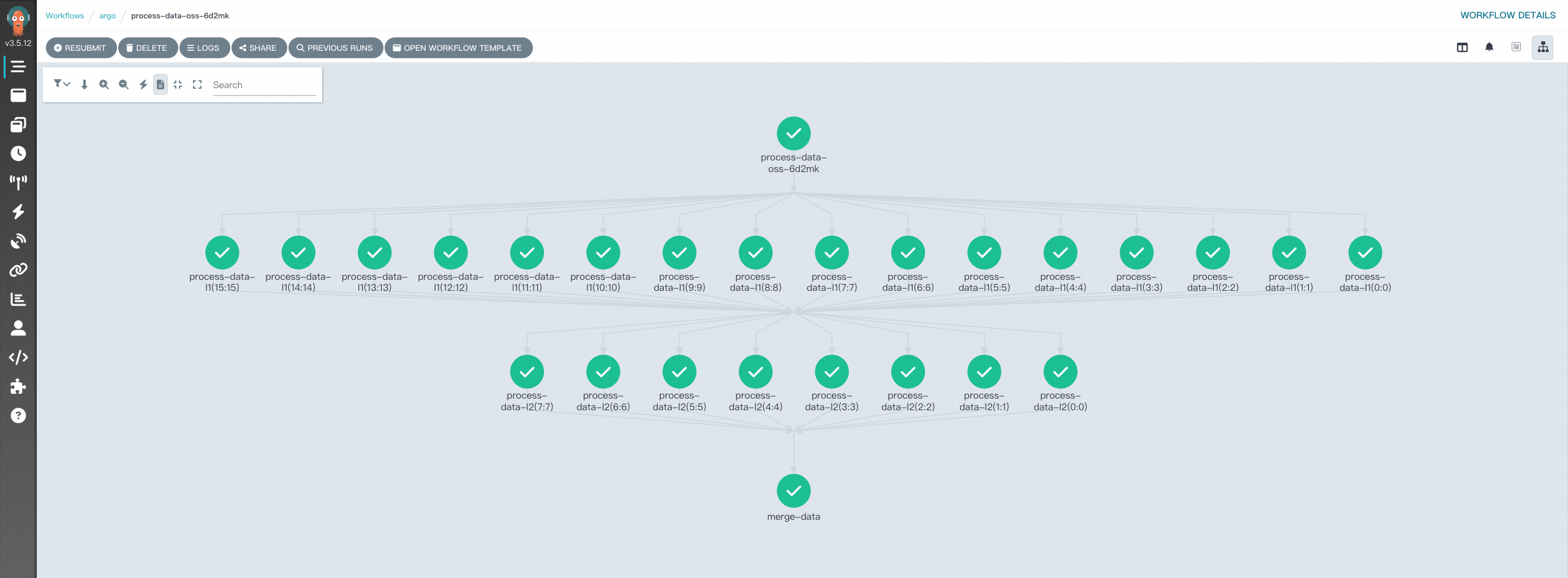
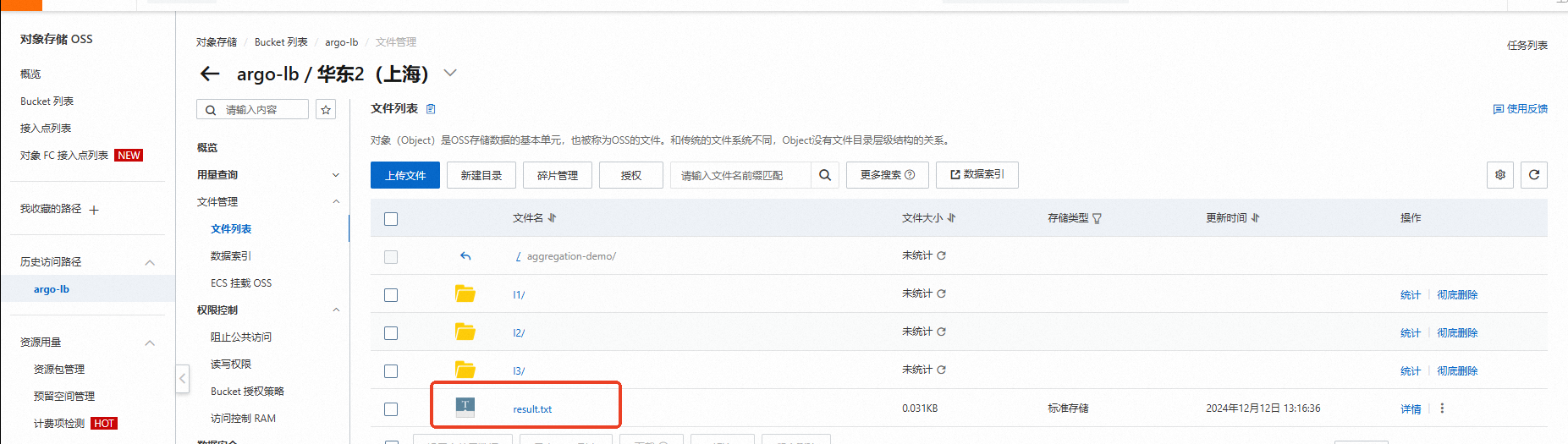
可以看到任务均已经执行成功。查看OSS,可以发现最终结果result.txt已经生成。
相关文档
若您希望使用Python SDK构建并提交工作流,请参见使用Python SDK构建大规模Argo Workflows。
联系我们
若您有任何产品建议或疑问,请加入钉钉群(钉钉群号:35688562)联系我们。
该文章对您有帮助吗?
- 本页导读 (0)
- 前提条件
- 步骤一:准备数据
- 步骤二:处理批量数据
- 相关文档
- 联系我们