本文为您介绍如何基于阿里巴巴OneData方法论最佳实践,使用Dataphin助力企业数据中台的建设与管理,快速构建标准、规范的数据仓库。
数仓构建流程
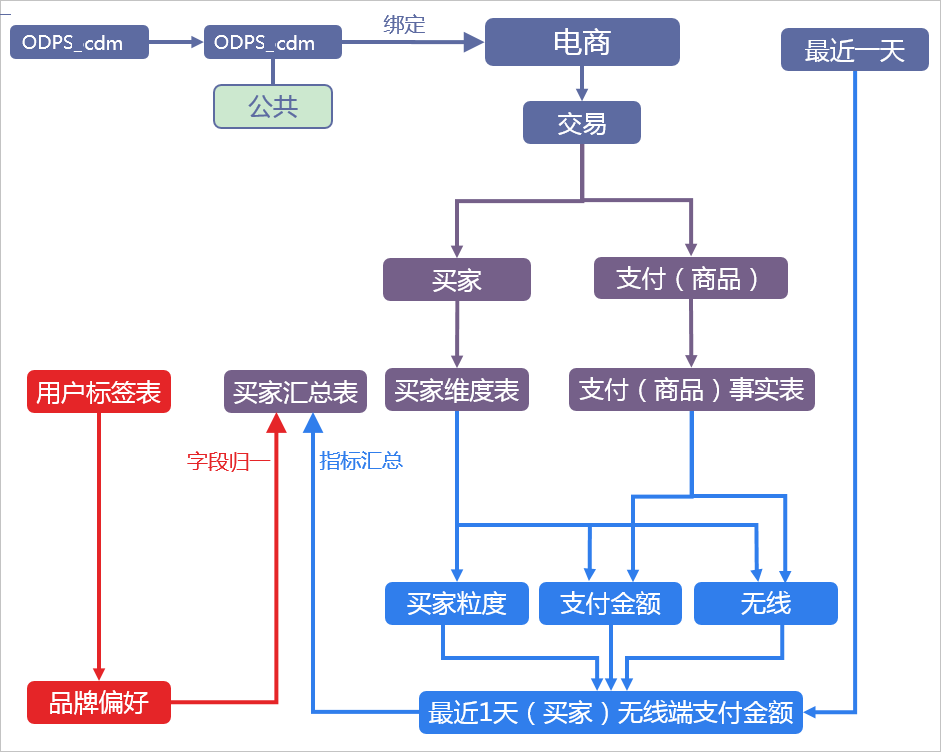
下图为使用Dataphin构建数据仓库的基本流程。

基本概念
在正式学习本教程之前,您需要了解以下基本概念:
数据板块:数据板块定义了数据仓库的多种命名空间,是一种系统级的概念对象,是比主题域更高维度的业务划分方法,适用于庞大的业务系统。当数据的业务含义存在较大差异时,您可以创建不同的数据板块,让各成员独立管理不同的业务,后续数据仓库的建设将按照数据板块进行划分。在Dataphin中,项目可以归属至数据板块以实现规范建模功能,同一个数据板块中可能包含多个不同的项目,所以数据板块与项目的关系为1:N。例如,根据企业的事业群或事业部进行划分的数据板块。
主题域:主题域主要用于存放同一数据板块内不同概念的指标。例如,您可以划分出商品域、交易域、会员域等,用于存放不同意义的指标。
业务实体:业务实体包含业务对象和业务活动:
业务对象:即参与业务的主体和客体,通常情况下业务对象是实际存在、不因事件发生而存在的对象。例如客户、员工、产品等具体的业务对象;地域、组织关系和产品类目等抽象的业务对象。
业务活动:是一个或者多个业务对象在某个时间(段)为了达成某种目的所进行的活动或者是某种活动的结果。例如下单、支付、退款都是业务活动。
维度:维度即进行统计的对象。通常,维度是实际客观存在的实体。Dataphin遵循Ralph Kimball的维度建模理论,创建维度,即从顶层规范业务中实体(或称主数据)的存在性及唯一性。维度及维度组合,也是派生指标的统计粒度。例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
指标:指标分为原子指标和派生指标。派生指标是以原子指标为基准,组装统计粒度、统计周期及业务限定而生成的。
原子指标:是对指标统计口径、具体算法的一个抽象。根据计算逻辑复杂性,Dataphin将原子指标分为两种:
原生的原子指标:例如支付金额。
衍生原子指标:基于原子指标组合构建。例如,客单价通过支付金额除以买家数组合而来。
派生指标:是业务中常用的统计指标。为保证统计指标标准、规范、无二义性地生成,OneData方法论将派生指标抽象为四部分:派生指标=原子指标+业务限定+统计周期+统计粒度。例如,原子指标(销售额)+业务限定(产品类别)+统计周期(每月统计一次)+统计粒度(按产品类别和月份进行统计)。
业务限定:统计的业务范围,用于筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。原子指标是计算逻辑的标准化定义,业务限定则是条件限制的标准化定义。例如,产品类别。
统计周期:统计的时间范围,也可以称为时间周期。例如最近1天、最近30天等(类似于SQL中where后的时间条件)。
统计粒度:统计分析的对象或视角,定义数据需要汇总的程度,可以理解为聚合运算时的分组条件(类似于SQL中group by的对象)。粒度是维度的一个组合,指明您的统计范围。例如,某个指标是某个卖家在某个省份的成交额,则粒度就是卖家、省份这两个维度的组合。
如果您需要统计全表的数据,则粒度为全表。在指定粒度时,您需要充分考虑到业务和维度的关系。统计粒度也被称为粒度,是维度或维度组合,一般用于派生指标构建,是汇总表的唯一性识别方式。
基本概念之间的关系

具体示例