特征数据库(下文简称FeatureDB)是阿里云PAI平台下特征平台(PAI-FeatureStore)提供的数据库服务,可以作为FeatureStore的在线数据源,提供在线特征存储功能,并为搜索推荐广告等服务提供高性能的读写优化。本文为您介绍什么是FeatureDB,以及FeatureDB的功能与优势。
什么是FeatureDB
FeatureDB是FeatureStore提供的高性能分布式存储数据库,支持KV、KKV格式的数据,并支持以结构化的方式将数组存储为Array,将KV存储为Map类型。通过Array、Map类型存储数据,可以为后续的读写、推理服务提供更高的性能。FeatureDB已经全面支持离线特征和实时特征的生产、更新与消费链路,同时也支持用户行为序列特征。
如何开通
您可以在新建FeatureDB数据源时按照界面提示进行开通,具体操作,请参见新建在线数据源:FeatureDB。
产品特性
FeatureDB针对FeatureStore特征读取特性实现了如下功能和优化:
支持读写KV、KKV类型特征。
支持读写MaxCompute复杂类型特征(Array、Map)。
支持全量拉取FeatureView下的所有特征数据。
支持毫秒级轮询更新实时特征数据。
支持秒级TTL,自动清理过期数据。
按量计费,根据实际读写数据量进行计费。
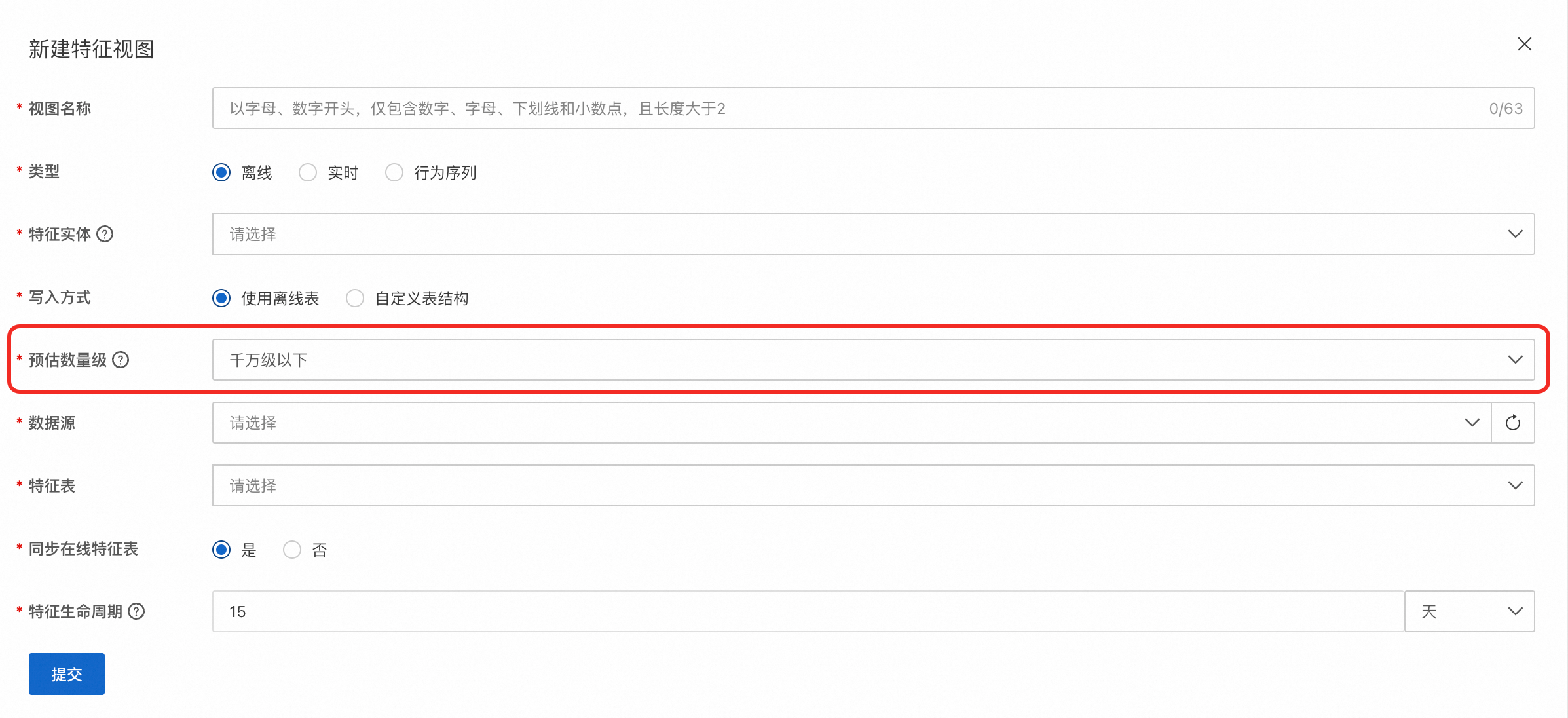
FeatureDB可以对FeatureView的数据进行分片存储,通过调整分片数来满足不同场景的读写性能需求,并且支持副本,以保障数据的稳定与安全。分片数量会根据您选择的预估数量级进行设置:
千万级以下(默认):5分片。
介于千万级与亿级之间:10分片。
亿级以上:20分片。
产品优势
高性价比
对于特征存储规模较小的客户,使用FeatureDB可以降低使用成本。
满足高频更新需求
当使用实时统计特征时,需每隔几秒及时更新实时特征到多个EasyRec Processor(模型推理服务)实例的存储中,这对高频更新有较高的要求,FeatureDB可以满足这一需求。
支持复杂类型特征
在搜索推广业务中,Array和Map类型的特征、用户行为长序列特征及其SideInfo被广泛使用。如果复杂类型特征以字符串形式存储,在使用时需要进行序列化转为Map类型,这会降低性能。
FeatureDB支持存储复杂类型数据,并支持将MaxCompute2.0复杂类型数据同步到FeatureDB,进行高性能读取操作。
支持弹性扩容
对于规模较大的客户,能够根据特征视图灵活增加分片数量,提高读写性能。
解决监控盲点
当集成第三方数据源时,整个数据链路的监控变得困难,特别是在实时特征方面。FeatureDB能够监控每个视图粒度的读写QPS、RT、数据更新延时和存储用量等关键性能指标。
产品功能
VPC网络高速连通
FeatureDB提供基于私网连接(PrivateLink)的VPC网络高速连通功能。配置成功后,FeatureStore会通过PrivateLink打通您的VPC和FeatureDB服务之间的网络,之后您可以在VPC中使用FeatureStore SDK通过私有连接访问FeatureDB,从而提高读写数据性能,降低访问延时。
您可以通过以下方式配置VPC网络高速连通。
方式一:如果未创建过FeatureDB数据源,单击管理数据源,进入管理数据源页面后单击新建数据源。新建FeatureDB数据源时,在VPC网络高速连通配置部分填写VPC,和可用区与交换机。具体操作细节,请参见新建在线数据源:FeatureDB。
方式二:如果已经创建了FeatureDB数据源,单击管理数据源,进入管理数据源页面后单击已经创建好的feature_db数据源,进入详情页。单击VPC网络高速连通配置,填写VPC,和可用区与交换机,并单击确定。
注意事项
VPC设置后无法修改,请确认您配置的VPC为您使用FeatureStore的线上服务所在的VPC。
推荐您将服务部署到推荐的可用区,这样可以避免跨可用区的网络耗时,最大幅度提高访问性能。
区域
地域
推荐的可用区
亚太
华东1(杭州)
可用区G
华东2(上海)
可用区L
华北2(北京)
可用区F
华南1(深圳)
可用区F
中国(香港)
可用区B
新加坡
可用区C
欧洲和美洲
德国(法兰克福)
可用区A
美国(硅谷)
可用区B
可用区与交换机:请确保选择了您线上服务机器所在可用区的交换机。建议选择至少两个可用区的交换机,从而实现业务的高可用性和稳定性。推荐您选择线上服务机器所在可用区的交换机,以及我们推荐的可用区的交换机。
配置成功后,后续只支持添加其他可用区的交换机,不支持修改或删除配置。
写入特征
对于离线特征,可以使用FeatureStore Python SDK通过DataWorks每天例行运行调度任务,将MaxCompute里的数据同步到FeatureDB中。
对于实时特征,目前可通过以下三种方式写入数据。
方式一:直接通过Java SDK写入特征数据。
// 配置 regionId, 阿里云账号, FeatureStore project Configuration configuration = new Configuration("cn-beijing", Constants.accessId, Constants.accessKey,"fs_demo_featuredb" ); // 配置 FeatureDB 用户名,密码 configuration.setUsername(Constants.username); configuration.setPassword(Constants.password); // 如果使用公网链接 FeatureStore, 参考上面的域名信息 // 如果使用 VPC 环境,不需要设置 //configuration.setDomain(Constants.host); ApiClient client = new ApiClient(configuration); // 如果使用公网链接 设置 usePublicAddress = true, vpc 环境不需要设置 // FeatureStoreClient featureStoreClient = new FeatureStoreClient(client, Constants.usePublicAddress); FeatureStoreClient featureStoreClient = new FeatureStoreClient(client ); Project project = featureStoreClient.getProject("fs_demo_featuredb"); if (null == project) { throw new RuntimeException("project not found"); } FeatureView featureView = project.getFeatureView("user_test_2"); if (null == featureView) { throw new RuntimeException("featureview not found"); } List<Map<String, Object>> writeData = new ArrayList<>(); // 模拟构造数据写入 for (int i = 0; i < 10; i++) { Map<String, Object> data = new HashMap<>(); data.put("user_id", i); data.put("string_field", String.format("test_%d", i)); data.put("int32_field", i); data.put("int64_field", Long.valueOf(i)); data.put("float_field", Float.valueOf(i)); data.put("double_field", Double.valueOf(i)); data.put("boolean_field", i % 2 == 0); writeData.add(data); } for (int i = 0; i < 100;i++) { featureView.writeFeatures(writeData); } // 这里只需要调用一次,如果全部数据写完,确保全部写入完成,调用此接口后,无法再调用 writeFeatures featureView.writeFlush();方式二:使用实时计算Flink生产实时特征,通过配置Flink Connector写入。具体操作,请参见设置Flink Connector。
方式三:如果需要在初始阶段同步存量数据,可以使用特征视图页面的数据同步功能,具体操作步骤如下:
在项目详情页面的特征视图页签,单击数据同步。
在弹出的页面,填写离线特征表信息和同步分区信息,并选择同步模式。
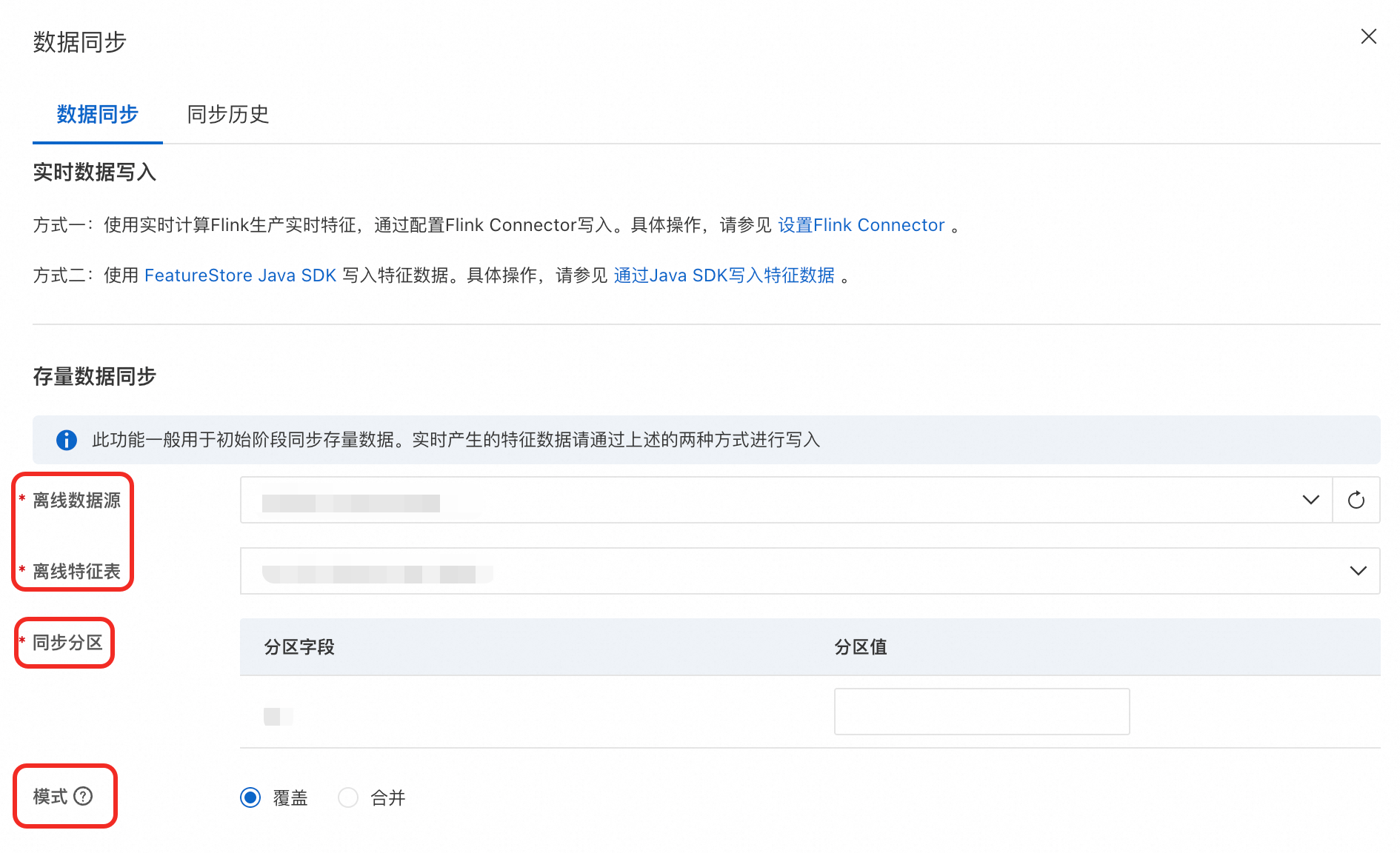
完成后单击提交,会自动跳转到同步历史页签,可以查看数据同步任务运行情况。
对于实时特征写入,默认我们会进行整行数据更新。如果写入数据只包含了部分字段,对于未写入的字段我们会将其设置为空。如果想要只更新写入字段的数据,并将其合并到原有数据上,您可以进行如下设置:
通过Java SDK写入:指定 InsertMode 写入模式,设置为 InsertMode.PartialFieldWrite。
for (int i = 0; i < 100;i++) { featureView.writeFeatures(writeData, InsertMode.PartialFieldWrite); }通过配置Flink Connector写入:设置参数 insert_mode 值为 partial_field_write。
读取特征
您可以使用FeatureStore SDK(Go/Java)或EasyRec Processor读取特征。
FeatureStore SDK(Go/Java )支持离线/实时特征的KV点查。通过指定特征的JoinID(主键)值与特征名称,即可在毫秒内完成键值对(KV)查询,获取目标特征数据。FeatureStore SDK(Go/Java)也支持行为序列特征的KKV查询。通过指定UserID(用户ID)值,即可查询到拼装好的序列特征结果。
EasyRec Processor已集成FeatureStore Cpp SDK,支持将FeatureDB的特征数据全量拉入内存,并支持毫秒级轮询更新实时特征数据到内存,从而实现更高性能的读取。
监控指标
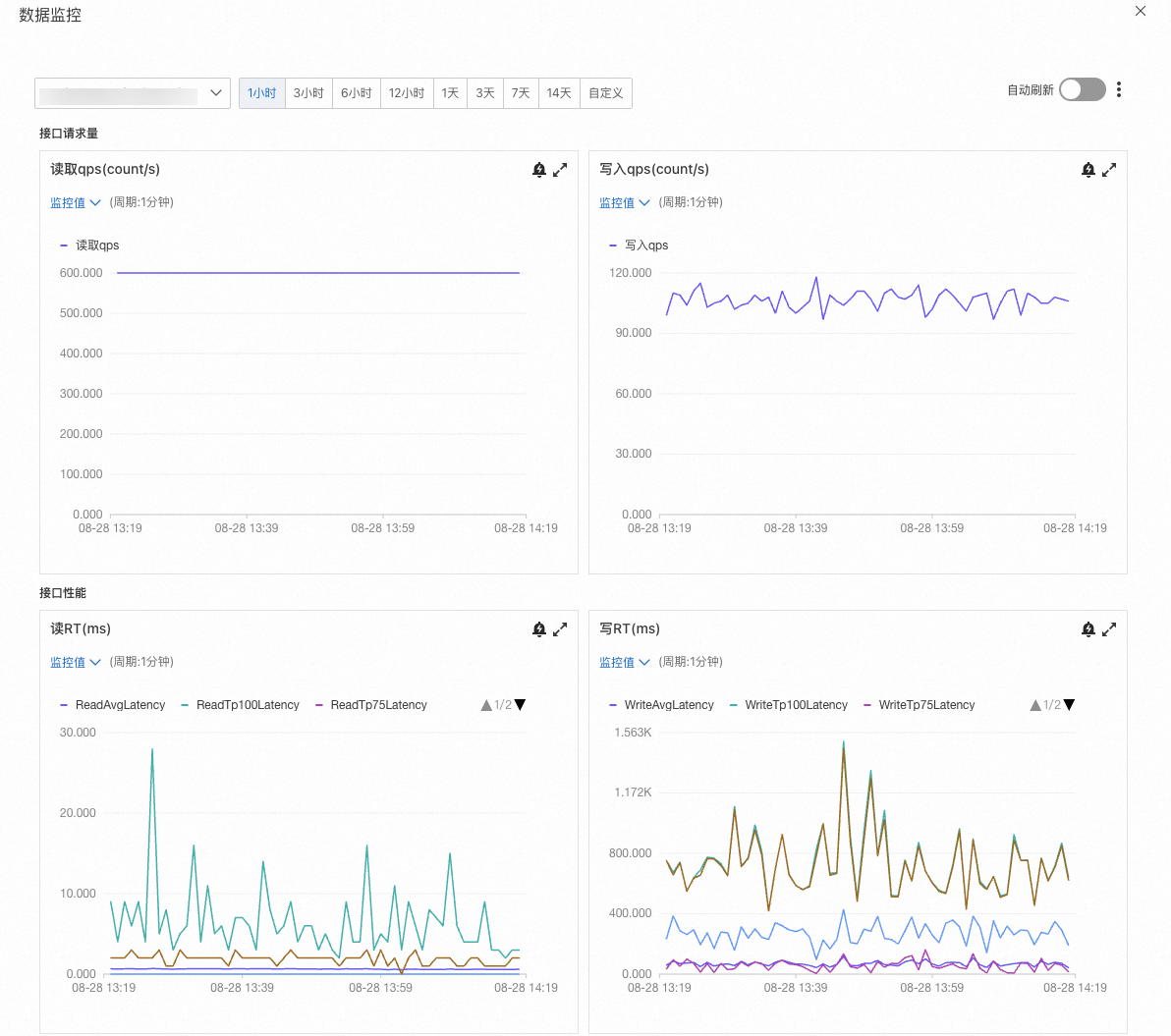
如果使用FeatureDB作为在线数据源,创建特征视图后,单击目标视图右侧的数据监控,可查看该视图的读写QPS和RT等指标。(离线特征视图数据同步写入不会反馈在监控指标中)
实时特征链路

FeatureStore提供的存储服务主要包括三部分:Feature Service(接入层)、消息队列(DataHub)和FeatureDB。
在实时特征中,用户可以通过FeatureStore Java SDK或Flink Connector调用Feature Service服务,将特征数据写入FeatureDB。通过Feature Service写入的数据,也会同步到用户的MaxCompute表中,可以用于实时特征的样本导出,进一步的模型训练。
对于存储在FeatureDB中的特征数据, 用户可以通过FeatureStore的Java/Go SDK读取,也可以通过 EasyRec Processor全量拉取特征存入本地缓存中,以实现更高性能的读取。对于实时特征,可以毫秒级获取最新特征信息。
实时特征数据生命周期设置
在创建实时特征视图时,可以通过特征生命周期来设置FeatureDB表的数据生命周期。当一行数据的生存时间到达生命周期后,它会在几秒内被自动清理。
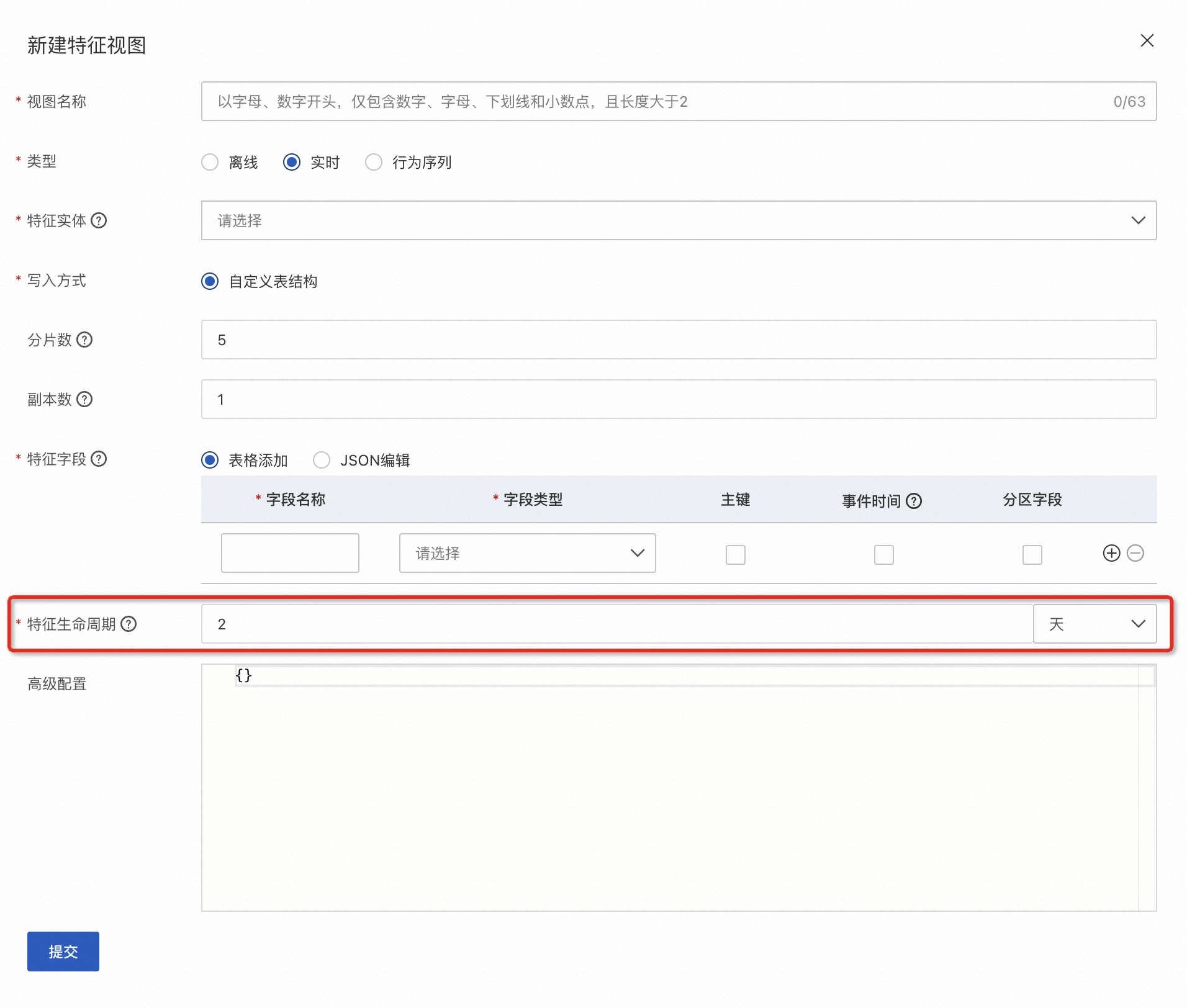
数据的生存时间目前支持两种设置方式:
方式一:不设置事件时间字段。这种情况下,会根据数据的写入时间开始计算生存时间,到达生命周期后,自动清理数据。
方式二:勾选了某个特征字段作为事件时间字段,单位是毫秒。假设 event_time 为事件时间字段的值, time_now 为现在的时间,time_ttl = time_now - ttl 为应该开始过期的 event_time 的值,这种情况下对于写入的特征数据的具体处理方式如下:
如果使用 PartialFieldWrite 模式进行部分字段更新写入,则会根据数据实际写入时间计算生存时间。
event_time > time_now + 15min:数据不写入。(这里防止不同系统之间时间戳有差异,放宽15分钟)
time_ttl < event_time <= time_now + 15min:数据正常写入,根据 event_time 开始计算生存时间,到达生命周期后,自动清理这行数据。
0 < event_time < time_ttl:数据写入后会被自动清理。这里需要注意的是,event_time的单位是毫秒。如果您的事件时间字段的值是秒,那么会落入这种情况,导致数据写入不成功。
event_time <= 0:根据数据实际写入时间计算生存时间。
值非法(无法转换成整型):数据不写入。
注册了事件时间字段但是没有传入事件时间字段的值:数据正常写入,根据数据实际写入时间计算生存时间。
不注册事件时间字段:数据正常写入,根据数据实际写入时间计算生存时间。
另外,在FeatureDB中,我们会将 event_time 的值作为这行数据的ts,意味着如果需要更新一个 key 对应的数据,需要事件时间字段的值大于等于之前的值,这行数据才会更新。如果新的 event_time < 原来 event_time 的值,则不会更新这个key对应的数据。
性能测试
以下是使用FeatureStore Go SDK在VPC环境中读取FeatureDB数据的性能压测结果示例,特征表数据选取的推荐情景中用户侧数据,特征表总行数是17689586,测试机器4核8GiB,测试结果仅供参考。
特征字段数量(列数)
读取keys数量(行数)
平均耗时
TP95
TP99
260
1
0.89毫秒
1.20毫秒
1.45毫秒
260
10
1.17毫秒
1.52毫秒
1.87毫秒
260
50
1.91毫秒
2.56毫秒
2.92毫秒
260
100
2.87毫秒
3.58毫秒
3.93毫秒
260
200
4.43毫秒
5.25毫秒
5.80毫秒
配置了VPC网络高速连通,线上服务部署在非推荐的可用区:
特征字段数量(列数)
读取keys数量(行数)
平均耗时
TP95
TP99
260
1
2.54毫秒
2.86毫秒
3.15毫秒
260
10
2.75毫秒
3.12毫秒
3.56毫秒
260
50
3.95毫秒
4.75毫秒
5.19毫秒
260
100
4.82毫秒
5.66毫秒
6.21毫秒
260
200
6.84毫秒
7.75毫秒
8.25毫秒
未配置VPC网络高速连通:
特征字段数量(列数)
读取keys数量(行数)
平均耗时
TP95
TP99
260
1
3.62毫秒
3.83毫秒
4.27毫秒
260
10
3.82毫秒
4.11毫秒
4.61毫秒
260
50
4.54毫秒
5.19毫秒
5.60毫秒
260
100
5.40毫秒
6.13毫秒
6.56毫秒
260
200
7.15毫秒
7.93毫秒
8.47毫秒
计费说明
详情请参见特征平台(FeatureStore)计费说明。