BladeLLM 是一款专为大语言模型(LLM)优化的推理引擎,旨在提供高性能的模型部署服务。面对LLM领域不断涌现的新机遇与挑战,BladeLLM 通过其先进的技术架构、友好的用户体验和卓越的性能表现,成为企业用户部署和推理LLM模型的理想选择。
技术架构
BladeLLM的技术架构如图所示:

部署平台层
BladeLLM适配各类GPU架构,包括英伟达GPU、AMD GPU和更多GPU类型。此外,BladeLLM与EAS做了深度集成,能够充分利用EAS的资源的调度和管理能力,为用户带来更高效可靠的一站式模型部署体验。
BladeLLM层
模型计算:
BladeLLM的基础是高性能算子和AI编译。BladeLLM设计了高效灵活的LLM算子库BlaDNN,在功能覆盖度和性能方面相对于主流开源算子库都有显著优势。BladeLLM还开源了基于AI编译技术自动算子生成的算子库FlashNN,能够灵活扩展多种硬件平台,性能与专家手工调优的算子实现相当。
量化压缩是LLM推理场景最重要的模型优化手段之一。BladeLLM支持GPTQ / AWQ / SmoothQuant / SmoothQuant+ 等前沿算法,能够显著提升吞吐量和降低延迟。
BladeLLM支持模型在多卡上的分布式推理,提供了张量并行和流水线并行策略,支持任意并行度,解决LLM的显存瓶颈问题。
生成引擎:
除了模型计算层面的优化,为了解决实际场景下高并发的服务性能,BladeLLM设计了针对LLM场景的全异步运行时,用户请求会先异步提交至batch调度模块中,然后异步提交至生成引擎,最后实现了异步解码。
BladeLLM实现了Continuous Batching批处理方式,提升了整体吞吐量和首包响应速度。
Prompt缓存能够使BladeLLM在处理重复或相似查询时从缓存中获取先前计算的结果,加速响应时间。
在解码阶段,BladeLLM通过推测解码(Speculative Decoding)和前向解码(Lookahead Decoding)等高效解码模式,提前预测多个可能的后续token,从而在精度无损的情况下,加速token的生成速度。
服务框架:
随着模型规模的飞速增长,单个实例的资源可能无法满足需求,需要将模型部署在多个实例中。BladeLLM实现了高效的分布式调度策略,结合EAS的LLM智能路由,能够根据全局的实例负载情况,动态分发请求,使得负载分布更加均匀,最大化提升了集群的利用率。
应用场景层
BladeLLM支持对话、检索增强生成(RAG)、多模态、JSON mode多个场景,为用户带来高效的模型部署解决方案。
用户体验
BladeLLM在设计上非常注重用户友好的体验,让用户能够轻松部署和使用LLM模型:
简单便捷的启动方式:BladeLLM在EAS平台上提供了场景化部署方式,预置了镜像、启动命令和常用参数,用户只需选择开源模型或者自定义模型,以及合适的资源规格,即可一键部署模型服务。
灵活易用的调用方式:BladeLLM支持HTTP SSE的流式和非流式响应接口,兼容OpenAI接口协议,便于用户快速集成到业务系统。
强大丰富的模型兼容:BladeLLM模型格式与HuggingFace和ModelScope等社区标准保持兼容,用户可以直接使用现有的模型权重,无需额外转换。
开箱即用的优化选项:BladeLLM实现了量化压缩、投机采样和Prompt缓存等优化功能,用户只需通过简单的参数设置即可使用。
稳定全面的生产支持:BladeLLM提供了稳定的生产镜像,并且在EAS上提供了实时监控和性能压测工具,全面支持客户业务的稳步运行。
性能表现
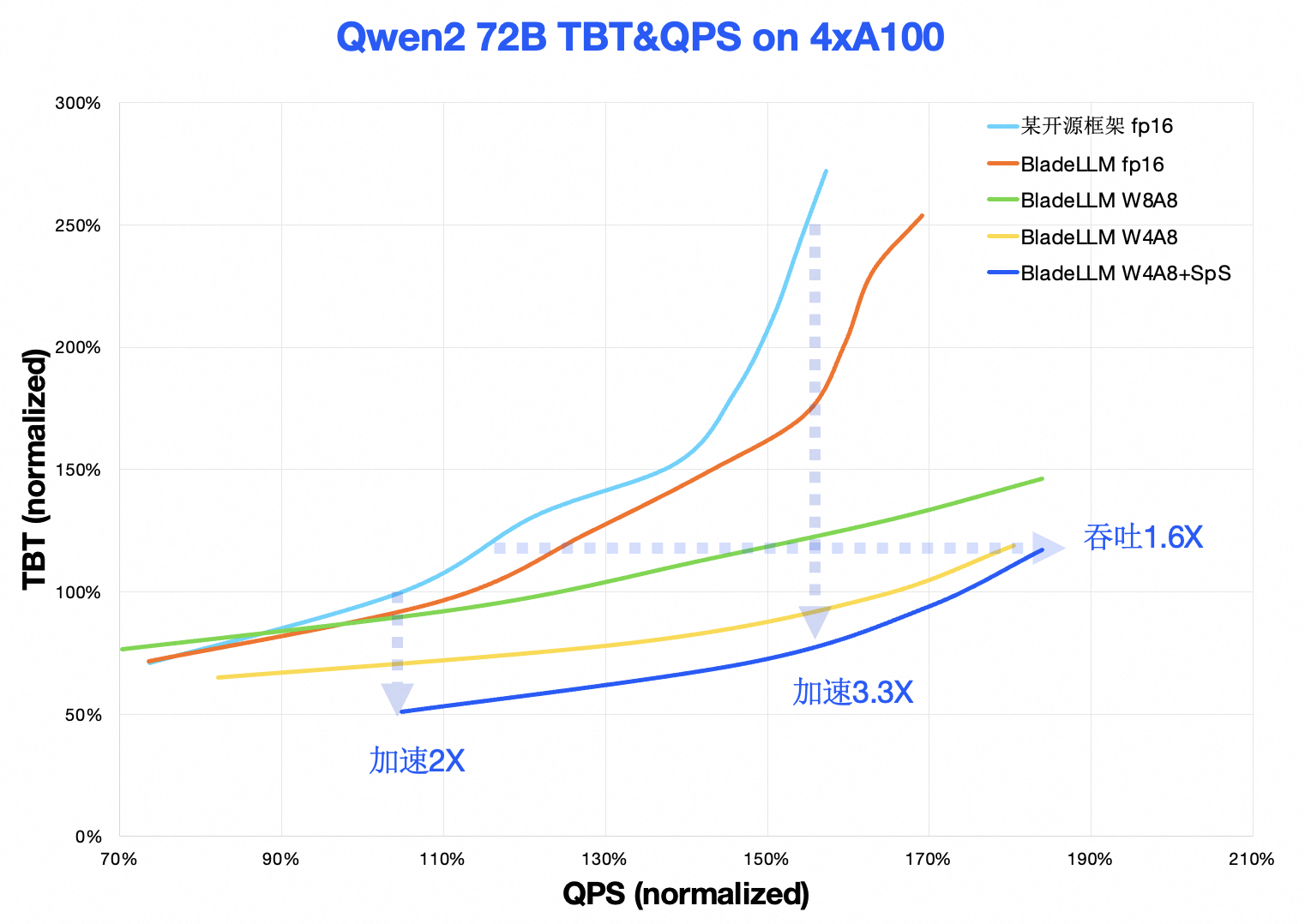
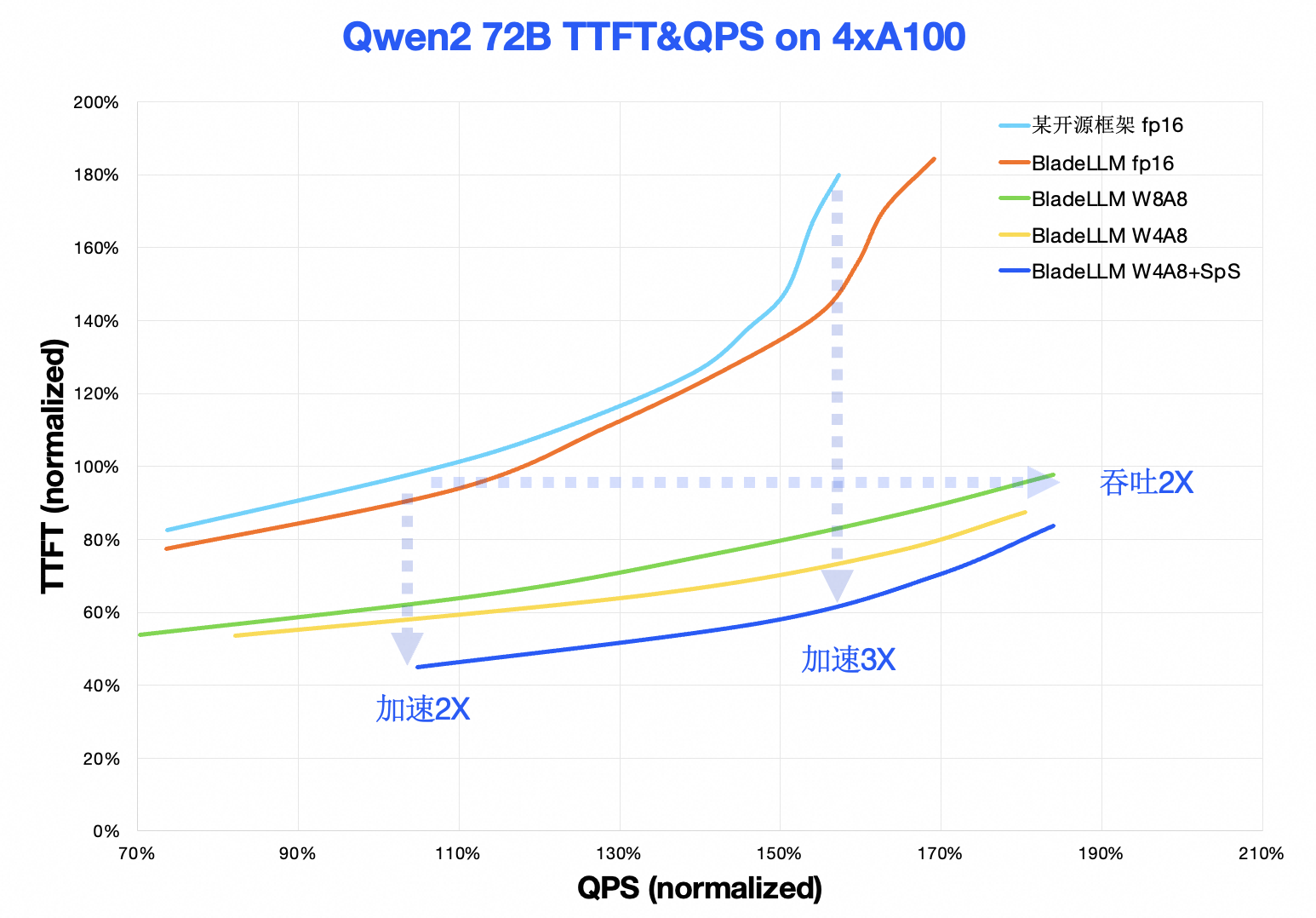
BladeLLM(v0.8.0)和某主流开源框架的性能对比如图所示:
TTFT-QPS曲线:在典型负载下,BladeLLM 首包响应 (TTFT)加速约2倍到3倍,在典型首包响应延迟要求情况下,吞吐(QPS)提升约2倍。
TBT-QPS曲线:在典型负载下,BladeLLM Token生成(TBT)加速约2倍~3.3倍,在典型生成响应延迟要求情况下,吞吐(QPS)提升约1.6X。