
本文介绍容器事件监控如何接入可观测监控 Prometheus 版以及如何查看监控大盘和设置告警规则。事件监控是Kubernetes中的一种监控方式,可以弥补资源监控在实时性、准确性和场景上的不足。您可以通过使用NPD(node-problem-detector),结合SLS的Kubernetes事件中心,配置NPD集群检查项以及异常事件离线功能,使用钉钉、SLS离线Kubernetes事件及EventBridge离线Kubernetes事件,实时监控集群的异常与问题。
前提条件
步骤一:接入容器事件监控
登录Prometheus控制台,在左侧导航栏单击接入中心。
单击容器事件监控卡片,选择待接入的容器服务集群,然后根据控制台指引完成组件接入。
Prometheus服务接入容器事件监控后,完整的数据接入大概需要1~2分钟左右。数据未完整接入前,监控大盘不显示数据。
步骤二:查看监控大盘
可观测监控 Prometheus 版默认内置了很多容器监控大盘,包括集群概览、核心组件、Node、Pod等监控能力,在容器服务控制台、ARMS控制台、Prometheus控制台都有透出。您可以通过以下方式查看监控大盘。
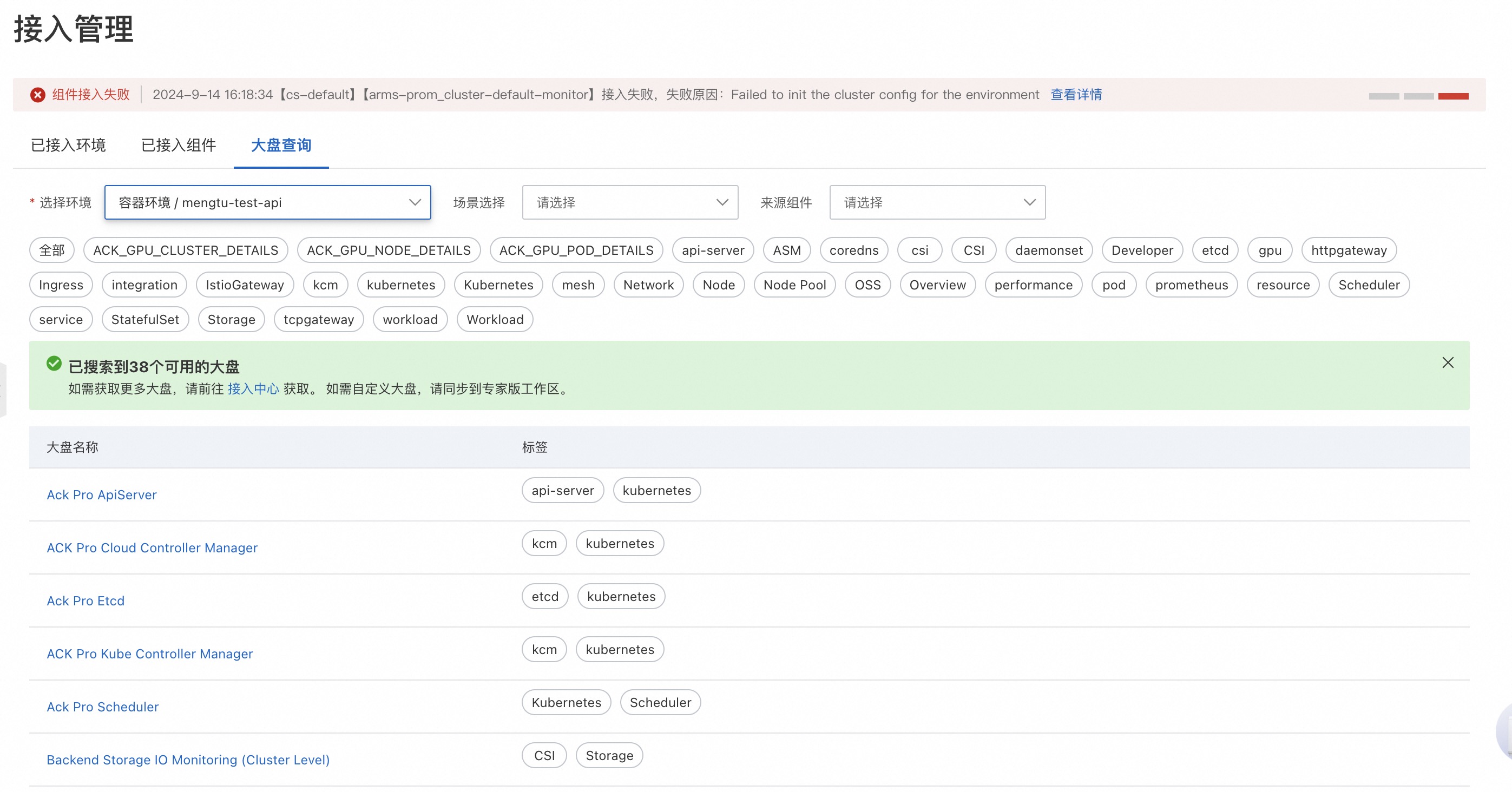
登录Prometheus控制台,在左侧导航栏单击接入管理。
在接入管理页面,单击大盘查询页签。在容器环境中选择待查看的集群,即可查看对应的监控大盘。
步骤三:设置告警
登录Prometheus控制台,在左侧导航栏单击接入管理。
在接入管理页面,单击已接入环境页签。选择容器环境,然后单击目标环境名称,进入容器环境详情页面。
在组件管理页签,查看Prometheus内置的告警通知。
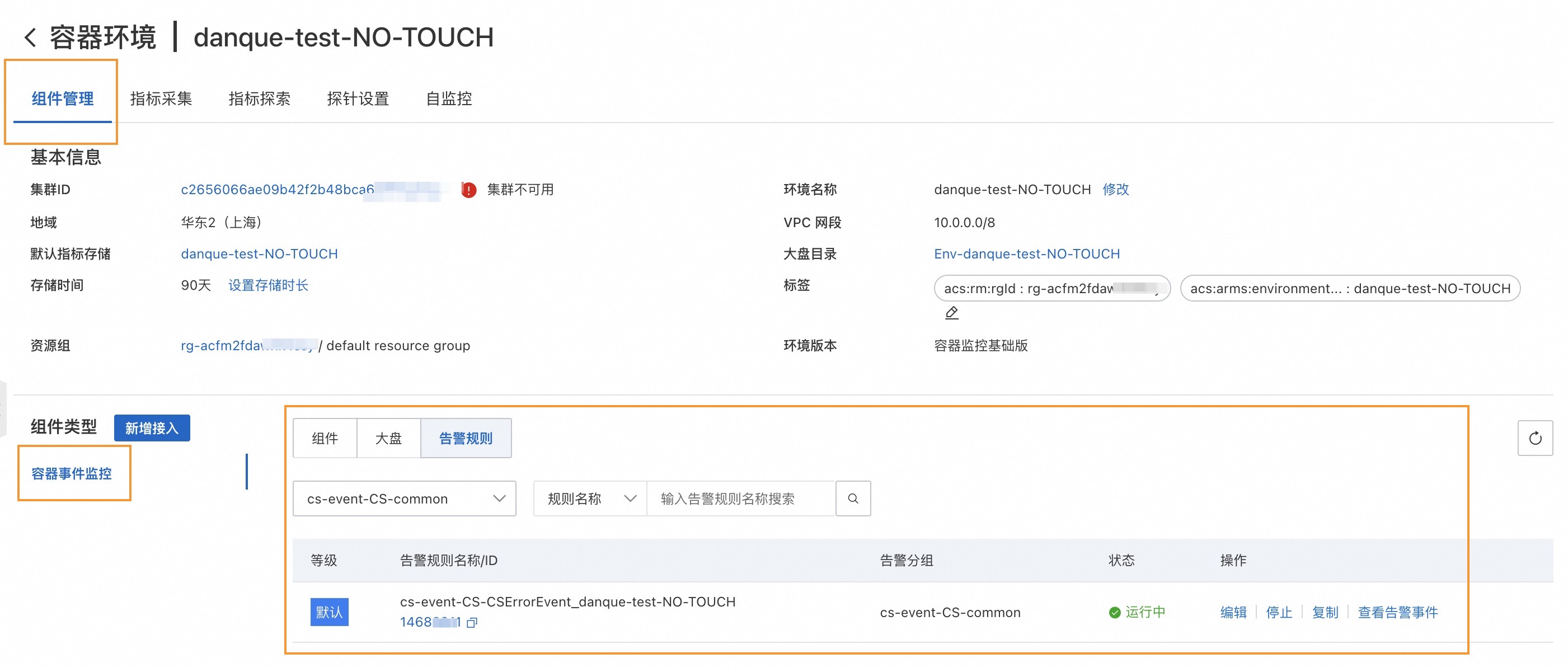
内置的告警规则会产生告警事件,但是不会进行告警通知。如果您希望将告警通知发送到邮件或其他平台,可以单击编辑配置通知方式。
在告警配置页面,您也可以自定义告警阈值、持续时间、告警内容等,告警详细配置,请参见创建Prometheus告警规则。

采集指标说明
指标名称 | 类型 | 指标描述 |
指标名称 | 类型 | 指标描述 |
eventer_events_error_total | COUNTER | 错误类型的事件 |
eventer_events_normal_total | COUNTER | 正常类型的事件 |
eventer_events_warning_total | COUNTER | 异常类型的事件 |
eventer_exporter_duration_milliseconds | SUMMARY | 导出事件以毫秒为单位的时间。 |
eventer_manager_last_time_seconds | GAUGE | 自Unix时代以来,eventer housekeep的最后一次时间(以秒为单位)。 |
eventer_scraper_duration_milliseconds | SUMMARY | 抓取事件所花费的时间(以毫秒为单位)。 |
eventer_scraper_events_total_number | COUNTER | 事件总数 |
eventer_scraper_last_time_seconds | GAUGE | 自Unix时代以来的最后一次事件时间(以秒为单位)。 |
- 本页导读 (1)
- 前提条件
- 步骤一:接入容器事件监控
- 步骤二:查看监控大盘
- 步骤三:设置告警
- 采集指标说明