本文介绍实现大数据分析方案的详细配置操作,包括在RDS MySQL中创建源表、在表格存储中创建结果表、在实时计算Flink中创建作业并启动和在表格存储中分析数据。
前提条件
步骤一:在RDS MySQL中创建源表
通过DMS登录RDS MySQL。具体操作,请参见连接RDS MySQL实例。
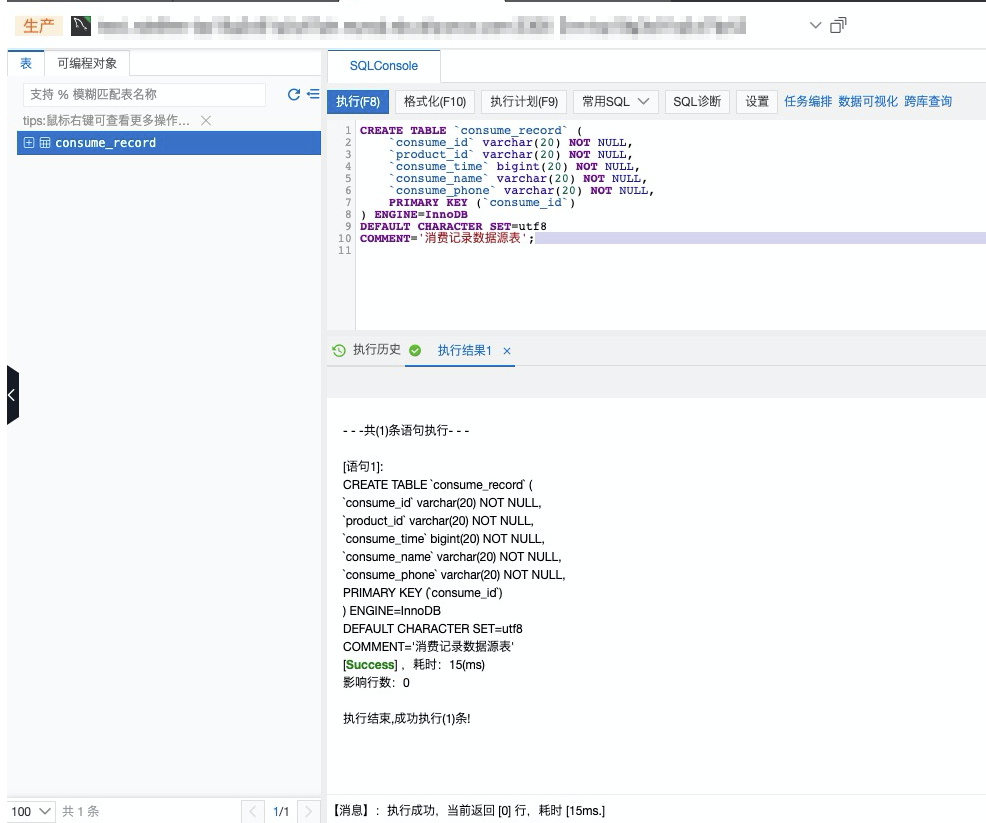
创建数据表consume_record。
consume_record数据表作为流计算任务源表,用于接入实时计算Flink。
编写创数据表的SQL语句。
本方案中SQL示例如下:
CREATE TABLE `consume_record` ( `consume_id` varchar(20) NOT NULL, `product_id` varchar(20) NOT NULL, `consume_time` bigint(20) NOT NULL, `consume_name` varchar(20) NOT NULL, `consume_phone` varchar(20) NOT NULL, PRIMARY KEY (`consume_id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8 COMMENT='消费记录数据源表';单击执行(F8)。
步骤二:在表格存储中创建维表和结果表
登录表格存储控制台。
创建数据表consume_product和product。具体操作,请参见创建数据表。
说明由于表格存储的数据表是schema free的,只需要定义主键,无需定义属性列。
consume_product数据表作为流计算任务结果表,用于保存商品消费信息与商品元数据信息。表结构请参见下表。
字段名称
数据类型
是否主键
描述
consume_id
STRING
是
消费ID(主键)。
product_id
STRING
是
商品ID。
price
DOUBLE
否
商品单价。
consume_time
BIGINT(20)
否
消费时间。
consume_name
STRING
否
消费者名称。
consume_phone
STRING
否
消费者联系方式。
product数据表是流计算任务维表,用于保存商品元数据信息。表结构请参见下表。
字段名称
数据类型
是否主键
描述
product_id
STRING
是
商品ID。
price
DOUBLE
否
商品单价。
product_type
STRING
否
商品类别。
步骤三:在实时计算Flink中创建作业并启动
登录实时计算管理控制台。
在实时计算控制台页面的Flink全托管区域,单击目标工作空间操作列的控制台。
创建作业gmv_post_aggregation。
在左侧导航栏,单击SQL开发。
单击新建。
在新建作业草稿对话框,单击空白的流作业草稿。
单击下一步。
填写作业配置信息。
作业参数
示例
说明
文件名称
flink-test
作业的名称。
说明作业名称在当前项目中必须保持唯一。
存储位置
作业开发
指定该作业的代码文件所属的文件夹。默认存放在作业开发目录。
您还可以在现有文件夹右侧,单击
 图标,新建子文件夹。
图标,新建子文件夹。引擎版本
vvr-6.0.4-flink-1.15
当前作业使用的Flink的引擎版本。引擎版本号含义、版本对应关系和生命周期重要时间点详情请参见引擎版本介绍。
单击创建。
配置作业并上线。
将以下作业代码示例拷贝到作业文本编辑区并根据实际修改配置信息。
-- mysql-cdc源表。 CREATE TEMPORARY TABLE consume_record ( `consume_id` VARCHAR(20), `product_id` VARCHAR(20), `consume_time` BIGINT, `consume_name` VARCHAR(20), `consume_phone` VARCHAR(20), PRIMARY KEY(consume_id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '<hostname>', 'port' = '3306', 'username' = '', 'password' = '', 'database-name' = '', 'table-name' = '' ); -- tablestore维表。 CREATE TEMPORARY TABLE product ( product_id STRING, price DOUBLE, product_type STRING, PRIMARY KEY (product_id) NOT ENFORCED ) WITH ( 'connector' = 'ots', 'endPoint' = '', 'instanceName' = '', 'tableName' = '', 'accessId' = '', 'accessKey' = '' ); -- tablestore结果表。 CREATE TEMPORARY TABLE consume_product ( consume_id STRING, product_id STRING, price DOUBLE, consume_time BIGINT, consume_name STRING, consume_phone STRING, PRIMARY KEY (consume_id,product_id) NOT ENFORCED ) WITH ( 'connector' = 'ots', 'endPoint' = '', 'instanceName' = '', 'tableName' = '', 'accessId' = '', 'accessKey' = '', 'valueColumns' = 'price,consume_time,consume_name,consume_phone' ); insert into consume_product select s.consume_id,d.product_ID as product_id,d.price, UNIX_TIMESTAMP(s.consume_time,'yy-MM-dd') as consume_time, s.consume_name,s.consume_phone from `consume_record` as s join `product` for system_time as of proctime() as d on s.product_id = d.product_ID配置项说明请参见下表。
分类
配置项
示例
描述
mysql-cdc源表配置
connector
mysql-cdc
MySQL连接器,必须设置为mysql-cdc。
hostname
myhost
主机名称。
port
3306
主机端口。
username
myflinktest
数据库账号。
password
********
数据库密码。
database-name
flinktest
数据库名称。
table-name
consume_record
数据表名称。
tablestore结果表
connector
ots
表格存储连接器,必须设置为ots。
endPoint
https://myinstance.cn-hangzhou.ots.aliyuncs.com
实例的服务地址。更多信息,请参见服务地址。
instanceName
myinstance
实例名称。
tableName
consume_product
数据表名称。
accessId
************
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。关于获取AccessKey ID和AccessKey Secret的具体操作,请参见获取AccessKey。
accessKey
****************
valueColumns
price,consume_time
保存到结果表中的列以列表形式表示,多个列之间用半角逗号(,)分隔。
只有当表格存储作为结果表时才需要配置此项。
部署作业。
单击部署。
在部署新版本对话框,填写备注信息和为作业添加标签以及根据需要选择是否提交到Session集群或者是否跳过部署前的深度检查。
如果未选中跳过部署前的深度检查,则系统会进行深度检查,深度检查通过后再进行部署。如果选中了跳过部署前的深度检查,则系统会直接进行部署。
单击确定。
启动作业。
在左侧导航栏,单击作业运维。
单击目标作业名称操作列中的启动。
在作业启动对话框,根据需要选择启动配置,单击启动。
步骤四:在表格存储中分析数据
您可以通过多元索引或者SQL查询功能进行数据分析。
通过多元索引进行数据分析的具体步骤如下:
为数据表consume_product创建多元索引。具体操作,请参见创建多元索引。
通过多元索引的统计聚合功能实现数据分析。
关于统计聚合功能的更多信息,请参见统计聚合、
public void agg(SyncClient client) { //构建查询语句。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("consume_product") //设置数据表名称。 .indexName("consume_product_index") //设置多元索引名称。 .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .addGroupBy(GroupByBuilders.groupByField("groupByProductID","product_id").addSubAggregation( AggregationBuilders.sum("sumagg","price") )) .build()) .build(); SearchResponse searchResponse = syncClient.search(searchRequest); for(GroupByFieldResultItem item : searchResponse.getGroupByResults().getAsGroupByFieldResult("groupByProductID").getGroupByFieldResultItems()){ System.out.println("商品ID:"+item.getKey()+",交易总额:"+item.getSubAggregationResults().getAsSumAggregationResult("sumagg").getValue()); } }结果示例如下:
商品ID:A001,交易总额:20.0 商品ID:A002,交易总额:40.0 商品ID:A004,交易总额:20.0 商品ID:A003,交易总额:5.0 商品ID:A005,交易总额:15.0 商品ID:A006,交易总额:5.0 商品ID:A008,交易总额:5.0
通过SQL查询进行数据分析的具体步骤如下:
为数据表consume_product创建映射关系。具体操作,请参见步骤一:创建映射关系。
创建映射关系的SQL语句示例如下:
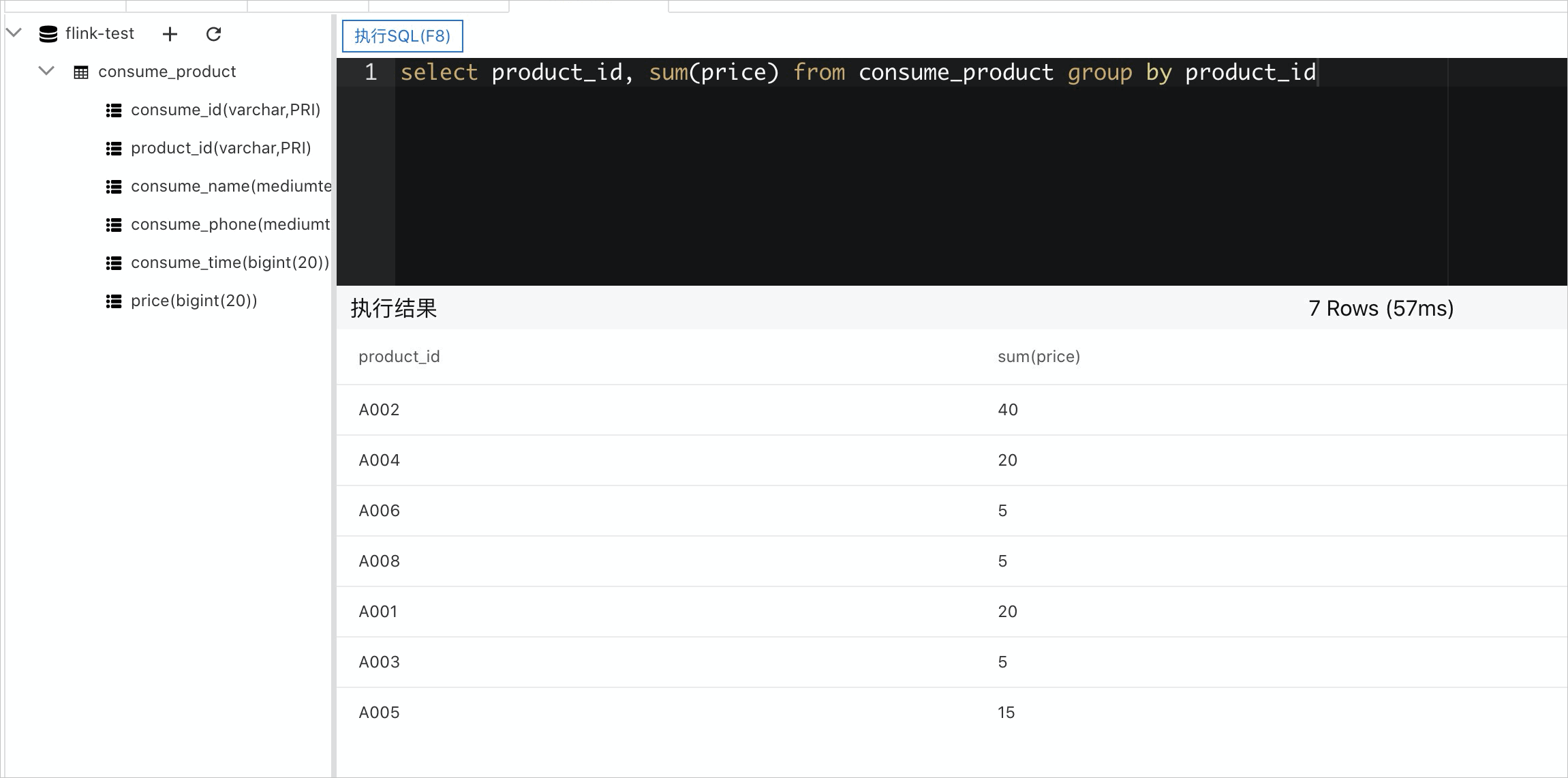
CREATE TABLE consume_product ( consume_id VARCHAR(1024), product_id VARCHAR(1024), price DOUBLE, consume_time BIGINT, consume_name MEDIUMTEXT, consume_phone MEDIUMTEXT, PRIMARY KEY (consume_id,product_id) )执行以下SQL语句进行数据分析。
select product_id, sum(price) from consume_product group by product_id结果示例如下图所示。